 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Two-stage Discriminative Re-ranking for Large-scale Landmark Retrieval
Mar 25, 2020
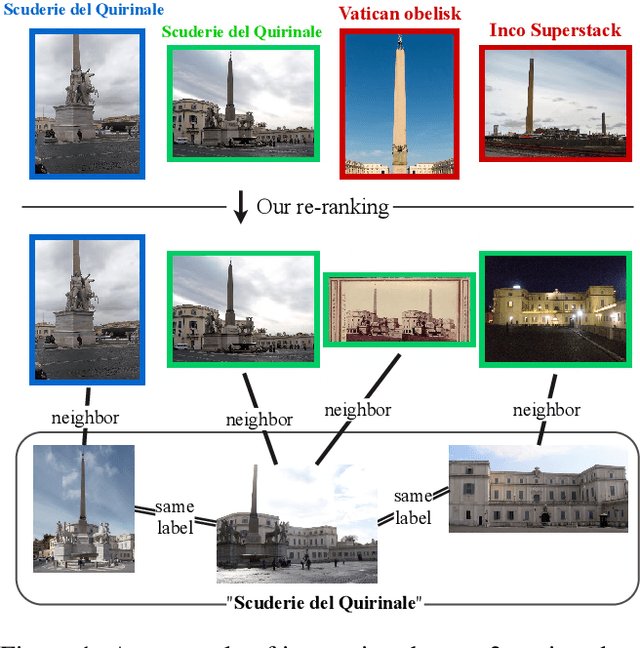
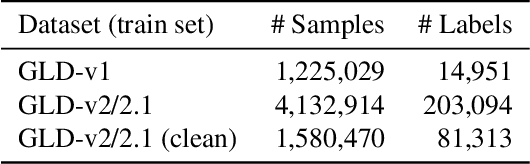
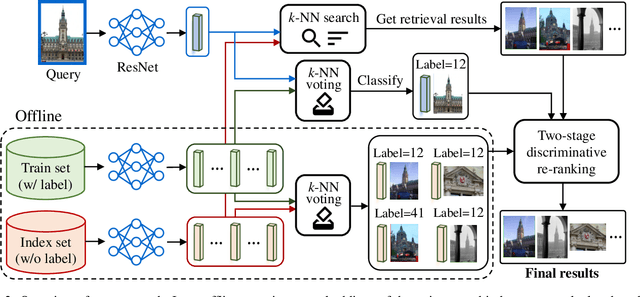
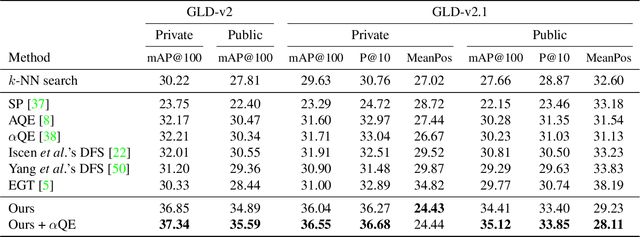
We propose an efficient pipeline for large-scale landmark image retrieval that addresses the diversity of the dataset through two-stage discriminative re-ranking. Our approach is based on embedding the images in a feature-space using a convolutional neural network trained with a cosine softmax loss. Due to the variance of the images, which include extreme viewpoint changes such as having to retrieve images of the exterior of a landmark from images of the interior, this is very challenging for approaches based exclusively on visual similarity. Our proposed re-ranking approach improves the results in two steps: in the sort-step, $k$-nearest neighbor search with soft-voting to sort the retrieved results based on their label similarity to the query images, and in the insert-step, we add additional samples from the dataset that were not retrieved by image-similarity. This approach allows overcoming the low visual diversity in retrieved images. In-depth experimental results show that the proposed approach significantly outperforms existing approaches on the challenging Google Landmarks Datasets. Using our methods, we achieved 1st place in the Google Landmark Retrieval 2019 challenge and 3rd place in the Google Landmark Recognition 2019 challenge on Kaggle. Our code is publicly available here: \url{https://github.com/lyakaap/Landmark2019-1st-and-3rd-Place-Solution}
PatchPerPix for Instance Segmentation
Jan 21, 2020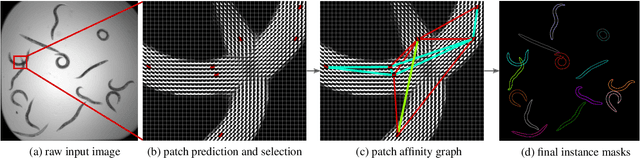
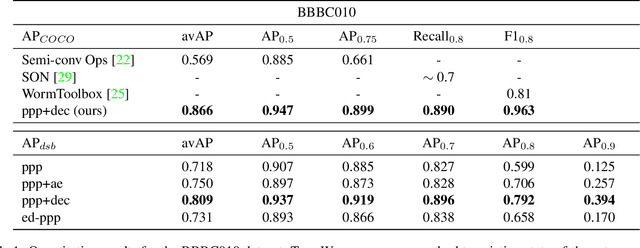
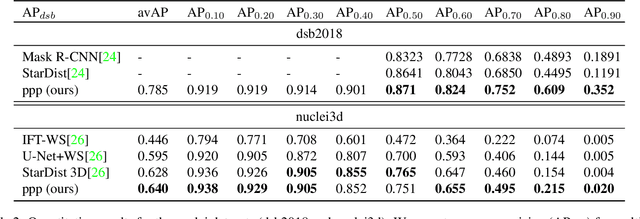
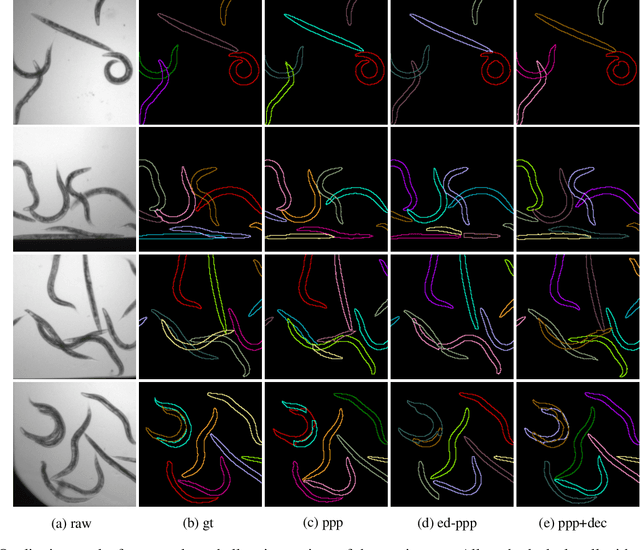
In this paper we present a novel method for proposal free instance segmentation that can handle sophisticated object shapes that span large parts of an image and form dense object clusters with crossovers. Our method is based on predicting dense local shape descriptors, which we assemble to form instances. All instances are assembled simultaneously in one go. To our knowledge, our method is the first non-iterative method that guarantees instances to be composed of learnt shape patches. We evaluate our method on a variety of data domains, where it defines the new state of the art on two challenging benchmarks, namely the ISBI 2012 EM segmentation benchmark, and the BBBC010 C. elegans dataset. We show furthermore that our method performs well also on 3d image data, and can handle even extreme cases of complex shape clusters.
Deep Collective Learning: Learning Optimal Inputs and Weights Jointly in Deep Neural Networks
Sep 17, 2020
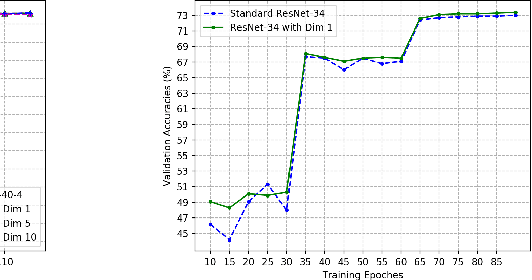
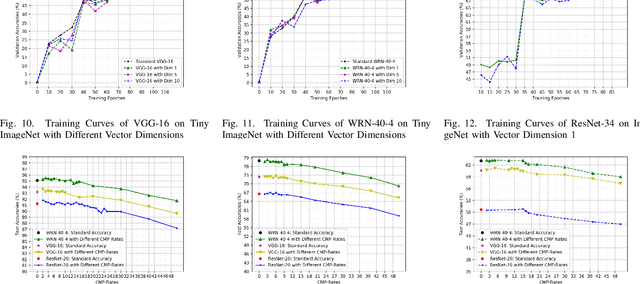

It is well observed that in deep learning and computer vision literature, visual data are always represented in a manually designed coding scheme (eg., RGB images are represented as integers ranging from 0 to 255 for each channel) when they are input to an end-to-end deep neural network (DNN) for any learning task. We boldly question whether the manually designed inputs are good for DNN training for different tasks and study whether the input to a DNN can be optimally learned end-to-end together with learning the weights of the DNN. In this paper, we propose the paradigm of {\em deep collective learning} which aims to learn the weights of DNNs and the inputs to DNNs simultaneously for given tasks. We note that collective learning has been implicitly but widely used in natural language processing while it has almost never been studied in computer vision. Consequently, we propose the lookup vision networks (Lookup-VNets) as a solution to deep collective learning in computer vision. This is achieved by associating each color in each channel with a vector in lookup tables. As learning inputs in computer vision has almost never been studied in the existing literature, we explore several aspects of this question through varieties of experiments on image classification tasks. Experimental results on four benchmark datasets, i.e., CIFAR-10, CIFAR-100, Tiny ImageNet, and ImageNet (ILSVRC2012) have shown several surprising characteristics of Lookup-VNets and have demonstrated the advantages and promise of Lookup-VNets and deep collective learning.
SoftSort: A Continuous Relaxation for the argsort Operator
Jun 29, 2020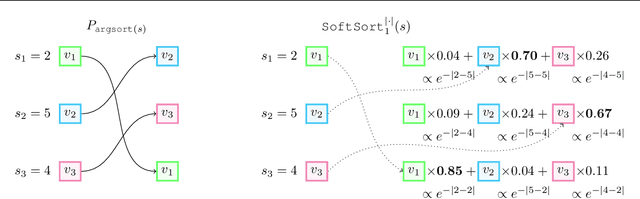

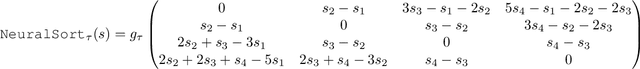

While sorting is an important procedure in computer science, the argsort operator - which takes as input a vector and returns its sorting permutation - has a discrete image and thus zero gradients almost everywhere. This prohibits end-to-end, gradient-based learning of models that rely on the argsort operator. A natural way to overcome this problem is to replace the argsort operator with a continuous relaxation. Recent work has shown a number of ways to do this, but the relaxations proposed so far are computationally complex. In this work we propose a simple continuous relaxation for the argsort operator which has the following qualities: it can be implemented in three lines of code, achieves state-of-the-art performance, is easy to reason about mathematically - substantially simplifying proofs - and is faster than competing approaches. We open source the code to reproduce all of the experiments and results.
GOLD-NAS: Gradual, One-Level, Differentiable
Jul 07, 2020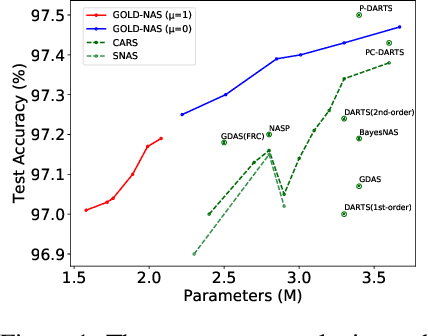
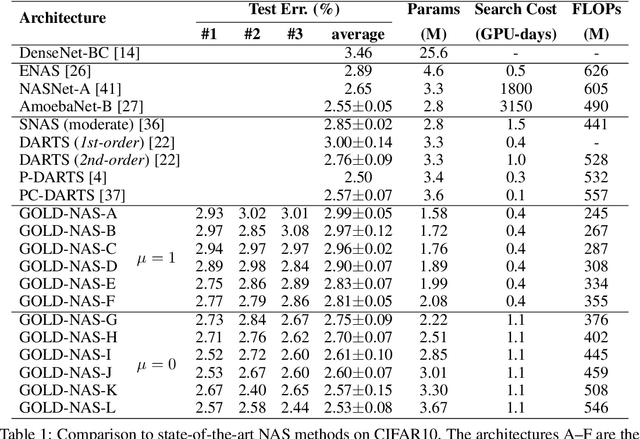
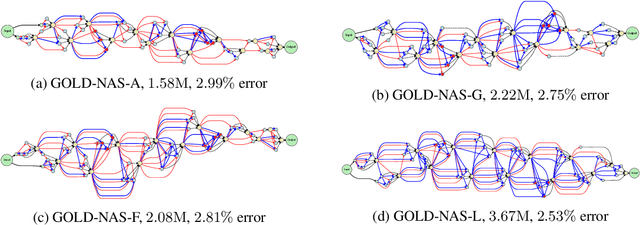
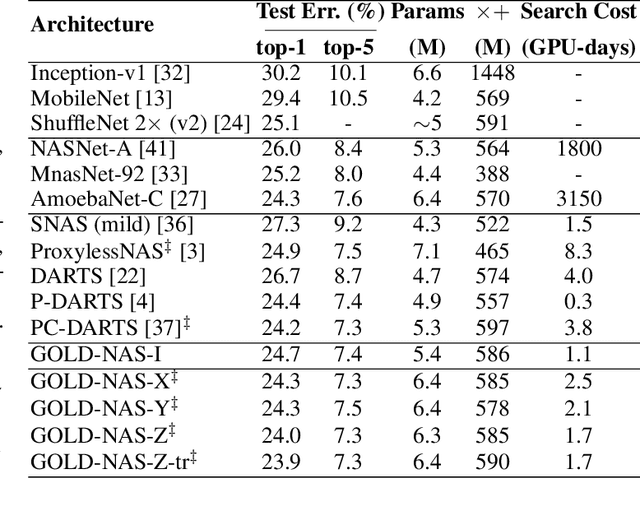
There has been a large literature of neural architecture search, but most existing work made use of heuristic rules that largely constrained the search flexibility. In this paper, we first relax these manually designed constraints and enlarge the search space to contain more than $10^{160}$ candidates. In the new space, most existing differentiable search methods can fail dramatically. We then propose a novel algorithm named Gradual One-Level Differentiable Neural Architecture Search (GOLD-NAS) which introduces a variable resource constraint to one-level optimization so that the weak operators are gradually pruned out from the super-network. In standard image classification benchmarks, GOLD-NAS can find a series of Pareto-optimal architectures within a single search procedure. Most of the discovered architectures were never studied before, yet they achieve a nice tradeoff between recognition accuracy and model complexity. We believe the new space and search algorithm can advance the search of differentiable NAS.
Review of Artificial Intelligence Techniques in Imaging Data Acquisition, Segmentation and Diagnosis for COVID-19
Apr 07, 2020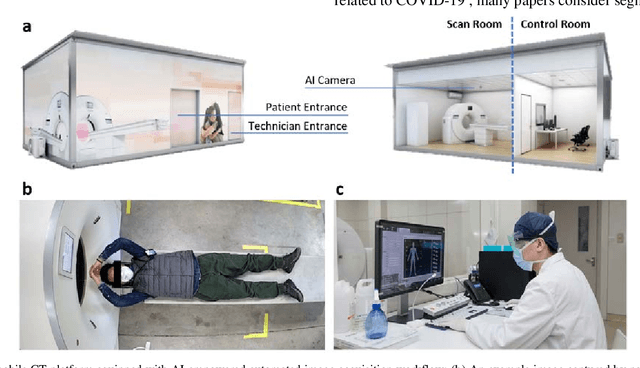
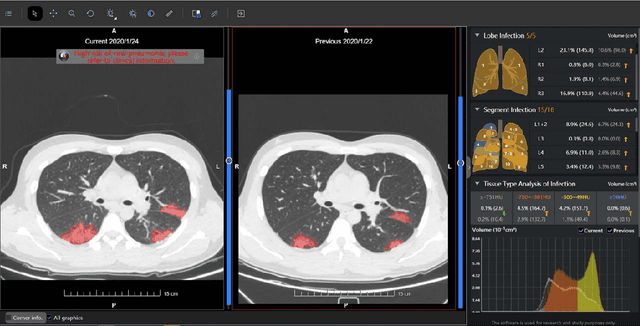
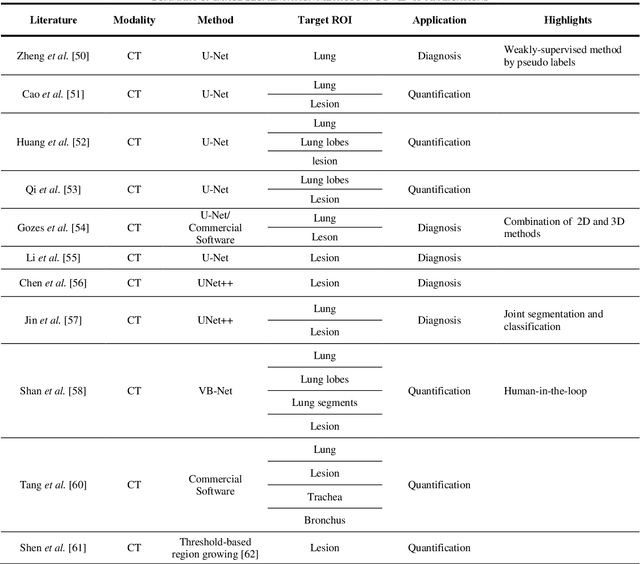
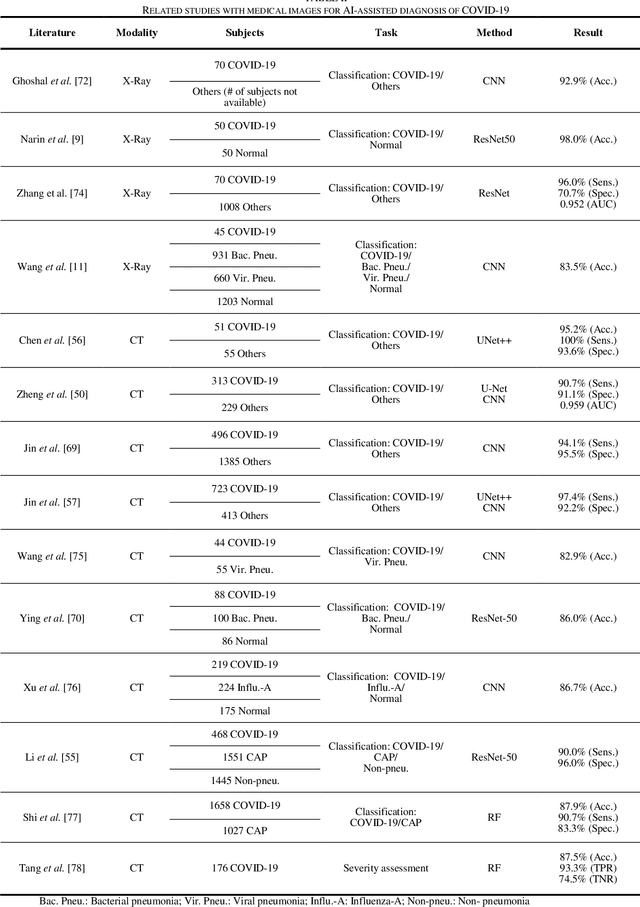
(This paper was submitted as an invited paper to IEEE Reviews in Biomedical Engineering on April 6, 2020.) The pandemic of coronavirus disease 2019 (COVID-19) is spreading all over the world. Medical imaging such as X-ray and computed tomography (CT) plays an essential role in the global fight against COVID-19, whereas the recently emerging artificial intelligence (AI) technologies further strengthen the power of the imaging tools and help medical specialists. We hereby review the rapid responses in the community of medical imaging (empowered by AI) toward COVID-19. For example, AI-empowered image acquisition can significantly help automate the scanning procedure and also reshape the workflow with minimal contact to patients, providing the best protection to the imaging technicians. Also, AI can improve work efficiency by accurate delination of infections in X-ray and CT images, facilitating subsequent quantification. Moreover, the computer-aided platforms help radiologists make clinical decisions, i.e., for disease diagnosis, tracking, and prognosis. In this review paper, we thus cover the entire pipeline of medical imaging and analysis techniques involved with COVID-19, including image acquisition, segmentation, diagnosis, and follow-up. We particularly focus on the integration of AI with X-ray and CT, both of which are widely used in the frontline hospitals, in order to depict the latest progress of medical imaging and radiology fighting against COVID-19.
How Can We Make GAN Perform Better in Single Medical Image Super-Resolution? A Lesion Focused Multi-Scale Approach
Jan 10, 2019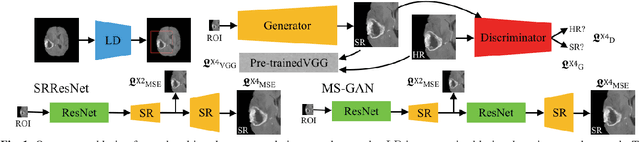
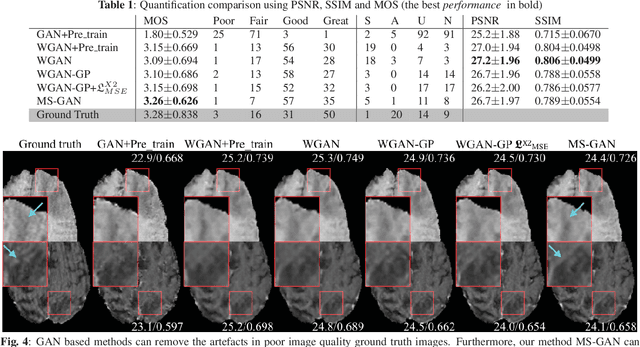
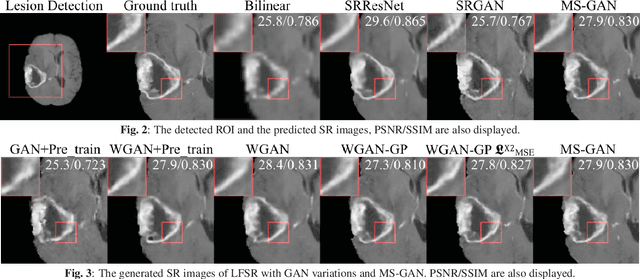
Single image super-resolution (SISR) is of great importance as a low-level computer vision task. The fast development of Generative Adversarial Network (GAN) based deep learning architectures realises an efficient and effective SISR to boost the spatial resolution of natural images captured by digital cameras. However, the SISR for medical images is still a very challenging problem. This is due to (1) compared to natural images, in general, medical images have lower signal to noise ratios, (2) GAN based models pre-trained on natural images may synthesise unrealistic patterns in medical images which could affect the clinical interpretation and diagnosis, and (3) the vanilla GAN architecture may suffer from unstable training and collapse mode that can also affect the SISR results. In this paper, we propose a novel lesion focused SR (LFSR) method, which incorporates GAN to achieve perceptually realistic SISR results for brain tumour MRI images. More importantly, we test and make comparison using recently developed GAN variations, e.g., Wasserstein GAN (WGAN) and WGAN with Gradient Penalty (WGAN-GP), and propose a novel multi-scale GAN (MS-GAN), to achieve a more stabilised and efficient training and improved perceptual quality of the super-resolved results. Based on both quantitative evaluations and our designed mean opinion score, the proposed LFSR coupled with MS-GAN has performed better in terms of both perceptual quality and efficiency.
Instance Segmentation of Visible and Occluded Regions for Finding and Picking Target from a Pile of Objects
Jan 21, 2020



We present a robotic system for picking a target from a pile of objects that is capable of finding and grasping the target object by removing obstacles in the appropriate order. The fundamental idea is to segment instances with both visible and occluded masks, which we call `instance occlusion segmentation'. To achieve this, we extend an existing instance segmentation model with a novel `relook' architecture, in which the model explicitly learns the inter-instance relationship. Also, by using image synthesis, we make the system capable of handling new objects without human annotations. The experimental results show the effectiveness of the relook architecture when compared with a conventional model and of the image synthesis when compared to a human-annotated dataset. We also demonstrate the capability of our system to achieve picking a target in a cluttered environment with a real robot.
Assessing Automated Machine Learning service to detect COVID-19 from X-Ray and CT images: A Real-time Smartphone Application case study
Oct 03, 2020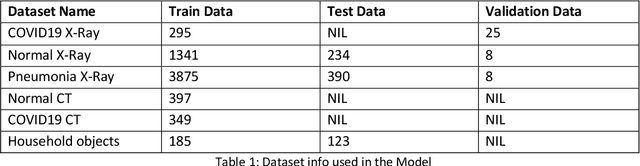
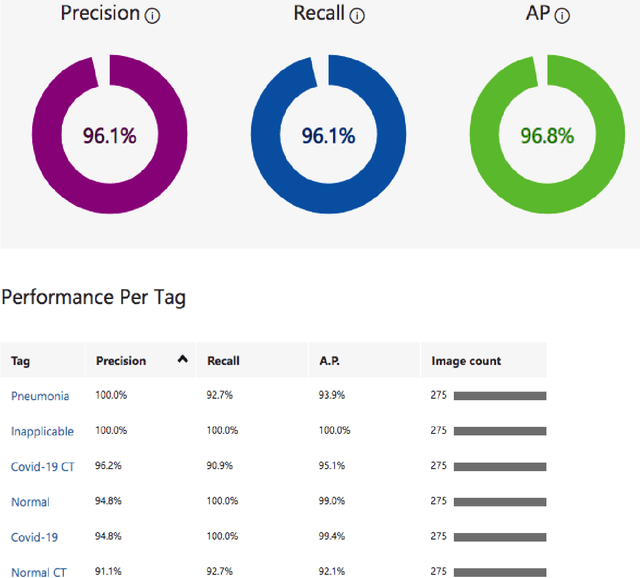
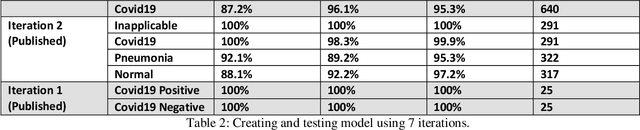
The recent outbreak of SARS COV-2 gave us a unique opportunity to study for a non interventional and sustainable AI solution. Lung disease remains a major healthcare challenge with high morbidity and mortality worldwide. The predominant lung disease was lung cancer. Until recently, the world has witnessed the global pandemic of COVID19, the Novel coronavirus outbreak. We have experienced how viral infection of lung and heart claimed thousands of lives worldwide. With the unprecedented advancement of Artificial Intelligence in recent years, Machine learning can be used to easily detect and classify medical imagery. It is much faster and most of the time more accurate than human radiologists. Once implemented, it is more cost-effective and time-saving. In our study, we evaluated the efficacy of Microsoft Cognitive Service to detect and classify COVID19 induced pneumonia from other Viral/Bacterial pneumonia based on X-Ray and CT images. We wanted to assess the implication and accuracy of the Automated ML-based Rapid Application Development (RAD) environment in the field of Medical Image diagnosis. This study will better equip us to respond with an ML-based diagnostic Decision Support System(DSS) for a Pandemic situation like COVID19. After optimization, the trained network achieved 96.8% Average Precision which was implemented as a Web Application for consumption. However, the same trained network did not perform the same like Web Application when ported to Smartphone for Real-time inference. Which was our main interest of study. The authors believe, there is scope for further study on this issue. One of the main goal of this study was to develop and evaluate the performance of AI-powered Smartphone-based Real-time Application. Facilitating primary diagnostic services in less equipped and understaffed rural healthcare centers of the world with unreliable internet service.
* 21 Pages, 6 Tables
Effect of Superpixel Aggregation on Explanations in LIME -- A Case Study with Biological Data
Oct 17, 2019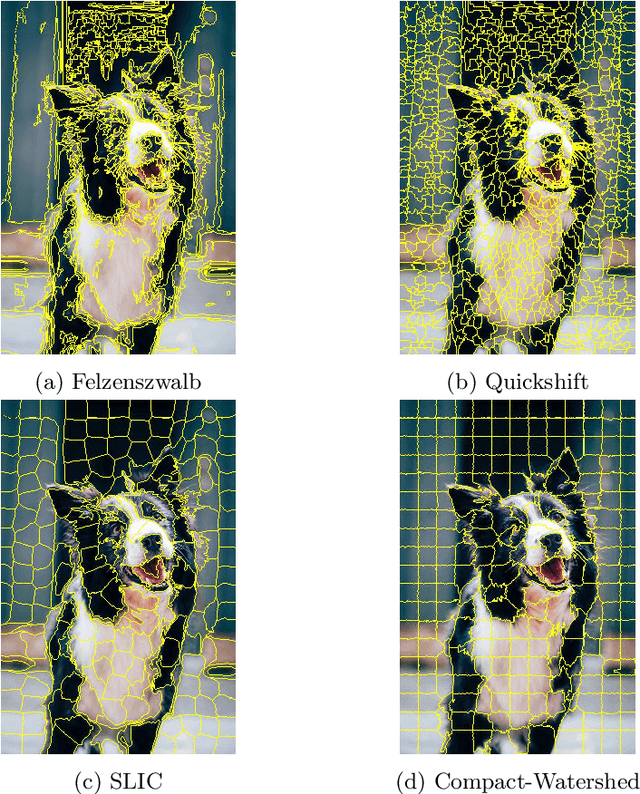
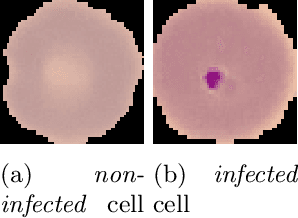
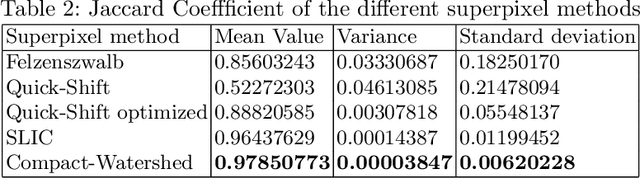

End-to-end learning with deep neural networks, such as convolutional neural networks (CNNs), has been demonstrated to be very successful for different tasks of image classification. To make decisions of black-box approaches transparent, different solutions have been proposed. LIME is an approach to explainable AI relying on segmenting images into superpixels based on the Quick-Shift algorithm. In this paper, we present an explorative study of how different superpixel methods, namely Felzenszwalb, SLIC and Compact-Watershed, impact the generated visual explanations. We compare the resulting relevance areas with the image parts marked by a human reference. Results show that image parts selected as relevant strongly vary depending on the applied method. Quick-Shift resulted in the least and Compact-Watershed in the highest correspondence with the reference relevance areas.