 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Ricci Curvature Based Volumetric Segmentation of the Auditory Ossicles
Jun 26, 2020
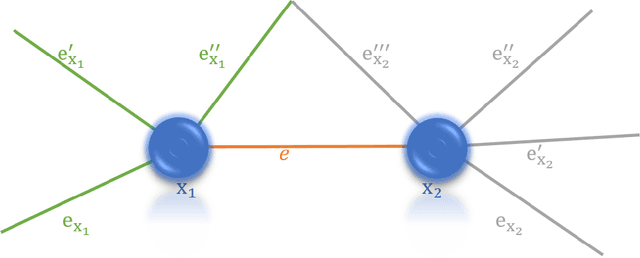
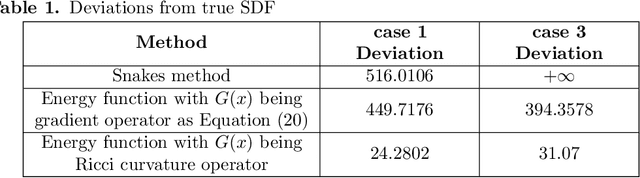
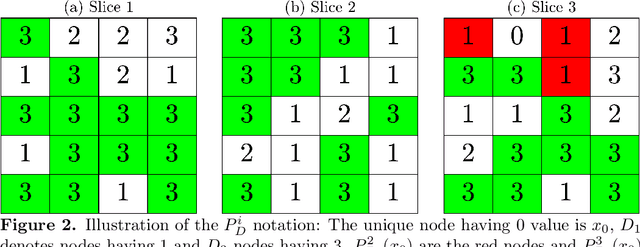
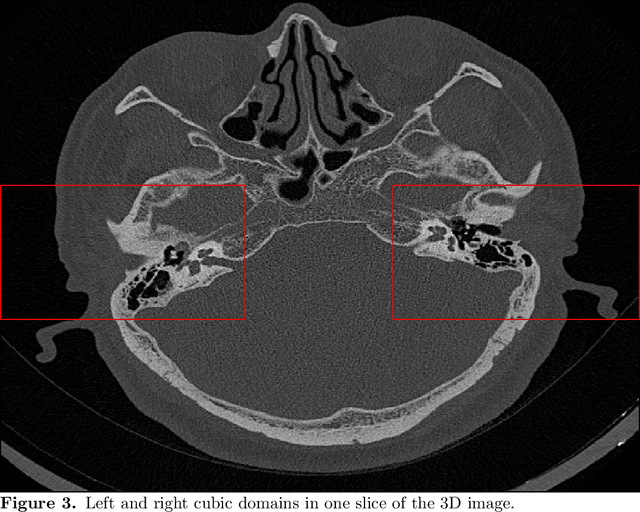
The auditory ossicles that are located in the middle ear are the smallest bones in the human body. Their damage will result in hearing loss. It is therefore important to be able to automatically diagnose ossicles' diseases based on Computed Tomography (CT) 3D imaging. However CT images usually include the whole head area, which is much larger than the bones of interest, thus the localization of the ossicles, followed by segmentation, both play a significant role in automatic diagnosis. The commonly employed local segmentation methods require manually selected initial points, which is a highly time consuming process. We therefore propose a completely automatic method to locate the ossicles which requires neither templates, nor manual labels. It relies solely on the connective properties of the auditory ossicles themselves, and their relationship with the surrounding tissue fluid. For the segmentation task, we define a novel energy function and obtain the shape of the ossicles from the 3D CT image by minimizing this new energy. Compared to the state-of-the-art methods which usually use the gradient operator and some normalization terms, we propose to add a Ricci curvature term to the commonly employed energy function. We compare our proposed method with the state-of-the-art methods and show that the performance of discrete Forman-Ricci curvature is superior to the others.
Deep Plug-and-Play Prior for Parallel MRI Reconstruction
Aug 30, 2019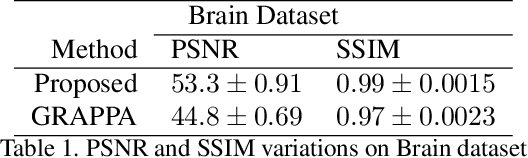
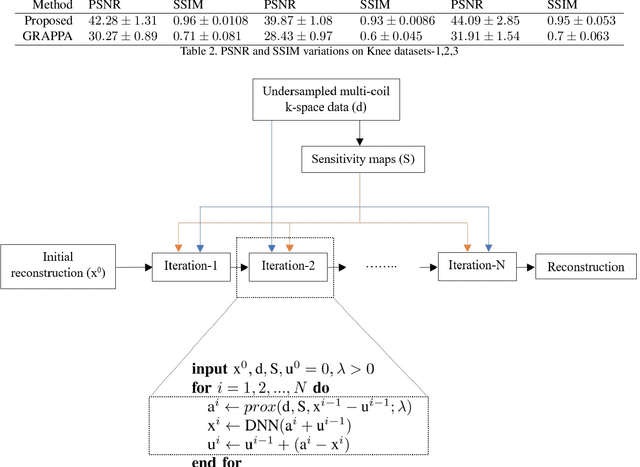
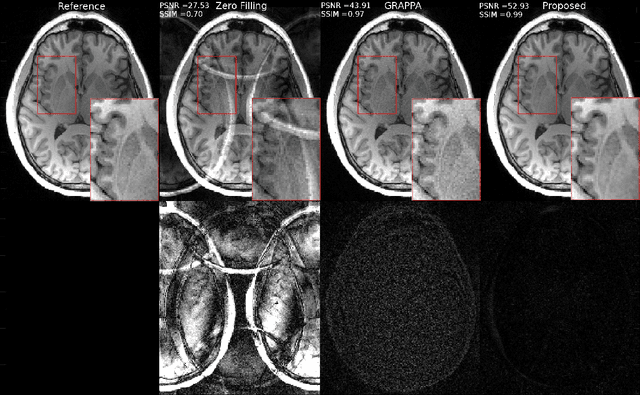
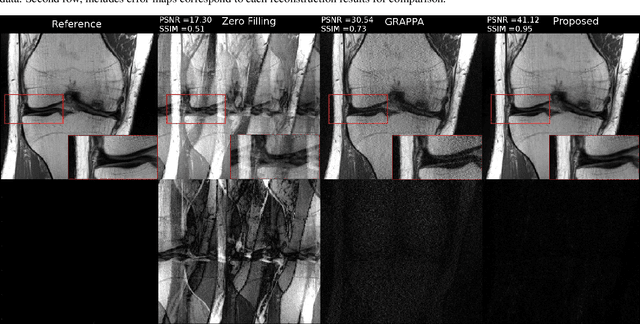
Fast data acquisition in Magnetic Resonance Imaging (MRI) is vastly in demand and scan time directly depends on the number of acquired k-space samples. Conventional MRI reconstruction methods for fast MRI acquisition mostly relied on different regularizers which represent analytical models of sparsity. However, recent data-driven methods based on deep learning has resulted in promising improvements in image reconstruction algorithms. In this paper, we propose a deep plug-and-play prior framework for parallel MRI reconstruction problems which utilize a deep neural network (DNN) as an advanced denoiser within an iterative method. This, in turn, enables rapid acquisition of MR images with improved image quality. The proposed method was compared with the reconstructions using the clinical gold standard GRAPPA method. Our results with undersampled data demonstrate that our method can deliver considerably higher quality images at high acceleration factors in comparison to clinical gold standard method for MRI reconstructions. Our proposed reconstruction enables an increase in acceleration factor, and a reduction in acquisition time while maintaining high image quality.
FragNet: Writer Identification using Deep Fragment Networks
Mar 24, 2020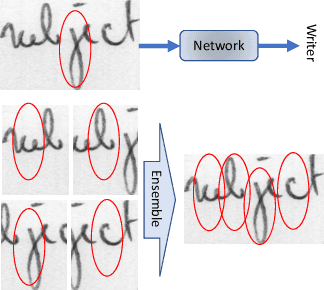
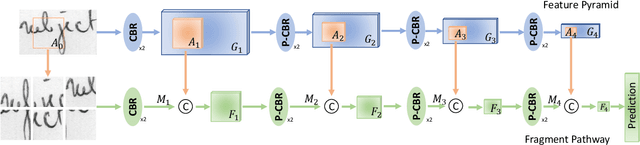
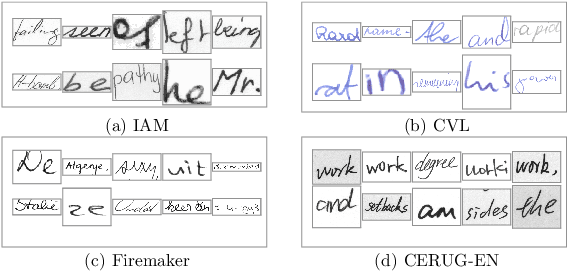
Writer identification based on a small amount of text is a challenging problem. In this paper, we propose a new benchmark study for writer identification based on word or text block images which approximately contain one word. In order to extract powerful features on these word images, a deep neural network, named FragNet, is proposed. The FragNet has two pathways: feature pyramid which is used to extract feature maps and fragment pathway which is trained to predict the writer identity based on fragments extracted from the input image and the feature maps on the feature pyramid. We conduct experiments on four benchmark datasets, which show that our proposed method can generate efficient and robust deep representations for writer identification based on both word and page images.
DeepFake Detection by Analyzing Convolutional Traces
Apr 22, 2020
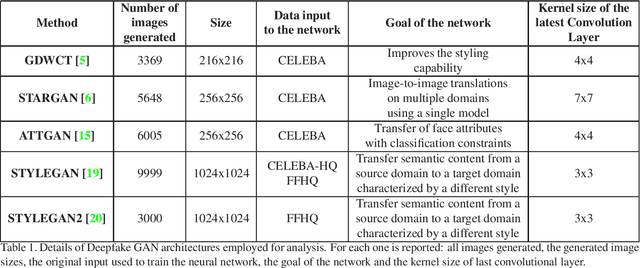

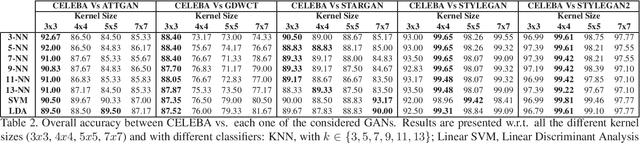
The Deepfake phenomenon has become very popular nowadays thanks to the possibility to create incredibly realistic images using deep learning tools, based mainly on ad-hoc Generative Adversarial Networks (GAN). In this work we focus on the analysis of Deepfakes of human faces with the objective of creating a new detection method able to detect a forensics trace hidden in images: a sort of fingerprint left in the image generation process. The proposed technique, by means of an Expectation Maximization (EM) algorithm, extracts a set of local features specifically addressed to model the underlying convolutional generative process. Ad-hoc validation has been employed through experimental tests with naive classifiers on five different architectures (GDWCT, STARGAN, ATTGAN, STYLEGAN, STYLEGAN2) against the CELEBA dataset as ground-truth for non-fakes. Results demonstrated the effectiveness of the technique in distinguishing the different architectures and the corresponding generation process.
Model-based Asynchronous Hyperparameter Optimization
Mar 24, 2020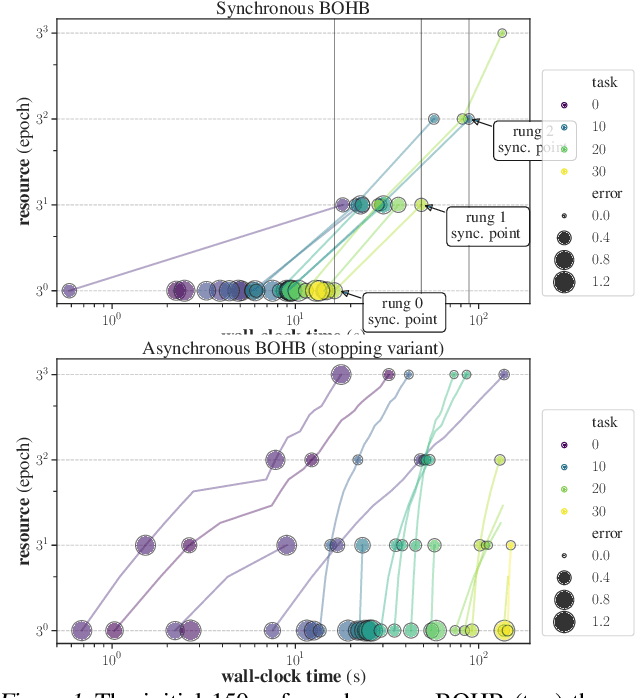


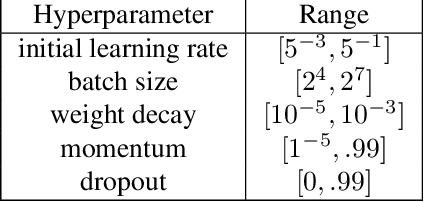
We introduce a model-based asynchronous multi-fidelity hyperparameter optimization (HPO) method, combining strengths of asynchronous Hyperband and Gaussian process-based Bayesian optimization. Our method obtains substantial speed-ups in wall-clock time over, both, synchronous and asynchronous Hyperband, as well as a prior model-based extension of the former. Candidate hyperparameters to evaluate are selected by a novel jointly dependent Gaussian process-based surrogate model over all resource levels, allowing evaluations at one level to be informed by evaluations gathered at all others. We benchmark several covariance functions and conduct extensive experiments on hyperparameter tuning for multi-layer perceptrons on tabular data, convolutional networks on image classification, and recurrent networks on language modelling, demonstrating the benefits of our approach.
Kornia: an Open Source Differentiable Computer Vision Library for PyTorch
Oct 09, 2019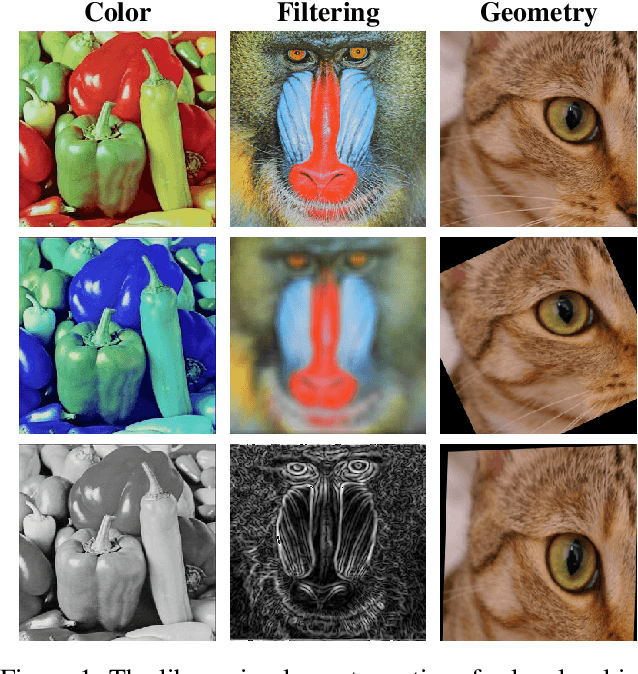

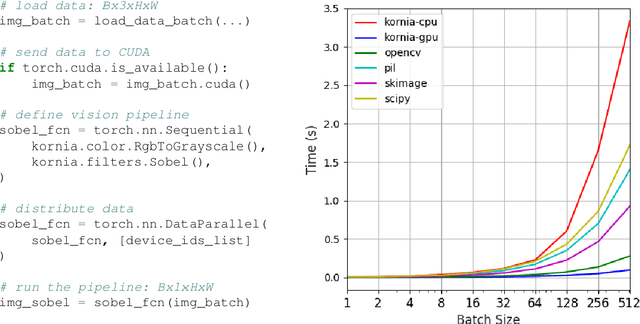
This work presents Kornia -- an open source computer vision library which consists of a set of differentiable routines and modules to solve generic computer vision problems. The package uses PyTorch as its main backend both for efficiency and to take advantage of the reverse-mode auto-differentiation to define and compute the gradient of complex functions. Inspired by OpenCV, Kornia is composed of a set of modules containing operators that can be inserted inside neural networks to train models to perform image transformations, camera calibration, epipolar geometry, and low level image processing techniques, such as filtering and edge detection that operate directly on high dimensional tensor representations. Examples of classical vision problems implemented using our framework are provided including a benchmark comparing to existing vision libraries.
ArchNet: Data Hiding Model in Distributed Machine Learning System
May 31, 2020
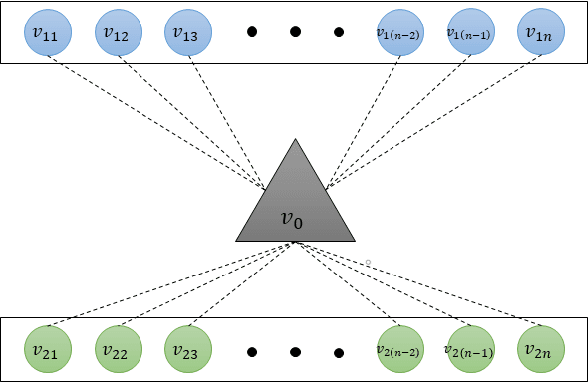
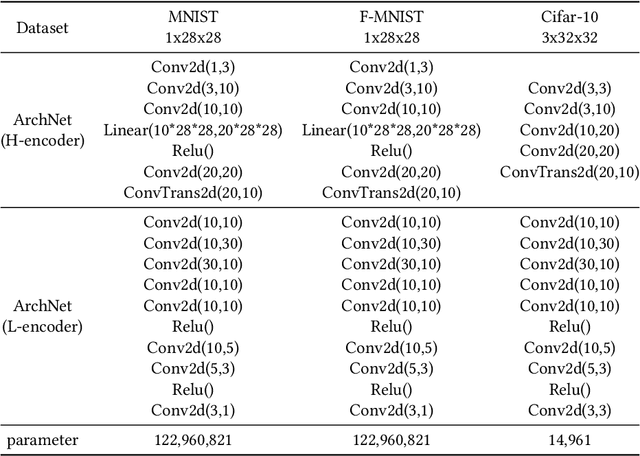
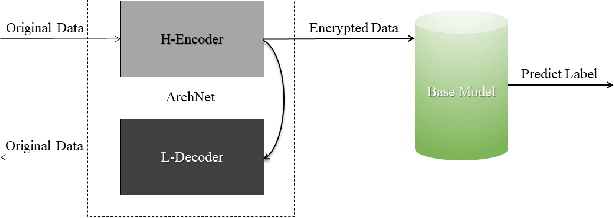
Integrating idle embedded devices into cloud computing is a promising approach to support distributed machine learning. In this paper, we approach to address the data hiding problem in such distributed machine learning systems. For the purpose of the data encryption in the distributed machine learning systems, we propose the Tripartite Asymmetric Encryption theorem and give mathematical proof. Based on the theorem, we design a general image encryption scheme ArchNet.The scheme has been implemented on MNIST, Fashion-MNIST and Cifar-10 datasets to simulate real situation. We use different base models on the encrypted datasets and compare the results with the RC4 algorithm and differential privacy policy. Experiment results evaluated the efficiency of the proposed design. Specifically, our design can improve the accuracy on MNIST up to 97.26% compared with RC4.The accuracies on the datasets encrypted by ArchNet are 97.26%, 84.15% and 79.80%, and they are 97.31%, 82.31% and 80.22% on the original datasets, which shows that the encrypted accuracy of ArchNet has the same performance as the base model. It also shows that ArchNet can be deployed on the distributed system with embedded devices.
Consistent Video Depth Estimation
Apr 30, 2020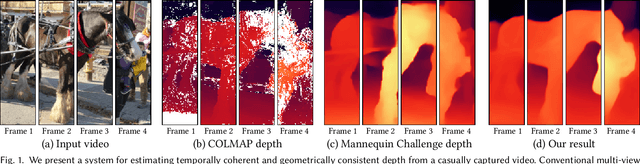
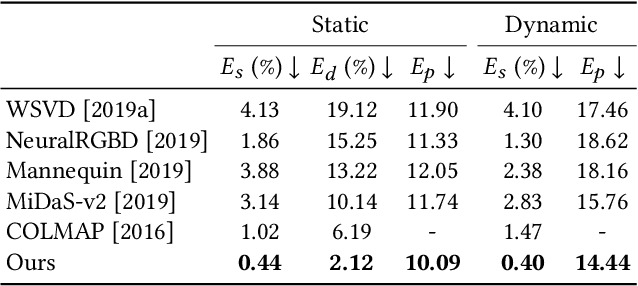
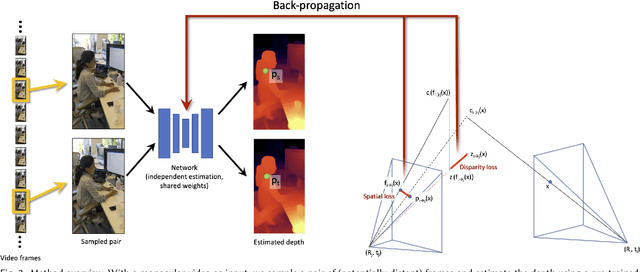
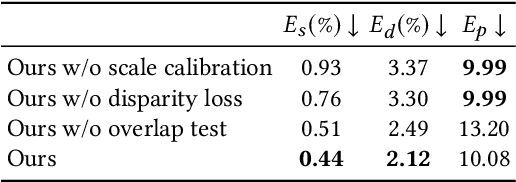
We present an algorithm for reconstructing dense, geometrically consistent depth for all pixels in a monocular video. We leverage a conventional structure-from-motion reconstruction to establish geometric constraints on pixels in the video. Unlike the ad-hoc priors in classical reconstruction, we use a learning-based prior, i.e., a convolutional neural network trained for single-image depth estimation. At test time, we fine-tune this network to satisfy the geometric constraints of a particular input video, while retaining its ability to synthesize plausible depth details in parts of the video that are less constrained. We show through quantitative validation that our method achieves higher accuracy and a higher degree of geometric consistency than previous monocular reconstruction methods. Visually, our results appear more stable. Our algorithm is able to handle challenging hand-held captured input videos with a moderate degree of dynamic motion. The improved quality of the reconstruction enables several applications, such as scene reconstruction and advanced video-based visual effects.
Visual-Textual Association with Hardest and Semi-Hard Negative Pairs Mining for Person Search
Dec 06, 2019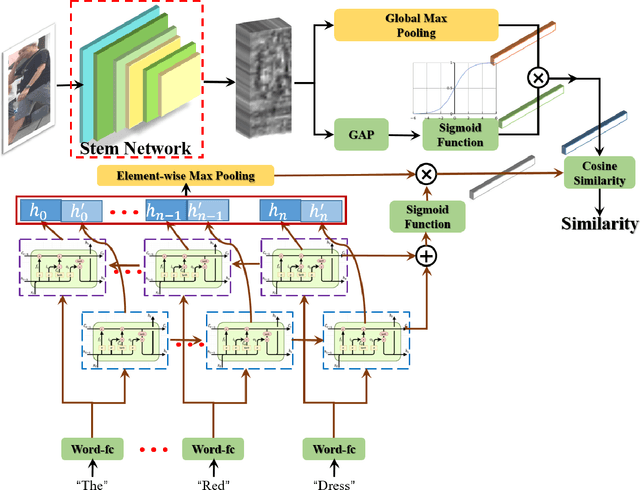
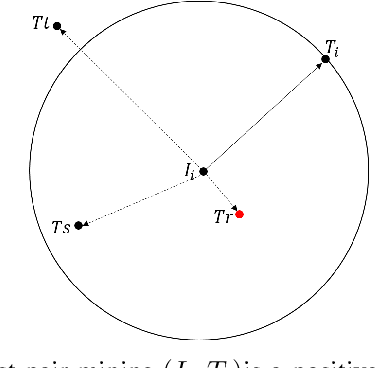
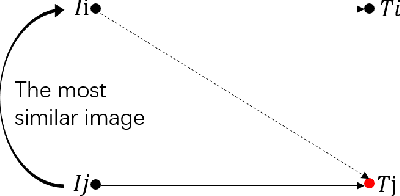
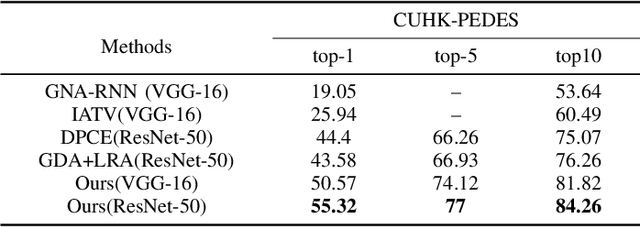
Searching persons in large-scale image databases with the query of natural language description is a more practical important applications in video surveillance. Intuitively, for person search, the core issue should be visual-textual association, which is still an extremely challenging task, due to the contradiction between the high abstraction of textual description and the intuitive expression of visual images. However, for this task, while positive image-text pairs are always well provided, most existing methods doesn't tackle this problem effectively by mining more reasonable negative pairs. In this paper, we proposed a novel visual-textual association approach with visual and textual attention, and cross-modality hardest and semi-hard negative pair mining. In order to evaluate the effectiveness and feasibility of the proposed approach, we conduct extensive experiments on typical person search datasdet: CUHK-PEDES, in which our approach achieves the top1 score of 55.32% as a new state-of-the-art. Besides, we also evaluate the semi-hard pair mining approach in COCO caption dataset, and validate the effectiveness and complementarity of the methods.
Hybrid Robotic-assisted Frameworks for Endomicroscopy Scanning in Retinal Surgeries
Sep 15, 2019
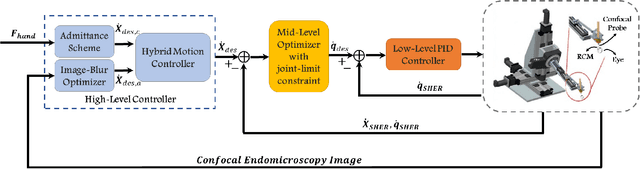
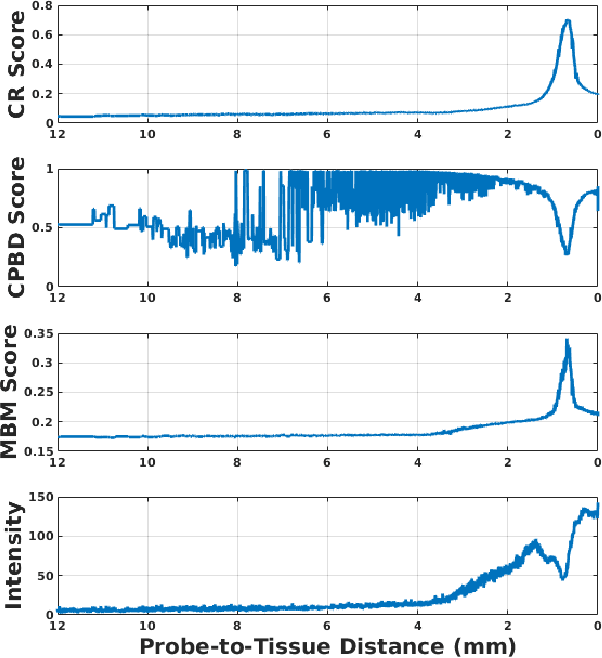
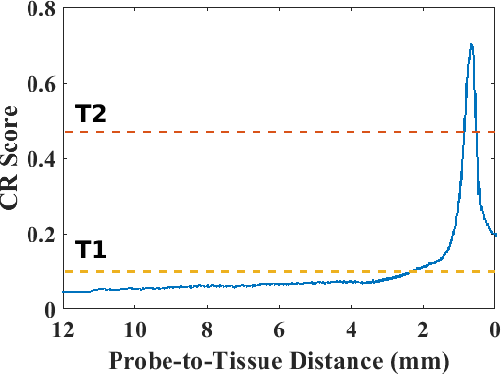
High-resolution real-time imaging at cellular levelin retinal surgeries is very challenging due to extremely confinedspace within the eyeball and lack of appropriate modalities.Probe-based confocal laser endomicroscopy (pCLE) system,which has a small footprint and provides highly-magnified im-ages, can be a potential imaging modality for improved diagnosis.The ability to visualize in cellular-level the retinal pigmentepithelium and the chorodial blood vessels underneath canprovide useful information for surgical outcomes in conditionssuch as retinal detachment. However, the adoption of pCLE islimited due to narrow field of view and micron-level range offocus. The physiological tremor of surgeons' hand also deterioratethe image quality considerably and leads to poor imaging results. In this paper, a novel image-based hybrid motion controlapproach is proposed to mitigate challenges of using pCLEin retinal surgeries. The proposed framework enables sharedcontrol of the pCLE probe by a surgeon to scan the tissueprecisely without hand tremors and an auto-focus image-basedcontrol algorithm that optimizes quality of pCLE images. Thecontrol strategy is deployed on two semi-autonomous frameworks: cooperative and teleoperated. Both frameworks consist of theSteady-Hand Eye Robot (SHER), whose end-effector holds thepCLE probe...