 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Multi-modal Transfer Learning for Grasping Transparent and Specular Objects
May 29, 2020

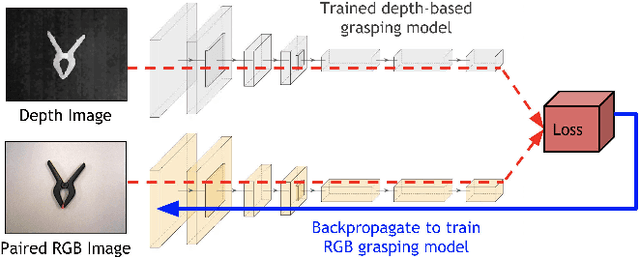
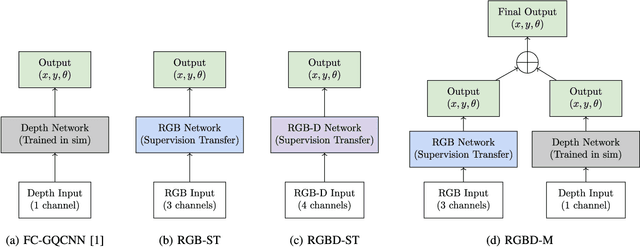

State-of-the-art object grasping methods rely on depth sensing to plan robust grasps, but commercially available depth sensors fail to detect transparent and specular objects. To improve grasping performance on such objects, we introduce a method for learning a multi-modal perception model by bootstrapping from an existing uni-modal model. This transfer learning approach requires only a pre-existing uni-modal grasping model and paired multi-modal image data for training, foregoing the need for ground-truth grasp success labels nor real grasp attempts. Our experiments demonstrate that our approach is able to reliably grasp transparent and reflective objects. Video and supplementary material are available at https://sites.google.com/view/transparent-specular-grasping.
* RA-L with presentation at ICRA 2020
Face Image Classification by Pooling Raw Features
Sep 17, 2014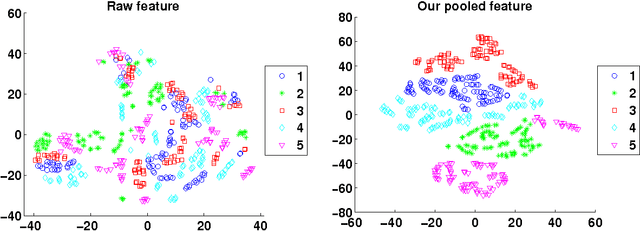
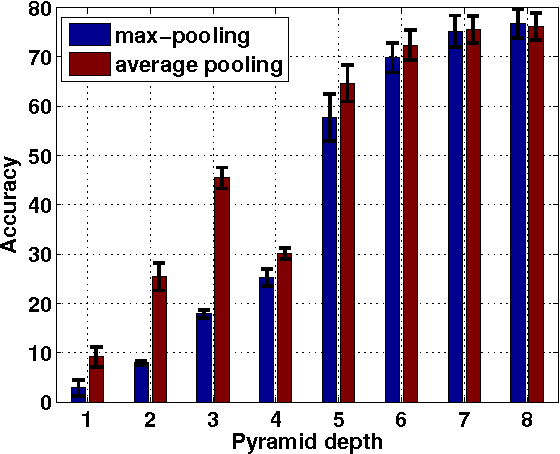
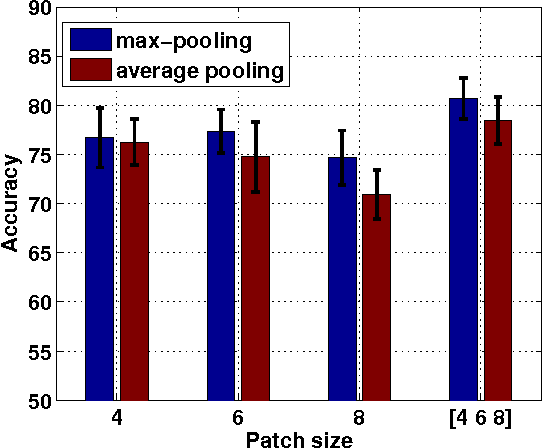
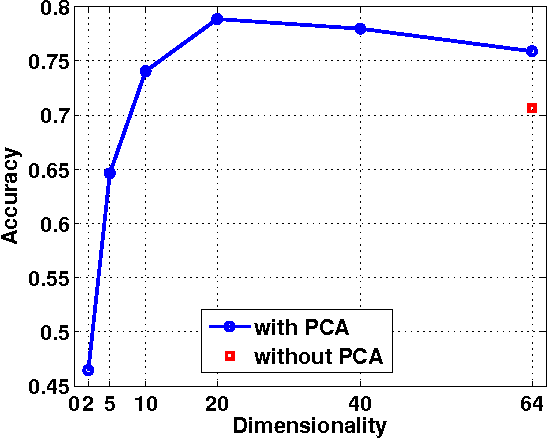
We propose a very simple, efficient yet surprisingly effective feature extraction method for face recognition (about 20 lines of Matlab code), which is mainly inspired by spatial pyramid pooling in generic image classification. We show that features formed by simply pooling local patches over a multi-level pyramid, coupled with a linear classifier, can significantly outperform most recent face recognition methods. The simplicity of our feature extraction procedure is demonstrated by the fact that no learning is involved (except PCA whitening). We show that, multi-level spatial pooling and dense extraction of multi-scale patches play critical roles in face image classification. The extracted facial features can capture strong structural information of individual faces with no label information being used. We also find that, pre-processing on local image patches such as contrast normalization can have an important impact on the classification accuracy. In particular, on the challenging face recognition datasets of FERET and LFW-a, our method improves previous best results by more than 10% and 20%, respectively.
The Relative Performance of Ensemble Methods with Deep Convolutional Neural Networks for Image Classification
Apr 05, 2017

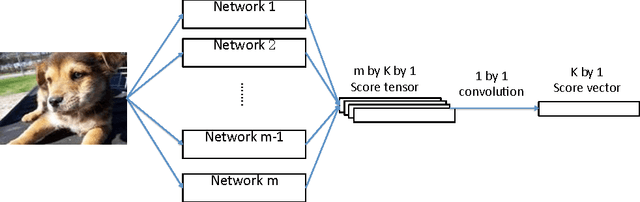
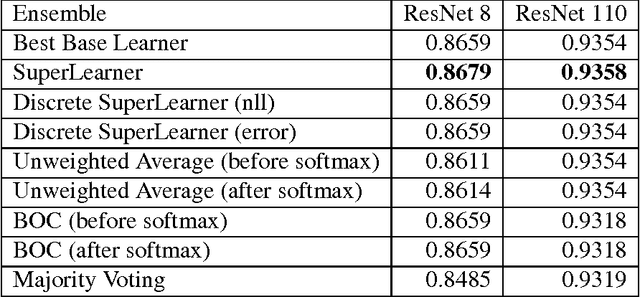
Artificial neural networks have been successfully applied to a variety of machine learning tasks, including image recognition, semantic segmentation, and machine translation. However, few studies fully investigated ensembles of artificial neural networks. In this work, we investigated multiple widely used ensemble methods, including unweighted averaging, majority voting, the Bayes Optimal Classifier, and the (discrete) Super Learner, for image recognition tasks, with deep neural networks as candidate algorithms. We designed several experiments, with the candidate algorithms being the same network structure with different model checkpoints within a single training process, networks with same structure but trained multiple times stochastically, and networks with different structure. In addition, we further studied the over-confidence phenomenon of the neural networks, as well as its impact on the ensemble methods. Across all of our experiments, the Super Learner achieved best performance among all the ensemble methods in this study.
Contrastive Learning for Weakly Supervised Phrase Grounding
Jun 17, 2020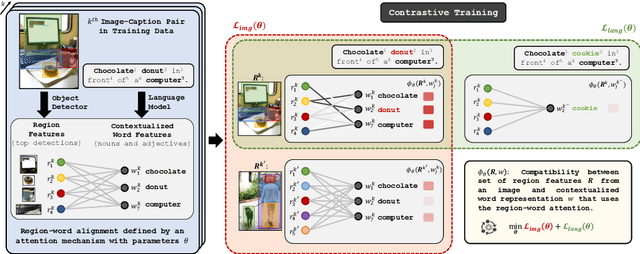
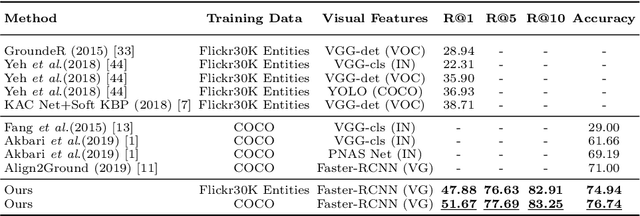
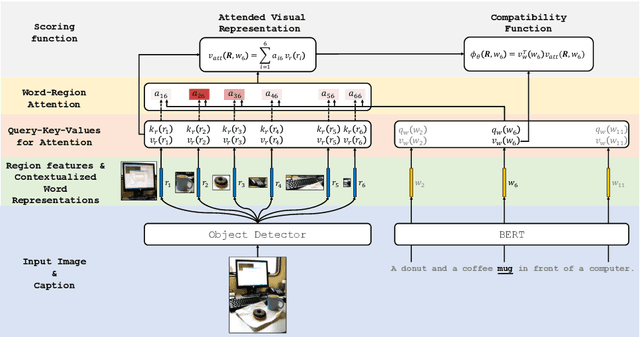

Phrase grounding, the problem of associating image regions to caption words, is a crucial component of vision-language tasks. We show that phrase grounding can be learned by optimizing word-region attention to maximize a lower bound on mutual information between images and caption words. Given pairs of images and captions, we maximize compatibility of the attention-weighted regions and the words in the corresponding caption, compared to non-corresponding pairs of images and captions. A key idea is to construct effective negative captions for learning through language model guided word substitutions. Training with our negatives yields a $\sim10\%$ absolute gain in accuracy over randomly-sampled negatives from the training data. Our weakly supervised phrase grounding model trained on COCO-Captions shows a healthy gain of $5.7\%$ to achieve $76.7\%$ accuracy on Flickr30K Entities benchmark.
UESegNet: Context Aware Unconstrained ROI Segmentation Networks for Ear Biometric
Oct 08, 2020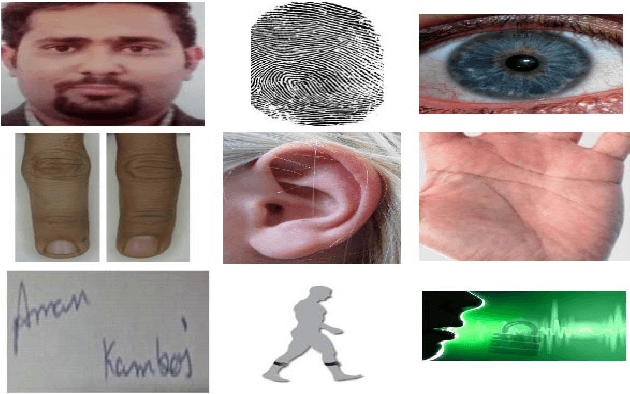
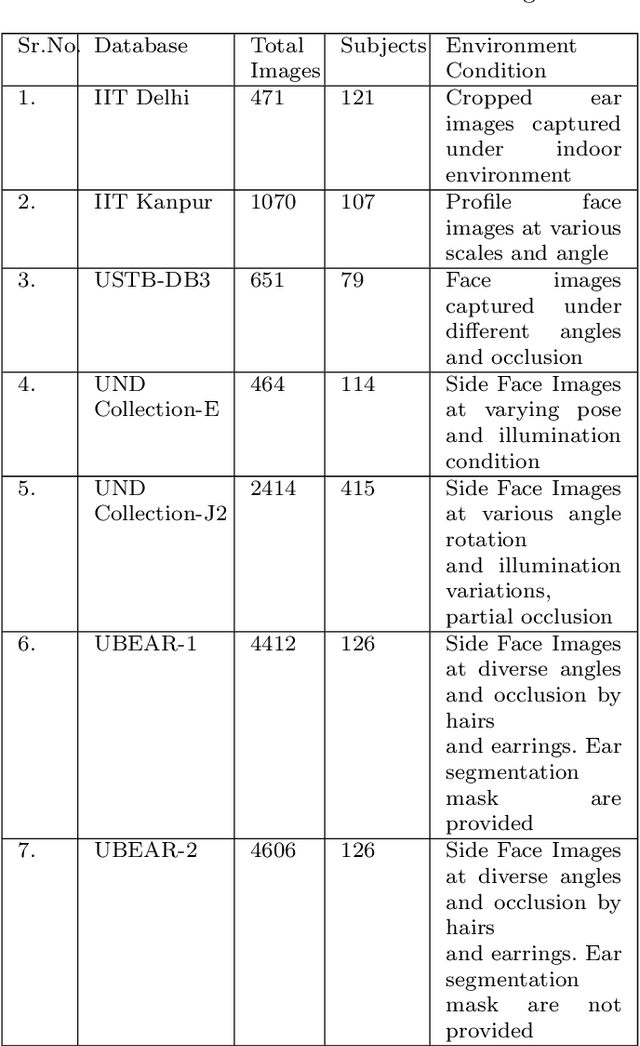
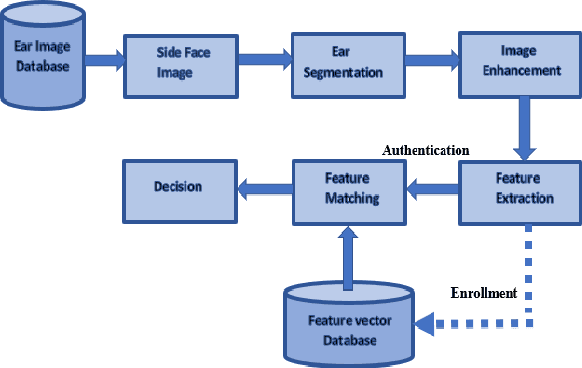
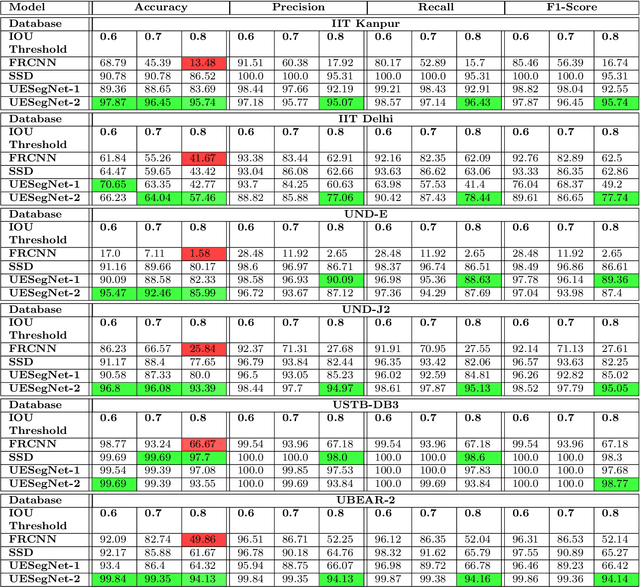
Biometric-based personal authentication systems have seen a strong demand mainly due to the increasing concern in various privacy and security applications. Although the use of each biometric trait is problem dependent, the human ear has been found to have enough discriminating characteristics to allow its use as a strong biometric measure. To locate an ear in a 2D side face image is a challenging task, numerous existing approaches have achieved significant performance, but the majority of studies are based on the constrained environment. However, ear biometrics possess a great level of difficulties in the unconstrained environment, where pose, scale, occlusion, illuminations, background clutter etc. varies to a great extent. To address the problem of ear localization in the wild, we have proposed two high-performance region of interest (ROI) segmentation models UESegNet-1 and UESegNet-2, which are fundamentally based on deep convolutional neural networks and primarily uses contextual information to localize ear in the unconstrained environment. Additionally, we have applied state-of-the-art deep learning models viz; FRCNN (Faster Region Proposal Network) and SSD (Single Shot MultiBox Detecor) for ear localization task. To test the model's generalization, they are evaluated on six different benchmark datasets viz; IITD, IITK, USTB-DB3, UND-E, UND-J2 and UBEAR, all of which contain challenging images. The performance of the models is compared on the basis of object detection performance measure parameters such as IOU (Intersection Over Union), Accuracy, Precision, Recall, and F1-Score. It has been observed that the proposed models UESegNet-1 and UESegNet-2 outperformed the FRCNN and SSD at higher values of IOUs i.e. an accuracy of 100\% is achieved at IOU 0.5 on majority of the databases.
ASAP-NMS: Accelerating Non-Maximum Suppression Using Spatially Aware Priors
Aug 21, 2020

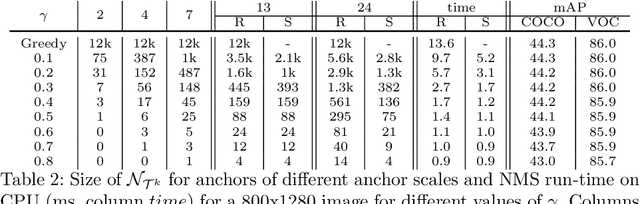

The widely adopted sequential variant of Non Maximum Suppression (or Greedy-NMS) is a crucial module for object-detection pipelines. Unfortunately, for the region proposal stage of two/multi-stage detectors, NMS is turning out to be a latency bottleneck due to its sequential nature. In this article, we carefully profile Greedy-NMS iterations to find that a major chunk of computation is wasted in comparing proposals that are already far-away and have a small chance of suppressing each other. We address this issue by comparing only those proposals that are generated from nearby anchors. The translation-invariant property of the anchor lattice affords generation of a lookup table, which provides an efficient access to nearby proposals, during NMS. This leads to an Accelerated NMS algorithm which leverages Spatially Aware Priors, or ASAP-NMS, and improves the latency of the NMS step from 13.6ms to 1.2 ms on a CPU without sacrificing the accuracy of a state-of-the-art two-stage detector on COCO and VOC datasets. Importantly, ASAP-NMS is agnostic to image resolution and can be used as a simple drop-in module during inference. Using ASAP-NMS at run-time only, we obtain an mAP of 44.2\%@25Hz on the COCO dataset with a V100 GPU.
A Comprehensive Overview and Survey of Recent Advances in Meta-Learning
May 08, 2020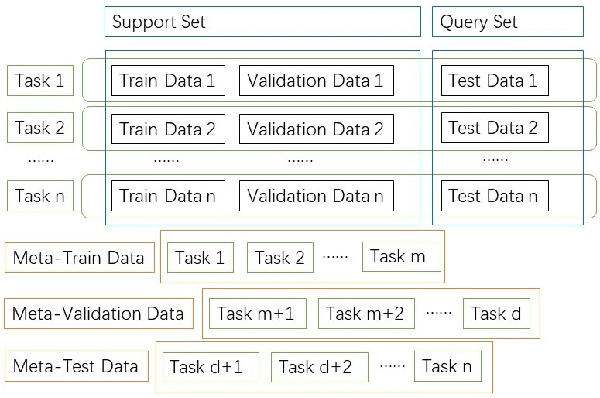

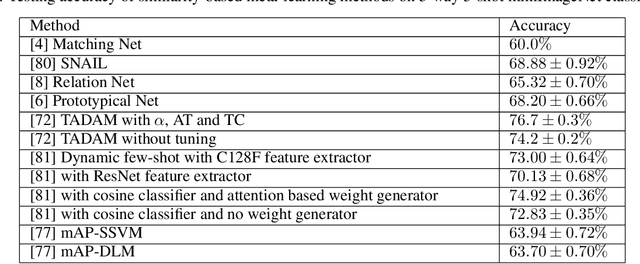
This article reviews meta-learning which seeks rapid and accurate model adaptation to unseen tasks with applications in image classification, natural language processing and robotics. Unlike deep learning, meta-learning uses few-shot datasets and concerns further improving model generalization to obtain higher prediction accuracy. We summarize meta-learning models in three categories: black-box adaptation, similarity based method and meta-learner procedure. Recent applications concentrate upon combination of meta-learning with Bayesian deep learning and reinforcement learning to provide feasible integrated problem solutions. We present performance comparison of recent meta-learning methods and discuss future research direction.
An Improved Person Re-identification Method by light-weight convolutional neural network
Aug 21, 2020
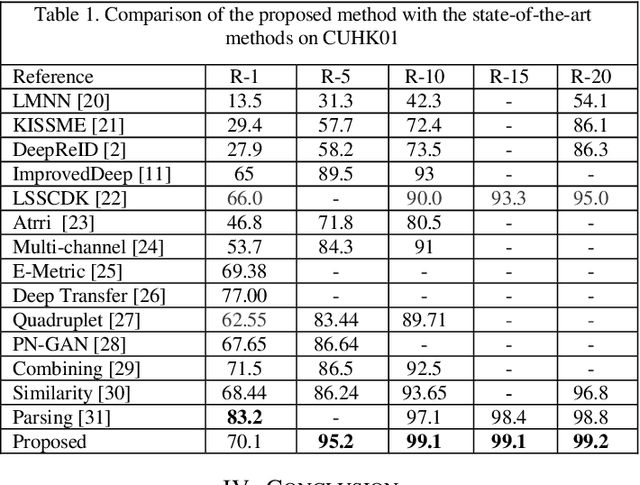
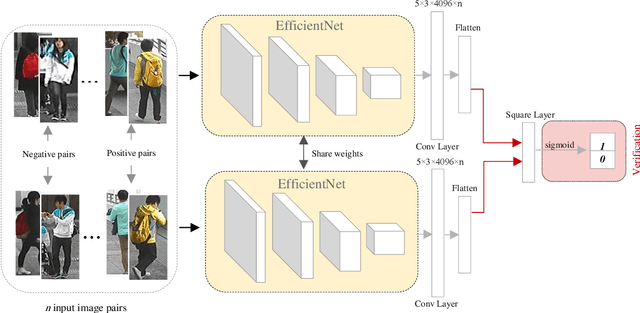
Person Re-identification is defined as a recognizing process where the person is observed by non-overlapping cameras at different places. In the last decade, the rise in the applications and importance of Person Re-identification for surveillance systems popularized this subject in different areas of computer vision. Person Re-identification is faced with challenges such as low resolution, varying poses, illumination, background clutter, and occlusion, which could affect the result of recognizing process. The present paper aims to improve Person Re-identification using transfer learning and application of verification loss function within the framework of Siamese network. The Siamese network receives image pairs as inputs and extract their features via a pre-trained model. EfficientNet was employed to obtain discriminative features and reduce the demands for data. The advantages of verification loss were used in the network learning. Experiments showed that the proposed model performs better than state-of-the-art methods on the CUHK01 dataset. For example, rank5 accuracies are 95.2% (+5.7) for the CUHK01 datasets. It also achieved an acceptable percentage in Rank 1. Because of the small size of the pre-trained model parameters, learning speeds up and there will be a need for less hardware and data.
Storing Encoded Episodes as Concepts for Continual Learning
Jun 26, 2020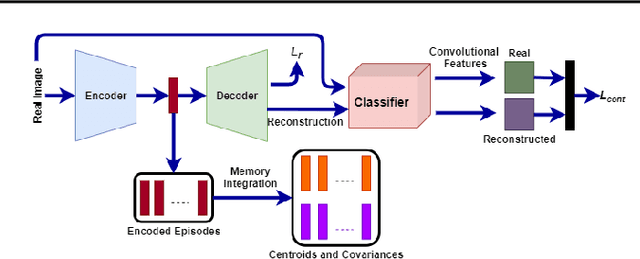
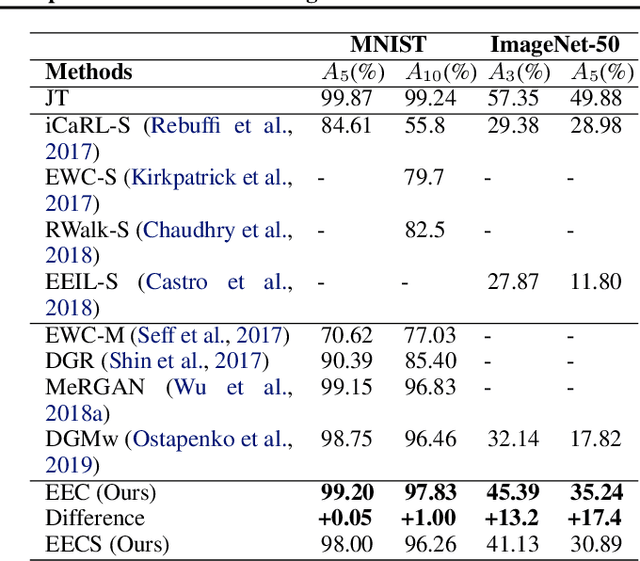

The two main challenges faced by continual learning approaches are catastrophic forgetting and memory limitations on the storage of data. To cope with these challenges, we propose a novel, cognitively-inspired approach which trains autoencoders with Neural Style Transfer to encode and store images. Reconstructed images from encoded episodes are replayed when training the classifier model on a new task to avoid catastrophic forgetting. The loss function for the reconstructed images is weighted to reduce its effect during classifier training to cope with image degradation. When the system runs out of memory the encoded episodes are converted into centroids and covariance matrices, which are used to generate pseudo-images during classifier training, keeping classifier performance stable with less memory. Our approach increases classification accuracy by 13-17% over state-of-the-art methods on benchmark datasets, while requiring 78% less storage space.
Towards Feature Space Adversarial Attack
Apr 26, 2020

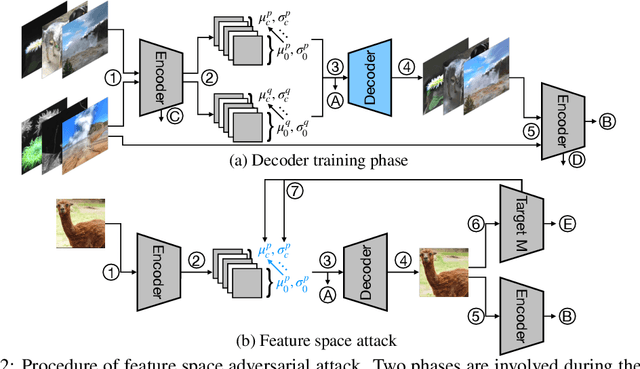
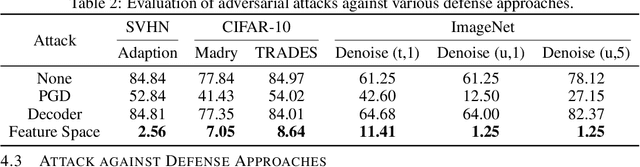
We propose a new type of adversarial attack to Deep Neural Networks (DNNs) for image classification. Different from most existing attacks that directly perturb input pixels. Our attack focuses on perturbing abstract features, more specifically, features that denote styles, including interpretable styles such as vivid colors and sharp outlines, and uninterpretable ones. It induces model misclassfication by injecting style changes insensitive for humans, through an optimization procedure. We show that state-of-the-art adversarial attack detection and defense techniques are ineffective in guarding against feature space attacks.