 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
MultiModal-Learning for Predicting Molecular Properties: A Framework Based on Image and Graph Structures
Nov 28, 2023
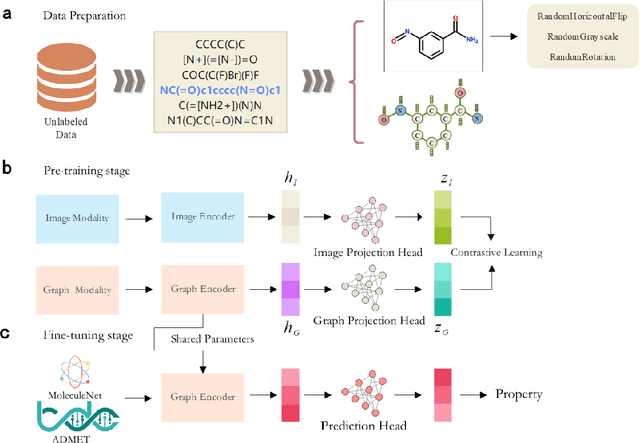
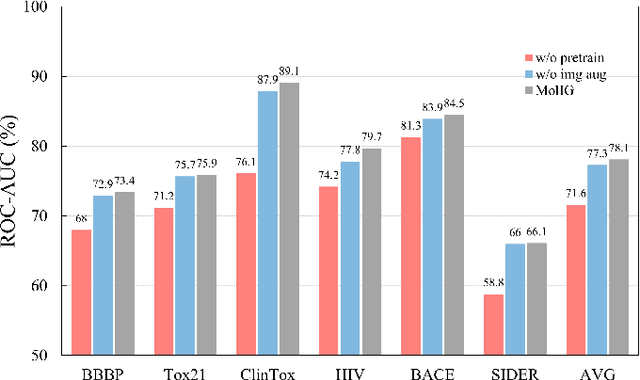
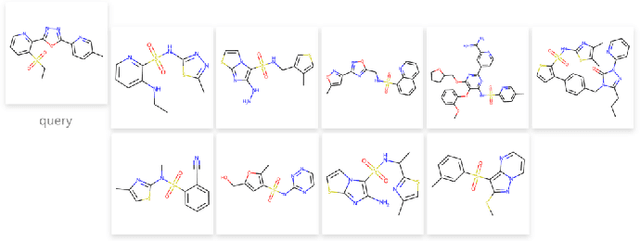
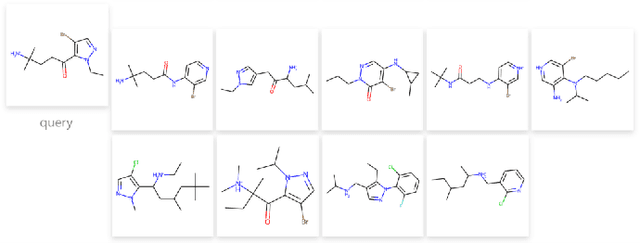
The quest for accurate prediction of drug molecule properties poses a fundamental challenge in the realm of Artificial Intelligence Drug Discovery (AIDD). An effective representation of drug molecules emerges as a pivotal component in this pursuit. Contemporary leading-edge research predominantly resorts to self-supervised learning (SSL) techniques to extract meaningful structural representations from large-scale, unlabeled molecular data, subsequently fine-tuning these representations for an array of downstream tasks. However, an inherent shortcoming of these studies lies in their singular reliance on one modality of molecular information, such as molecule image or SMILES representations, thus neglecting the potential complementarity of various molecular modalities. In response to this limitation, we propose MolIG, a novel MultiModaL molecular pre-training framework for predicting molecular properties based on Image and Graph structures. MolIG model innovatively leverages the coherence and correlation between molecule graph and molecule image to execute self-supervised tasks, effectively amalgamating the strengths of both molecular representation forms. This holistic approach allows for the capture of pivotal molecular structural characteristics and high-level semantic information. Upon completion of pre-training, Graph Neural Network (GNN) Encoder is used for the prediction of downstream tasks. In comparison to advanced baseline models, MolIG exhibits enhanced performance in downstream tasks pertaining to molecular property prediction within benchmark groups such as MoleculeNet Benchmark Group and ADMET Benchmark Group.
SkyScript: A Large and Semantically Diverse Vision-Language Dataset for Remote Sensing
Dec 20, 2023Remote sensing imagery, despite its broad applications in helping achieve Sustainable Development Goals and tackle climate change, has not yet benefited from the recent advancements of versatile, task-agnostic vision language models (VLMs). A key reason is that the large-scale, semantically diverse image-text dataset required for developing VLMs is still absent for remote sensing images. Unlike natural images, remote sensing images and their associated text descriptions cannot be efficiently collected from the public Internet at scale. In this work, we bridge this gap by using geo-coordinates to automatically connect open, unlabeled remote sensing images with rich semantics covered in OpenStreetMap, and thus construct SkyScript, a comprehensive vision-language dataset for remote sensing images, comprising 2.6 million image-text pairs covering 29K distinct semantic tags. With continual pre-training on this dataset, we obtain a VLM that surpasses baseline models with a 6.2% average accuracy gain in zero-shot scene classification across seven benchmark datasets. It also demonstrates the ability of zero-shot transfer for fine-grained object attribute classification and cross-modal retrieval. We hope this dataset can support the advancement of VLMs for various multi-modal tasks in remote sensing, such as open-vocabulary classification, retrieval, captioning, and text-to-image synthesis.
Multi-Clue Reasoning with Memory Augmentation for Knowledge-based Visual Question Answering
Dec 20, 2023Visual Question Answering (VQA) has emerged as one of the most challenging tasks in artificial intelligence due to its multi-modal nature. However, most existing VQA methods are incapable of handling Knowledge-based Visual Question Answering (KB-VQA), which requires external knowledge beyond visible contents to answer questions about a given image. To address this issue, we propose a novel framework that endows the model with capabilities of answering more general questions, and achieves a better exploitation of external knowledge through generating Multiple Clues for Reasoning with Memory Neural Networks (MCR-MemNN). Specifically, a well-defined detector is adopted to predict image-question related relation phrases, each of which delivers two complementary clues to retrieve the supporting facts from external knowledge base (KB), which are further encoded into a continuous embedding space using a content-addressable memory. Afterwards, mutual interactions between visual-semantic representation and the supporting facts stored in memory are captured to distill the most relevant information in three modalities (i.e., image, question, and KB). Finally, the optimal answer is predicted by choosing the supporting fact with the highest score. We conduct extensive experiments on two widely-used benchmarks. The experimental results well justify the effectiveness of MCR-MemNN, as well as its superiority over other KB-VQA methods.
End-to-end Rain Streak Removal with RAW Images
Dec 20, 2023In this work we address the problem of rain streak removal with RAW images. The general approach is firstly processing RAW data into RGB images and removing rain streak with RGB images. Actually the original information of rain in RAW images is affected by image signal processing (ISP) pipelines including none-linear algorithms, unexpected noise, artifacts and so on. It gains more benefit to directly remove rain in RAW data before being processed into RGB format. To solve this problem, we propose a joint solution for rain removal and RAW processing to obtain clean color images from rainy RAW image. To be specific, we generate rainy RAW data by converting color rain streak into RAW space and design simple but efficient RAW processing algorithms to synthesize both rainy and clean color images. The rainy color images are used as reference to help color corrections. Different backbones show that our method conduct a better result compared with several other state-of-the-art deraining methods focused on color image. In addition, the proposed network generalizes well to other cameras beyond our selected RAW dataset. Finally, we give the result tested on images processed by different ISP pipelines to show the generalization performance of our model is better compared with methods on color images.
Promise:Prompt-driven 3D Medical Image Segmentation Using Pretrained Image Foundation Models
Nov 13, 2023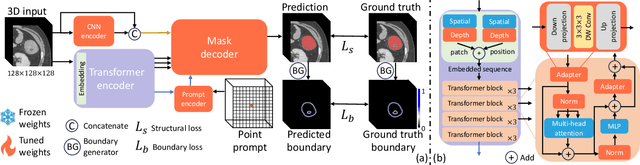

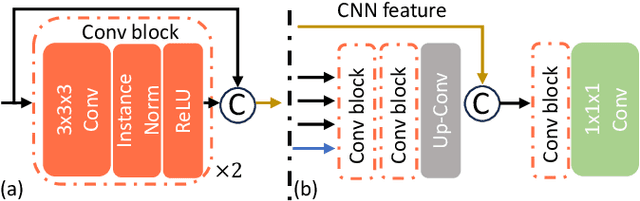
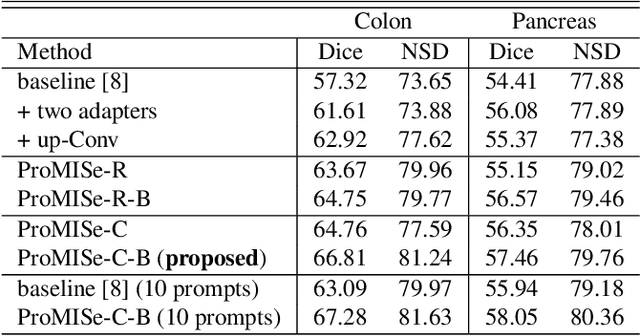
To address prevalent issues in medical imaging, such as data acquisition challenges and label availability, transfer learning from natural to medical image domains serves as a viable strategy to produce reliable segmentation results. However, several existing barriers between domains need to be broken down, including addressing contrast discrepancies, managing anatomical variability, and adapting 2D pretrained models for 3D segmentation tasks. In this paper, we propose ProMISe,a prompt-driven 3D medical image segmentation model using only a single point prompt to leverage knowledge from a pretrained 2D image foundation model. In particular, we use the pretrained vision transformer from the Segment Anything Model (SAM) and integrate lightweight adapters to extract depth-related (3D) spatial context without updating the pretrained weights. For robust results, a hybrid network with complementary encoders is designed, and a boundary-aware loss is proposed to achieve precise boundaries. We evaluate our model on two public datasets for colon and pancreas tumor segmentations, respectively. Compared to the state-of-the-art segmentation methods with and without prompt engineering, our proposed method achieves superior performance. The code is publicly available at https://github.com/MedICL-VU/ProMISe.
Scene-Conditional 3D Object Stylization and Composition
Dec 19, 2023Recently, 3D generative models have made impressive progress, enabling the generation of almost arbitrary 3D assets from text or image inputs. However, these approaches generate objects in isolation without any consideration for the scene where they will eventually be placed. In this paper, we propose a framework that allows for the stylization of an existing 3D asset to fit into a given 2D scene, and additionally produce a photorealistic composition as if the asset was placed within the environment. This not only opens up a new level of control for object stylization, for example, the same assets can be stylized to reflect changes in the environment, such as summer to winter or fantasy versus futuristic settings-but also makes the object-scene composition more controllable. We achieve this by combining modeling and optimizing the object's texture and environmental lighting through differentiable ray tracing with image priors from pre-trained text-to-image diffusion models. We demonstrate that our method is applicable to a wide variety of indoor and outdoor scenes and arbitrary objects.
3DTINC: Time-Equivariant Non-Contrastive Learning for Predicting Disease Progression from Longitudinal OCTs
Dec 28, 2023Self-supervised learning (SSL) has emerged as a powerful technique for improving the efficiency and effectiveness of deep learning models. Contrastive methods are a prominent family of SSL that extract similar representations of two augmented views of an image while pushing away others in the representation space as negatives. However, the state-of-the-art contrastive methods require large batch sizes and augmentations designed for natural images that are impractical for 3D medical images. To address these limitations, we propose a new longitudinal SSL method, 3DTINC, based on non-contrastive learning. It is designed to learn perturbation-invariant features for 3D optical coherence tomography (OCT) volumes, using augmentations specifically designed for OCT. We introduce a new non-contrastive similarity loss term that learns temporal information implicitly from intra-patient scans acquired at different times. Our experiments show that this temporal information is crucial for predicting progression of retinal diseases, such as age-related macular degeneration (AMD). After pretraining with 3DTINC, we evaluated the learned representations and the prognostic models on two large-scale longitudinal datasets of retinal OCTs where we predict the conversion to wet-AMD within a six months interval. Our results demonstrate that each component of our contributions is crucial for learning meaningful representations useful in predicting disease progression from longitudinal volumetric scans.
Binaural recording methods with analysis on inter-aural time, level, and phase differences
Dec 28, 2023Binaural recordings are a form of stereophonic recording method that replicates how human ears perceive sound, these types of recordings create a 3D aural image around the listener and are extremely immersive when well recorded and listened to appropriately with headphones. It has wide applications in video, podcast, and gaming formats -- allowing the listener to feel like they are there. Although binaural formats are seldom used for music applications, they have also been utilized in music ranging from Rock, Jazz, Acoustic, and Classical. In this paper, we will investigate the acoustical phenomenon that produces the binaural effect in audio recordings -- including the ITD (Inter-aural time difference), the ILD (inter-aural level difference), IPD (inter-aural phase difference) as well as the monaural spectral difference that occurs between two ears so we can better understand the replication of human hearing in binaural recordings. Binaural recordings differ from regular stereophonic recordings as they are arranged in a specific way to account for HRTF (Head-related transfer function). The most common method of binaural recordings is with two high-quality omni-directional microphones affixed on a dummy head where the ears are located, although other methods exist without the use of a full dummy head.
A proposed new metric for the conceptual diversity of a text
Dec 27, 2023A word may contain one or more hidden concepts. While the "animal" word evokes many images in our minds and encapsulates many concepts (birds, dogs, cats, crocodiles, etc.), the `parrot' word evokes a single image (a colored bird with a short, hooked beak and the ability to mimic sounds). In spoken or written texts, we use some words in a general sense and some in a detailed way to point to a specific object. Until now, a text's conceptual diversity value cannot be determined using a standard and precise technique. This research contributes to the natural language processing field of AI by offering a standardized method and a generic metric for evaluating and comparing concept diversity in different texts and domains. It also contributes to the field of semantic research of languages. If we give examples for the diversity score of two sentences, "He discovered an unknown entity." has a high conceptual diversity score (16.6801), and "The endoplasmic reticulum forms a series of flattened sacs within the cytoplasm of eukaryotic cells." sentence has a low conceptual diversity score which is 3.9068.
Learning to Embed Time Series Patches Independently
Dec 27, 2023Masked time series modeling has recently gained much attention as a self-supervised representation learning strategy for time series. Inspired by masked image modeling in computer vision, recent works first patchify and partially mask out time series, and then train Transformers to capture the dependencies between patches by predicting masked patches from unmasked patches. However, we argue that capturing such patch dependencies might not be an optimal strategy for time series representation learning; rather, learning to embed patches independently results in better time series representations. Specifically, we propose to use 1) the simple patch reconstruction task, which autoencode each patch without looking at other patches, and 2) the simple patch-wise MLP that embeds each patch independently. In addition, we introduce complementary contrastive learning to hierarchically capture adjacent time series information efficiently. Our proposed method improves time series forecasting and classification performance compared to state-of-the-art Transformer-based models, while it is more efficient in terms of the number of parameters and training/inference time. Code is available at this repository: https://github.com/seunghan96/pits.