 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUser-Oriented Smart General AI System under Causal Inference
Mar 25, 2021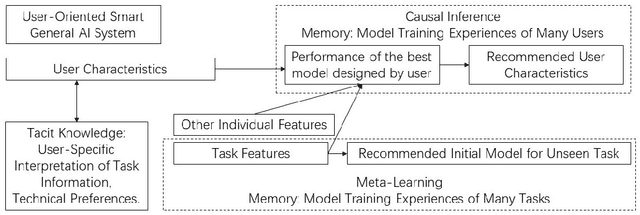
General AI system solves a wide range of tasks with high performance in an automated fashion. The best general AI algorithm designed by one individual is different from that devised by another. The best performance records achieved by different users are also different. An inevitable component of general AI is tacit knowledge that depends upon user-specific comprehension of task information and individual model design preferences that are related to user technical experiences. Tacit knowledge affects model performance but cannot be automatically optimized in general AI algorithms. In this paper, we propose User-Oriented Smart General AI System under Causal Inference, abbreviated as UOGASuCI, where UOGAS represents User-Oriented General AI System and uCI means under the framework of causal inference. User characteristics that have a significant influence upon tacit knowledge can be extracted from observed model training experiences of many users in external memory modules. Under the framework of causal inference, we manage to identify the optimal value of user characteristics that are connected with the best model performance designed by users. We make suggestions to users about how different user characteristics can improve the best model performance achieved by users. By recommending updating user characteristics associated with individualized tacit knowledge comprehension and technical preferences, UOGAS helps users design models with better performance.
A Brief Summary of Interactions Between Meta-Learning and Self-Supervised Learning
Mar 01, 2021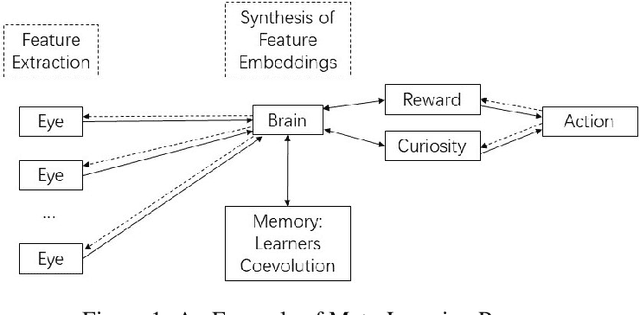
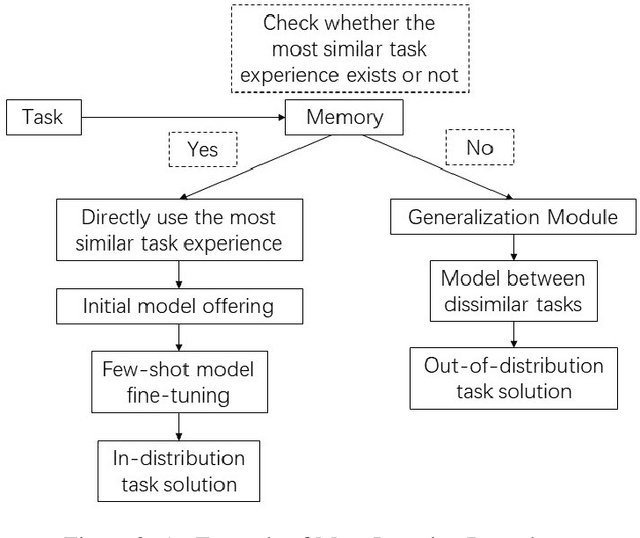
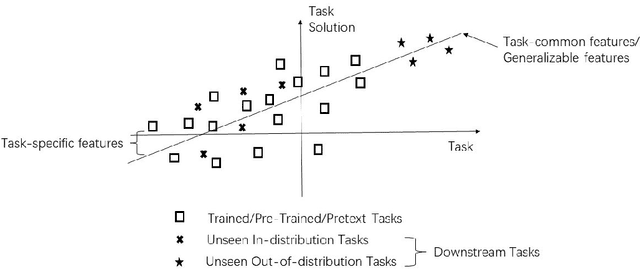
This paper briefly reviews the connections between meta-learning and self-supervised learning. Meta-learning can be applied to improve model generalization capability and to construct general AI algorithms. Self-supervised learning utilizes self-supervision from original data and extracts higher-level generalizable features through unsupervised pre-training or optimization of contrastive loss objectives. In self-supervised learning, data augmentation techniques are widely applied and data labels are not required since pseudo labels can be estimated from trained models on similar tasks. Meta-learning aims to adapt trained deep models to solve diverse tasks and to develop general AI algorithms. We review the associations of meta-learning with both generative and contrastive self-supervised learning models. Unlabeled data from multiple sources can be jointly considered even when data sources are vastly different. We show that an integration of meta-learning and self-supervised learning models can best contribute to the improvement of model generalization capability. Self-supervised learning guided by meta-learner and general meta-learning algorithms under self-supervision are both examples of possible combinations.
A Brief Survey of Associations Between Meta-Learning and General AI
Jan 12, 2021This paper briefly reviews the history of meta-learning and describes its contribution to general AI. Meta-learning improves model generalization capacity and devises general algorithms applicable to both in-distribution and out-of-distribution tasks potentially. General AI replaces task-specific models with general algorithmic systems introducing higher level of automation in solving diverse tasks using AI. We summarize main contributions of meta-learning to the developments in general AI, including memory module, meta-learner, coevolution, curiosity, forgetting and AI-generating algorithm. We present connections between meta-learning and general AI and discuss how meta-learning can be used to formulate general AI algorithms.
A Comprehensive Overview and Survey of Recent Advances in Meta-Learning
May 08, 2020

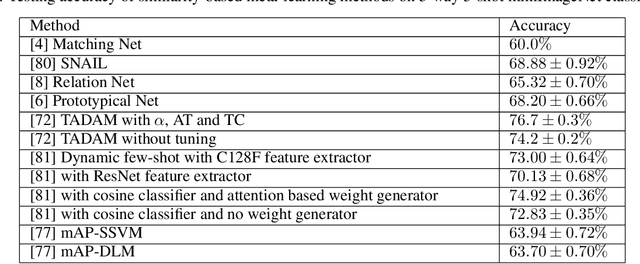
This article reviews meta-learning which seeks rapid and accurate model adaptation to unseen tasks with applications in image classification, natural language processing and robotics. Unlike deep learning, meta-learning uses few-shot datasets and concerns further improving model generalization to obtain higher prediction accuracy. We summarize meta-learning models in three categories: black-box adaptation, similarity based method and meta-learner procedure. Recent applications concentrate upon combination of meta-learning with Bayesian deep learning and reinforcement learning to provide feasible integrated problem solutions. We present performance comparison of recent meta-learning methods and discuss future research direction.
Measurement Error in Nutritional Epidemiology: A Survey
Apr 14, 2020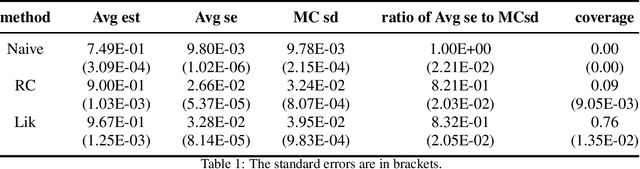
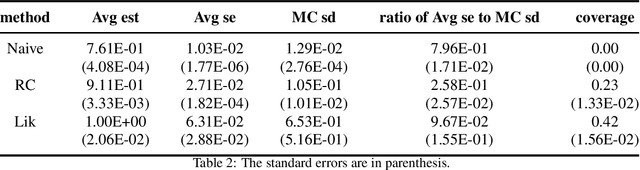
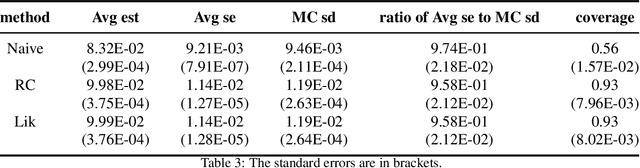
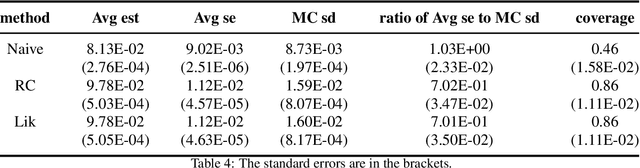
This article reviews bias-correction models for measurement error of exposure variables in the field of nutritional epidemiology. Measurement error usually attenuates estimated slope towards zero. Due to the influence of measurement error, inference of parameter estimate is conservative and confidence interval of the slope parameter is too narrow. Bias-correction in estimators and confidence intervals are of primary interest. We review the following bias-correction models: regression calibration methods, likelihood based models, missing data models, simulation based methods, nonparametric models and sampling based procedures.