 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerch 2.0: The Bittern Lesson for Bioacoustics
Aug 06, 2025



Perch is a performant pre-trained model for bioacoustics. It was trained in supervised fashion, providing both off-the-shelf classification scores for thousands of vocalizing species as well as strong embeddings for transfer learning. In this new release, Perch 2.0, we expand from training exclusively on avian species to a large multi-taxa dataset. The model is trained with self-distillation using a prototype-learning classifier as well as a new source-prediction training criterion. Perch 2.0 obtains state-of-the-art performance on the BirdSet and BEANS benchmarks. It also outperforms specialized marine models on marine transfer learning tasks, despite having almost no marine training data. We present hypotheses as to why fine-grained species classification is a particularly robust pre-training task for bioacoustics.
The Search for Squawk: Agile Modeling in Bioacoustics
May 07, 2025Passive acoustic monitoring (PAM) has shown great promise in helping ecologists understand the health of animal populations and ecosystems. However, extracting insights from millions of hours of audio recordings requires the development of specialized recognizers. This is typically a challenging task, necessitating large amounts of training data and machine learning expertise. In this work, we introduce a general, scalable and data-efficient system for developing recognizers for novel bioacoustic problems in under an hour. Our system consists of several key components that tackle problems in previous bioacoustic workflows: 1) highly generalizable acoustic embeddings pre-trained for birdsong classification minimize data hunger; 2) indexed audio search allows the efficient creation of classifier training datasets, and 3) precomputation of embeddings enables an efficient active learning loop, improving classifier quality iteratively with minimal wait time. Ecologists employed our system in three novel case studies: analyzing coral reef health through unidentified sounds; identifying juvenile Hawaiian bird calls to quantify breeding success and improve endangered species monitoring; and Christmas Island bird occupancy modeling. We augment the case studies with simulated experiments which explore the range of design decisions in a structured way and help establish best practices. Altogether these experiments showcase our system's scalability, efficiency, and generalizability, enabling scientists to quickly address new bioacoustic challenges.
Leveraging tropical reef, bird and unrelated sounds for superior transfer learning in marine bioacoustics
Apr 25, 2024



Machine learning has the potential to revolutionize passive acoustic monitoring (PAM) for ecological assessments. However, high annotation and compute costs limit the field's efficacy. Generalizable pretrained networks can overcome these costs, but high-quality pretraining requires vast annotated libraries, limiting its current applicability primarily to bird taxa. Here, we identify the optimum pretraining strategy for a data-deficient domain using coral reef bioacoustics. We assemble ReefSet, a large annotated library of reef sounds, though modest compared to bird libraries at 2% of the sample count. Through testing few-shot transfer learning performance, we observe that pretraining on bird audio provides notably superior generalizability compared to pretraining on ReefSet or unrelated audio alone. However, our key findings show that cross-domain mixing which leverages bird, reef and unrelated audio during pretraining maximizes reef generalizability. SurfPerch, our pretrained network, provides a strong foundation for automated analysis of marine PAM data with minimal annotation and compute costs.
BIRB: A Generalization Benchmark for Information Retrieval in Bioacoustics
Dec 13, 2023

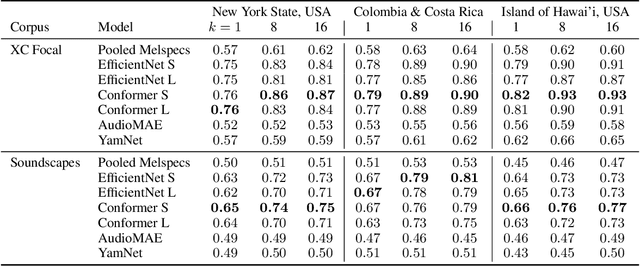

The ability for a machine learning model to cope with differences in training and deployment conditions--e.g. in the presence of distribution shift or the generalization to new classes altogether--is crucial for real-world use cases. However, most empirical work in this area has focused on the image domain with artificial benchmarks constructed to measure individual aspects of generalization. We present BIRB, a complex benchmark centered on the retrieval of bird vocalizations from passively-recorded datasets given focal recordings from a large citizen science corpus available for training. We propose a baseline system for this collection of tasks using representation learning and a nearest-centroid search. Our thorough empirical evaluation and analysis surfaces open research directions, suggesting that BIRB fills the need for a more realistic and complex benchmark to drive progress on robustness to distribution shifts and generalization of ML models.
Simple Steps to Success: Axiomatics of Distance-Based Algorithmic Recourse
Jun 27, 2023



We propose a novel data-driven framework for algorithmic recourse that offers users interventions to change their predicted outcome. Existing approaches to compute recourse find a set of points that satisfy some desiderata -- e.g. an intervention in the underlying causal graph, or minimizing a cost function. Satisfying these criteria, however, requires extensive knowledge of the underlying model structure, often an unrealistic amount of information in several domains. We propose a data-driven, computationally efficient approach to computing algorithmic recourse. We do so by suggesting directions in the data manifold that users can take to change their predicted outcome. We present Stepwise Explainable Paths (StEP), an axiomatically justified framework to compute direction-based algorithmic recourse. We offer a thorough empirical and theoretical investigation of StEP. StEP offers provable privacy and robustness guarantees, and outperforms the state-of-the-art on several established recourse desiderata.