 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Closed-Loop Adaptation for Weakly-Supervised Semantic Segmentation
May 29, 2019
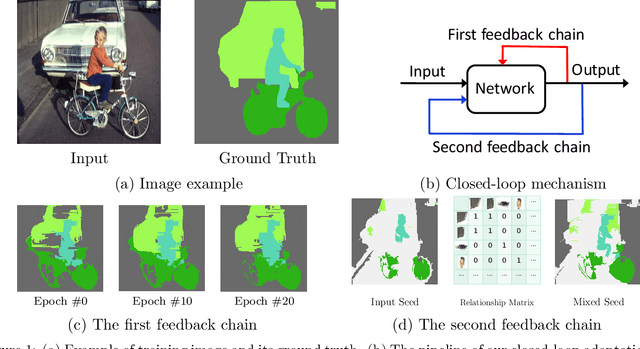
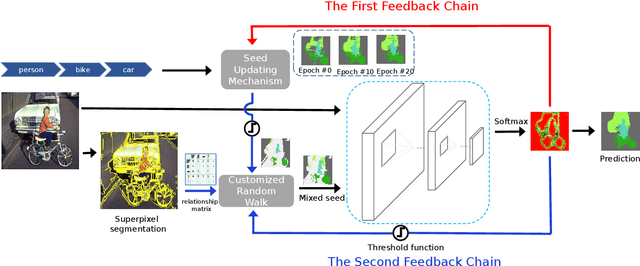

Weakly-supervised semantic segmentation aims to assign each pixel a semantic category under weak supervisions, such as image-level tags. Most of existing weakly-supervised semantic segmentation methods do not use any feedback from segmentation output and can be considered as open-loop systems. They are prone to accumulated errors because of the static seeds and the sensitive structure information. In this paper, we propose a generic self-adaptation mechanism for existing weakly-supervised semantic segmentation methods by introducing two feedback chains, thus constituting a closed-loop system. Specifically, the first chain iteratively produces dynamic seeds by incorporating cross-image structure information, whereas the second chain further expands seed regions by a customized random walk process to reconcile inner-image structure information characterized by superpixels. Experiments on PASCAL VOC 2012 suggest that our network outperforms state-of-the-art methods with significantly less computational and memory burden.
Semantic Relatedness Based Re-ranker for Text Spotting
Sep 19, 2019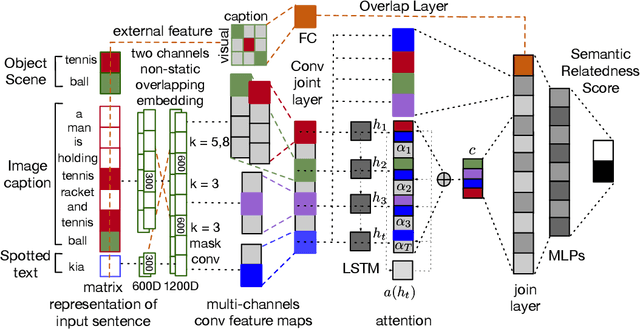
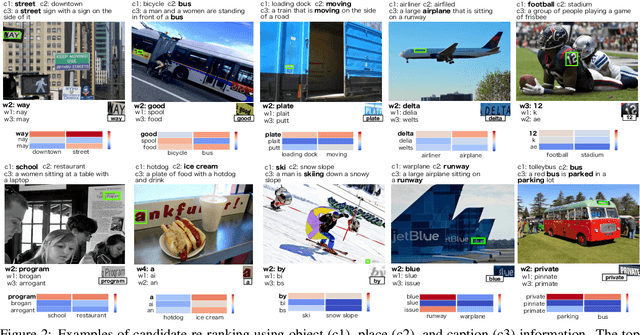
Applications such as textual entailment, plagiarism detection or document clustering rely on the notion of semantic similarity, and are usually approached with dimension reduction techniques like LDA or with embedding-based neural approaches. We present a scenario where semantic similarity is not enough, and we devise a neural approach to learn semantic relatedness. The scenario is text spotting in the wild, where a text in an image (e.g. street sign, advertisement or bus destination) must be identified and recognized. Our goal is to improve the performance of vision systems by leveraging semantic information. Our rationale is that the text to be spotted is often related to the image context in which it appears (word pairs such as Delta-airplane, or quarters-parking are not similar, but are clearly related). We show how learning a word-to-word or word-to-sentence relatedness score can improve the performance of text spotting systems up to 2.9 points, outperforming other measures in a benchmark dataset.
A fast and memory-efficient algorithm for smooth interpolation of polyrigid transformations: application to human joint tracking
Jun 02, 2020

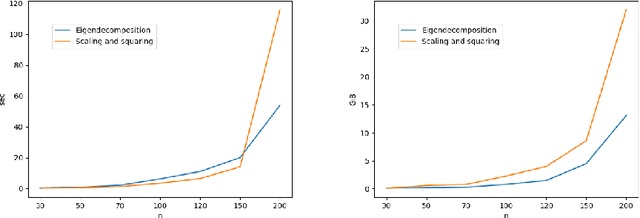
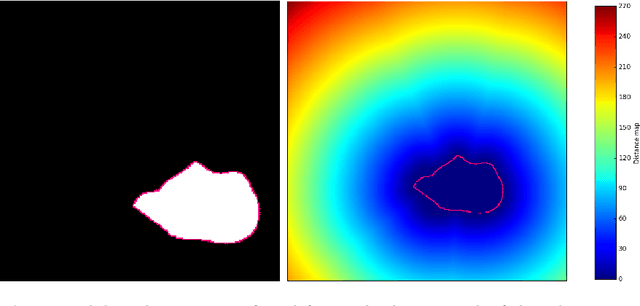
The log Euclidean polyrigid registration framework provides a way to smoothly estimate and interpolate poly-rigid/affine transformations for which the invertibility is guaranteed. This powerful and flexible mathematical framework is currently being used to track the human joint dynamics by first imposing bone rigidity constraints in order to synthetize the spatio-temporal joint deformations later. However, since no closed-form exists, then a computationally expensive integration of ordinary differential equations (ODEs) is required to perform image registration using this framework. To tackle this problem, the exponential map for solving these ODEs is computed using the scaling and squaring method in the literature. In this paper, we propose an algorithm using a matrix diagonalization based method for smooth interpolation of homogeneous polyrigid transformations of human joints during motion. The use of this alternative computational approach to integrate ODEs is well motivated by the fact that bone rigid transformations satisfy the mechanical constraints of human joint motion, which provide conditions that guarantee the diagonalizability of local bone transformations and consequently of the resulting joint transformations. In a comparison with the scaling and squaring method, we discuss the usefulness of the matrix eigendecomposition technique which reduces significantly the computational burden associated with the computation of matrix exponential over a dense regular grid. Finally, we have applied the method to enhance the temporal resolution of dynamic MRI sequences of the ankle joint. To conclude, numerical experiments show that the eigendecomposition method is more capable of balancing the trade-off between accuracy, computation time, and memory requirements.
CCCNet: An Attention Based Deep Learning Framework for Categorized Crowd Counting
Dec 12, 2019
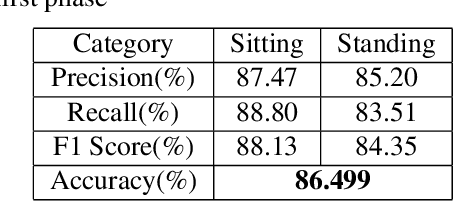
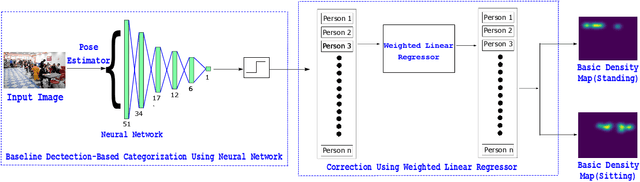
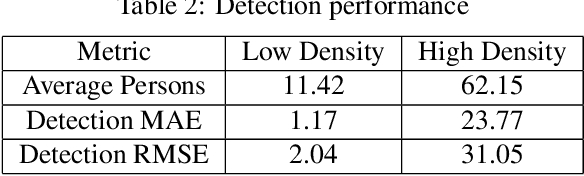
Crowd counting problem that counts the number of people in an image has been extensively studied in recent years. In this paper, we introduce a new variant of crowd counting problem, namely "Categorized Crowd Counting", that counts the number of people sitting and standing in a given image. Categorized crowd counting has many real-world applications such as crowd monitoring, customer service, and resource management. The major challenges in categorized crowd counting come from high occlusion, perspective distortion and the seemingly identical upper body posture of sitting and standing persons. Existing density map based approaches perform well to approximate a large crowd, but lose important local information necessary for categorization. On the other hand, traditional detection-based approaches perform poorly in occluded environments, especially when the crowd size gets bigger. Hence, to solve the categorized crowd counting problem, we develop a novel attention-based deep learning framework that addresses the above limitations. In particular, our approach works in three phases: i) We first generate basic detection based sitting and standing density maps to capture the local information; ii) Then, we generate a crowd counting based density map as global counting feature; iii) Finally, we have a cross-branch segregating refinement phase that splits the crowd density map into final sitting and standing density maps using attention mechanism. Extensive experiments show the efficacy of our approach in solving the categorized crowd counting problem.
Speak2Label: Using Domain Knowledge for Creating a Large Scale Driver Gaze Zone Estimation Dataset
Apr 13, 2020

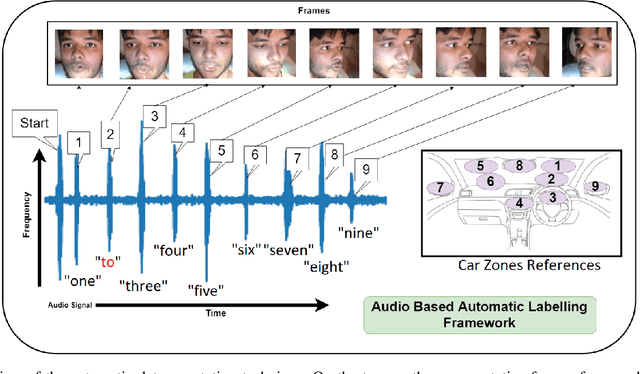
Labelling of human behavior analysis data is a complex and time consuming task. In this paper, a fully automatic technique for labelling an image based gaze behavior dataset for driver gaze zone estimation is proposed. Domain knowledge can be added to the data recording paradigm and later labels can be generated in an automatic manner using speech to text conversion. In order to remove the noise in STT due to different ethnicity, the speech frequency and energy are analysed. The resultant Driver Gaze in the Wild DGW dataset contains 586 recordings, captured during different times of the day including evening. The large scale dataset contains 338 subjects with an age range of 18-63 years. As the data is recorded in different lighting conditions, an illumination robust layer is proposed in the Convolutional Neural Network (CNN). The extensive experiments show the variance in the database resembling real-world conditions and the effectiveness of the proposed CNN pipeline. The proposed network is also fine-tuned for the eye gaze prediction task, which shows the discriminativeness of the representation learnt by our network on the proposed DGW dataset.
Deeply Activated Salient Region for Instance Search
Feb 01, 2020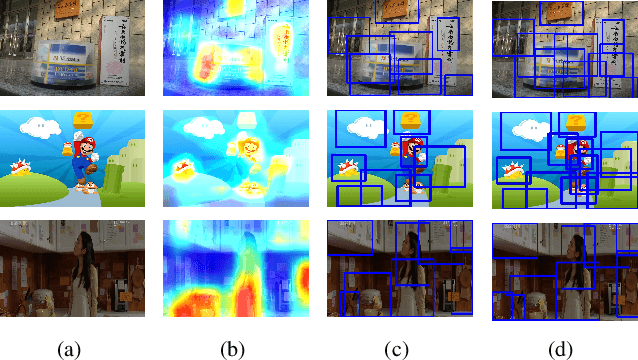
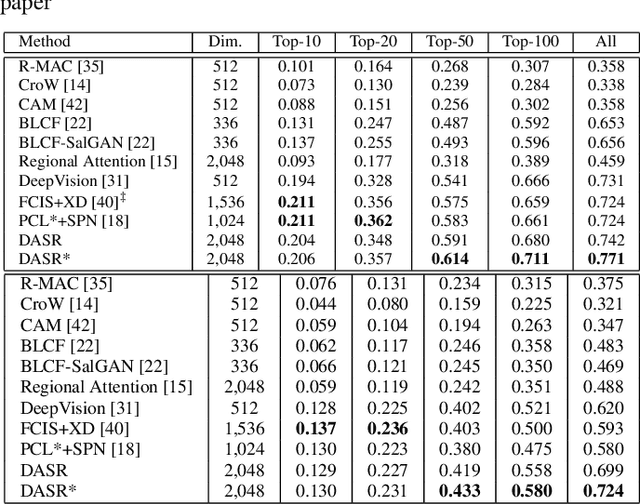
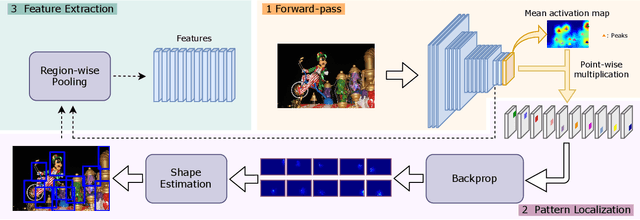
Due to the lack of suitable feature representation, effective solution to the instance search is still slow to occur. In this paper, a novel instance-level feature descriptor is proposed. The feature is built upon the salient instance region that is activated by a layer-wise back-propagation process. Such kind of region usually covers the major part an instance and represents the common patterns shared among instances of the same category. The back-propagation starts from the last convolution layer of pre-trained CNN that is originally used for classification. This makes the feature representation remain effective for instances from both known and unknown categories. Moreover, experiments show that it is effective for instance as well as image search tasks.
Semi-Supervised Monocular Depth Estimation with Left-Right Consistency Using Deep Neural Network
May 18, 2019
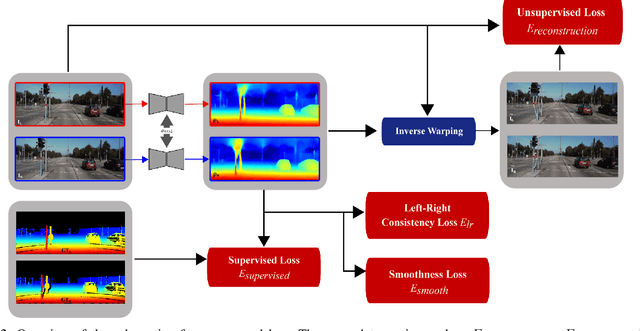

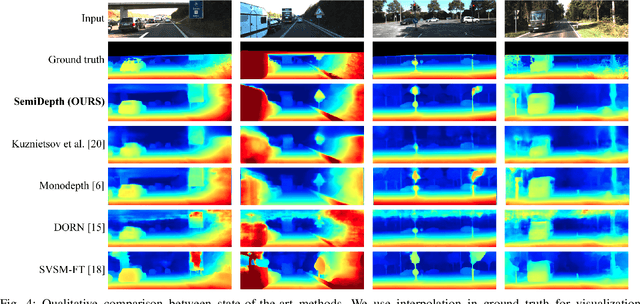
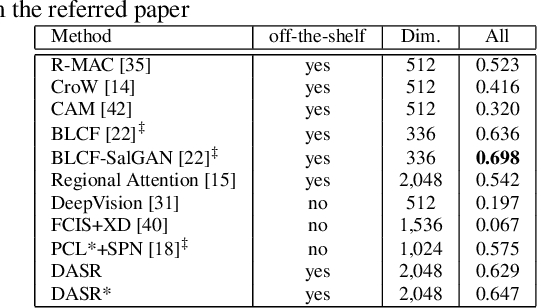
There has been tremendous research progress in estimating the depth of a scene from a monocular camera image. Existing methods for single-image depth prediction are exclusively based on deep neural networks, and their training can be unsupervised using stereo image pairs, supervised using LiDAR point clouds, or semi-supervised using both stereo and LiDAR. In general, semi-supervised training is preferred as it does not suffer from the weaknesses of either supervised training, resulting from the difference in the cameras and the LiDARs field of view, or unsupervised training, resulting from the poor depth accuracy that can be recovered from a stereo pair. In this paper, we present our research in single image depth prediction using semi-supervised training that outperforms the state-of-the-art. We achieve this through a loss function that explicitly exploits left-right consistency in a stereo reconstruction, which has not been adopted in previous semi-supervised training. In addition, we describe the correct use of ground truth depth derived from LiDAR that can significantly reduce prediction error. The performance of our depth prediction model is evaluated on popular datasets, and the importance of each aspect of our semi-supervised training approach is demonstrated through experimental results. Our deep neural network model has been made publicly available.
Using a thousand optimization tasks to learn hyperparameter search strategies
Mar 11, 2020
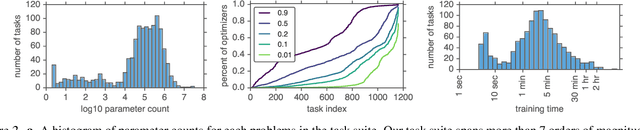
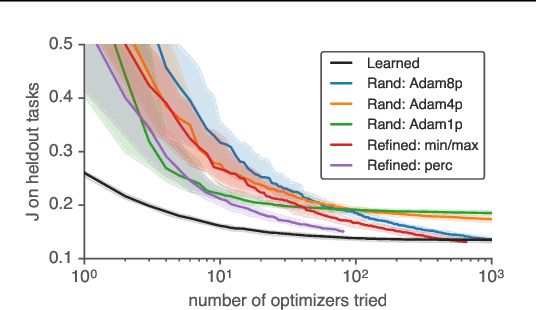
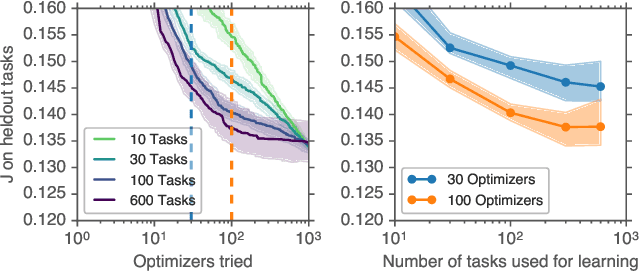
We present TaskSet, a dataset of tasks for use in training and evaluating optimizers. TaskSet is unique in its size and diversity, containing over a thousand tasks ranging from image classification with fully connected or convolutional neural networks, to variational autoencoders, to non-volume preserving flows on a variety of datasets. As an example application of such a dataset we explore meta-learning an ordered list of hyperparameters to try sequentially. By learning this hyperparameter list from data generated using TaskSet we achieve large speedups in sample efficiency over random search. Next we use the diversity of the TaskSet and our method for learning hyperparameter lists to empirically explore the generalization of these lists to new optimization tasks in a variety of settings including ImageNet classification with Resnet50 and LM1B language modeling with transformers. As part of this work we have opensourced code for all tasks, as well as ~29 million training curves for these problems and the corresponding hyperparameters.
SAG-VAE: End-to-end Joint Inference of Data Representations and Feature Relations
Nov 27, 2019
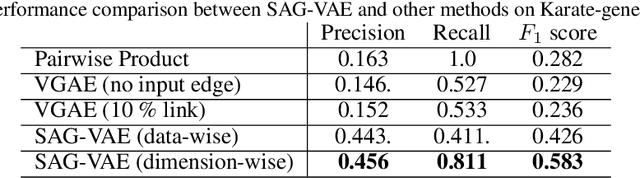
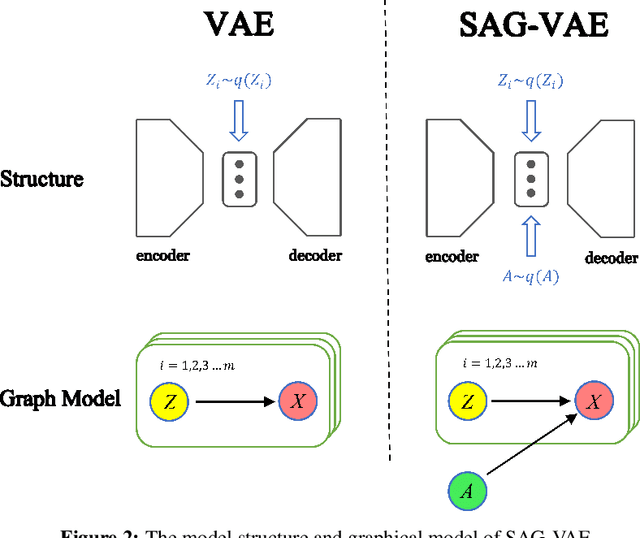
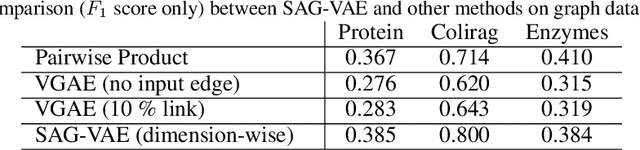
Variational Autoencoders (VAEs) are powerful in data representation inference, but it cannot learn relations between features with its vanilla form and common variations. The ability to capture relations within data can provide the much needed inductive bias necessary for building more robust Machine Learning algorithms with more interpretable results. In this paper, inspired by recent advances in relational learning using Graph Neural Networks, we propose the \textbf{S}elf-\textbf{A}ttention \textbf{G}raph \textbf{V}ariational \textbf{A}uto\textbf{E}ncoder (SAG-VAE) network which can simultaneously learn feature relations and data representations in an end-to-end manner. SAG-VAE is trained by jointly inferring the posterior distribution of two types of latent variables, which denote the data representation and a shared graph structure, respectively. Furthermore, we introduce a novel self-attention graph network that improves the generative capabilities of SAG-VAE by parameterizing the generative distribution allowing SAG-VAE to generate new data via graph convolution, while still trainable via backpropagation. A learnable relational graph representation enhances SAG-VAE's robustness to perturbation and noise, while also providing deeper intuition into model performance. Experiments based on graphs show that SAG-VAE is capable of approximately retrieving edges and links between nodes based entirely on feature observations. Finally, results on image data illustrate that SAG-VAE is fairly robust against perturbations in image reconstruction and sampling.
Imperceptible Adversarial Attacks on Tabular Data
Dec 13, 2019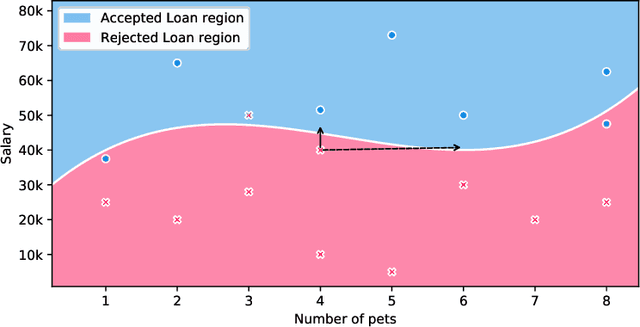
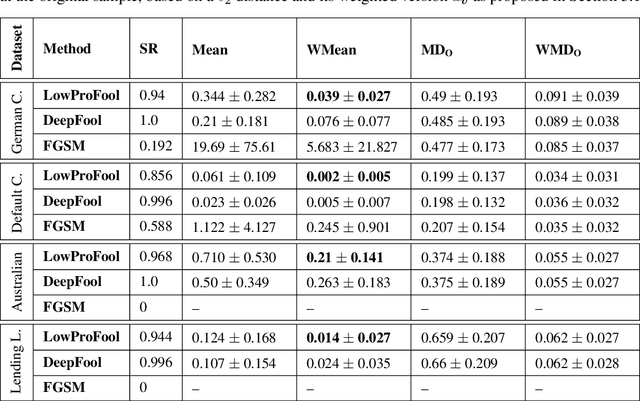
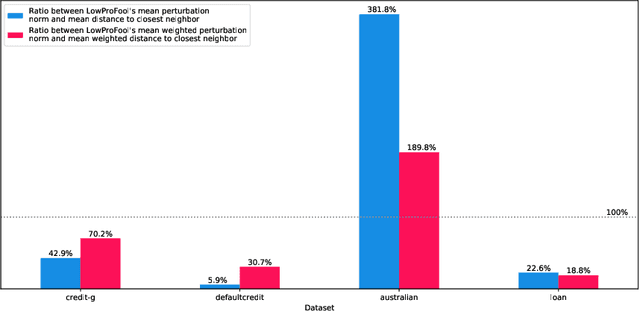
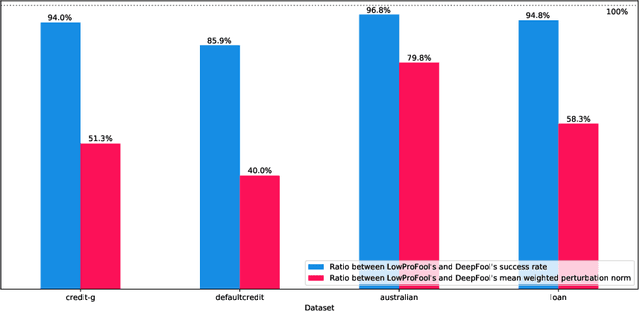
Security of machine learning models is a concern as they may face adversarial attacks for unwarranted advantageous decisions. While research on the topic has mainly been focusing on the image domain, numerous industrial applications, in particular in finance, rely on standard tabular data. In this paper, we discuss the notion of adversarial examples in the tabular domain. We propose a formalization based on the imperceptibility of attacks in the tabular domain leading to an approach to generate imperceptible adversarial examples. Experiments show that we can generate imperceptible adversarial examples with a high fooling rate.