 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTractRLFusion: A GPT-Based Multi-Critic Policy Fusion Framework for Fiber Tractography
Jan 20, 2026Tractography plays a pivotal role in the non-invasive reconstruction of white matter fiber pathways, providing vital information on brain connectivity and supporting precise neurosurgical planning. Although traditional methods relied mainly on classical deterministic and probabilistic approaches, recent progress has benefited from supervised deep learning (DL) and deep reinforcement learning (DRL) to improve tract reconstruction. A persistent challenge in tractography is accurately reconstructing white matter tracts while minimizing spurious connections. To address this, we propose TractRLFusion, a novel GPT-based policy fusion framework that integrates multiple RL policies through a data-driven fusion strategy. Our method employs a two-stage training data selection process for effective policy fusion, followed by a multi-critic fine-tuning phase to enhance robustness and generalization. Experiments on HCP, ISMRM, and TractoInferno datasets demonstrate that TractRLFusion outperforms individual RL policies as well as state-of-the-art classical and DRL methods in accuracy and anatomical reliability.
TrackletGPT: A Language-like GPT Framework for White Matter Tract Segmentation
Jan 20, 2026White Matter Tract Segmentation is imperative for studying brain structural connectivity, neurological disorders and neurosurgery. This task remains complex, as tracts differ among themselves, across subjects and conditions, yet have similar 3D structure across hemispheres and subjects. To address these challenges, we propose TrackletGPT, a language-like GPT framework which reintroduces sequential information in tokens using tracklets. TrackletGPT generalises seamlessly across datasets, is fully automatic, and encodes granular sub-streamline segments, Tracklets, scaling and refining GPT models in Tractography Segmentation. Based on our experiments, TrackletGPT outperforms state-of-the-art methods on average DICE, Overlap and Overreach scores on TractoInferno and HCP datasets, even on inter-dataset experiments.
TractoGPT: A GPT architecture for White Matter Segmentation
Jan 26, 2025



White matter bundle segmentation is crucial for studying brain structural connectivity, neurosurgical planning, and neurological disorders. White Matter Segmentation remains challenging due to structural similarity in streamlines, subject variability, symmetry in 2 hemispheres, etc. To address these challenges, we propose TractoGPT, a GPT-based architecture trained on streamline, cluster, and fusion data representations separately. TractoGPT is a fully-automatic method that generalizes across datasets and retains shape information of the white matter bundles. Experiments also show that TractoGPT outperforms state-of-the-art methods on average DICE, Overlap and Overreach scores. We use TractoInferno and 105HCP datasets and validate generalization across dataset.
TractoEmbed: Modular Multi-level Embedding framework for white matter tract segmentation
Nov 12, 2024



White matter tract segmentation is crucial for studying brain structural connectivity and neurosurgical planning. However, segmentation remains challenging due to issues like class imbalance between major and minor tracts, structural similarity, subject variability, symmetric streamlines between hemispheres etc. To address these challenges, we propose TractoEmbed, a modular multi-level embedding framework, that encodes localized representations through learning tasks in respective encoders. In this paper, TractoEmbed introduces a novel hierarchical streamline data representation that captures maximum spatial information at each level i.e. individual streamlines, clusters, and patches. Experiments show that TractoEmbed outperforms state-of-the-art methods in white matter tract segmentation across different datasets, and spanning various age groups. The modular framework directly allows the integration of additional embeddings in future works.
Tract-RLFormer: A Tract-Specific RL policy based Decoder-only Transformer Network
Nov 08, 2024Fiber tractography is a cornerstone of neuroimaging, enabling the detailed mapping of the brain's white matter pathways through diffusion MRI. This is crucial for understanding brain connectivity and function, making it a valuable tool in neurological applications. Despite its importance, tractography faces challenges due to its complexity and susceptibility to false positives, misrepresenting vital pathways. To address these issues, recent strategies have shifted towards deep learning, utilizing supervised learning, which depends on precise ground truth, or reinforcement learning, which operates without it. In this work, we propose Tract-RLFormer, a network utilizing both supervised and reinforcement learning, in a two-stage policy refinement process that markedly improves the accuracy and generalizability across various data-sets. By employing a tract-specific approach, our network directly delineates the tracts of interest, bypassing the traditional segmentation process. Through rigorous validation on datasets such as TractoInferno, HCP, and ISMRM-2015, our methodology demonstrates a leap forward in tractography, showcasing its ability to accurately map the brain's white matter tracts.
MHATC: Autism Spectrum Disorder identification utilizing multi-head attention encoder along with temporal consolidation modules
Dec 27, 2021
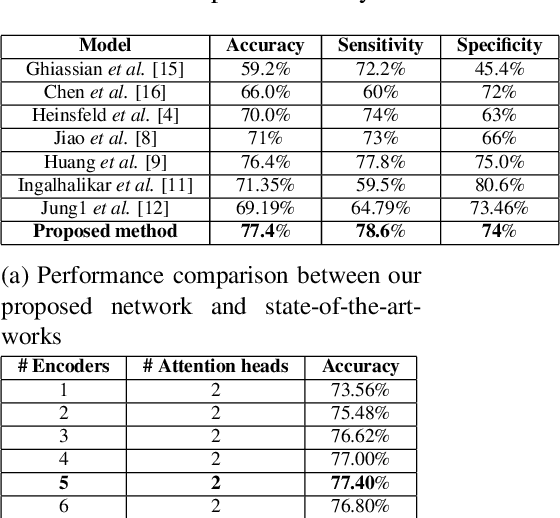
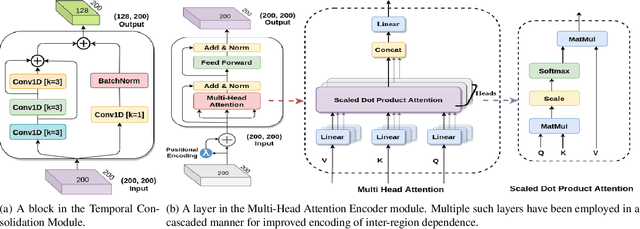
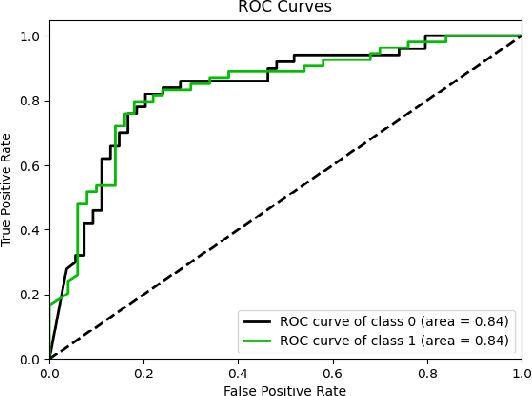
Resting-state fMRI is commonly used for diagnosing Autism Spectrum Disorder (ASD) by using network-based functional connectivity. It has been shown that ASD is associated with brain regions and their inter-connections. However, discriminating based on connectivity patterns among imaging data of the control population and that of ASD patients' brains is a non-trivial task. In order to tackle said classification task, we propose a novel deep learning architecture (MHATC) consisting of multi-head attention and temporal consolidation modules for classifying an individual as a patient of ASD. The devised architecture results from an in-depth analysis of the limitations of current deep neural network solutions for similar applications. Our approach is not only robust but computationally efficient, which can allow its adoption in a variety of other research and clinical settings.
UESegNet: Context Aware Unconstrained ROI Segmentation Networks for Ear Biometric
Oct 08, 2020
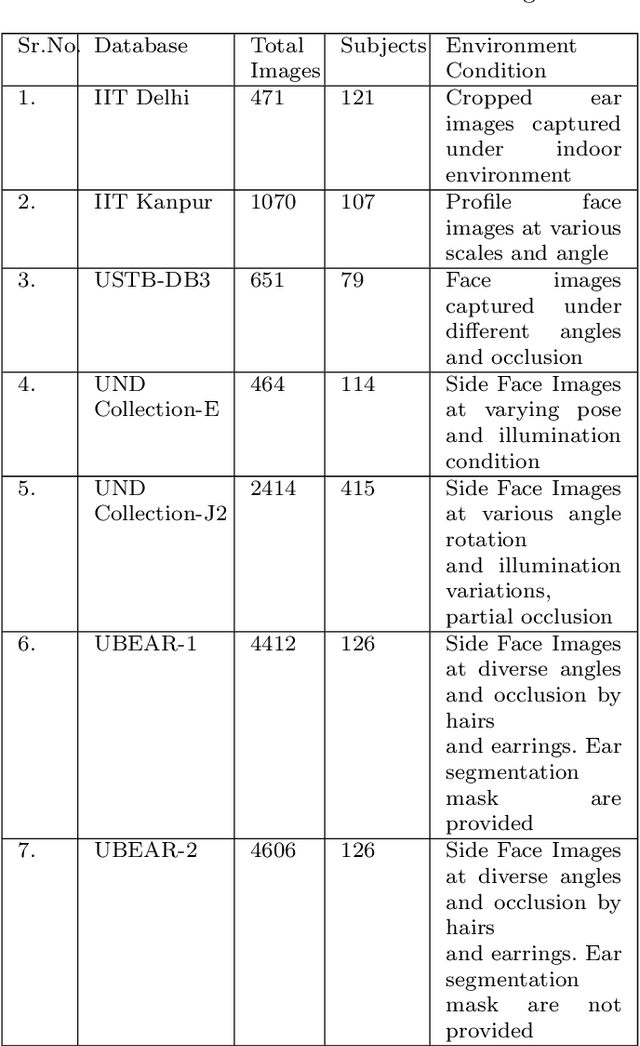
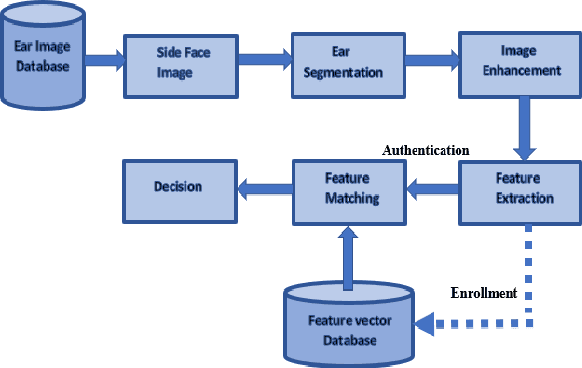
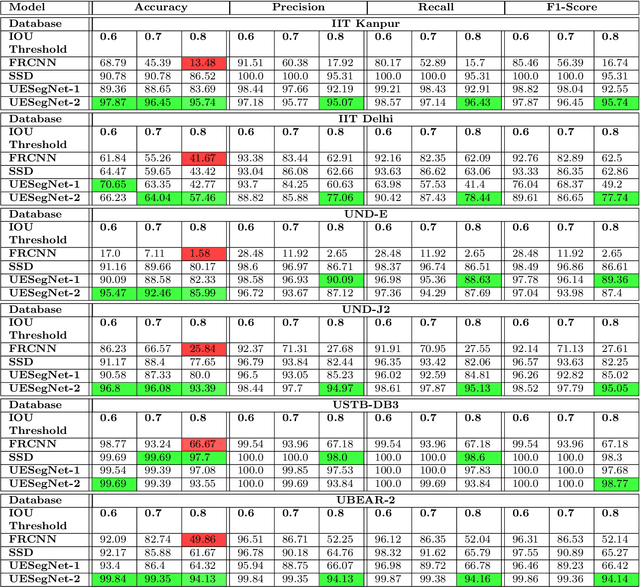
Biometric-based personal authentication systems have seen a strong demand mainly due to the increasing concern in various privacy and security applications. Although the use of each biometric trait is problem dependent, the human ear has been found to have enough discriminating characteristics to allow its use as a strong biometric measure. To locate an ear in a 2D side face image is a challenging task, numerous existing approaches have achieved significant performance, but the majority of studies are based on the constrained environment. However, ear biometrics possess a great level of difficulties in the unconstrained environment, where pose, scale, occlusion, illuminations, background clutter etc. varies to a great extent. To address the problem of ear localization in the wild, we have proposed two high-performance region of interest (ROI) segmentation models UESegNet-1 and UESegNet-2, which are fundamentally based on deep convolutional neural networks and primarily uses contextual information to localize ear in the unconstrained environment. Additionally, we have applied state-of-the-art deep learning models viz; FRCNN (Faster Region Proposal Network) and SSD (Single Shot MultiBox Detecor) for ear localization task. To test the model's generalization, they are evaluated on six different benchmark datasets viz; IITD, IITK, USTB-DB3, UND-E, UND-J2 and UBEAR, all of which contain challenging images. The performance of the models is compared on the basis of object detection performance measure parameters such as IOU (Intersection Over Union), Accuracy, Precision, Recall, and F1-Score. It has been observed that the proposed models UESegNet-1 and UESegNet-2 outperformed the FRCNN and SSD at higher values of IOUs i.e. an accuracy of 100\% is achieved at IOU 0.5 on majority of the databases.
SP-NET: One Shot Fingerprint Singular-Point Detector
Aug 13, 2019

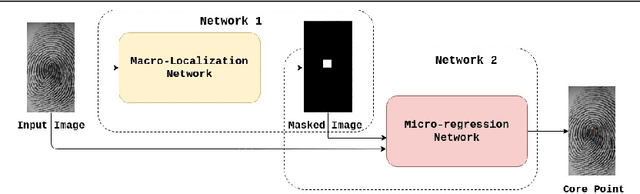

Singular points of a fingerprint image are special locations having high curvature properties. They can play a pivotal role in fingerprint normalization and reliable feature extraction. Accurate and efficient extraction of a singular point plays a major role in successful fingerprint recognition and indexing. In this paper, a novel deep learning based architecture is proposed for one shot (end-to-end) singular point detection from an input fingerprint image. The model consists of a Macro-Localization Network and a Micro-Regression Network along with three stacked hourglass as a bottleneck. The proposed model has been tested on three databases viz. FVC2002 DB1_A, FVC2002 DB2_A and FPL30K and has been found to achieve true detection rate of 98.75%, 97.5% and 92.72% respectively, which is better than any other state-of-the-art technique.
UBSegNet: Unified Biometric Region of Interest Segmentation Network
Sep 26, 2017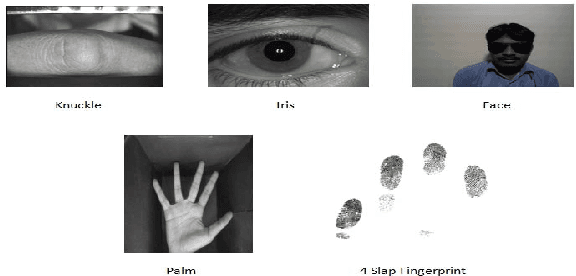
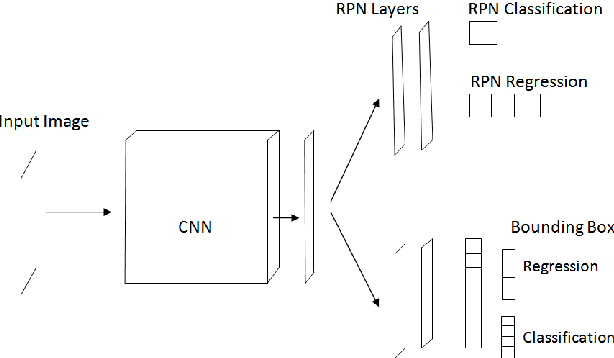
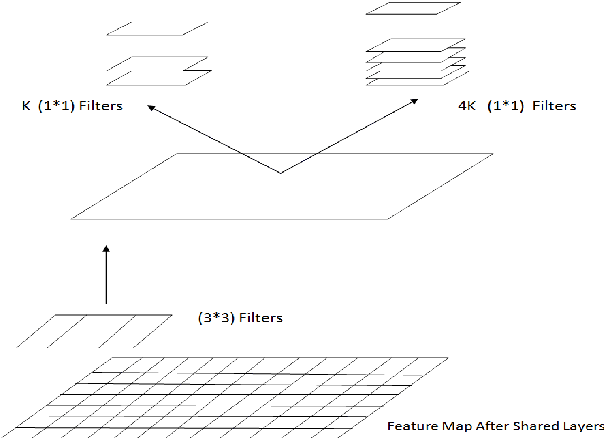
Digital human identity management, can now be seen as a social necessity, as it is essentially required in almost every public sector such as, financial inclusions, security, banking, social networking e.t.c. Hence, in today's rampantly emerging world with so many adversarial entities, relying on a single biometric trait is being too optimistic. In this paper, we have proposed a novel end-to-end, Unified Biometric ROI Segmentation Network (UBSegNet), for extracting region of interest from five different biometric traits viz. face, iris, palm, knuckle and 4-slap fingerprint. The architecture of the proposed UBSegNet consists of two stages: (i) Trait classification and (ii) Trait localization. For these stages, we have used a state of the art region based convolutional neural network (RCNN), comprising of three major parts namely convolutional layers, region proposal network (RPN) along with classification and regression heads. The model has been evaluated over various huge publicly available biometric databases. To the best of our knowledge this is the first unified architecture proposed, segmenting multiple biometric traits. It has been tested over around 5000 * 5 = 25,000 images (5000 images per trait) and produces very good results. Our work on unified biometric segmentation, opens up the vast opportunities in the field of multiple biometric traits based authentication systems.