 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
GILT: Generating Images from Long Text
Jan 08, 2019

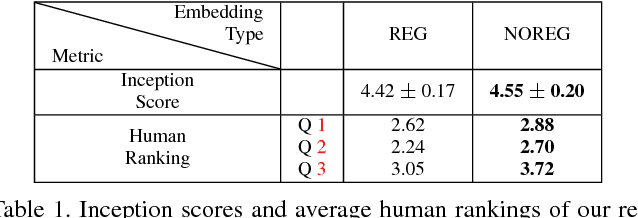

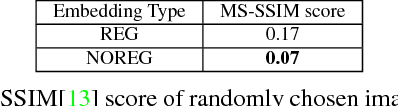
Creating an image reflecting the content of a long text is a complex process that requires a sense of creativity. For example, creating a book cover or a movie poster based on their summary or a food image based on its recipe. In this paper we present the new task of generating images from long text that does not describe the visual content of the image directly. For this, we build a system for generating high-resolution 256 $\times$ 256 images of food conditioned on their recipes. The relation between the recipe text (without its title) to the visual content of the image is vague, and the textual structure of recipes is complex, consisting of two sections (ingredients and instructions) both containing multiple sentences. We used the recipe1M dataset to train and evaluate our model that is based on a the StackGAN-v2 architecture.
LiDAR guided Small obstacle Segmentation
Mar 12, 2020
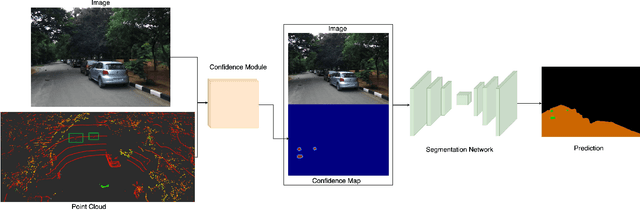
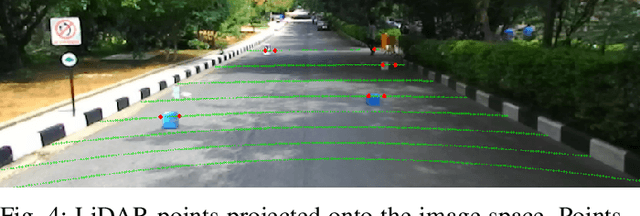
Detecting small obstacles on the road is critical for autonomous driving. In this paper, we present a method to reliably detect such obstacles through a multi-modal framework of sparse LiDAR(VLP-16) and Monocular vision. LiDAR is employed to provide additional context in the form of confidence maps to monocular segmentation networks. We show significant performance gains when the context is fed as an additional input to monocular semantic segmentation frameworks. We further present a new semantic segmentation dataset to the community, comprising of over 3000 image frames with corresponding LiDAR observations. The images come with pixel-wise annotations of three classes off-road, road, and small obstacle. We stress that precise calibration between LiDAR and camera is crucial for this task and thus propose a novel Hausdorff distance based calibration refinement method over extrinsic parameters. As a first benchmark over this dataset, we report our results with 73% instance detection up to a distance of 50 meters on challenging scenarios. Qualitatively by showcasing accurate segmentation of obstacles less than 15 cms at 50m depth and quantitatively through favourable comparisons vis a vis prior art, we vindicate the method's efficacy. Our project-page and Dataset is hosted at https://small-obstacle-dataset.github.io/
SLAM Endoscopy enhanced by adversarial depth prediction
Jun 29, 2019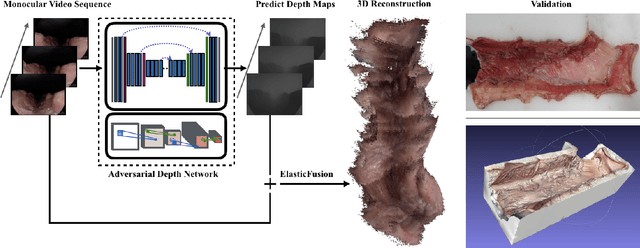

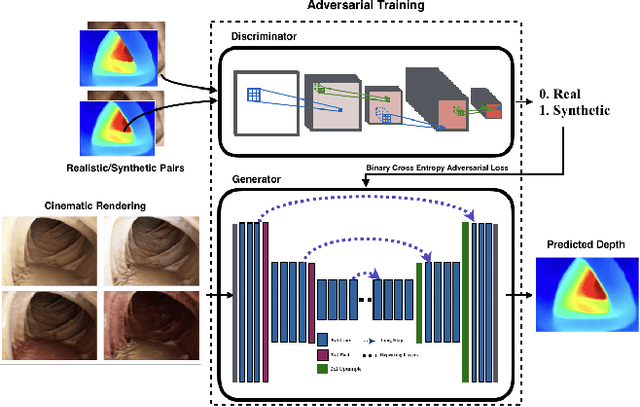
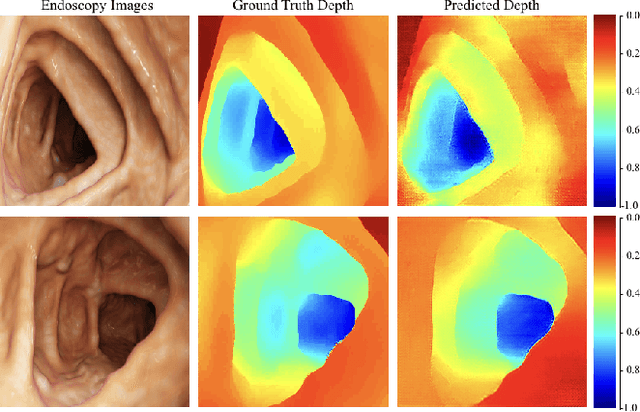
Medical endoscopy remains a challenging application for simultaneous localization and mapping (SLAM) due to the sparsity of image features and size constraints that prevent direct depth-sensing. We present a SLAM approach that incorporates depth predictions made by an adversarially-trained convolutional neural network (CNN) applied to monocular endoscopy images. The depth network is trained with synthetic images of a simple colon model, and then fine-tuned with domain-randomized, photorealistic images rendered from computed tomography measurements of human colons. Each image is paired with an error-free depth map for supervised adversarial learning. Monocular RGB images are then fused with corresponding depth predictions, enabling dense reconstruction and mosaicing as an endoscope is advanced through the gastrointestinal tract. Our preliminary results demonstrate that incorporating monocular depth estimation into a SLAM architecture can enable dense reconstruction of endoscopic scenes.
Real-time 3D Deep Multi-Camera Tracking
Mar 26, 2020
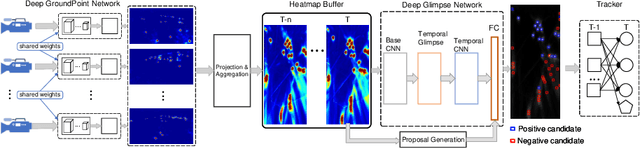

Tracking a crowd in 3D using multiple RGB cameras is a challenging task. Most previous multi-camera tracking algorithms are designed for offline setting and have high computational complexity. Robust real-time multi-camera 3D tracking is still an unsolved problem. In this work, we propose a novel end-to-end tracking pipeline, Deep Multi-Camera Tracking (DMCT), which achieves reliable real-time multi-camera people tracking. Our DMCT consists of 1) a fast and novel perspective-aware Deep GroudPoint Network, 2) a fusion procedure for ground-plane occupancy heatmap estimation, 3) a novel Deep Glimpse Network for person detection and 4) a fast and accurate online tracker. Our design fully unleashes the power of deep neural network to estimate the "ground point" of each person in each color image, which can be optimized to run efficiently and robustly. Our fusion procedure, glimpse network and tracker merge the results from different views, find people candidates using multiple video frames and then track people on the fused heatmap. Our system achieves the state-of-the-art tracking results while maintaining real-time performance. Apart from evaluation on the challenging WILDTRACK dataset, we also collect two more tracking datasets with high-quality labels from two different environments and camera settings. Our experimental results confirm that our proposed real-time pipeline gives superior results to previous approaches.
AutoGAN: Neural Architecture Search for Generative Adversarial Networks
Aug 11, 2019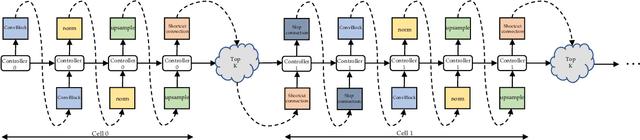
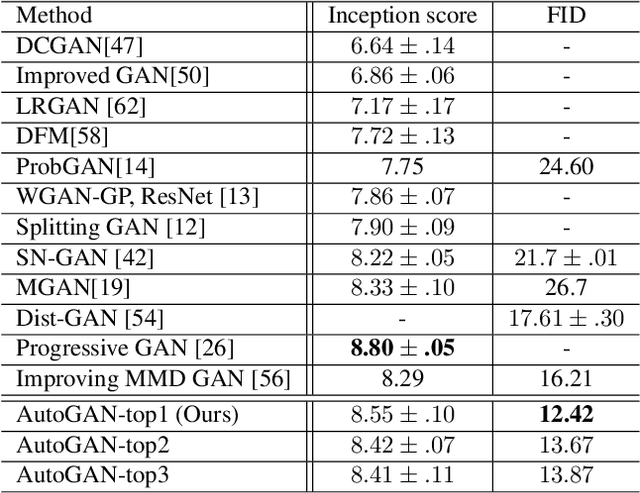
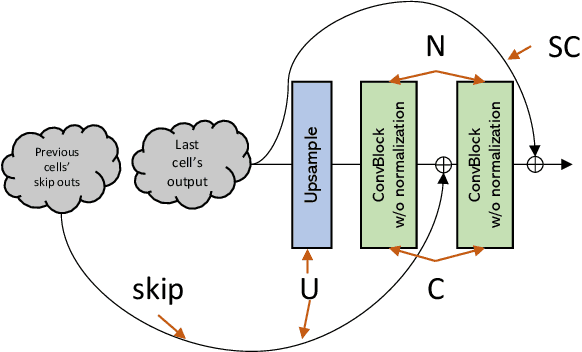
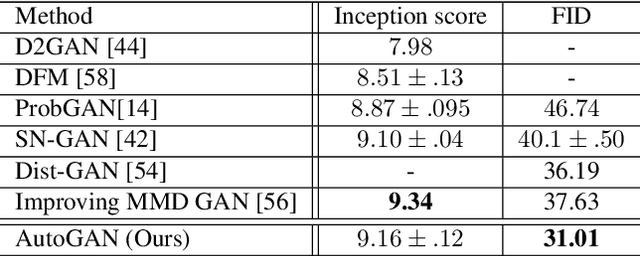
Neural architecture search (NAS) has witnessed prevailing success in image classification and (very recently) segmentation tasks. In this paper, we present the first preliminary study on introducing the NAS algorithm to generative adversarial networks (GANs), dubbed AutoGAN. The marriage of NAS and GANs faces its unique challenges. We define the search space for the generator architectural variations and use an RNN controller to guide the search, with parameter sharing and dynamic-resetting to accelerate the process. Inception score is adopted as the reward, and a multi-level search strategy is introduced to perform NAS in a progressive way. Experiments validate the effectiveness of AutoGAN on the task of unconditional image generation. Specifically, our discovered architectures achieve highly competitive performance compared to current state-of-the-art hand-crafted GANs, e.g., setting new state-of-the-art FID scores of 12.42 on CIFAR-10, and 31.01 on STL-10, respectively. We also conclude with a discussion of the current limitations and future potential of AutoGAN. The code is available at https://github.com/TAMU-VITA/AutoGAN
Lattice Map Spiking Neural Networks (LM-SNNs) for Clustering and Classifying Image Data
Jun 04, 2019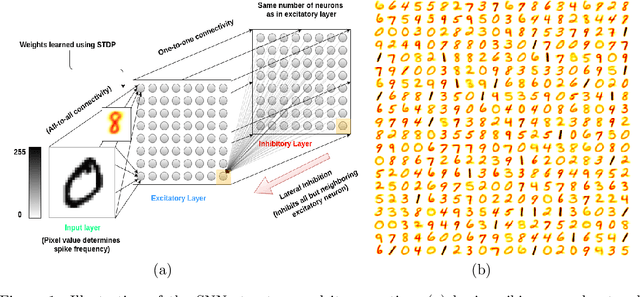

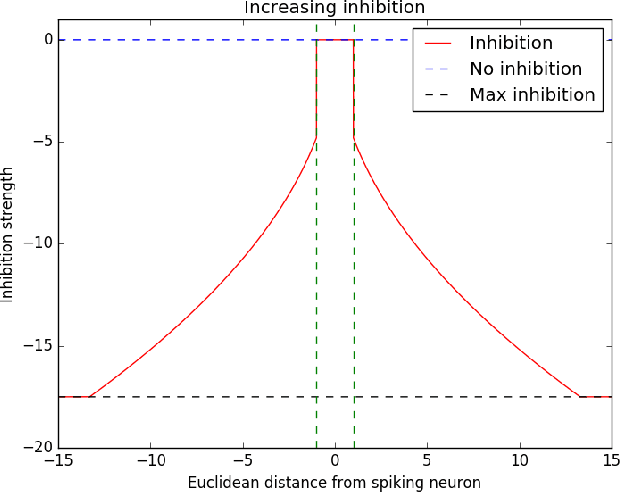
Spiking neural networks (SNNs) with a lattice architecture are introduced in this work, combining several desirable properties of SNNs and self-organized maps (SOMs). Networks are trained with biologically motivated, unsupervised learning rules to obtain a self-organized grid of filters via cooperative and competitive excitatory-inhibitory interactions. Several inhibition strategies are developed and tested, such as (i) incrementally increasing inhibition level over the course of network training, and (ii) switching the inhibition level from low to high (two-level) after an initial training segment. During the labeling phase, the spiking activity generated by data with known labels is used to assign neurons to categories of data, which are then used to evaluate the network's classification ability on a held-out set of test data. Several biologically plausible evaluation rules are proposed and compared, including a population-level confidence rating, and an $n$-gram inspired method. The effectiveness of the proposed self-organized learning mechanism is tested using the MNIST benchmark dataset, as well as using images produced by playing the Atari Breakout game.
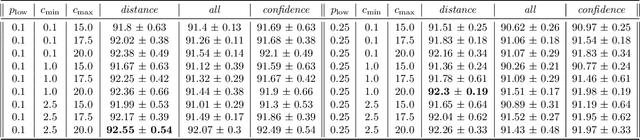
Autonomous quadrotor obstacle avoidance based on dueling double deep recurrent Q network with monocular vision
Feb 10, 2020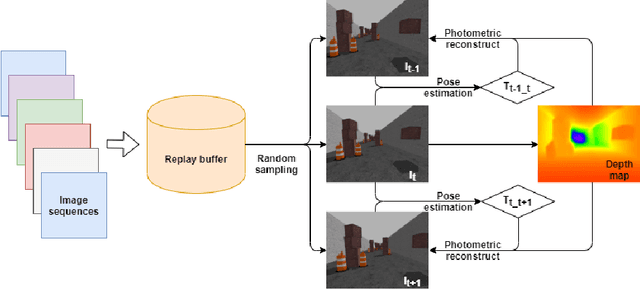

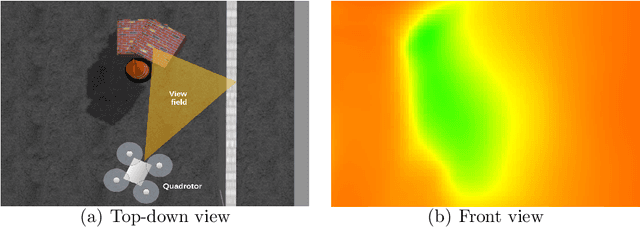
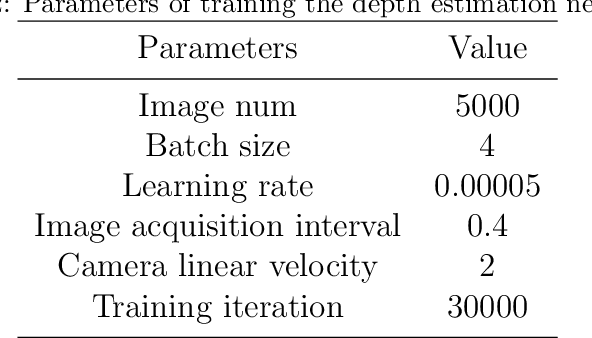
The fast developing of unmanned aerial vehicle(UAV) brings forward the higher request to the ability of autonomous obstacle avoidance in crowded environment. Small UAVs such as quadrotors usually integrate with simple sensors and computation units because of the limited payload and power supply, which adds difficulties for operating traditional obstacle avoidance method. In this paper, we present a framework to control a quadrotor to fly through crowded environments autonomously. This framework adopts a two-stage architecture, a sensing module based on unsupervised deep learning method and a decision module established on deep reinforcement learning method, which takes the monocular image as inputs and outputs quadrotor actions. And it enables the quadrotor to realize autonomous obstacle avoidance without any prior environment information or labeled datasets. To eliminate the negative effects of limited observation capacity of on-board monocular camera, the decision module uses dueling double deep recurrent Q networks. The trained model shows high success rate as it control a quadrotor to fly through crowded environments in simulation. And it can have good performance after scenario transformed.
Open Source Computer Vision-based Layer-wise 3D Printing Analysis
Mar 12, 2020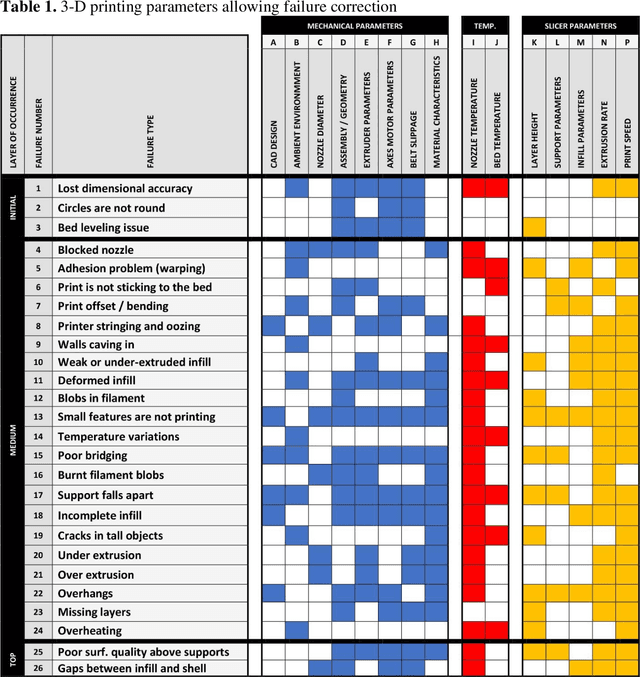

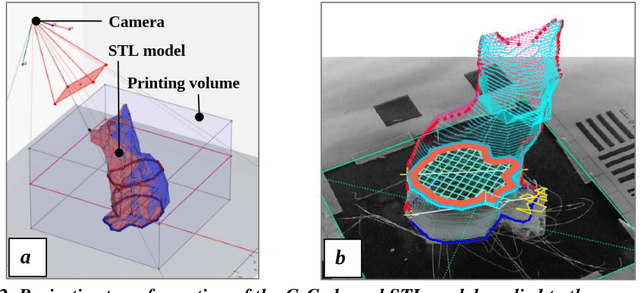
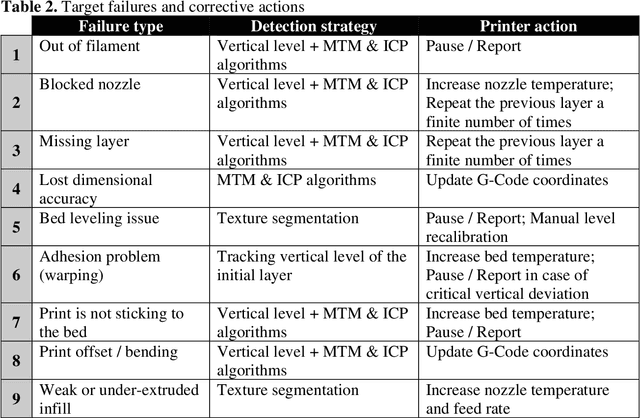
The paper describes an open source computer vision-based hardware structure and software algorithm, which analyzes layer-wise the 3-D printing processes, tracks printing errors, and generates appropriate printer actions to improve reliability. This approach is built upon multiple-stage monocular image examination, which allows monitoring both the external shape of the printed object and internal structure of its layers. Starting with the side-view height validation, the developed program analyzes the virtual top view for outer shell contour correspondence using the multi-template matching and iterative closest point algorithms, as well as inner layer texture quality clustering the spatial-frequency filter responses with Gaussian mixture models and segmenting structural anomalies with the agglomerative hierarchical clustering algorithm. This allows evaluation of both global and local parameters of the printing modes. The experimentally-verified analysis time per layer is less than one minute, which can be considered a quasi-real-time process for large prints. The systems can work as an intelligent printing suspension tool designed to save time and material. However, the results show the algorithm provides a means to systematize in situ printing data as a first step in a fully open source failure correction algorithm for additive manufacturing.
Adversarial Examples versus Cloud-based Detectors: A Black-box Empirical Study
Jan 13, 2019
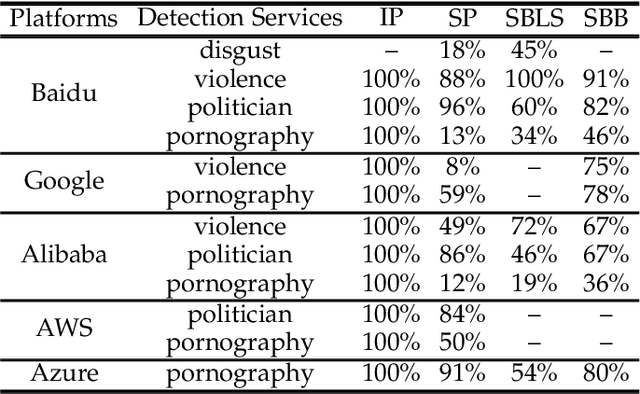

Deep learning has been broadly leveraged by major cloud providers such as Google, AWS, Baidu, to offer various computer vision related services including image auto-classification, object identification and illegal image detection. While many recent works demonstrated that deep learning classification models are vulnerable to adversarial examples, real-world cloud-based image detection services are more complex than classification and there is little literature about adversarial example attacks on detection services. In this paper, we mainly focus on studying the security of real-world cloud-based image detectors. Specifically, (1) based on effective semantic segmentation, we propose four different attacks to generate semantics-aware adversarial examples via only interacting with black-box APIs; and (2) we make the first attempt to conduct an extensive empirical study of black-box attacks against real-world cloud-based image detectors. Through evaluations on five popular cloud platforms including AWS, Azure, Google Cloud, Baidu Cloud and Alibaba Cloud, we demonstrate that our IP attack has a success rate of approximately 100%, and semantic segmentation based attacks (e.g., SP, SBLS, SBB) have a a success rate over 90% among different detection services, such as violence, politician and pornography detection. We discuss the possible defenses to address these security challenges in cloud-based detectors.
KerCNNs: biologically inspired lateral connections for classification of corrupted images
Oct 18, 2019
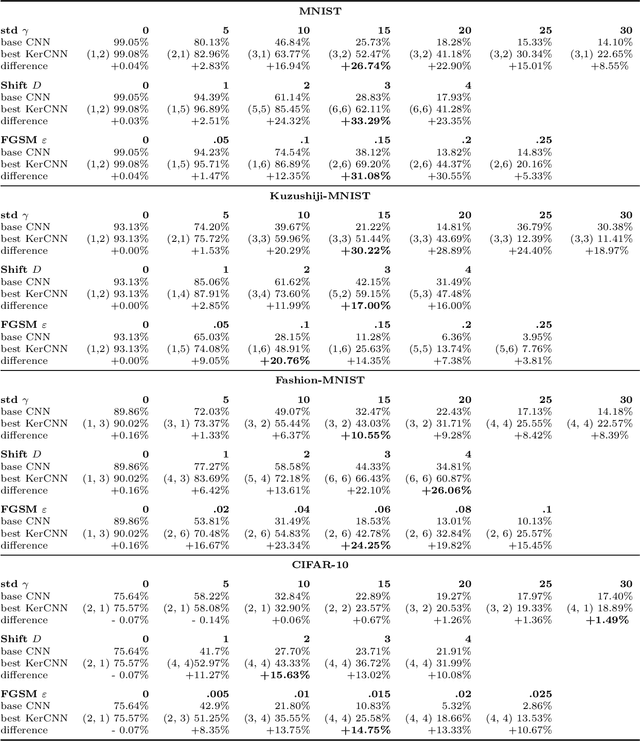
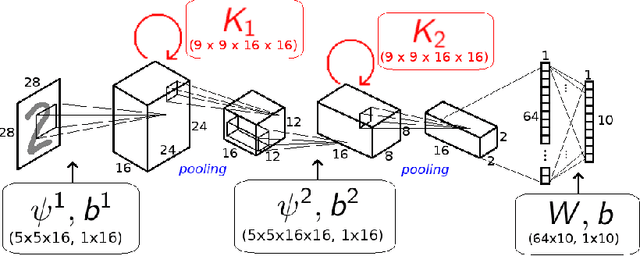
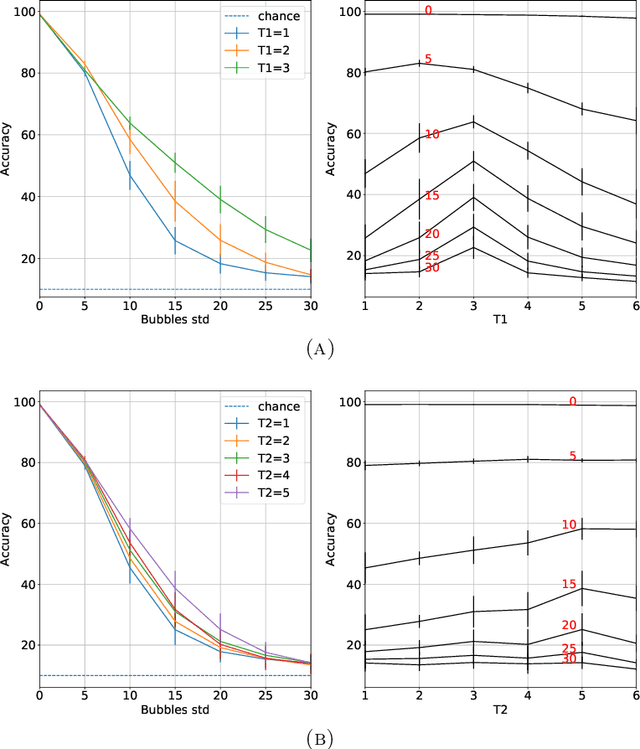
The state of the art in many computer vision tasks is represented by Convolutional Neural Networks (CNNs). Although their hierarchical organization and local feature extraction are inspired by the structure of primate visual systems, the lack of lateral connections in such architectures critically distinguishes their analysis from biological object processing. The idea of enriching CNNs with recurrent lateral connections of convolutional type has been put into practice in recent years, in the form of learned recurrent kernels with no geometrical constraints. In the present work, we introduce biologically plausible lateral kernels encoding a notion of correlation between the feedforward filters of a CNN: at each layer, the associated kernel acts as a transition kernel on the space of activations. The lateral kernels are defined in terms of the filters, thus providing a parameter-free approach to assess the geometry of horizontal connections based on the feedforward structure. We then test this new architecture, which we call KerCNN, on a generalization task related to global shape analysis and pattern completion: once trained for performing basic image classification, the network is evaluated on corrupted testing images. The image perturbations examined are designed to undermine the recognition of the images via local features, thus requiring an integration of context information - which in biological vision is critically linked to lateral connectivity. Our KerCNNs turn out to be far more stable than CNNs and recurrent CNNs to such degradations, thus validating this biologically inspired approach to reinforce object recognition under challenging conditions.