 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Generative Adversarial Networks for Bitcoin Data Augmentation
May 27, 2020
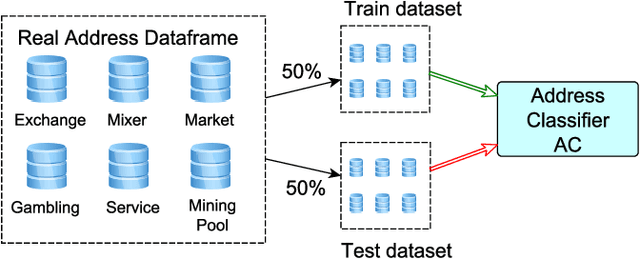
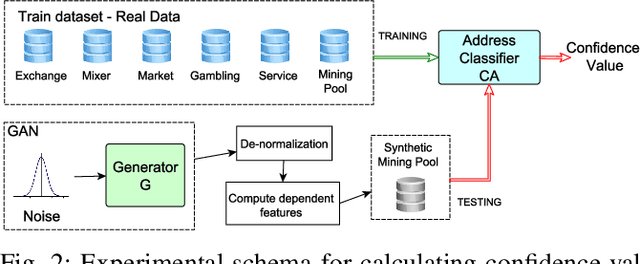
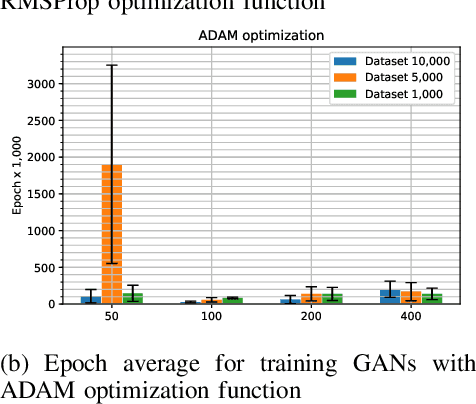
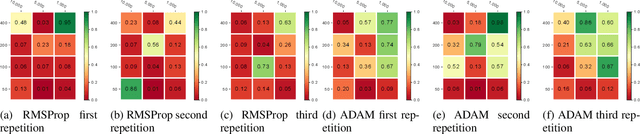
In Bitcoin entity classification, results are strongly conditioned by the ground-truth dataset, especially when applying supervised machine learning approaches. However, these ground-truth datasets are frequently affected by significant class imbalance as generally they contain much more information regarding legal services (Exchange, Gambling), than regarding services that may be related to illicit activities (Mixer, Service). Class imbalance increases the complexity of applying machine learning techniques and reduces the quality of classification results, especially for underrepresented, but critical classes. In this paper, we propose to address this problem by using Generative Adversarial Networks (GANs) for Bitcoin data augmentation as GANs recently have shown promising results in the domain of image classification. However, there is no "one-fits-all" GAN solution that works for every scenario. In fact, setting GAN training parameters is non-trivial and heavily affects the quality of the generated synthetic data. We therefore evaluate how GAN parameters such as the optimization function, the size of the dataset and the chosen batch size affect GAN implementation for one underrepresented entity class (Mining Pool) and demonstrate how a "good" GAN configuration can be obtained that achieves high similarity between synthetically generated and real Bitcoin address data. To the best of our knowledge, this is the first study presenting GANs as a valid tool for generating synthetic address data for data augmentation in Bitcoin entity classification.
TapLab: A Fast Framework for Semantic Video Segmentation Tapping into Compressed-Domain Knowledge
Mar 30, 2020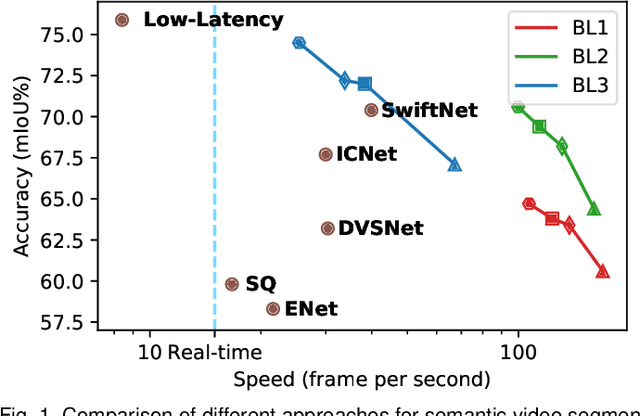
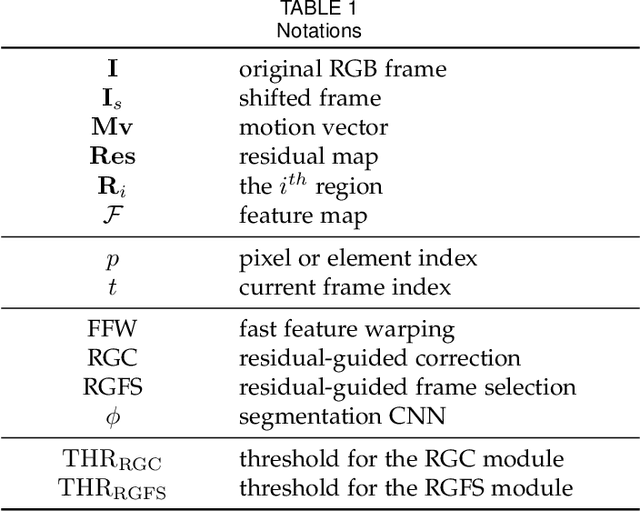
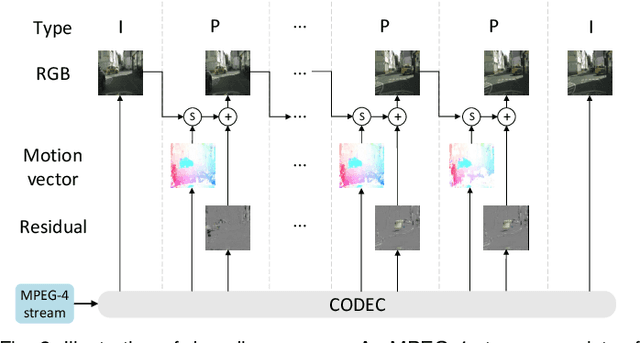

Real-time semantic video segmentation is a challenging task due to the strict requirements of inference speed. Recent approaches mainly devote great efforts to reducing the model size for high efficiency. In this paper, we rethink this problem from a different viewpoint: using knowledge contained in compressed videos. We propose a simple and effective framework, dubbed TapLab, to tap into resources from the compressed domain. Specifically, we design a fast feature warping module using motion vectors for acceleration. To reduce the noise introduced by motion vectors, we design a residual-guided correction module and a residual-guided frame selection module using residuals. Compared with the state-of-the-art fast semantic image segmentation models, our proposed TapLab significantly reduces redundant computations, running around 3 times faster with comparable accuracy for 1024x2048 video. The experimental results show that TapLab achieves 70.6% mIoU on the Cityscapes dataset at 99.8 FPS with a single GPU card. A high-speed version even reaches the speed of 160+ FPS.
Earballs: Neural Transmodal Translation
May 27, 2020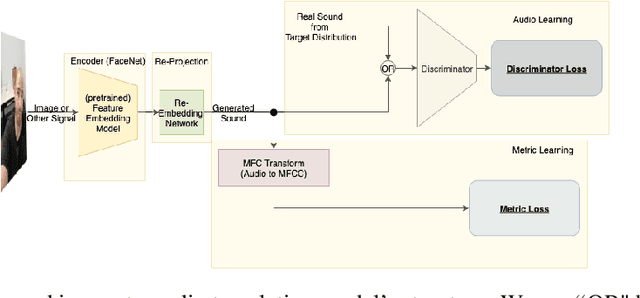
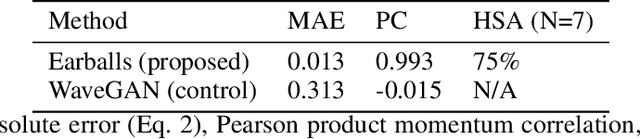


As is expressed in the adage "a picture is worth a thousand words", when using spoken language to communicate visual information, brevity can be a challenge. This work describes a novel technique for leveraging machine learned feature embeddings to translate visual (and other types of) information into a perceptual audio domain, allowing users to perceive this information using only their aural faculty. To be clear, the goal of this work is to propose a mechanism for providing an information preserving mapping that users can learn to use to see (or perceive other information) using their auditory system. The system uses a pretrained image embedding network to extract visual features and embed them in a compact subset of Euclidean space -- this converts the images into feature vectors whose $L^2$ distances can be used as a meaningful measure of similarity. A generative adversarial network is then used to find a distance preserving map from this metric space of feature vectors into the metric space defined by a target audio dataset and a mel-frequency cepstrum-based psychoacoustic distance metric. We demonstrate this technique by translating images of faces into human speech-like audio. The GAN successfully found a metric preserving mapping, and in human subject tests, users were able to successfully classify images of faces using only the audio output by our model.
DUAL-GLOW: Conditional Flow-Based Generative Model for Modality Transfer
Aug 21, 2019

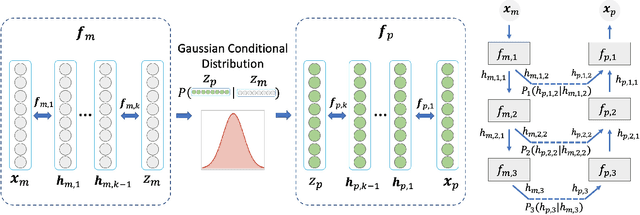
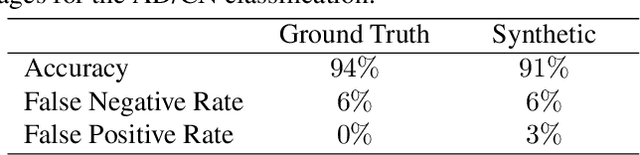
Positron emission tomography (PET) imaging is an imaging modality for diagnosing a number of neurological diseases. In contrast to Magnetic Resonance Imaging (MRI), PET is costly and involves injecting a radioactive substance into the patient. Motivated by developments in modality transfer in vision, we study the generation of certain types of PET images from MRI data. We derive new flow-based generative models which we show perform well in this small sample size regime (much smaller than dataset sizes available in standard vision tasks). Our formulation, DUAL-GLOW, is based on two invertible networks and a relation network that maps the latent spaces to each other. We discuss how given the prior distribution, learning the conditional distribution of PET given the MRI image reduces to obtaining the conditional distribution between the two latent codes w.r.t. the two image types. We also extend our framework to leverage 'side' information (or attributes) when available. By controlling the PET generation through 'conditioning' on age, our model is also able to capture brain FDG-PET (hypometabolism) changes, as a function of age. We present experiments on the Alzheimers Disease Neuroimaging Initiative (ADNI) dataset with 826 subjects, and obtain good performance in PET image synthesis, qualitatively and quantitatively better than recent works.
Training with Quantization Noise for Extreme Fixed-Point Compression
Apr 15, 2020
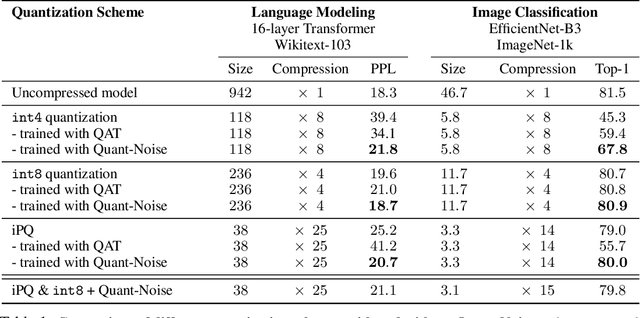
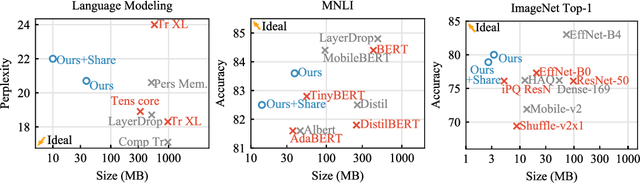
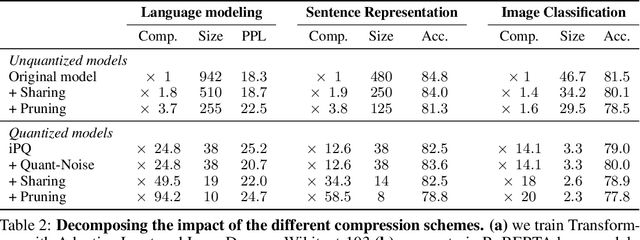
We tackle the problem of producing compact models, maximizing their accuracy for a given model size. A standard solution is to train networks with Quantization Aware Training, where the weights are quantized during training and the gradients approximated with the Straight-Through Estimator. In this paper, we extend this approach to work with extreme compression methods where the approximations introduced by STE are severe. Our proposal is to only quantize a different random subset of weights during each forward, allowing for unbiased gradients to flow through the other weights. Controlling the amount of noise and its form allows for extreme compression rates while maintaining the performance of the original model. As a result we establish new state-of-the-art compromises between accuracy and model size both in natural language processing and image classification. For example, applying our method to state-of-the-art Transformer and ConvNet architectures, we can achieve 82.5% accuracy on MNLI by compressing RoBERTa to 14MB and 80.0% top-1 accuracy on ImageNet by compressing an EfficientNet-B3 to 3.3MB.
AETv2: AutoEncoding Transformations for Self-Supervised Representation Learning by Minimizing Geodesic Distances in Lie Groups
Nov 16, 2019
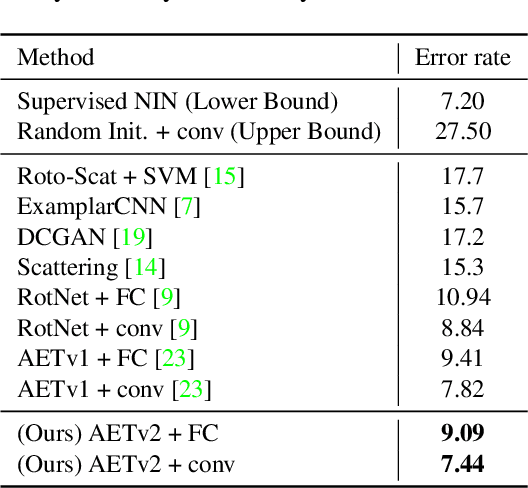
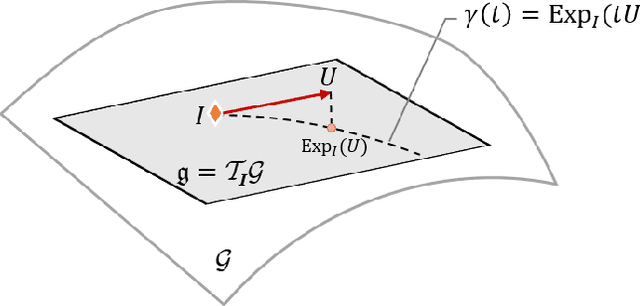

Self-supervised learning by predicting transformations has demonstrated outstanding performances in both unsupervised and (semi-)supervised tasks. Among the state-of-the-art methods is the AutoEncoding Transformations (AET) by decoding transformations from the learned representations of original and transformed images. Both deterministic and probabilistic AETs rely on the Euclidean distance to measure the deviation of estimated transformations from their groundtruth counterparts. However, this assumption is questionable as a group of transformations often reside on a curved manifold rather staying in a flat Euclidean space. For this reason, we should use the geodesic to characterize how an image transform along the manifold of a transformation group, and adopt its length to measure the deviation between transformations. Particularly, we present to autoencode a Lie group of homography transformations PG(2) to learn image representations. For this, we make an estimate of the intractable Riemannian logarithm by projecting PG(2) to a subgroup of rotation transformations SO(3) that allows the closed-form expression of geodesic distances. Experiments demonstrate the proposed AETv2 model outperforms the previous version as well as the other state-of-the-art self-supervised models in multiple tasks.
A sub-Riemannian model of the visual cortex with frequency and phase
Oct 11, 2019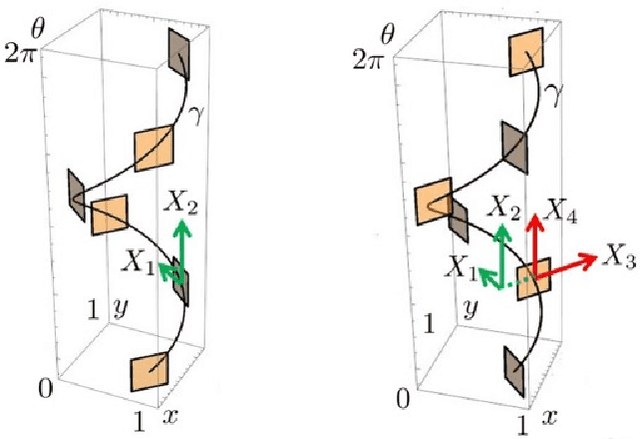
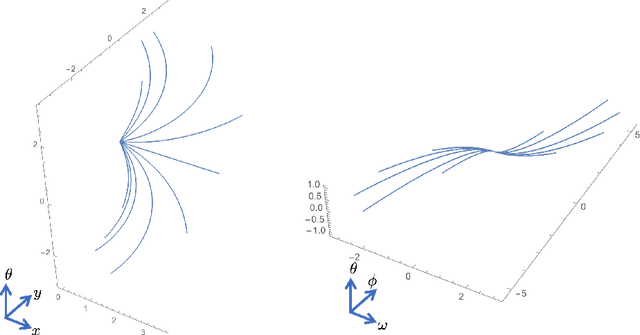

In this paper we present a novel model of the primary visual cortex (V1) based on orientation, frequency and phase selective behavior of the V1 simple cells. We start from the first level mechanisms of visual perception: receptive profiles. The model interprets V1 as a fiber bundle over the 2-dimensional retinal plane by introducing orientation, frequency and phase as intrinsic variables. Each receptive profile on the fiber is mathematically interpreted as a rotated, frequency modulated and phase shifted Gabor function. We start from the Gabor function and show that it induces in a natural way the model geometry and the associated horizontal connectivity modeling the neural connectivity patterns in V1. We provide an image enhancement algorithm employing the model framework. The algorithm is capable of exploiting not only orientation but also frequency and phase information existing intrinsically in a 2-dimensional input image. We provide the experimental results corresponding to the enhancement algorithm.
A Hybrid Method for Training Convolutional Neural Networks
Apr 15, 2020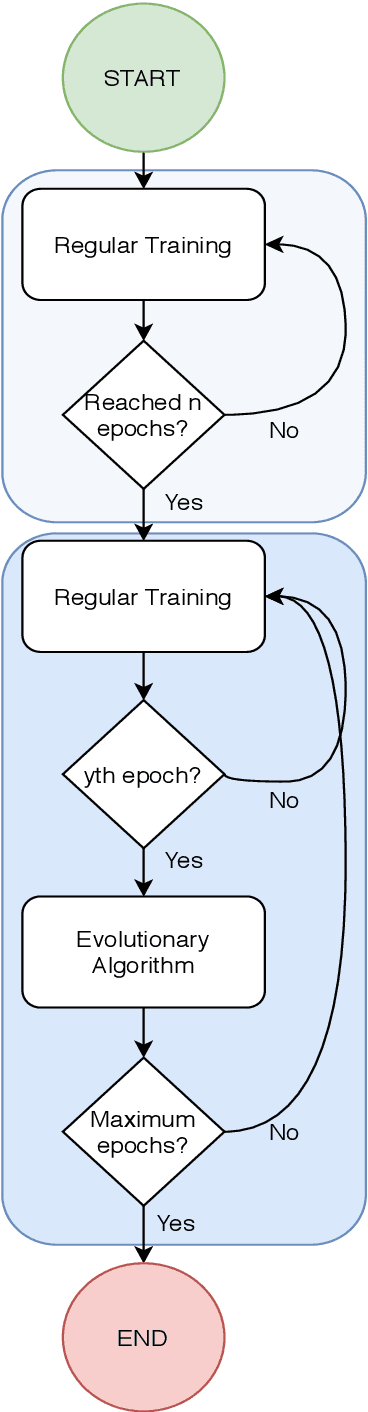
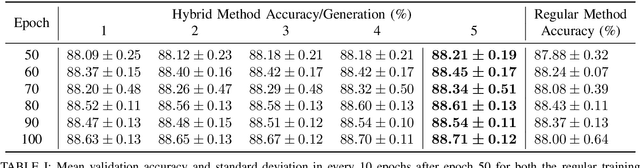

Artificial Intelligence algorithms have been steadily increasing in popularity and usage. Deep Learning, allows neural networks to be trained using huge datasets and also removes the need for human extracted features, as it automates the feature learning process. In the hearth of training deep neural networks, such as Convolutional Neural Networks, we find backpropagation, that by computing the gradient of the loss function with respect to the weights of the network for a given input, it allows the weights of the network to be adjusted to better perform in the given task. In this paper, we propose a hybrid method that uses both backpropagation and evolutionary strategies to train Convolutional Neural Networks, where the evolutionary strategies are used to help to avoid local minimas and fine-tune the weights, so that the network achieves higher accuracy results. We show that the proposed hybrid method is capable of improving upon regular training in the task of image classification in CIFAR-10, where a VGG16 model was used and the final test results increased 0.61%, in average, when compared to using only backpropagation.
Effects of Blur and Deblurring to Visual Object Tracking
Aug 21, 2019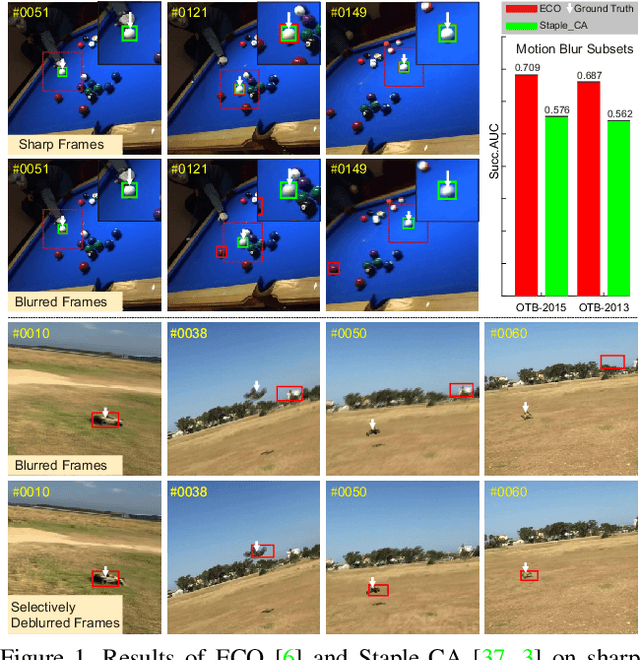

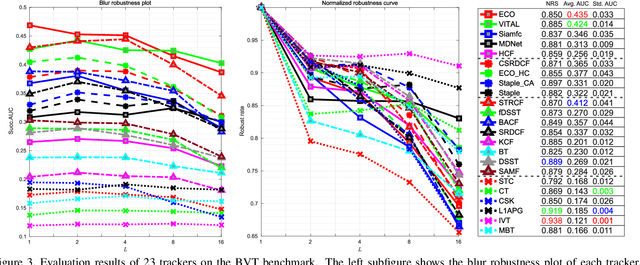
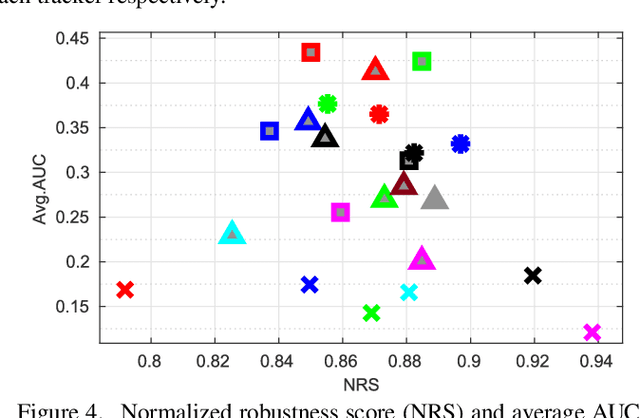
Intuitively, motion blur may hurt the performance of visual object tracking. However, we lack quantitative evaluation of tracker robustness to different levels of motion blur. Meanwhile, while image deblurring methods can produce visually clearer videos for pleasing human eyes, it is unknown whether visual object tracking can benefit from image deblurring or not. In this paper, we address these two problems by constructing a Blurred Video Tracking benchmark, which contains a variety of videos with different levels of motion blurs, as well as ground truth tracking results for evaluating trackers. We extensively evaluate 23 trackers on this benchmark and observe several new interesting results. Specifically, we find that light blur may improve the performance of many trackers, but heavy blur always hurts the tracking performance. We also find that image deblurring may help to improve tracking performance on heavily blurred videos but hurt the performance on lightly blurred videos. According to these observations, we propose a new GAN based scheme to improve the tracker robustness to motion blurs. In this scheme, a finetuned discriminator is used as an adaptive assessor to selectively deblur frames during the tracking process. We use this scheme to successfully improve the accuracy and robustness of 6 trackers.
Adversarial Pulmonary Pathology Translation for Pairwise Chest X-ray Data Augmentation
Oct 11, 2019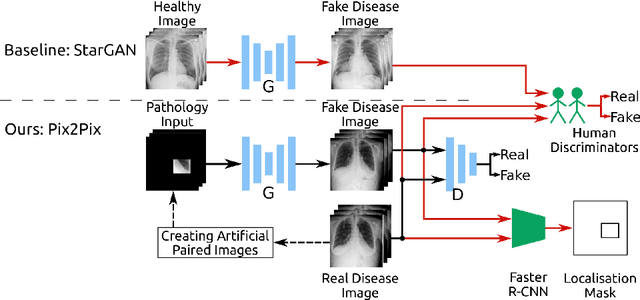
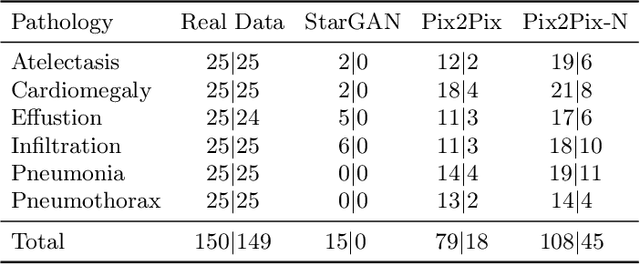
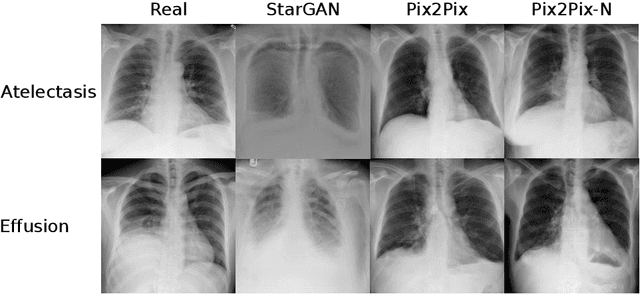
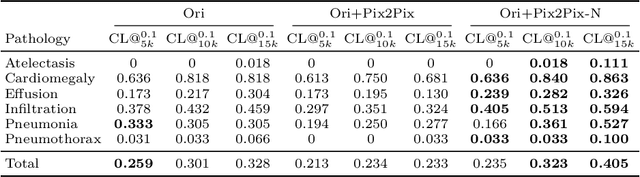
Recent works show that Generative Adversarial Networks (GANs) can be successfully applied to chest X-ray data augmentation for lung disease recognition. However, the implausible and distorted pathology features generated from the less than perfect generator may lead to wrong clinical decisions. Why not keep the original pathology region? We proposed a novel approach that allows our generative model to generate high quality plausible images that contain undistorted pathology areas. The main idea is to design a training scheme based on an image-to-image translation network to introduce variations of new lung features around the pathology ground-truth area. Moreover, our model is able to leverage both annotated disease images and unannotated healthy lung images for the purpose of generation. We demonstrate the effectiveness of our model on two tasks: (i) we invite certified radiologists to assess the quality of the generated synthetic images against real and other state-of-the-art generative models, and (ii) data augmentation to improve the performance of disease localisation.