 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
An Algorithm for the Visualization of Relevant Patterns in Astronomical Light Curves
Mar 08, 2019
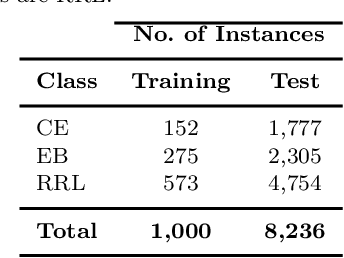

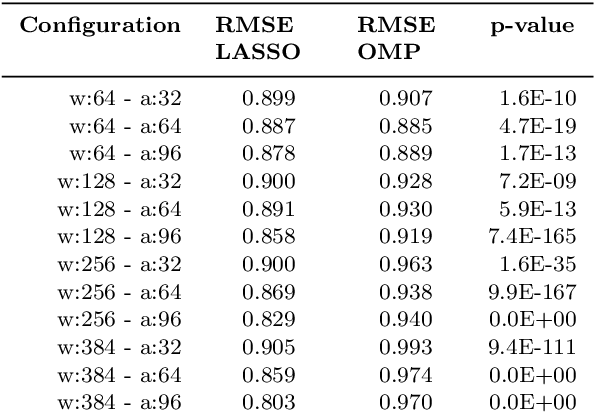
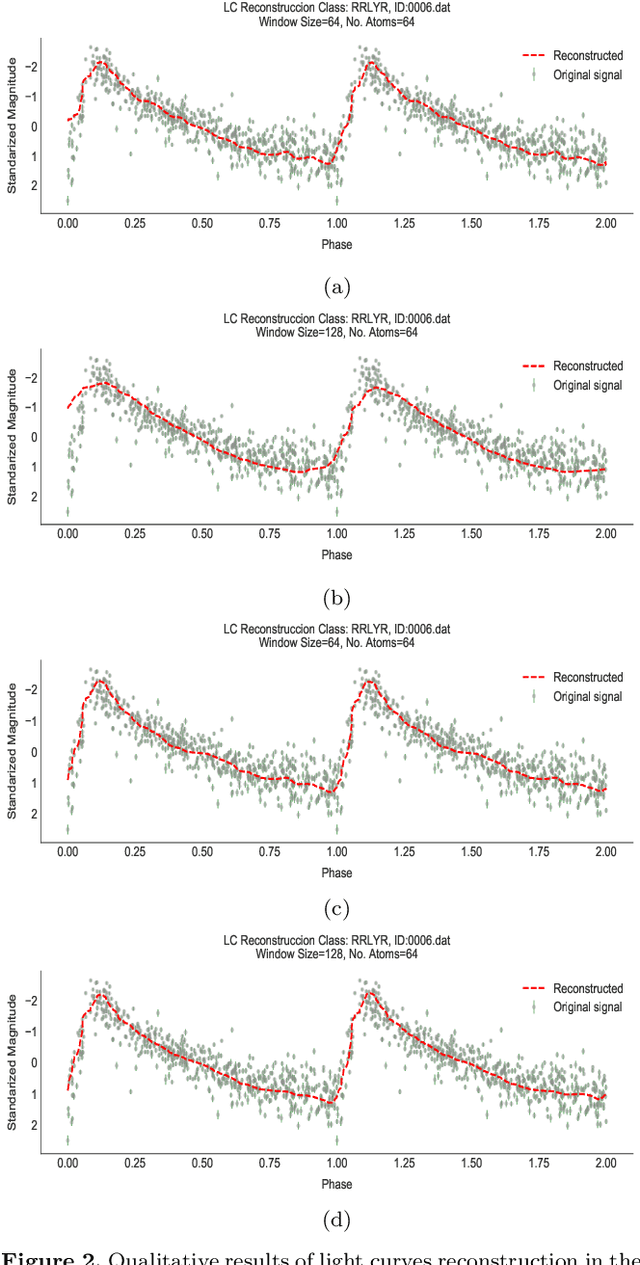
Within the last years, the classification of variable stars with Machine Learning has become a mainstream area of research. Recently, visualization of time series is attracting more attention in data science as a tool to visually help scientists to recognize significant patterns in complex dynamics. Within the Machine Learning literature, dictionary-based methods have been widely used to encode relevant parts of image data. These methods intrinsically assign a degree of importance to patches in pictures, according to their contribution in the image reconstruction. Inspired by dictionary-based techniques, we present an approach that naturally provides the visualization of salient parts in astronomical light curves, making the analogy between image patches and relevant pieces in time series. Our approach encodes the most meaningful patterns such that we can approximately reconstruct light curves by just using the encoded information. We test our method in light curves from the OGLE-III and StarLight databases. Our results show that the proposed model delivers an automatic and intuitive visualization of relevant light curve parts, such as local peaks and drops in magnitude.
* Accepted 2019 January 8. Received 2019 January 8; in original form 2018 January 29. 7 pages, 6 figures
Dynamic texture and scene classification by transferring deep image features
Feb 01, 2015
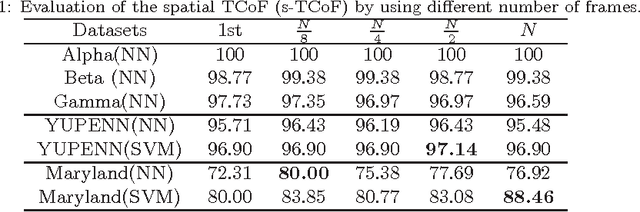
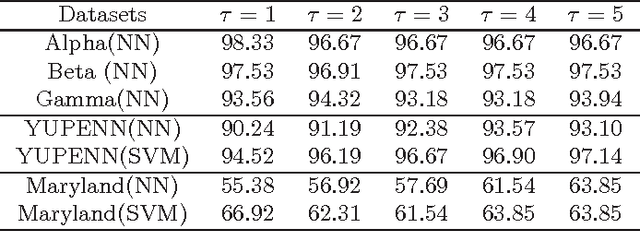
Dynamic texture and scene classification are two fundamental problems in understanding natural video content. Extracting robust and effective features is a crucial step towards solving these problems. However the existing approaches suffer from the sensitivity to either varying illumination, or viewpoint changing, or even camera motion, and/or the lack of spatial information. Inspired by the success of deep structures in image classification, we attempt to leverage a deep structure to extract feature for dynamic texture and scene classification. To tackle with the challenges in training a deep structure, we propose to transfer some prior knowledge from image domain to video domain. To be specific, we propose to apply a well-trained Convolutional Neural Network (ConvNet) as a mid-level feature extractor to extract features from each frame, and then form a representation of a video by concatenating the first and the second order statistics over the mid-level features. We term this two-level feature extraction scheme as a Transferred ConvNet Feature (TCoF). Moreover we explore two different implementations of the TCoF scheme, i.e., the \textit{spatial} TCoF and the \textit{temporal} TCoF, in which the mean-removed frames and the difference between two adjacent frames are used as the inputs of the ConvNet, respectively. We evaluate systematically the proposed spatial TCoF and the temporal TCoF schemes on three benchmark data sets, including DynTex, YUPENN, and Maryland, and demonstrate that the proposed approach yields superior performance.
Decoupled Attention Network for Text Recognition
Dec 21, 2019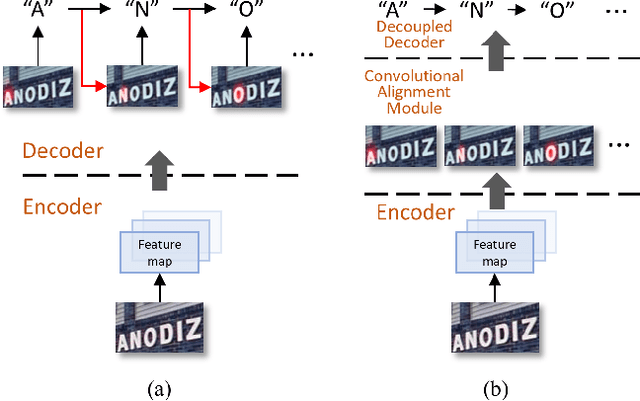
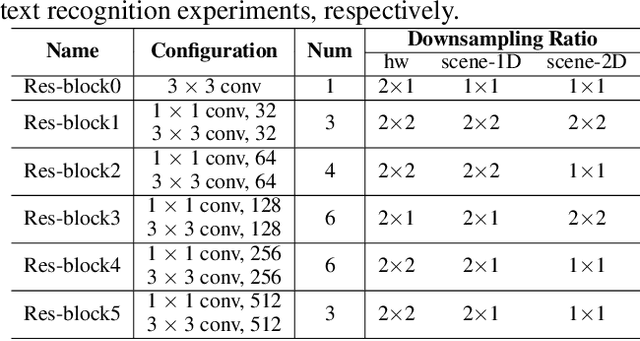
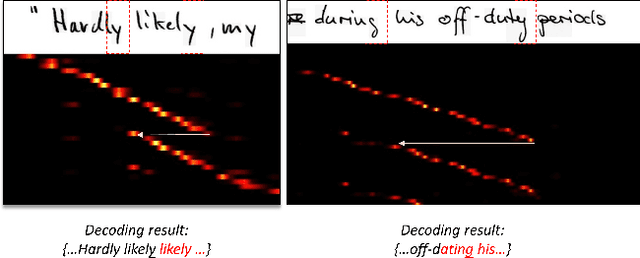
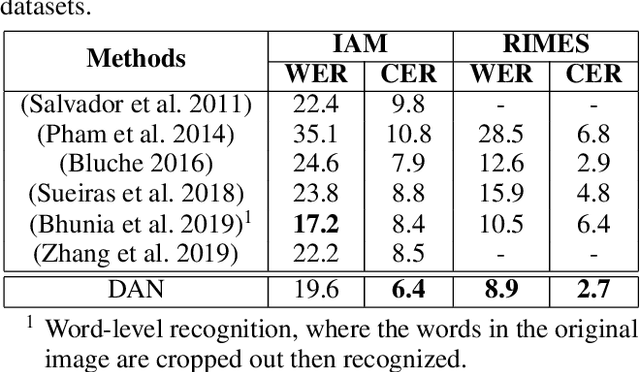
Text recognition has attracted considerable research interests because of its various applications. The cutting-edge text recognition methods are based on attention mechanisms. However, most of attention methods usually suffer from serious alignment problem due to its recurrency alignment operation, where the alignment relies on historical decoding results. To remedy this issue, we propose a decoupled attention network (DAN), which decouples the alignment operation from using historical decoding results. DAN is an effective, flexible and robust end-to-end text recognizer, which consists of three components: 1) a feature encoder that extracts visual features from the input image; 2) a convolutional alignment module that performs the alignment operation based on visual features from the encoder; and 3) a decoupled text decoder that makes final prediction by jointly using the feature map and attention maps. Experimental results show that DAN achieves state-of-the-art performance on multiple text recognition tasks, including offline handwritten text recognition and regular/irregular scene text recognition.
Improving STDP-based Visual Feature Learning with Whitening
Feb 24, 2020
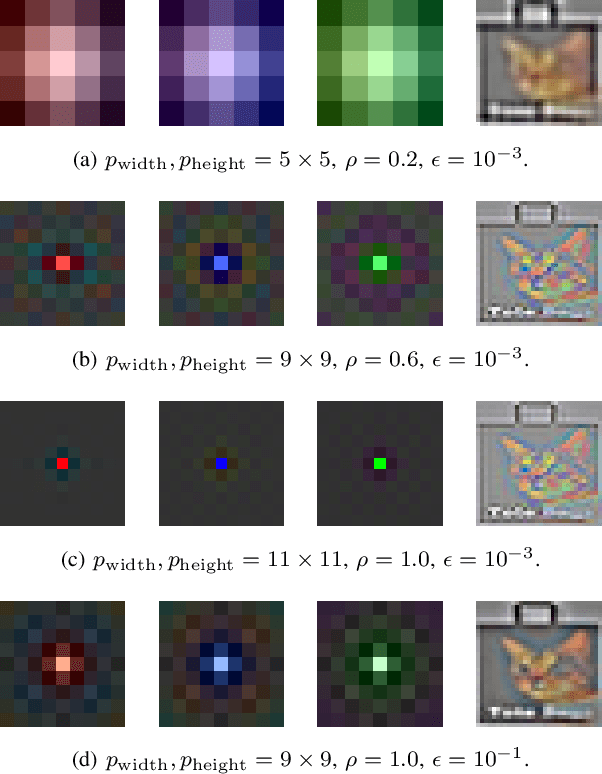
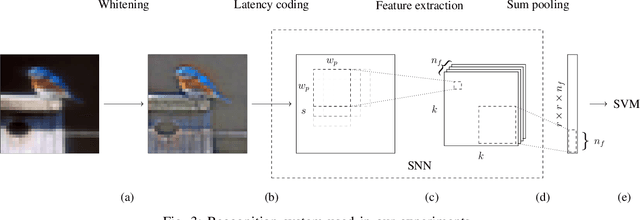
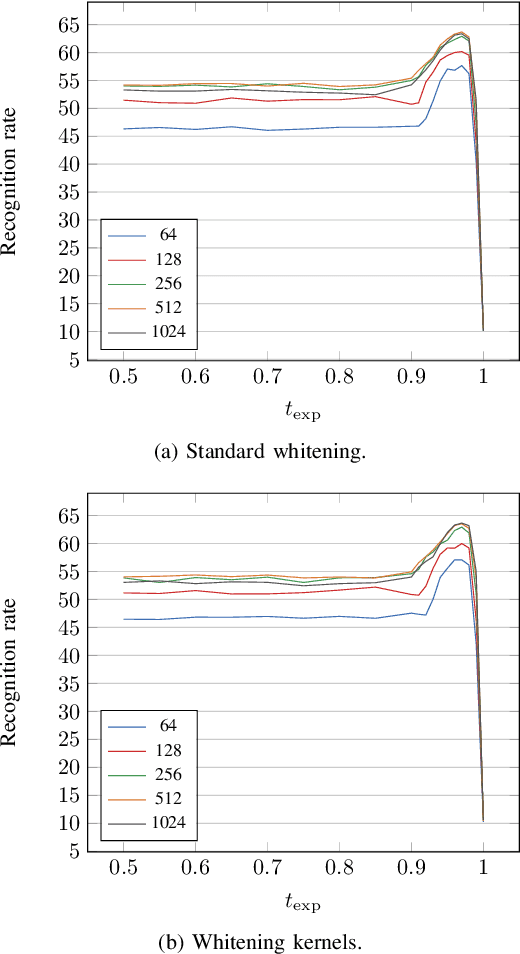
In recent years, spiking neural networks (SNNs) emerge as an alternative to deep neural networks (DNNs). SNNs present a higher computational efficiency using low-power neuromorphic hardware and require less labeled data for training using local and unsupervised learning rules such as spike timing-dependent plasticity (STDP). SNN have proven their effectiveness in image classification on simple datasets such as MNIST. However, to process natural images, a pre-processing step is required. Difference-of-Gaussians (DoG) filtering is typically used together with on-center/off-center coding, but it results in a loss of information that is detrimental to the classification performance. In this paper, we propose to use whitening as a pre-processing step before learning features with STDP. Experiments on CIFAR-10 show that whitening allows STDP to learn visual features that are closer to the ones learned with standard neural networks, with a significantly increased classification performance as compared to DoG filtering. We also propose an approximation of whitening as convolution kernels that is computationally cheaper to learn and more suited to be implemented on neuromorphic hardware. Experiments on CIFAR-10 show that it performs similarly to regular whitening. Cross-dataset experiments on CIFAR-10 and STL-10 also show that it is fairly stable across datasets, making it possible to learn a single whitening transformation to process different datasets.
Kite: Automatic speech recognition for unmanned aerial vehicles
Jul 02, 2019
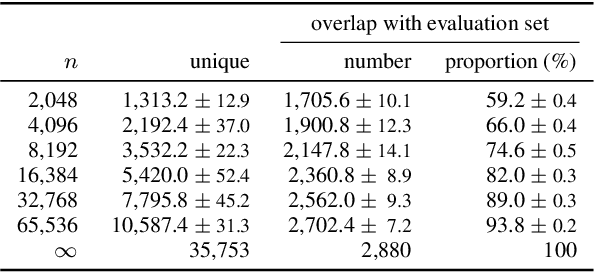
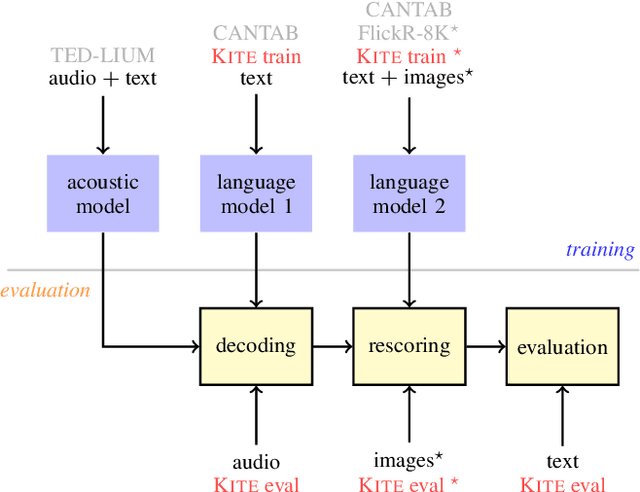
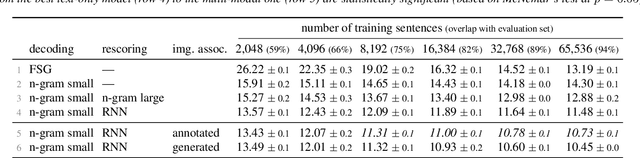
This paper addresses the problem of building a speech recognition system attuned to the control of unmanned aerial vehicles (UAVs). Even though UAVs are becoming widespread, the task of creating voice interfaces for them is largely unaddressed. To this end, we introduce a multi-modal evaluation dataset for UAV control, consisting of spoken commands and associated images, which represent the visual context of what the UAV "sees" when the pilot utters the command. We provide baseline results and address two research directions: (i) how robust the language models are, given an incomplete list of commands at train time; (ii) how to incorporate visual information in the language model. We find that recurrent neural networks (RNNs) are a solution to both tasks: they can be successfully adapted using a small number of commands and they can be extended to use visual cues. Our results show that the image-based RNN outperforms its text-only counterpart even if the command-image training associations are automatically generated and inherently imperfect. The dataset and our code are available at http://kite.speed.pub.ro.
Drop to Adapt: Learning Discriminative Features for Unsupervised Domain Adaptation
Oct 12, 2019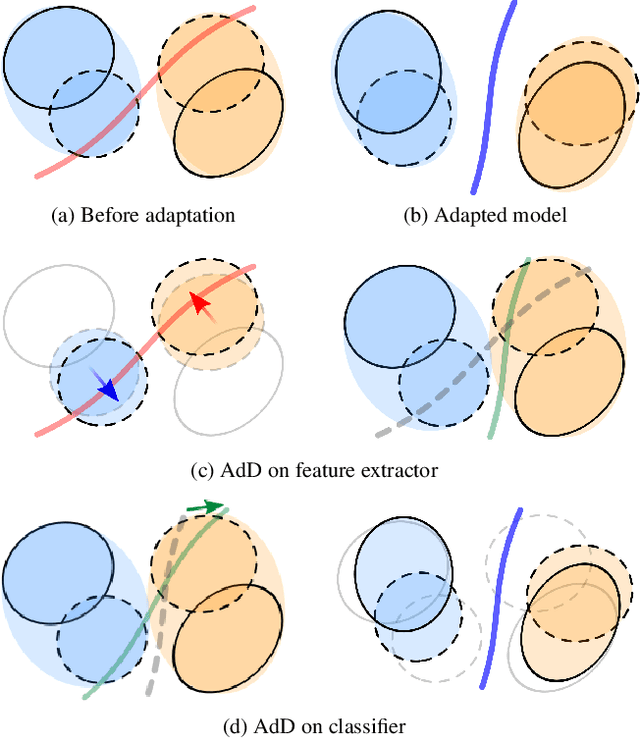
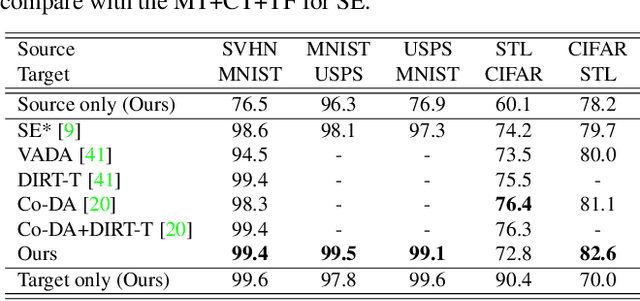
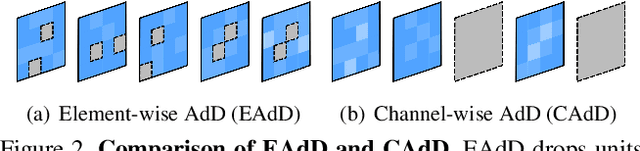
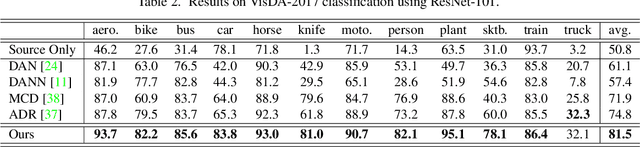
Recent works on domain adaptation exploit adversarial training to obtain domain-invariant feature representations from the joint learning of feature extractor and domain discriminator networks. However, domain adversarial methods render suboptimal performances since they attempt to match the distributions among the domains without considering the task at hand. We propose Drop to Adapt (DTA), which leverages adversarial dropout to learn strongly discriminative features by enforcing the cluster assumption. Accordingly, we design objective functions to support robust domain adaptation. We demonstrate efficacy of the proposed method on various experiments and achieve consistent improvements in both image classification and semantic segmentation tasks. Our source code is available at https://github.com/postBG/DTA.pytorch.
Memory-efficient and fast implementation of local adaptive binarization methods
May 30, 2019

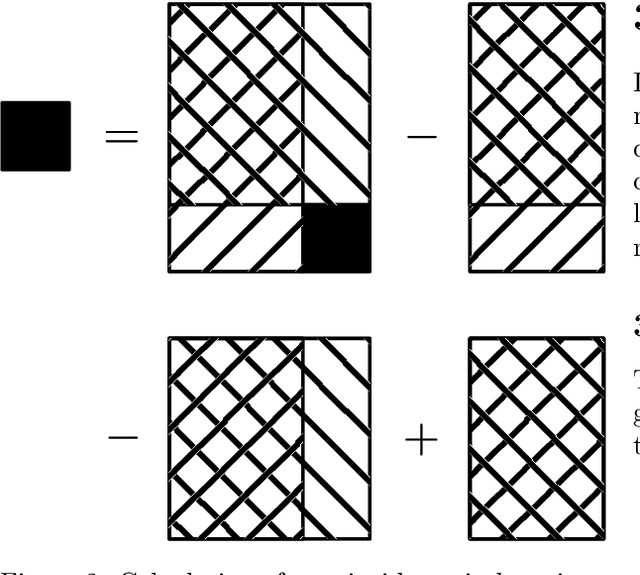
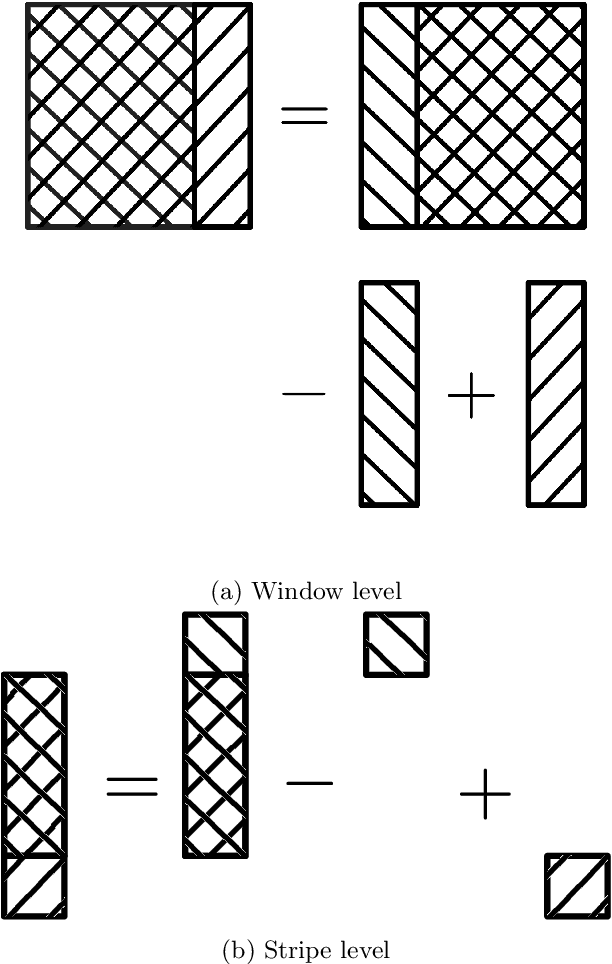
Binarization is widely used as an image preprocessing step to separate object especially text from background before recognition. For noisy images with uneven illumination, threshold values should be computed pixel by pixel to obtain a good segmentation. Since local threshold values typically depend on moments-based statistics such as mean and variance of gray levels inside rectangular windows, integral images are commonly used to accelerate the calculation. However, integral images are memory consuming. For Sauvola's method, the two integral images occupy $16HW$ bytes given a $H\times W$ input image. By using a recursive technique to avoid integral images, memory usage of intermediate data structures can be reduced significantly to $6\min\{H,W\}$ bytes, while the time complexity remains $O(HW)$ independent of window size. Therefore, the proposed implementation enable various local adaptive binarization methods to be applied in real-time use cases on devices with limited resources.
Chargrid-OCR: End-to-end trainable Optical Character Recognition through Semantic Segmentation and Object Detection
Sep 13, 2019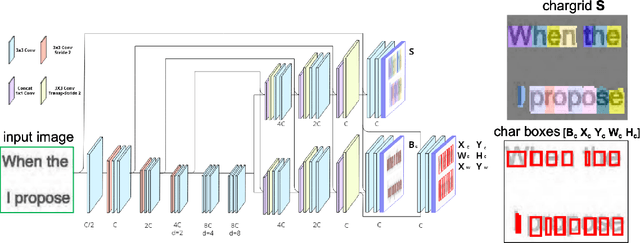
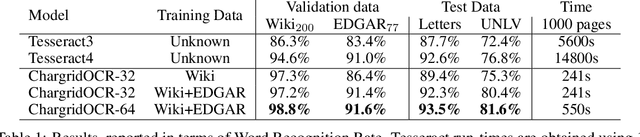

We present an end-to-end trainable approach for optical character recognition (OCR) on printed documents. It is based on predicting a two-dimensional character grid (\emph{chargrid}) representation of a document image as a semantic segmentation task. To identify individual character instances from the chargrid, we regard characters as objects and use object detection techniques from computer vision. We demonstrate experimentally that our method outperforms previous state-of-the-art approaches in accuracy while being easily parallelizable on GPU (therefore being significantly faster), as well as easier to train.
ABBA: Saliency-Regularized Motion-Based Adversarial Blur Attack
Feb 10, 2020
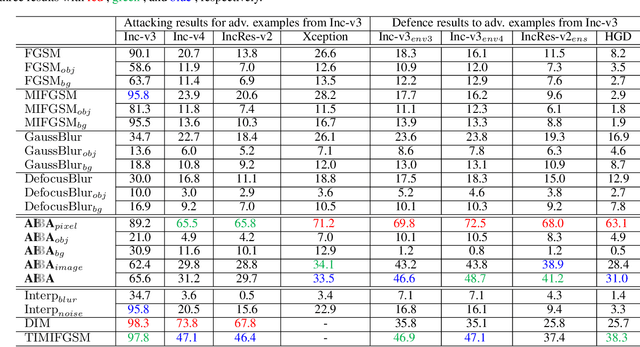

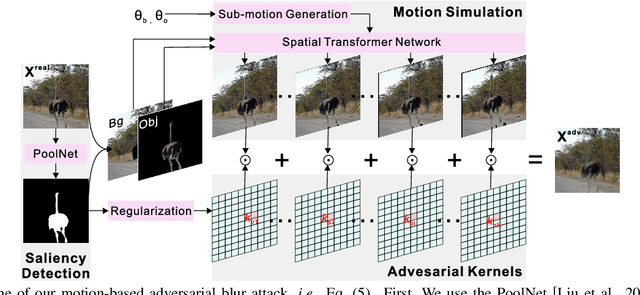
Deep neural networks are vulnerable to noise-based adversarial examples, which can mislead the networks by adding random-like noise. However, such examples are hardly found in the real world and easily perceived when thumping noises are used to keep their high transferability across different models. In this paper, we identify a new attacking method termed motion-based adversarial blur attack (ABBA) that can generate visually natural motion-blurred adversarial examples even with relatively high perturbation, allowing much better transferability than noise-based methods. To this end, we first formulate the kernel-prediction-based attack where an input image is convolved with kernels in a pixel-wise way, and the misclassification capability is achieved by tuning the kernel weights. To generate visually more natural and plausible examples, we further propose the saliency-regularized adversarial kernel prediction where the salient region serves as a moving object, and the predicted kernel is regularized to achieve naturally visual effects. Besides, the attack can be further enhanced by adaptively tuning the translations of object and background. Extensive experimental results on the NeurIPS'17 adversarial competition dataset validate the effectiveness of ABBA by considering various kernel sizes, translations, and regions. Furthermore, we study the effects of state-of-the-art GAN-based deblurring mechanisms to our methods.
Detecting Parking Spaces in a Parcel using Satellite Images
Aug 28, 2019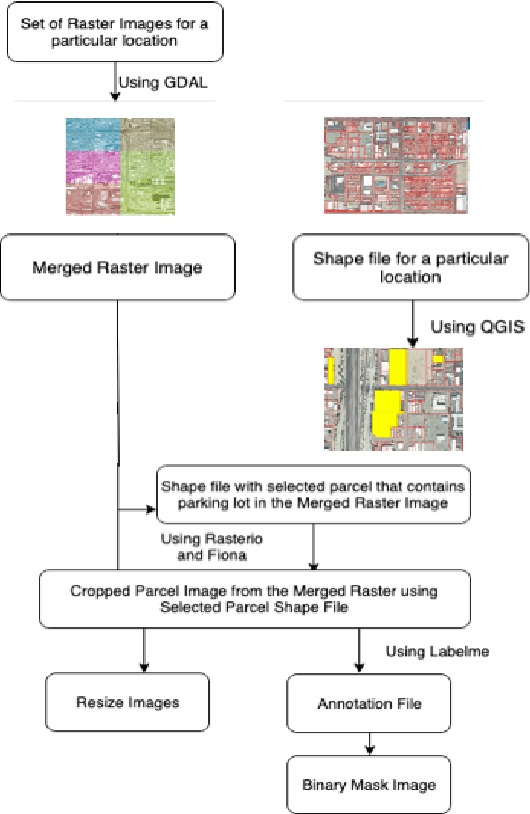
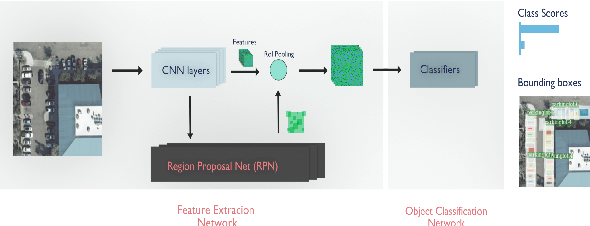
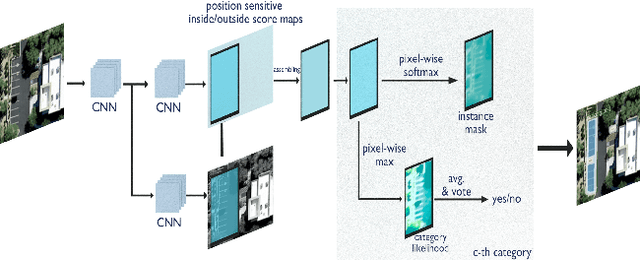
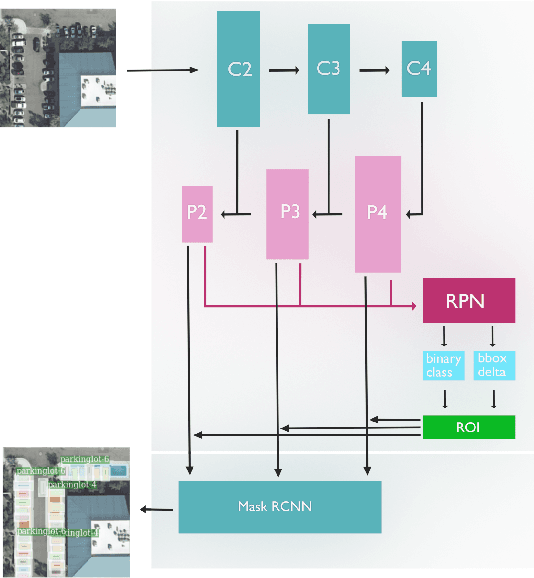
Remote Sensing Images from satellites have been used in various domains for detecting and understanding structures on the ground surface. In this work, satellite images were used for localizing parking spaces and vehicles in parking lots for a given parcel using an RCNN based Neural Network Architectures. Parcel shapefiles and raster images from USGS image archive were used for developing images for both training and testing. Feature Pyramid based Mask RCNN yields average class accuracy of 97.56% for both parking spaces and vehicles