 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConTextTab: A Semantics-Aware Tabular In-Context Learner
Jun 12, 2025Tabular in-context learning (ICL) has recently achieved state-of-the-art (SOTA) performance on several tabular prediction tasks. Previously restricted to classification problems on small tables, recent advances such as TabPFN and TabICL have extended its use to larger datasets. While being architecturally efficient and well-adapted to tabular data structures, current table-native ICL architectures, being trained exclusively on synthetic data, do not fully leverage the rich semantics and world knowledge contained in real-world tabular data. On another end of this spectrum, tabular ICL models based on pretrained large language models such as TabuLa-8B integrate deep semantic understanding and world knowledge but are only able to make use of a small amount of context due to inherent architectural limitations. With the aim to combine the best of both these worlds, we introduce ConTextTab, integrating semantic understanding and alignment into a table-native ICL framework. By employing specialized embeddings for different data modalities and by training on large-scale real-world tabular data, our model is competitive with SOTA across a broad set of benchmarks while setting a new standard on the semantically rich CARTE benchmark.
PORTAL: Scalable Tabular Foundation Models via Content-Specific Tokenization
Oct 17, 2024



Self-supervised learning on tabular data seeks to apply advances from natural language and image domains to the diverse domain of tables. However, current techniques often struggle with integrating multi-domain data and require data cleaning or specific structural requirements, limiting the scalability of pre-training datasets. We introduce PORTAL (Pretraining One-Row-at-a-Time for All tabLes), a framework that handles various data modalities without the need for cleaning or preprocessing. This simple yet powerful approach can be effectively pre-trained on online-collected datasets and fine-tuned to match state-of-the-art methods on complex classification and regression tasks. This work offers a practical advancement in self-supervised learning for large-scale tabular data.
ClusterTabNet: Supervised clustering method for table detection and table structure recognition
Feb 12, 2024



We present a novel deep-learning-based method to cluster words in documents which we apply to detect and recognize tables given the OCR output. We interpret table structure bottom-up as a graph of relations between pairs of words (belonging to the same row, column, header, as well as to the same table) and use a transformer encoder model to predict its adjacency matrix. We demonstrate the performance of our method on the PubTables-1M dataset as well as PubTabNet and FinTabNet datasets. Compared to the current state-of-the-art detection methods such as DETR and Faster R-CNN, our method achieves similar or better accuracy, while requiring a significantly smaller model.
Chargrid-OCR: End-to-end trainable Optical Character Recognition through Semantic Segmentation and Object Detection
Sep 13, 2019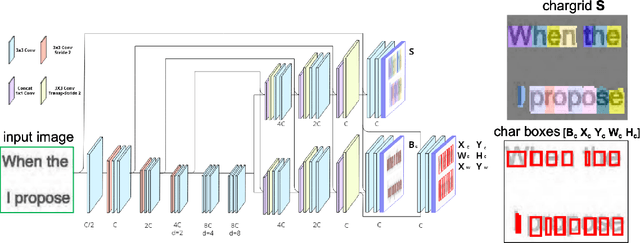
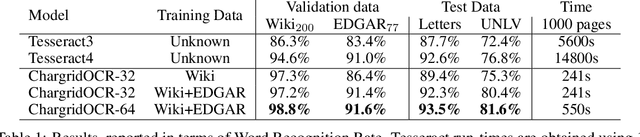

We present an end-to-end trainable approach for optical character recognition (OCR) on printed documents. It is based on predicting a two-dimensional character grid (\emph{chargrid}) representation of a document image as a semantic segmentation task. To identify individual character instances from the chargrid, we regard characters as objects and use object detection techniques from computer vision. We demonstrate experimentally that our method outperforms previous state-of-the-art approaches in accuracy while being easily parallelizable on GPU (therefore being significantly faster), as well as easier to train.