 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
An Evaluation of GPT-4V and Gemini in Online VQA
Dec 17, 2023
A comprehensive evaluation is critical to assess the capabilities of large multimodal models (LMM). In this study, we evaluate the state-of-the-art LMMs, namely GPT-4V and Gemini, utilizing the VQAonline dataset. VQAonline is an end-to-end authentic VQA dataset sourced from a diverse range of everyday users. Compared previous benchmarks, VQAonline well aligns with real-world tasks. It enables us to effectively evaluate the generality of an LMM, and facilitates a direct comparison with human performance. To comprehensively evaluate GPT-4V and Gemini, we generate seven types of metadata for around 2,000 visual questions, such as image type and the required image processing capabilities. Leveraging this array of metadata, we analyze the zero-shot performance of GPT-4V and Gemini, and identify the most challenging questions for both models.
Quality and Quantity: Unveiling a Million High-Quality Images for Text-to-Image Synthesis in Fashion Design
Nov 29, 2023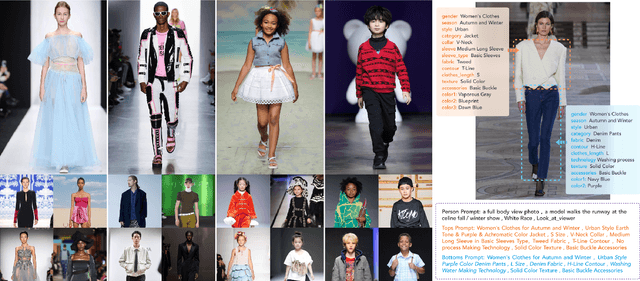
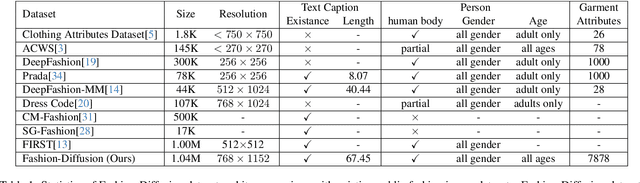
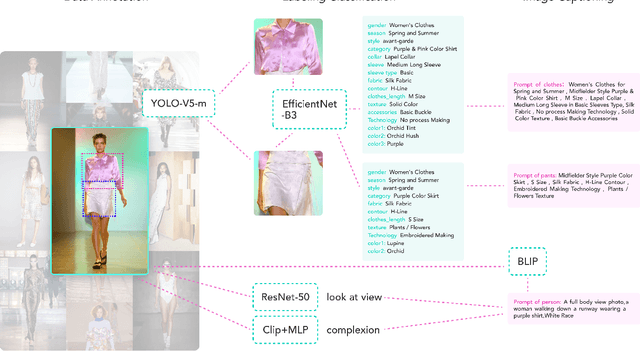
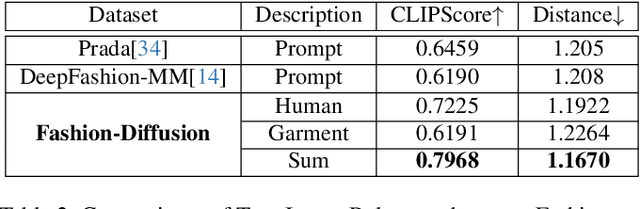
The fusion of AI and fashion design has emerged as a promising research area. However, the lack of extensive, interrelated data on clothing and try-on stages has hindered the full potential of AI in this domain. Addressing this, we present the Fashion-Diffusion dataset, a product of multiple years' rigorous effort. This dataset, the first of its kind, comprises over a million high-quality fashion images, paired with detailed text descriptions. Sourced from a diverse range of geographical locations and cultural backgrounds, the dataset encapsulates global fashion trends. The images have been meticulously annotated with fine-grained attributes related to clothing and humans, simplifying the fashion design process into a Text-to-Image (T2I) task. The Fashion-Diffusion dataset not only provides high-quality text-image pairs and diverse human-garment pairs but also serves as a large-scale resource about humans, thereby facilitating research in T2I generation. Moreover, to foster standardization in the T2I-based fashion design field, we propose a new benchmark comprising multiple datasets for evaluating the performance of fashion design models. This work represents a significant leap forward in the realm of AI-driven fashion design, setting a new standard for future research in this field.
Enhanced Breast Cancer Tumor Classification using MobileNetV2: A Detailed Exploration on Image Intensity, Error Mitigation, and Streamlit-driven Real-time Deployment
Dec 05, 2023This research introduces a sophisticated transfer learning model based on Google's MobileNetV2 for breast cancer tumor classification into normal, benign, and malignant categories, utilizing a dataset of 1576 ultrasound images (265 normal, 891 benign, 420 malignant). The model achieves an accuracy of 0.82, precision of 0.83, recall of 0.81, ROC-AUC of 0.94, PR-AUC of 0.88, and MCC of 0.74. It examines image intensity distributions and misclassification errors, offering improvements for future applications. Addressing dataset imbalances, the study ensures a generalizable model. This work, using a dataset from Baheya Hospital, Cairo, Egypt, compiled by Walid Al-Dhabyani et al., emphasizes MobileNetV2's potential in medical imaging, aiming to improve diagnostic precision in oncology. Additionally, the paper explores Streamlit-based deployment for real-time tumor classification, demonstrating MobileNetV2's applicability in medical imaging and setting a benchmark for future research in oncology diagnostics.
Single Image Compressed Sensing MRI via a Self-Supervised Deep Denoising Approach
Nov 22, 2023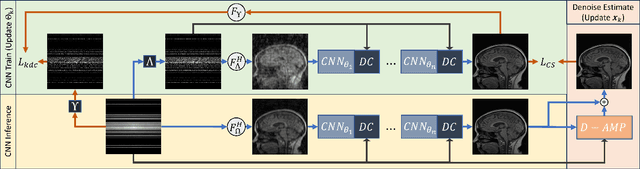
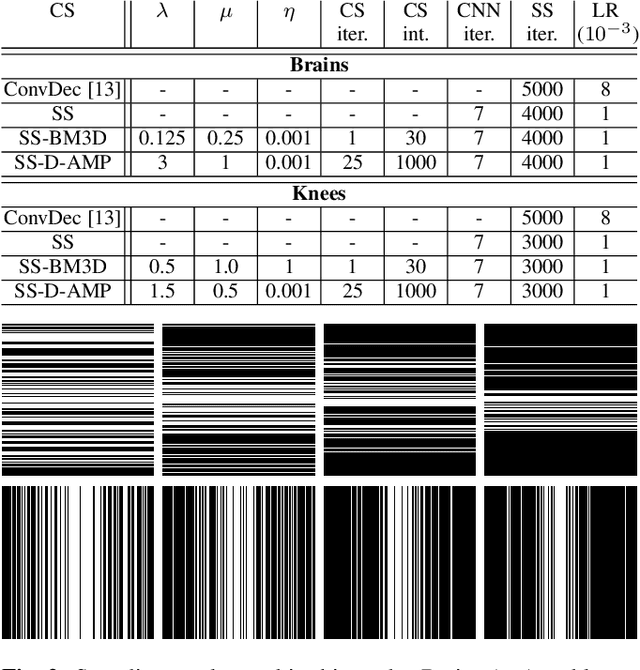
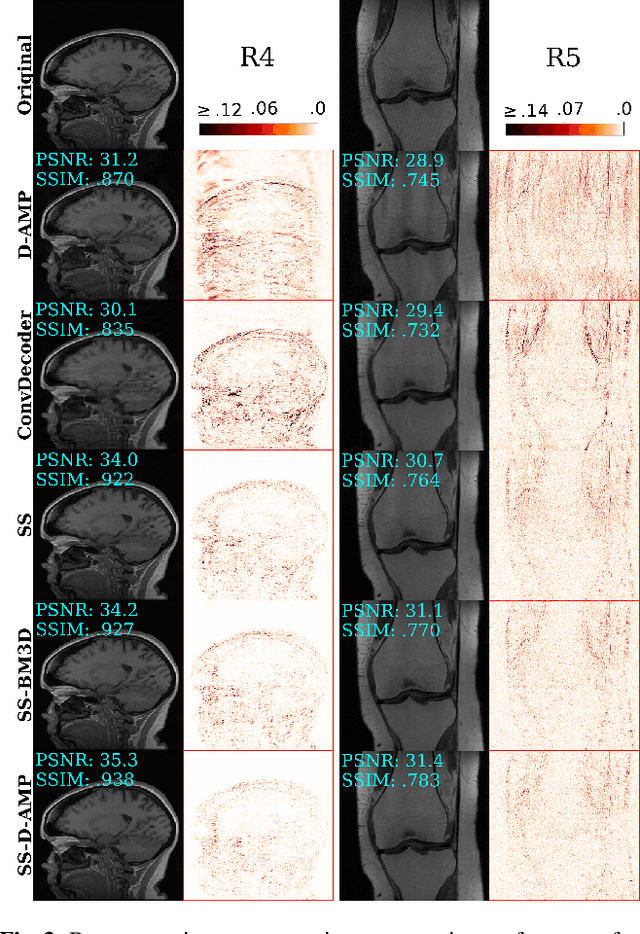
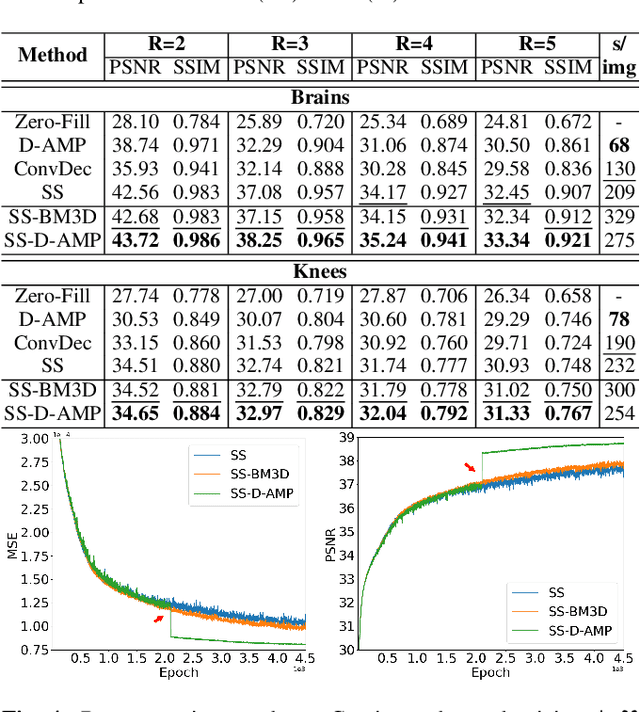
Popular methods in compressed sensing (CS) are dependent on deep learning (DL), where large amounts of data are used to train non-linear reconstruction models. However, ensuring generalisability over and access to multiple datasets is challenging to realise for real-world applications. To address these concerns, this paper proposes a single image, self-supervised (SS) CS-MRI framework that enables a joint deep and sparse regularisation of CS artefacts. The approach effectively dampens structured CS artefacts, which can be difficult to remove assuming sparse reconstruction, or relying solely on the inductive biases of CNN to produce noise-free images. Image quality is thereby improved compared to either approach alone. Metrics are evaluated using Cartesian 1D masks on a brain and knee dataset, with PSNR improving by 2-4dB on average.
Corrupting Convolution-based Unlearnable Datasets with Pixel-based Image Transformations
Nov 30, 2023Unlearnable datasets lead to a drastic drop in the generalization performance of models trained on them by introducing elaborate and imperceptible perturbations into clean training sets. Many existing defenses, e.g., JPEG compression and adversarial training, effectively counter UDs based on norm-constrained additive noise. However, a fire-new type of convolution-based UDs have been proposed and render existing defenses all ineffective, presenting a greater challenge to defenders. To address this, we express the convolution-based unlearnable sample as the result of multiplying a matrix by a clean sample in a simplified scenario, and formalize the intra-class matrix inconsistency as $\Theta_{imi}$, inter-class matrix consistency as $\Theta_{imc}$ to investigate the working mechanism of the convolution-based UDs. We conjecture that increasing both of these metrics will mitigate the unlearnability effect. Through validation experiments that commendably support our hypothesis, we further design a random matrix to boost both $\Theta_{imi}$ and $\Theta_{imc}$, achieving a notable degree of defense effect. Hence, by building upon and extending these facts, we first propose a brand-new image COrruption that employs randomly multiplicative transformation via INterpolation operation to successfully defend against convolution-based UDs. Our approach leverages global pixel random interpolations, effectively suppressing the impact of multiplicative noise in convolution-based UDs. Additionally, we have also designed two new forms of convolution-based UDs, and find that our defense is the most effective against them.
A Survey of Classical And Quantum Sequence Models
Dec 15, 2023Our primary objective is to conduct a brief survey of various classical and quantum neural net sequence models, which includes self-attention and recurrent neural networks, with a focus on recent quantum approaches proposed to work with near-term quantum devices, while exploring some basic enhancements for these quantum models. We re-implement a key representative set of these existing methods, adapting an image classification approach using quantum self-attention to create a quantum hybrid transformer that works for text and image classification, and applying quantum self-attention and quantum recurrent neural networks to natural language processing tasks. We also explore different encoding techniques and introduce positional encoding into quantum self-attention neural networks leading to improved accuracy and faster convergence in text and image classification experiments. This paper also performs a comparative analysis of classical self-attention models and their quantum counterparts, helping shed light on the differences in these models and their performance.
Receler: Reliable Concept Erasing of Text-to-Image Diffusion Models via Lightweight Erasers
Nov 29, 2023Concept erasure in text-to-image diffusion models aims to disable pre-trained diffusion models from generating images related to a target concept. To perform reliable concept erasure, the properties of robustness and locality are desirable. The former refrains the model from producing images associated with the target concept for any paraphrased or learned prompts, while the latter preserves the model ability in generating images for non-target concepts. In this paper, we propose Reliable Concept Erasing via Lightweight Erasers (Receler), which learns a lightweight Eraser to perform concept erasing and enhances locality and robustness with the proposed concept-localized regularization and adversarial prompt learning, respectively. Comprehensive quantitative and qualitative experiments with various concept prompts verify the superiority of Receler over the previous erasing methods on the above two desirable properties.
Single-Image 3D Human Digitization with Shape-Guided Diffusion
Nov 15, 2023We present an approach to generate a 360-degree view of a person with a consistent, high-resolution appearance from a single input image. NeRF and its variants typically require videos or images from different viewpoints. Most existing approaches taking monocular input either rely on ground-truth 3D scans for supervision or lack 3D consistency. While recent 3D generative models show promise of 3D consistent human digitization, these approaches do not generalize well to diverse clothing appearances, and the results lack photorealism. Unlike existing work, we utilize high-capacity 2D diffusion models pretrained for general image synthesis tasks as an appearance prior of clothed humans. To achieve better 3D consistency while retaining the input identity, we progressively synthesize multiple views of the human in the input image by inpainting missing regions with shape-guided diffusion conditioned on silhouette and surface normal. We then fuse these synthesized multi-view images via inverse rendering to obtain a fully textured high-resolution 3D mesh of the given person. Experiments show that our approach outperforms prior methods and achieves photorealistic 360-degree synthesis of a wide range of clothed humans with complex textures from a single image.
Diagonal Hierarchical Consistency Learning for Semi-supervised Medical Image Segmentation
Nov 20, 2023Medical image segmentation, which is essential for many clinical applications, has achieved almost human-level performance via data-driven deep learning techniques. Nevertheless, its performance is predicated upon the costly process of manually annotating a vast amount of medical images. To this end, we propose a novel framework for robust semi-supervised medical image segmentation using diagonal hierarchical consistency learning (DiHC-Net). First, it is composed of multiple sub-models with identical multi-scale architecture but with distinct sub-layers, such as up-sampling and normalisation layers. Second, along with mutual consistency, a novel diagonal hierarchical consistency is enforced between one model's intermediate and final prediction and other models' soft pseudo labels in a diagonal hierarchical fashion. Experimental results verify the efficacy of our simple framework, outperforming all previous approaches on public Left Atrium (LA) dataset.
Enhancing Low-dose CT Image Reconstruction by Integrating Supervised and Unsupervised Learning
Nov 19, 2023Traditional model-based image reconstruction (MBIR) methods combine forward and noise models with simple object priors. Recent application of deep learning methods for image reconstruction provides a successful data-driven approach to addressing the challenges when reconstructing images with undersampled measurements or various types of noise. In this work, we propose a hybrid supervised-unsupervised learning framework for X-ray computed tomography (CT) image reconstruction. The proposed learning formulation leverages both sparsity or unsupervised learning-based priors and neural network reconstructors to simulate a fixed-point iteration process. Each proposed trained block consists of a deterministic MBIR solver and a neural network. The information flows in parallel through these two reconstructors and is then optimally combined. Multiple such blocks are cascaded to form a reconstruction pipeline. We demonstrate the efficacy of this learned hybrid model for low-dose CT image reconstruction with limited training data, where we use the NIH AAPM Mayo Clinic Low Dose CT Grand Challenge dataset for training and testing. In our experiments, we study combinations of supervised deep network reconstructors and MBIR solver with learned sparse representation-based priors or analytical priors. Our results demonstrate the promising performance of the proposed framework compared to recent low-dose CT reconstruction methods.