 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA self-regulated convolutional neural network for classifying variable stars
May 20, 2025Over the last two decades, machine learning models have been widely applied and have proven effective in classifying variable stars, particularly with the adoption of deep learning architectures such as convolutional neural networks, recurrent neural networks, and transformer models. While these models have achieved high accuracy, they require high-quality, representative data and a large number of labelled samples for each star type to generalise well, which can be challenging in time-domain surveys. This challenge often leads to models learning and reinforcing biases inherent in the training data, an issue that is not easily detectable when validation is performed on subsamples from the same catalogue. The problem of biases in variable star data has been largely overlooked, and a definitive solution has yet to be established. In this paper, we propose a new approach to improve the reliability of classifiers in variable star classification by introducing a self-regulated training process. This process utilises synthetic samples generated by a physics-enhanced latent space variational autoencoder, incorporating six physical parameters from Gaia Data Release 3. Our method features a dynamic interaction between a classifier and a generative model, where the generative model produces ad-hoc synthetic light curves to reduce confusion during classifier training and populate underrepresented regions in the physical parameter space. Experiments conducted under various scenarios demonstrate that our self-regulated training approach outperforms traditional training methods for classifying variable stars on biased datasets, showing statistically significant improvements.
Improved Uncertainty Quantification in Physics-Informed Neural Networks Using Error Bounds and Solution Bundles
May 09, 2025



Physics-Informed Neural Networks (PINNs) have been widely used to obtain solutions to various physical phenomena modeled as Differential Equations. As PINNs are not naturally equipped with mechanisms for Uncertainty Quantification, some work has been done to quantify the different uncertainties that arise when dealing with PINNs. In this paper, we use a two-step procedure to train Bayesian Neural Networks that provide uncertainties over the solutions to differential equation systems provided by PINNs. We use available error bounds over PINNs to formulate a heteroscedastic variance that improves the uncertainty estimation. Furthermore, we solve forward problems and utilize the obtained uncertainties when doing parameter estimation in inverse problems in cosmology.
Exoplanet Transit Candidate Identification in TESS Full-Frame Images via a Transformer-Based Algorithm
Feb 11, 2025The Transiting Exoplanet Survey Satellite (TESS) is surveying a large fraction of the sky, generating a vast database of photometric time series data that requires thorough analysis to identify exoplanetary transit signals. Automated learning approaches have been successfully applied to identify transit signals. However, most existing methods focus on the classification and validation of candidates, while few efforts have explored new techniques for the search of candidates. To search for new exoplanet transit candidates, we propose an approach to identify exoplanet transit signals without the need for phase folding or assuming periodicity in the transit signals, such as those observed in multi-transit light curves. To achieve this, we implement a new neural network inspired by Transformers to directly process Full Frame Image (FFI) light curves to detect exoplanet transits. Transformers, originally developed for natural language processing, have recently demonstrated significant success in capturing long-range dependencies compared to previous approaches focused on sequential data. This ability allows us to employ multi-head self-attention to identify exoplanet transit signals directly from the complete light curves, combined with background and centroid time series, without requiring prior transit parameters. The network is trained to learn characteristics of the transit signal, like the dip shape, which helps distinguish planetary transits from other variability sources. Our model successfully identified 214 new planetary system candidates, including 122 multi-transit light curves, 88 single-transit and 4 multi-planet systems from TESS sectors 1-26 with a radius > 0.27 $R_{\mathrm{Jupiter}}$, demonstrating its ability to detect transits regardless of their periodicity.
Distinguishing a planetary transit from false positives: a Transformer-based classification for planetary transit signals
Apr 27, 2023Current space-based missions, such as the Transiting Exoplanet Survey Satellite (TESS), provide a large database of light curves that must be analysed efficiently and systematically. In recent years, deep learning (DL) methods, particularly convolutional neural networks (CNN), have been used to classify transit signals of candidate exoplanets automatically. However, CNNs have some drawbacks; for example, they require many layers to capture dependencies on sequential data, such as light curves, making the network so large that it eventually becomes impractical. The self-attention mechanism is a DL technique that attempts to mimic the action of selectively focusing on some relevant things while ignoring others. Models, such as the Transformer architecture, were recently proposed for sequential data with successful results. Based on these successful models, we present a new architecture for the automatic classification of transit signals. Our proposed architecture is designed to capture the most significant features of a transit signal and stellar parameters through the self-attention mechanism. In addition to model prediction, we take advantage of attention map inspection, obtaining a more interpretable DL approach. Thus, we can identify the relevance of each element to differentiate a transit signal from false positives, simplifying the manual examination of candidates. We show that our architecture achieves competitive results concerning the CNNs applied for recognizing exoplanetary transit signals in data from the TESS telescope. Based on these results, we demonstrate that applying this state-of-the-art DL model to light curves can be a powerful technique for transit signal detection while offering a level of interpretability.
Informative regularization for a multi-layer perceptron RR Lyrae classifier under data shift
Mar 12, 2023



In recent decades, machine learning has provided valuable models and algorithms for processing and extracting knowledge from time-series surveys. Different classifiers have been proposed and performed to an excellent standard. Nevertheless, few papers have tackled the data shift problem in labeled training sets, which occurs when there is a mismatch between the data distribution in the training set and the testing set. This drawback can damage the prediction performance in unseen data. Consequently, we propose a scalable and easily adaptable approach based on an informative regularization and an ad-hoc training procedure to mitigate the shift problem during the training of a multi-layer perceptron for RR Lyrae classification. We collect ranges for characteristic features to construct a symbolic representation of prior knowledge, which was used to model the informative regularizer component. Simultaneously, we design a two-step back-propagation algorithm to integrate this knowledge into the neural network, whereby one step is applied in each epoch to minimize classification error, while another is applied to ensure regularization. Our algorithm defines a subset of parameters (a mask) for each loss function. This approach handles the forgetting effect, which stems from a trade-off between these loss functions (learning from data versus learning expert knowledge) during training. Experiments were conducted using recently proposed shifted benchmark sets for RR Lyrae stars, outperforming baseline models by up to 3\% through a more reliable classifier. Our method provides a new path to incorporate knowledge from characteristic features into artificial neural networks to manage the underlying data shift problem.
Error-Aware B-PINNs: Improving Uncertainty Quantification in Bayesian Physics-Informed Neural Networks
Dec 14, 2022



Physics-Informed Neural Networks (PINNs) are gaining popularity as a method for solving differential equations. While being more feasible in some contexts than the classical numerical techniques, PINNs still lack credibility. A remedy for that can be found in Uncertainty Quantification (UQ) which is just beginning to emerge in the context of PINNs. Assessing how well the trained PINN complies with imposed differential equation is the key to tackling uncertainty, yet there is lack of comprehensive methodology for this task. We propose a framework for UQ in Bayesian PINNs (B-PINNs) that incorporates the discrepancy between the B-PINN solution and the unknown true solution. We exploit recent results on error bounds for PINNs on linear dynamical systems and demonstrate the predictive uncertainty on a class of linear ODEs.
Uncertainty Quantification in Neural Differential Equations
Nov 08, 2021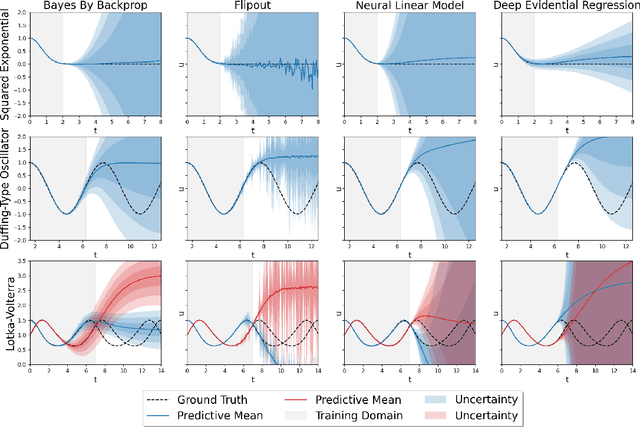

Uncertainty quantification (UQ) helps to make trustworthy predictions based on collected observations and uncertain domain knowledge. With increased usage of deep learning in various applications, the need for efficient UQ methods that can make deep models more reliable has increased as well. Among applications that can benefit from effective handling of uncertainty are the deep learning based differential equation (DE) solvers. We adapt several state-of-the-art UQ methods to get the predictive uncertainty for DE solutions and show the results on four different DE types.
Classifying CMB time-ordered data through deep neural networks
Apr 13, 2020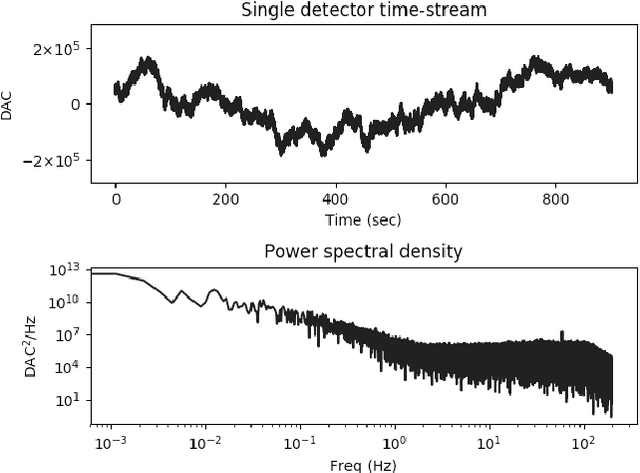
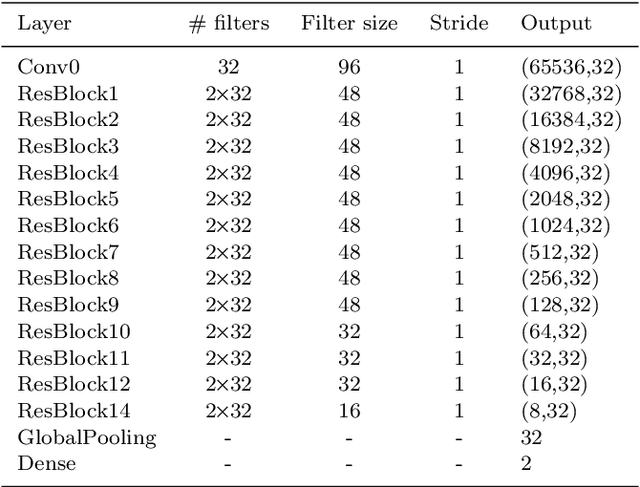
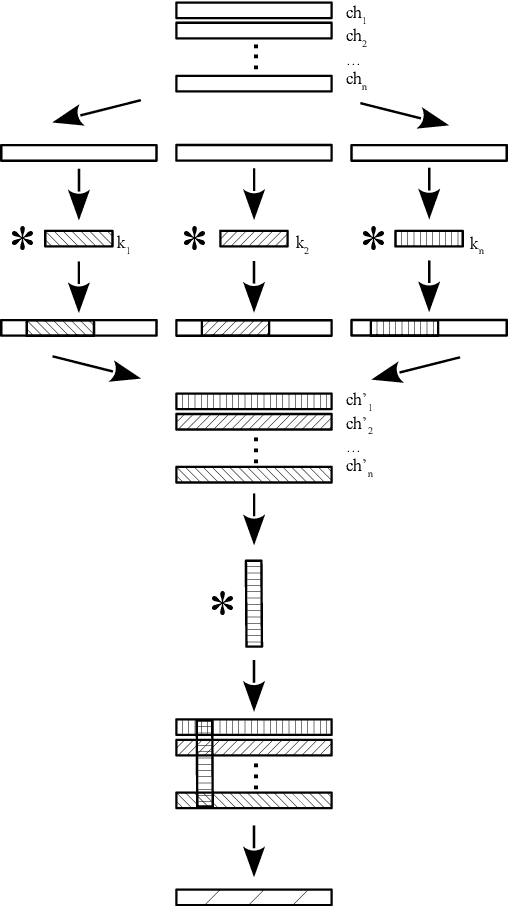
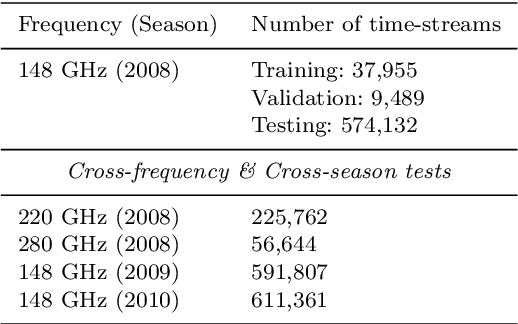
The Cosmic Microwave Background (CMB) has been measured over a wide range of multipoles. Experiments with arc-minute resolution like the Atacama Cosmology Telescope (ACT) have contributed to the measurement of primary and secondary anisotropies, leading to remarkable scientific discoveries. Such findings require careful data selection in order to remove poorly-behaved detectors and unwanted contaminants. The current data classification methodology used by ACT relies on several statistical parameters that are assessed and fine-tuned by an expert. This method is highly time-consuming and band or season-specific, which makes it less scalable and efficient for future CMB experiments. In this work, we propose a supervised machine learning model to classify detectors of CMB experiments. The model corresponds to a deep convolutional neural network. We tested our method on real ACT data, using the 2008 season, 148 GHz, as training set with labels provided by the ACT data selection software. The model learns to classify time-streams starting directly from the raw data. For the season and frequency considered during the training, we find that our classifier reaches a precision of 99.8%. For 220 and 280 GHz data, season 2008, we obtained 99.4% and 97.5% of precision, respectively. Finally, we performed a cross-season test over 148 GHz data from 2009 and 2010 for which our model reaches a precision of 99.8% and 99.5%, respectively. Our model is about 10x faster than the current pipeline, making it potentially suitable for real-time implementations.
Scalable End-to-end Recurrent Neural Network for Variable star classification
Feb 03, 2020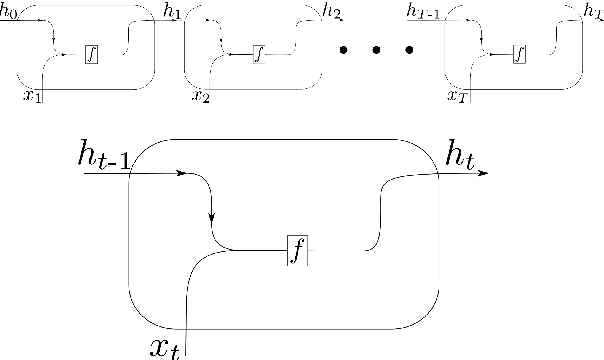

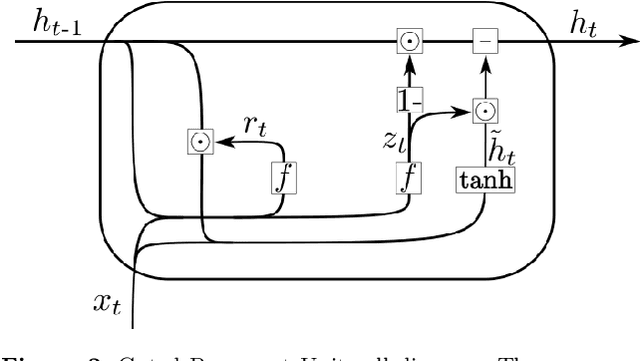
During the last decade, considerable effort has been made to perform automatic classification of variable stars using machine learning techniques. Traditionally, light curves are represented as a vector of descriptors or features used as input for many algorithms. Some features are computationally expensive, cannot be updated quickly and hence for large datasets such as the LSST cannot be applied. Previous work has been done to develop alternative unsupervised feature extraction algorithms for light curves, but the cost of doing so still remains high. In this work, we propose an end-to-end algorithm that automatically learns the representation of light curves that allows an accurate automatic classification. We study a series of deep learning architectures based on Recurrent Neural Networks and test them in automated classification scenarios. Our method uses minimal data preprocessing, can be updated with a low computational cost for new observations and light curves, and can scale up to massive datasets. We transform each light curve into an input matrix representation whose elements are the differences in time and magnitude, and the outputs are classification probabilities. We test our method in three surveys: OGLE-III, Gaia and WISE. We obtain accuracies of about $95\%$ in the main classes and $75\%$ in the majority of subclasses. We compare our results with the Random Forest classifier and obtain competitive accuracies while being faster and scalable. The analysis shows that the computational complexity of our approach grows up linearly with the light curve size, while the traditional approach cost grows as $N\log{(N)}$.
Streaming Classification of Variable Stars
Dec 04, 2019
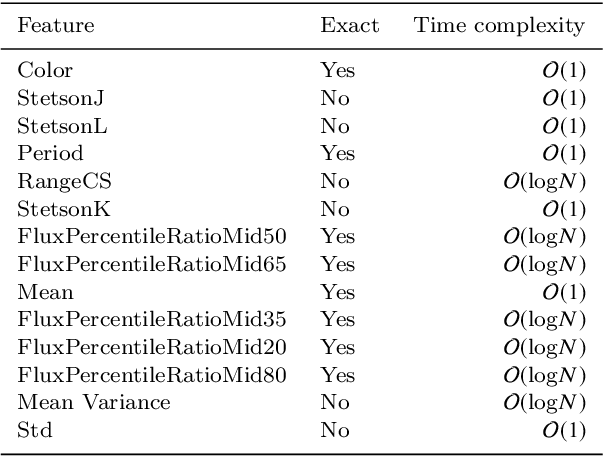
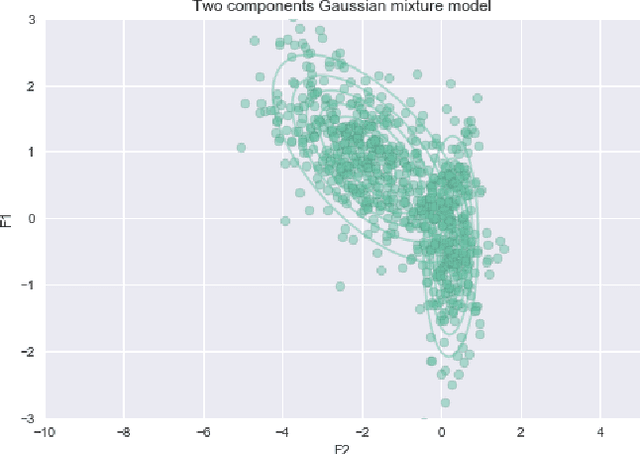
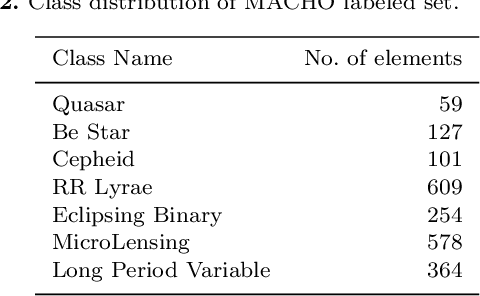
In the last years, automatic classification of variable stars has received substantial attention. Using machine learning techniques for this task has proven to be quite useful. Typically, machine learning classifiers used for this task require to have a fixed training set, and the training process is performed offline. Upcoming surveys such as the Large Synoptic Survey Telescope (LSST) will generate new observations daily, where an automatic classification system able to create alerts online will be mandatory. A system with those characteristics must be able to update itself incrementally. Unfortunately, after training, most machine learning classifiers do not support the inclusion of new observations in light curves, they need to re-train from scratch. Naively re-training from scratch is not an option in streaming settings, mainly because of the expensive pre-processing routines required to obtain a vector representation of light curves (features) each time we include new observations. In this work, we propose a streaming probabilistic classification model; it uses a set of newly designed features that work incrementally. With this model, we can have a machine learning classifier that updates itself in real time with new observations. To test our approach, we simulate a streaming scenario with light curves from CoRot, OGLE and MACHO catalogs. Results show that our model achieves high classification performance, staying an order of magnitude faster than traditional classification approaches.