 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Global and Local Interpretability for Cardiac MRI Classification
Jun 14, 2019
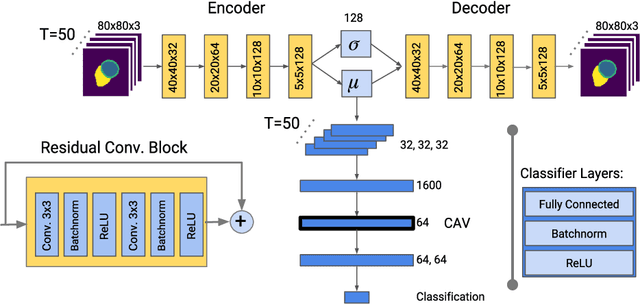

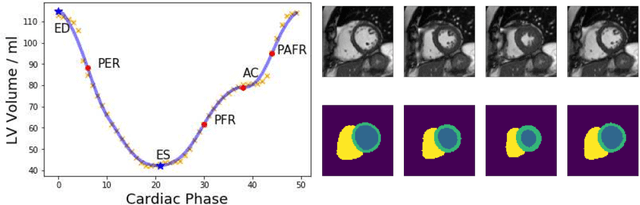
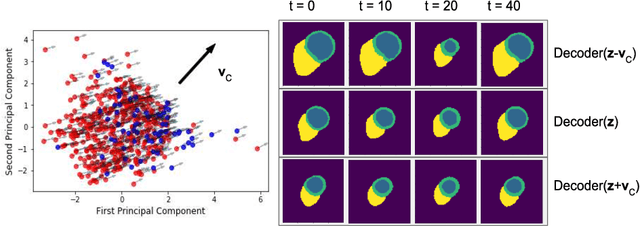
Deep learning methods for classifying medical images have demonstrated impressive accuracy in a wide range of tasks but often these models are hard to interpret, limiting their applicability in clinical practice. In this work we introduce a convolutional neural network model for identifying disease in temporal sequences of cardiac MR segmentations which is interpretable in terms of clinically familiar measurements. The model is based around a variational autoencoder, reducing the input into a low-dimensional latent space in which classification occurs. We then use the recently developed `concept activation vector' technique to associate concepts which are diagnostically meaningful (eg. clinical biomarkers such as `low left-ventricular ejection fraction') to certain vectors in the latent space. These concepts are then qualitatively inspected by observing the change in the image domain resulting from interpolations in the latent space in the direction of these vectors. As a result, when the model classifies images it is also capable of providing naturally interpretable concepts relevant to that classification and demonstrating the meaning of those concepts in the image domain. Our approach is demonstrated on the UK Biobank cardiac MRI dataset where we detect the presence of coronary artery disease.
Automated Pavement Crack Segmentation Using Fully Convolutional U-Net with a Pretrained ResNet-34 Encoder
Jan 11, 2020
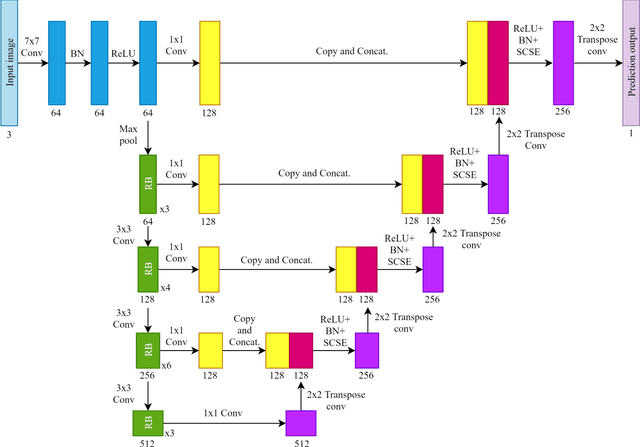
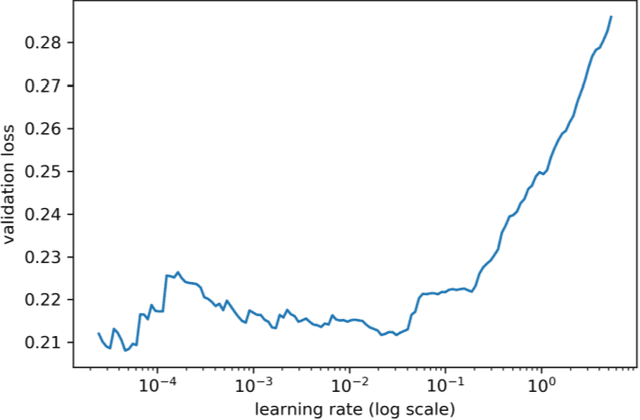
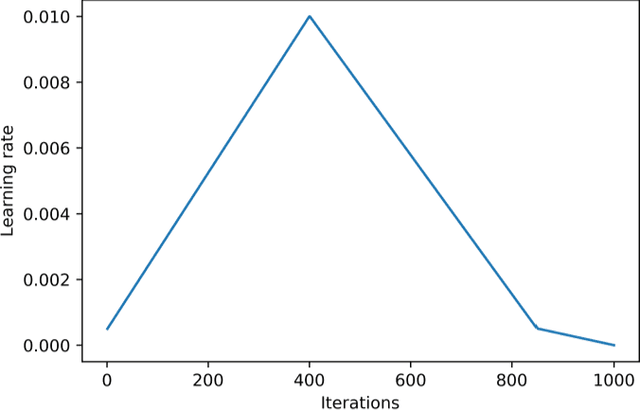
Automated pavement crack segmentation is a challenging task because of inherent irregular patterns and lighting conditions, in addition to the presence of noise in images. Conventional approaches require a substantial amount of feature engineering to differentiate crack regions from non-affected regions. In this paper, we propose a deep learning technique based on a convolutional neural network to perform segmentation tasks on pavement crack images. Our approach requires minimal feature engineering compared to other machine learning techniques. The proposed neural network architecture is a modified U-Net in which the encoder is replaced with a pretrained ResNet-34 network. To minimize the dice coefficient loss function, we optimize the parameters in the neural network by using an adaptive moment optimizer called AdamW. Additionally, we use a systematic method to find the optimum learning rate instead of doing parametric sweeps. We used a "one-cycle" training schedule based on cyclical learning rates to speed up the convergence. We evaluated the performance of our convolutional neural network on CFD, a pavement crack image dataset. Our method achieved an F1 score of about 96%. This is the best performance among all other algorithms tested on this dataset, outperforming the previous best method by a 1.7% margin.
Facial Recognition with Encoded Local Projections
Sep 11, 2018
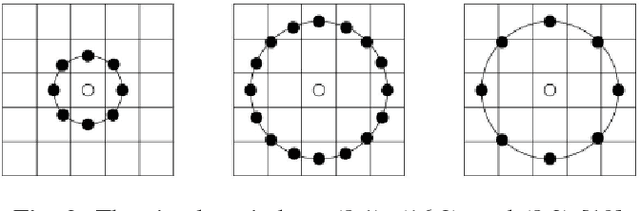

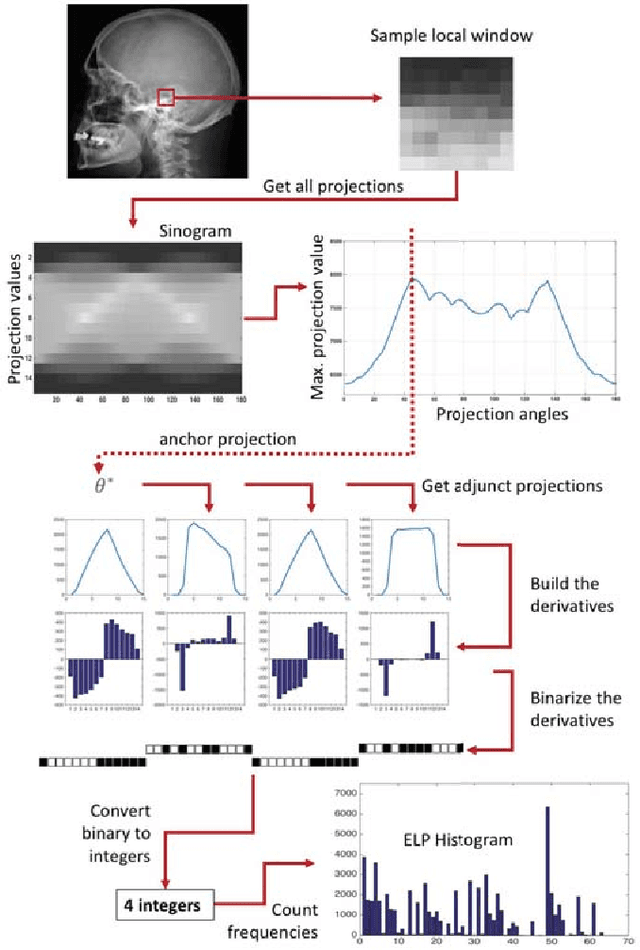
Encoded Local Projections (ELP) is a recently introduced dense sampling image descriptor which uses projections in small neighbourhoods to construct a histogram/descriptor for the entire image. ELP has shown to be as accurate as other state-of-the-art features in searching medical images while being time and resource efficient. This paper attempts for the first time to utilize ELP descriptor as primary features for facial recognition and compare the results with LBP histogram on the Labeled Faces in the Wild dataset. We have evaluated descriptors by comparing the chi-squared distance of each image descriptor versus all others as well as training Support Vector Machines (SVM) with each feature vector. In both cases, the results of ELP were better than LBP in the same sub-image configuration.
Learning Data Manipulation for Augmentation and Weighting
Oct 28, 2019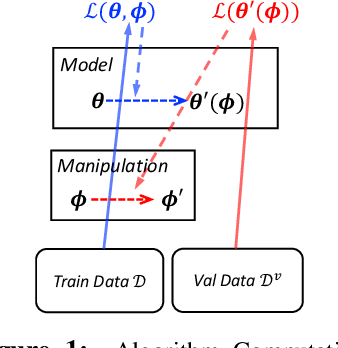
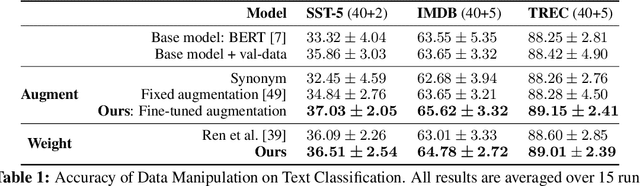
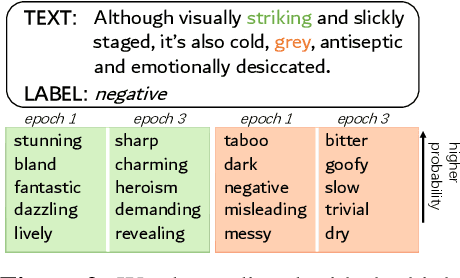
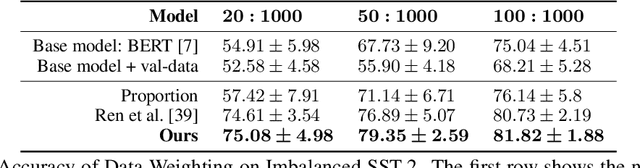
Manipulating data, such as weighting data examples or augmenting with new instances, has been increasingly used to improve model training. Previous work has studied various rule- or learning-based approaches designed for specific types of data manipulation. In this work, we propose a new method that supports learning different manipulation schemes with the same gradient-based algorithm. Our approach builds upon a recent connection of supervised learning and reinforcement learning (RL), and adapts an off-the-shelf reward learning algorithm from RL for joint data manipulation learning and model training. Different parameterization of the "data reward" function instantiates different manipulation schemes. We showcase data augmentation that learns a text transformation network, and data weighting that dynamically adapts the data sample importance. Experiments show the resulting algorithms significantly improve the image and text classification performance in low data regime and class-imbalance problems.
Spatial-Spectral Fusion by Combining Deep Learning and Variation Model
Sep 04, 2018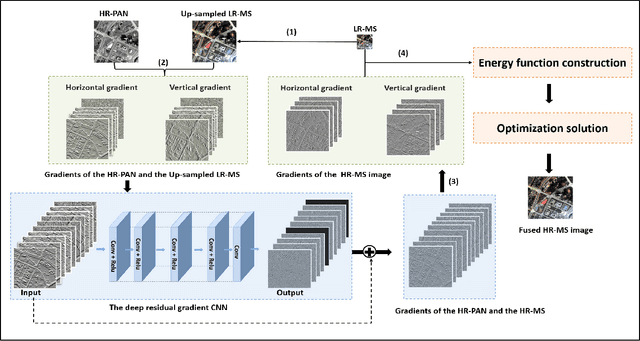


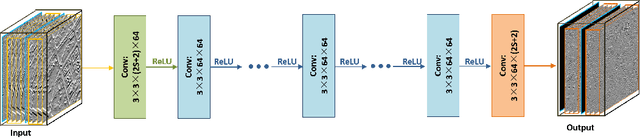
In the field of spatial-spectral fusion, the model-based method and the deep learning (DL)-based method are state-of-the-art. This paper presents a fusion method that incorporates the deep neural network into the model-based method for the most common case in the spatial-spectral fusion: PAN/multispectral (MS) fusion. Specifically, we first map the gradient of the high spatial resolution panchromatic image (HR-PAN) and the low spatial resolution multispectral image (LR-MS) to the gradient of the high spatial resolution multispectral image (HR-MS) via a deep residual convolutional neural network (CNN). Then we construct a fusion framework by the LR-MS image, the gradient prior learned from the gradient network, and the ideal fused image. Finally, an iterative optimization algorithm is used to solve the fusion model. Both quantitative and visual assessments on high-quality images from various sources demonstrate that the proposed fusion method is superior to all the mainstream algorithms included in the comparison in terms of overall fusion accuracy.
Stroke Constrained Attention Network for Online Handwritten Mathematical Expression Recognition
Feb 20, 2020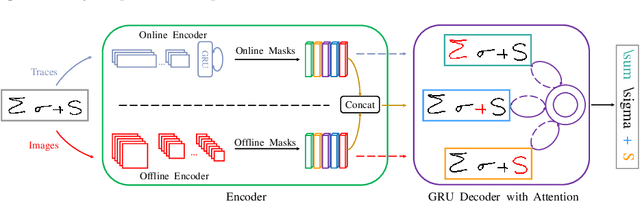
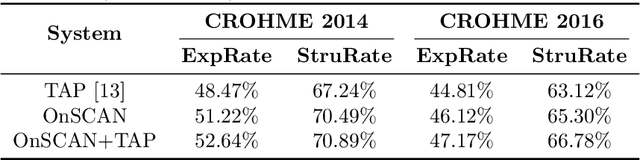
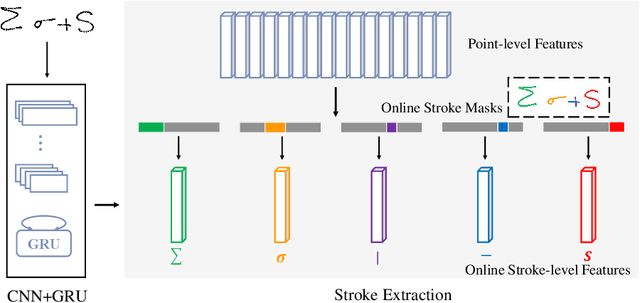
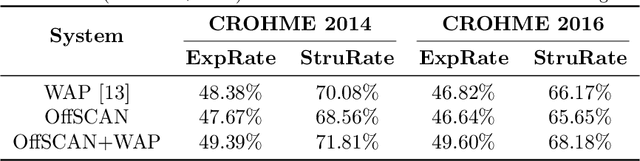
In this paper, we propose a novel stroke constrained attention network (SCAN) which treats stroke as the basic unit for encoder-decoder based online handwritten mathematical expression recognition (HMER). Unlike previous methods which use trace points or image pixels as basic units, SCAN makes full use of stroke-level information for better alignment and representation. The proposed SCAN can be adopted in both single-modal (online or offline) and multi-modal HMER. For single-modal HMER, SCAN first employs a CNN-GRU encoder to extract point-level features from input traces in online mode and employs a CNN encoder to extract pixel-level features from input images in offline mode, then use stroke constrained information to convert them into online and offline stroke-level features. Using stroke-level features can explicitly group points or pixels belonging to the same stroke, therefore reduces the difficulty of symbol segmentation and recognition via the decoder with attention mechanism. For multi-modal HMER, other than fusing multi-modal information in decoder, SCAN can also fuse multi-modal information in encoder by utilizing the stroke based alignments between online and offline modalities. The encoder fusion is a better way for combining multi-modal information as it implements the information interaction one step before the decoder fusion so that the advantages of multiple modalities can be exploited earlier and more adequately when training the encoder-decoder model. Evaluated on a benchmark published by CROHME competition, the proposed SCAN achieves the state-of-the-art performance.
Learning to Globally Edit Images with Textual Description
Oct 13, 2018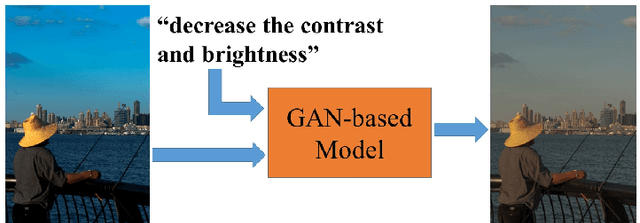


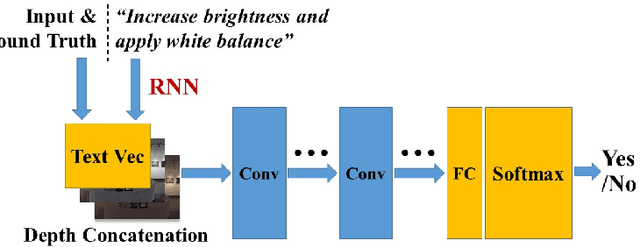
We show how we can globally edit images using textual instructions: given a source image and a textual instruction for the edit, generate a new image transformed under this instruction. To tackle this novel problem, we develop three different trainable models based on RNN and Generative Adversarial Network (GAN). The models (bucket, filter bank, and end-to-end) differ in how much expert knowledge is encoded, with the most general version being purely end-to-end. To train these systems, we use Amazon Mechanical Turk to collect textual descriptions for around 2000 image pairs sampled from several datasets. Experimental results evaluated on our dataset validate our approaches. In addition, given that the filter bank model is a good compromise between generality and performance, we investigate it further by replacing RNN with Graph RNN, and show that Graph RNN improves performance. To the best of our knowledge, this is the first computational photography work on global image editing that is purely based on free-form textual instructions.
On the Learning Dynamics of Two-layer Nonlinear Convolutional Neural Networks
May 24, 2019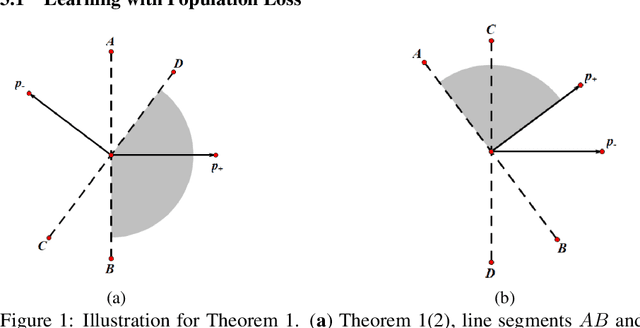
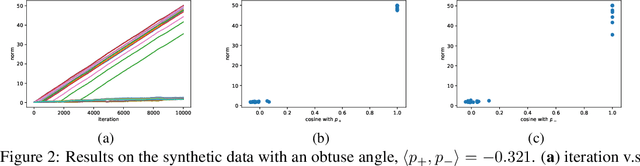
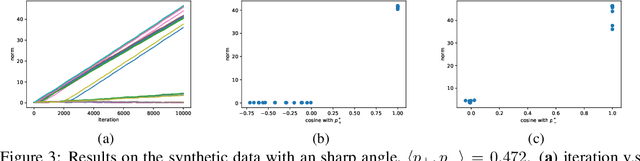

Convolutional neural networks (CNNs) have achieved remarkable performance in various fields, particularly in the domain of computer vision. However, why this architecture works well remains to be a mystery. In this work we move a small step toward understanding the success of CNNs by investigating the learning dynamics of a two-layer nonlinear convolutional neural network over some specific data distributions. Rather than the typical Gaussian assumption for input data distribution, we consider a more realistic setting that each data point (e.g. image) contains a specific pattern determining its class label. Within this setting, we both theoretically and empirically show that some convolutional filters will learn the key patterns in data and the norm of these filters will dominate during the training process with stochastic gradient descent. And with any high probability, when the number of iterations is sufficiently large, the CNN model could obtain 100% accuracy over the considered data distributions. Our experiments demonstrate that for practical image classification tasks our findings still hold to some extent.
Visual Localization Using Sparse Semantic 3D Map
Apr 08, 2019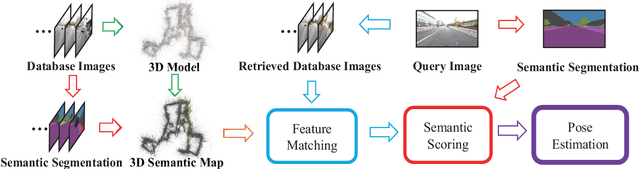
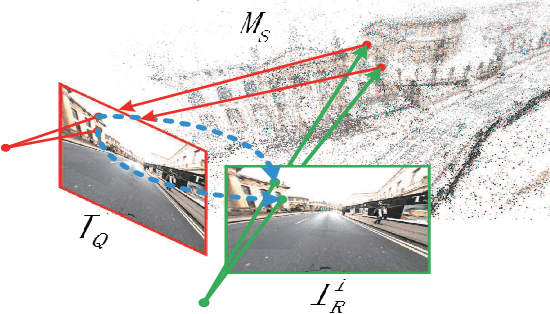

Accurate and robust visual localization under a wide range of viewing condition variations including season and illumination changes, as well as weather and day-night variations, is the key component for many computer vision and robotics applications. Under these conditions, most traditional methods would fail to locate the camera. In this paper we present a visual localization algorithm that combines structure-based method and image-based method with semantic information. Given semantic information about the query and database images, the retrieved images are scored according to the semantic consistency of the 3D model and the query image. Then the semantic matching score is used as weight for RANSAC's sampling and the pose is solved by a standard PnP solver. Experiments on the challenging long-term visual localization benchmark dataset demonstrate that our method has significant improvement compared with the state-of-the-arts.
RoIMix: Proposal-Fusion among Multiple Images for Underwater Object Detection
Nov 08, 2019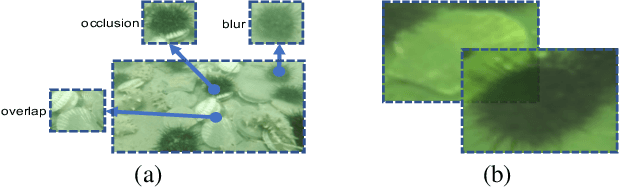

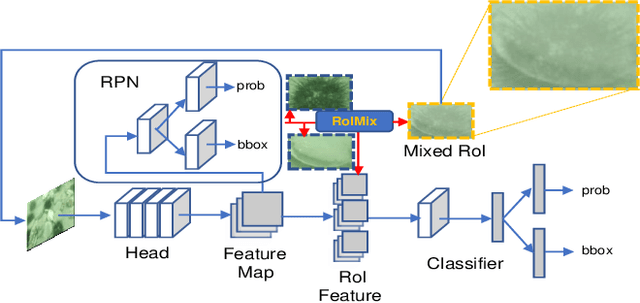

Generic object detection algorithms have proven their excellent performance in recent years. However, object detection on underwater datasets is still less explored. In contrast to generic datasets, underwater images usually have color shift and low contrast; sediment would cause blurring in underwater images. In addition, underwater creatures often appear closely to each other on images due to their living habits. To address these issues, our work investigates augmentation policies to simulate overlapping, occluded and blurred objects, and we construct a model capable of achieving better generalization. We propose an augmentation method called RoIMix, which characterizes interactions among images. Proposals extracted from different images are mixed together. Previous data augmentation methods operate on a single image while we apply RoIMix to multiple images to create enhanced samples as training data. Experiments show that our proposed method improves the performance of region-based object detectors on both Pascal VOC and URPC datasets.