 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Convolutional Transformation Network for Malware Classification
Sep 16, 2019


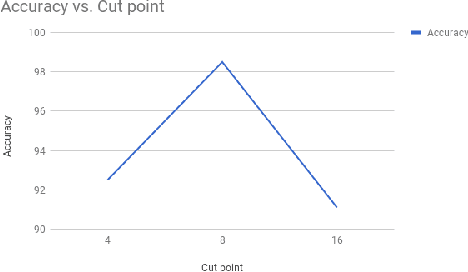
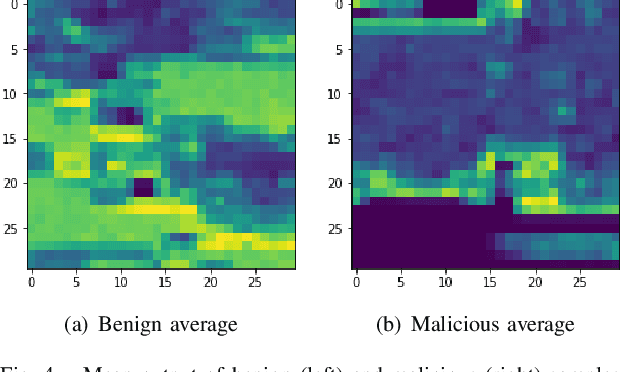
Modern malware evolves various detection avoidance techniques to bypass the state-of-the-art detection methods. An emerging trend to deal with this issue is the combination of image transformation and machine learning techniques to classify and detect malware. However, existing works in this field only perform simple image transformation methods that limit the accuracy of the detection. In this paper, we introduce a novel approach to classify malware by using a deep network on images transformed from binary samples. In particular, we first develop a novel hybrid image transformation method to convert binaries into color images that convey the binary semantics. The images are trained by a deep convolutional neural network that later classifies the test inputs into benign or malicious categories. Through the extensive experiments, our proposed method surpasses all baselines and achieves 99.14% in terms of accuracy on the testing set.
AE TextSpotter: Learning Visual and Linguistic Representation for Ambiguous Text Spotting
Aug 05, 2020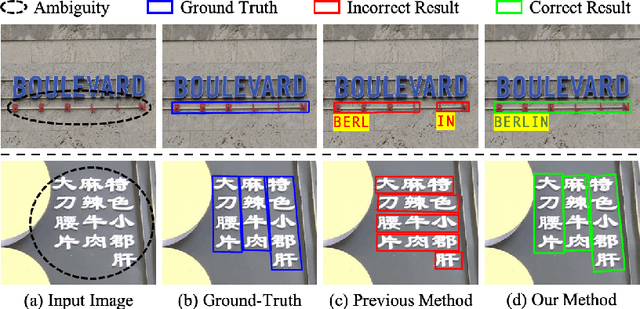
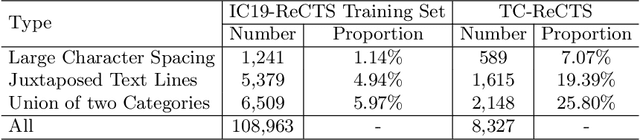

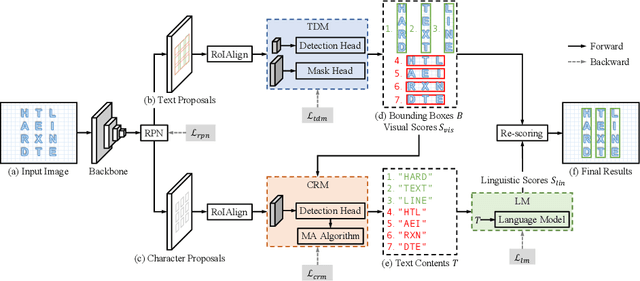
Scene text spotting aims to detect and recognize the entire word or sentence with multiple characters in natural images. It is still challenging because ambiguity often occurs when the spacing between characters is large or the characters are evenly spread in multiple rows and columns, making many visually plausible groupings of the characters (e.g. "BERLIN" is incorrectly detected as "BERL" and "IN" in Fig. 1(c)). Unlike previous works that merely employed visual features for text detection, this work proposes a novel text spotter, named Ambiguity Eliminating Text Spotter (AE TextSpotter), which learns both visual and linguistic features to significantly reduce ambiguity in text detection. The proposed AE TextSpotter has three important benefits. 1) The linguistic representation is learned together with the visual representation in a framework. To our knowledge, it is the first time to improve text detection by using a language model. 2) A carefully designed language module is utilized to reduce the detection confidence of incorrect text lines, making them easily pruned in the detection stage. 3) Extensive experiments show that AE TextSpotter outperforms other state-of-the-art methods by a large margin. For example, we carefully select a validation set of extremely ambiguous samples from the IC19-ReCTS dataset, where our approach surpasses other methods by more than 4%. The image list and evaluation scripts of the validation set have been released at https://github.com/whai362/TDA-ReCTS.
Object Detection on Single Monocular Images through Canonical Correlation Analysis
Feb 13, 2020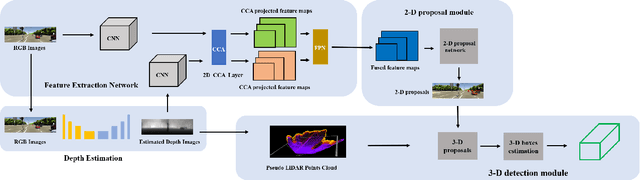


Without using extra 3-D data like points cloud or depth images for providing 3-D information, we retrieve the 3-D object information from single monocular images. The high-quality predicted depth images are recovered from single monocular images, and it is fed into the 2-D object proposal network with corresponding monocular images. Most existing deep learning frameworks with two-streams input data always fuse separate data by concatenating or adding, which views every part of a feature map can contribute equally to the whole task. However, when data are noisy, and too much information is redundant, these methods no longer produce predictions or classifications efficiently. In this report, we propose a two-dimensional CCA(canonical correlation analysis) framework to fuse monocular images and corresponding predicted depth images for basic computer vision tasks like image classification and object detection. Firstly, we implemented different structures with one-dimensional CCA and Alexnet to test the performance on the image classification task. And then, we applied one of these structures with 2D-CCA for object detection. During these experiments, we found that our proposed framework behaves better when taking predicted depth images as inputs with the model trained from ground truth depth.
Fine-grained Image Classification by Exploring Bipartite-Graph Labels
Dec 10, 2015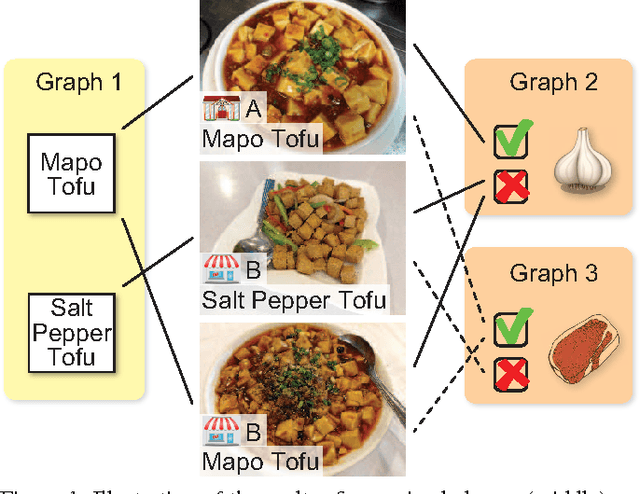
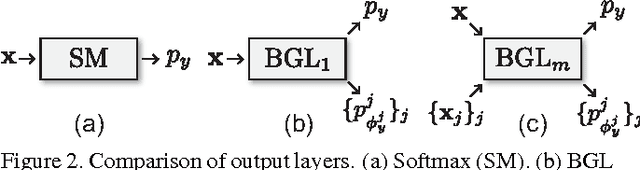

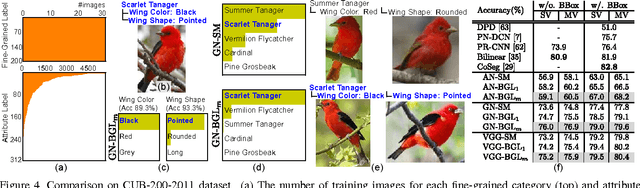
Given a food image, can a fine-grained object recognition engine tell "which restaurant which dish" the food belongs to? Such ultra-fine grained image recognition is the key for many applications like search by images, but it is very challenging because it needs to discern subtle difference between classes while dealing with the scarcity of training data. Fortunately, the ultra-fine granularity naturally brings rich relationships among object classes. This paper proposes a novel approach to exploit the rich relationships through bipartite-graph labels (BGL). We show how to model BGL in an overall convolutional neural networks and the resulting system can be optimized through back-propagation. We also show that it is computationally efficient in inference thanks to the bipartite structure. To facilitate the study, we construct a new food benchmark dataset, which consists of 37,885 food images collected from 6 restaurants and totally 975 menus. Experimental results on this new food and three other datasets demonstrates BGL advances previous works in fine-grained object recognition. An online demo is available at http://www.f-zhou.com/fg_demo/.
Visualization for Histopathology Images using Graph Convolutional Neural Networks
Jun 16, 2020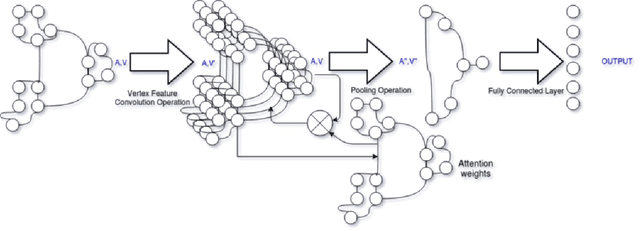
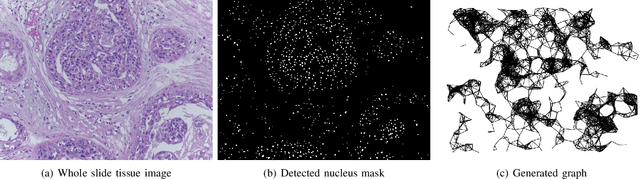
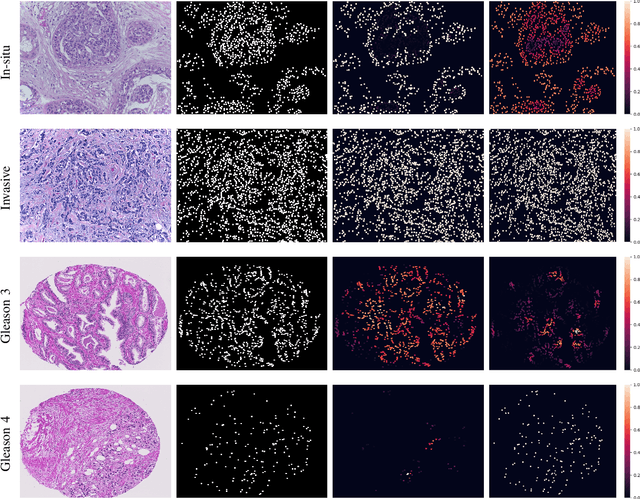
With the increase in the use of deep learning for computer-aided diagnosis in medical images, the criticism of the black-box nature of the deep learning models is also on the rise. The medical community needs interpretable models for both due diligence and advancing the understanding of disease and treatment mechanisms. In histology, in particular, while there is rich detail available at the cellular level and that of spatial relationships between cells, it is difficult to modify convolutional neural networks to point out the relevant visual features. We adopt an approach to model histology tissue as a graph of nuclei and develop a graph convolutional network framework based on attention mechanism and node occlusion for disease diagnosis. The proposed method highlights the relative contribution of each cell nucleus in the whole-slide image. Our visualization of such networks trained to distinguish between invasive and in-situ breast cancers, and Gleason 3 and 4 prostate cancers generate interpretable visual maps that correspond well with our understanding of the structures that are important to experts for their diagnosis.
DeepHAZMAT: Hazardous Materials Sign Detection and Segmentation with Restricted Computational Resources
Jul 13, 2020



One of the most challenging and non-trivial tasks in robotics-based rescue operations is Hazardous Materials or HAZMATs sign detection within the operation field, in order to prevent other unexpected disasters. Each Hazmat sign has a specific meaning that the rescue robot should detect and interpret it to take a safe action, accordingly. Accurate Hazmat detection and real-time processing are the two most important factors in such robotics applications. Furthermore, we also have to cope with some secondary challengers such as image distortion problems and restricted CPU and computational resources which are embedded in a rescue robot. In this paper, we propose a CNN-Based pipeline called DeepHAZMAT for detecting and segmenting Hazmats in four steps; 1) optimising the number of input images that are fed into the CNN network, 2) using the YOLOv3-tiny structure to collect the required visual information from the hazardous areas, 3) Hazmat sign segmentation and separation from the background using GrabCut technique, and 4) post-processing the result with morphological operators and convex hall algorithm. In spite of the utilisation of a very limited memory and CPU resources, the experimental results show the proposed method has successfully maintained a better performance in terms of detection-speed and detection-accuracy, compared with the state-of-the-art methods.
Point-Set Anchors for Object Detection, Instance Segmentation and Pose Estimation
Jul 13, 2020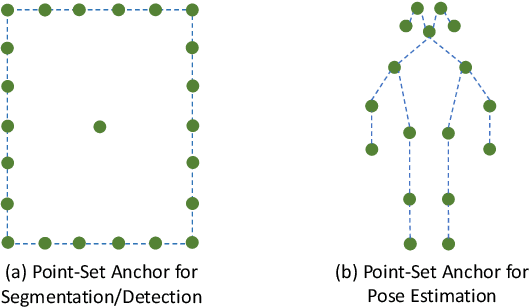

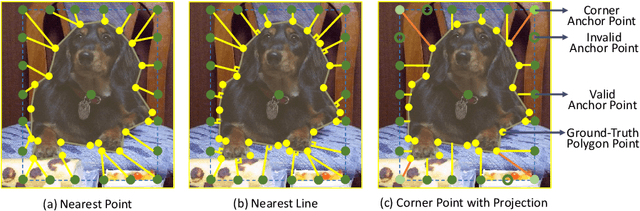

A recent approach for object detection and human pose estimation is to regress bounding boxes or human keypoints from a central point on the object or person. While this center-point regression is simple and efficient, we argue that the image features extracted at a central point contain limited information for predicting distant keypoints or bounding box boundaries, due to object deformation and scale/orientation variation. To facilitate inference, we propose to instead perform regression from a set of points placed at more advantageous positions. This point set is arranged to reflect a good initialization for the given task, such as modes in the training data for pose estimation, which lie closer to the ground truth than the central point and provide more informative features for regression. As the utility of a point set depends on how well its scale, aspect ratio and rotation matches the target, we adopt the anchor box technique of sampling these transformations to generate additional point-set candidates. We apply this proposed framework, called Point-Set Anchors, to object detection, instance segmentation, and human pose estimation. Our results show that this general-purpose approach can achieve performance competitive with state-of-the-art methods for each of these tasks.
Deep Feature Space: A Geometrical Perspective
Jun 30, 2020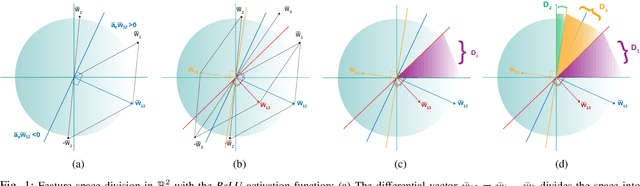
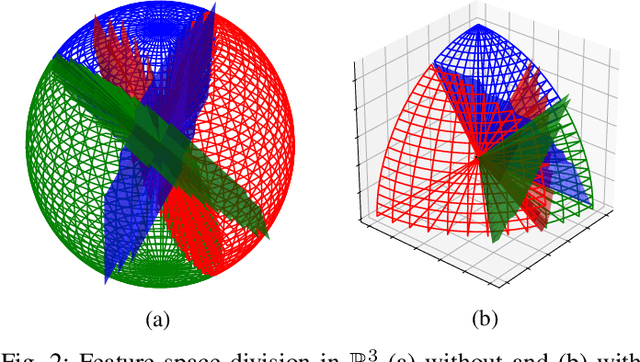
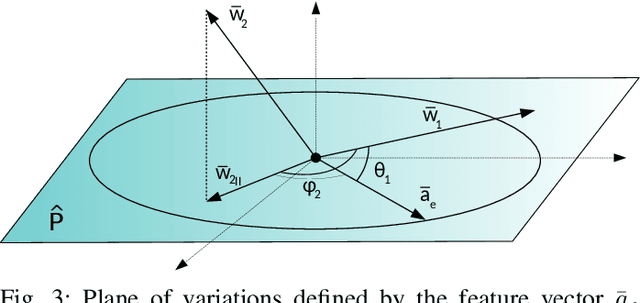
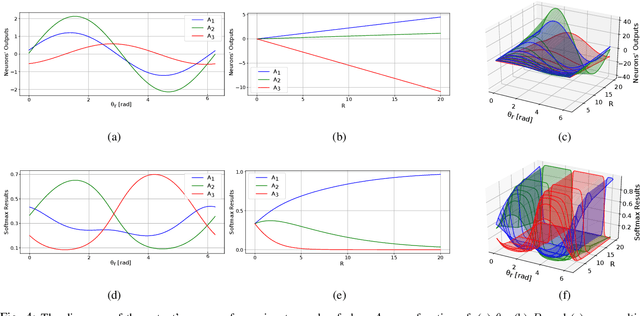
One of the most prominent attributes of Neural Networks (NNs) constitutes their capability of learning to extract robust and descriptive features from high dimensional data, like images. Hence, such an ability renders their exploitation as feature extractors particularly frequent in an abundant of modern reasoning systems. Their application scope mainly includes complex cascade tasks, like multi-modal recognition and deep Reinforcement Learning (RL). However, NNs induce implicit biases that are difficult to avoid or to deal with and are not met in traditional image descriptors. Moreover, the lack of knowledge for describing the intra-layer properties -- and thus their general behavior -- restricts the further applicability of the extracted features. With the paper at hand, a novel way of visualizing and understanding the vector space before the NNs' output layer is presented, aiming to enlighten the deep feature vectors' properties under classification tasks. Main attention is paid to the nature of overfitting in the feature space and its adverse effect on further exploitation. We present the findings that can be derived from our model's formulation, and we evaluate them on realistic recognition scenarios, proving its prominence by improving the obtained results.
Deep 3D Pan via adaptive "t-shaped" convolutions with global and local adaptive dilations
Oct 02, 2019
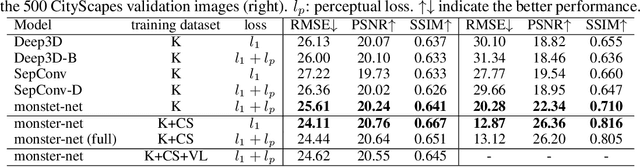
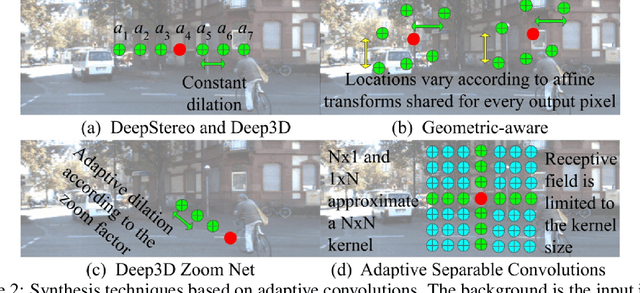
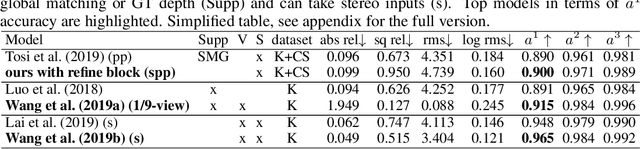
Recent advances in deep learning have shown promising results in many low-level vision tasks. However, solving the single-image-based view synthesis is still an open problem. In particular, the generation of new images at parallel camera views given a single input image is of great interest, as it enables 3D visualization of the 2D input scenery. We propose a novel network architecture to perform stereoscopic view synthesis at arbitrary camera positions along the X-axis, or Deep 3D Pan, with "t-shaped" adaptive kernels equipped with globally and locally adaptive dilations. Our proposed network architecture, the monster-net, is devised with a novel "t-shaped" adaptive kernel with globally and locally adaptive dilation, which can efficiently incorporate global camera shift into and handle local 3D geometries of the target image's pixels for the synthesis of naturally looking 3D panned views when a 2-D input image is given. Extensive experiments were performed on the KITTI, CityScapes and our VICLAB_STEREO indoors dataset to prove the efficacy of our method. Our monster-net significantly outperforms the state-of-the-art method, SOTA, by a large margin in all metrics of RMSE, PSNR, and SSIM. Our proposed monster-net is capable of reconstructing more reliable image structures in synthesized images with coherent geometry. Moreover, the disparity information that can be extracted from the "t-shaped" kernel is much more reliable than that of the SOTA for the unsupervised monocular depth estimation task, confirming the effectiveness of our method.
Fine-Grained Neural Architecture Search
Nov 18, 2019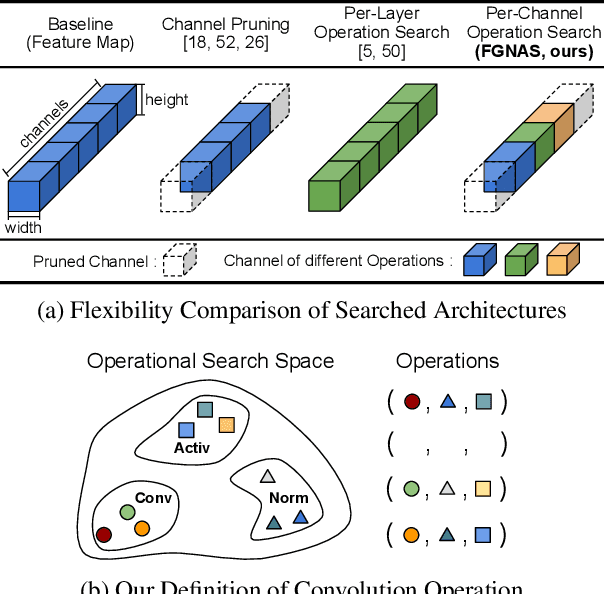

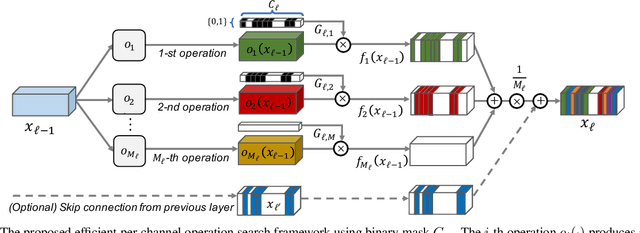

We present an elegant framework of fine-grained neural architecture search (FGNAS), which allows to employ multiple heterogeneous operations within a single layer and can even generate compositional feature maps using several different base operations. FGNAS runs efficiently in spite of significantly large search space compared to other methods because it trains networks end-to-end by a stochastic gradient descent method. Moreover, the proposed framework allows to optimize the network under predefined resource constraints in terms of number of parameters, FLOPs and latency. FGNAS has been applied to two crucial applications in resource demanding computer vision tasks---large-scale image classification and image super-resolution---and demonstrates the state-of-the-art performance through flexible operation search and channel pruning.