 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Dominant Sets for "Constrained" Image Segmentation
Jul 15, 2017

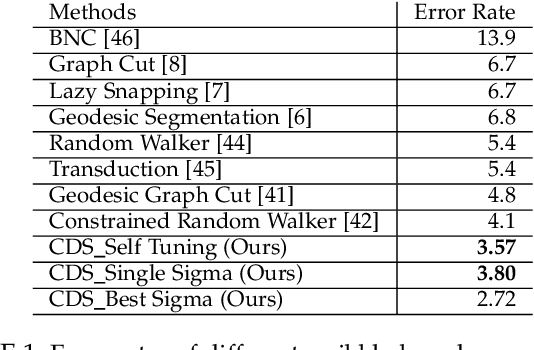

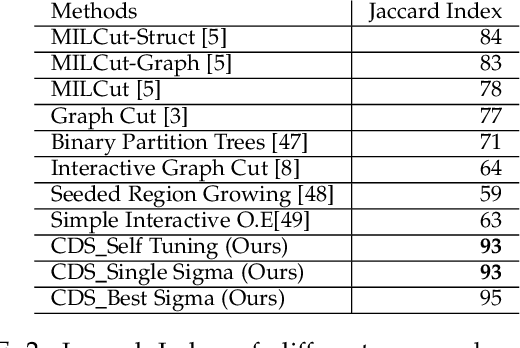
Image segmentation has come a long way since the early days of computer vision, and still remains a challenging task. Modern variations of the classical (purely bottom-up) approach, involve, e.g., some form of user assistance (interactive segmentation) or ask for the simultaneous segmentation of two or more images (co-segmentation). At an abstract level, all these variants can be thought of as "constrained" versions of the original formulation, whereby the segmentation process is guided by some external source of information. In this paper, we propose a new approach to tackle this kind of problems in a unified way. Our work is based on some properties of a family of quadratic optimization problems related to dominant sets, a well-known graph-theoretic notion of a cluster which generalizes the concept of a maximal clique to edge-weighted graphs. In particular, we show that by properly controlling a regularization parameter which determines the structure and the scale of the underlying problem, we are in a position to extract groups of dominant-set clusters that are constrained to contain predefined elements. In particular, we shall focus on interactive segmentation and co-segmentation (in both the unsupervised and the interactive versions). The proposed algorithm can deal naturally with several type of constraints and input modality, including scribbles, sloppy contours, and bounding boxes, and is able to robustly handle noisy annotations on the part of the user. Experiments on standard benchmark datasets show the effectiveness of our approach as compared to state-of-the-art algorithms on a variety of natural images under several input conditions and constraints.
Small-Object Detection in Remote Sensing Images with End-to-End Edge-Enhanced GAN and Object Detector Network
Apr 15, 2020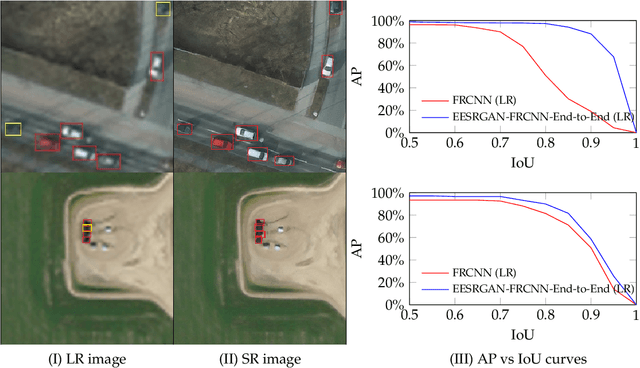
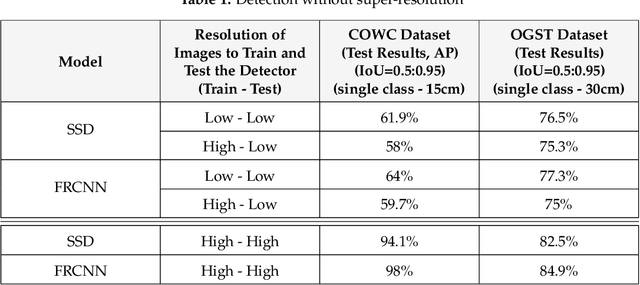
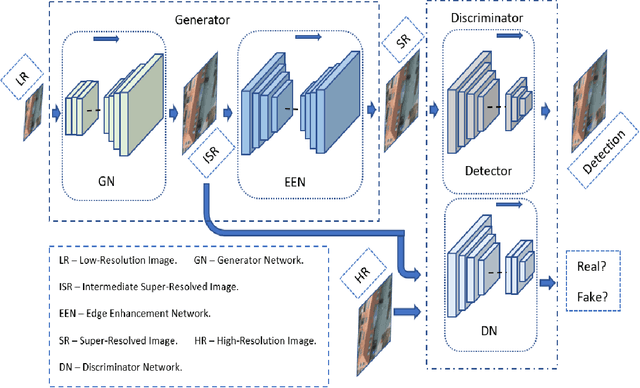
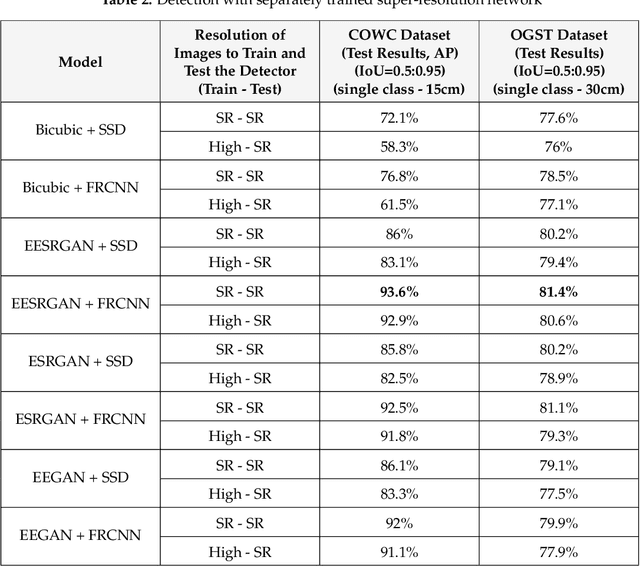
The detection performance of small objects in remote sensing images is not satisfactory compared to large objects, especially in low-resolution and noisy images. A generative adversarial network (GAN)-based model called enhanced super-resolution GAN (ESRGAN) shows remarkable image enhancement performance, but reconstructed images miss high-frequency edge information. Therefore, object detection performance degrades for small objects on recovered noisy and low-resolution remote sensing images. Inspired by the success of edge enhanced GAN (EEGAN) and ESRGAN, we apply a new edge-enhanced super-resolution GAN (EESRGAN) to improve the image quality of remote sensing images and use different detector networks in an end-to-end manner where detector loss is backpropagated into the EESRGAN to improve the detection performance. We propose an architecture with three components: ESRGAN, Edge Enhancement Network (EEN), and Detection network. We use residual-in-residual dense blocks (RRDB) for both the ESRGAN and EEN, and for the detector network, we use the faster region-based convolutional network (FRCNN) (two-stage detector) and single-shot multi-box detector (SSD) (one stage detector). Extensive experiments on a public (car overhead with context) and a self-assembled (oil and gas storage tank) satellite dataset show superior performance of our method compared to the standalone state-of-the-art object detectors.
PatternNet: A Benchmark Dataset for Performance Evaluation of Remote Sensing Image Retrieval
Jul 10, 2017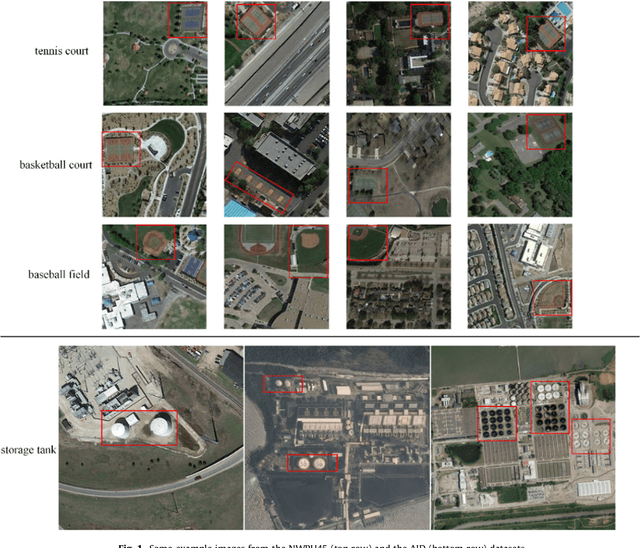

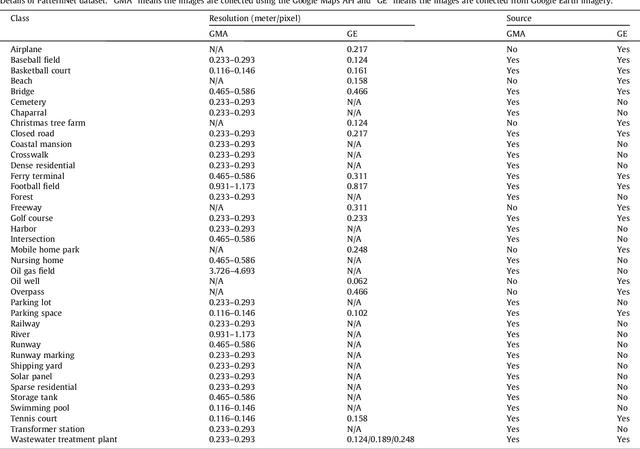

Remote sensing image retrieval(RSIR), which aims to efficiently retrieve data of interest from large collections of remote sensing data, is a fundamental task in remote sensing. Over the past several decades, there has been significant effort to extract powerful feature representations for this task since the retrieval performance depends on the representative strength of the features. Benchmark datasets are also critical for developing, evaluating, and comparing RSIR approaches. Current benchmark datasets are deficient in that 1) they were originally collected for land use/land cover classification and not image retrieval, 2) they are relatively small in terms of the number of classes as well the number of sample images per class, and 3) the retrieval performance has saturated. These limitations have severely restricted the development of novel feature representations for RSIR, particularly the recent deep-learning based features which require large amounts of training data. We therefore present in this paper, a new large-scale remote sensing dataset termed "PatternNet" that was collected specifically for RSIR. PatternNet was collected from high-resolution imagery and contains 38 classes with 800 images per class. We also provide a thorough review of RSIR approaches ranging from traditional handcrafted feature based methods to recent deep learning based ones. We evaluate over 35 methods to establish extensive baseline results for future RSIR research using the PatternNet benchmark.
Universal Semantic Segmentation for Fisheye Urban Driving Images
Jan 31, 2020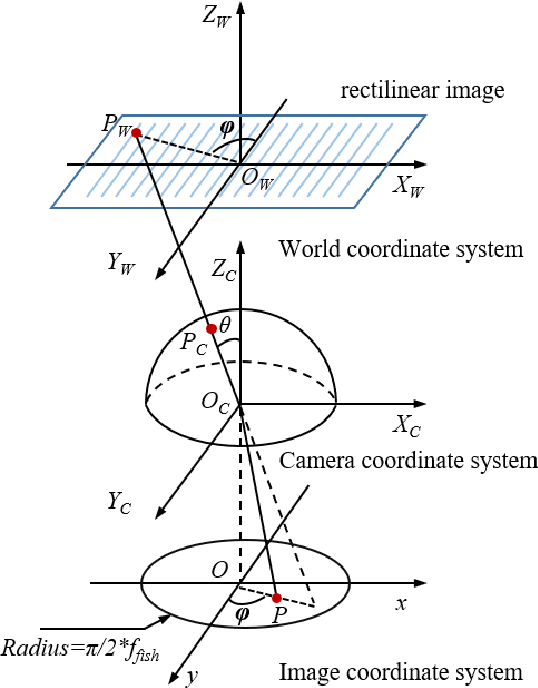

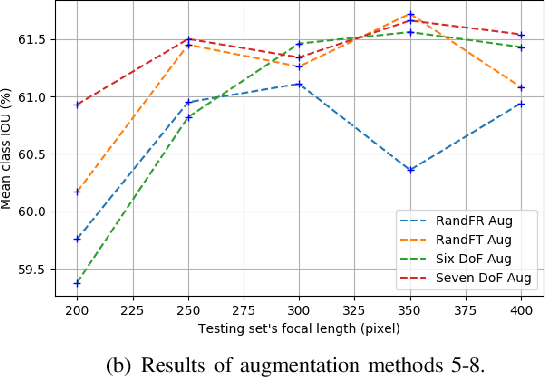
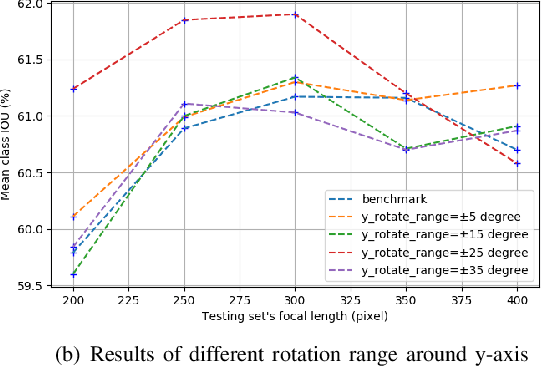
Semantic segmentation is a critical method in the field of autonomous driving. When performing semantic image segmentation, a wider field of view (FoV) helps to obtain more information about the surrounding environment, making automatic driving safer and more reliable, which could be offered by fisheye cameras. However, large public fisheye data sets are not available, and the fisheye images captured by the fisheye camera with large FoV comes with large distortion, so commonly-used semantic segmentation model cannot be directly utilized. In this paper, a seven degrees of freedom (DoF) augmentation method is proposed to transform rectilinear image to fisheye image in a more comprehensive way. In the training process, rectilinear images are transformed into fisheye images in seven DoF, which simulates the fisheye images taken by cameras of different positions, orientations and focal lengths. The result shows that training with the seven-DoF augmentation can evidently improve the model's accuracy and robustness against different distorted fisheye data. This seven-DoF augmentation provides an universal semantic segmentation solution for fisheye cameras in different autonomous driving applications. Also, we provide specific parameter settings of the augmentation for autonomous driving. At last, we tested our universal semantic segmentation model on real fisheye images and obtained satisfactory results. The code and configurations are released at \url{https://github.com/Yaozhuwa/FisheyeSeg}.
Interactive Image Segmentation From A Feedback Control Perspective
Sep 26, 2016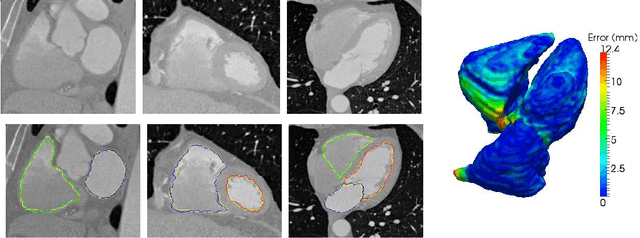
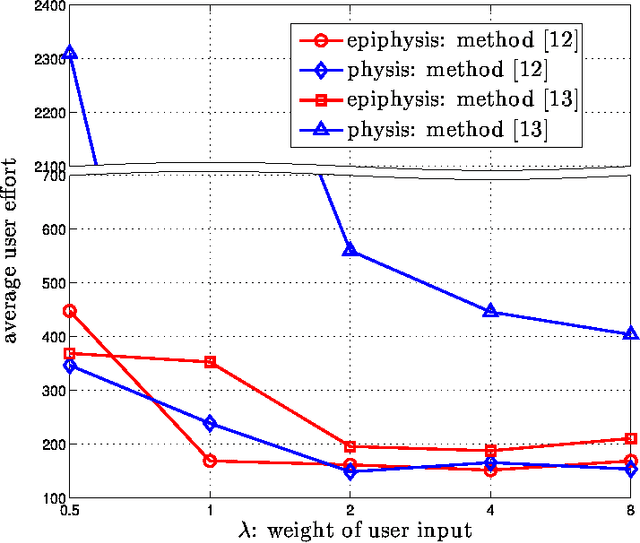
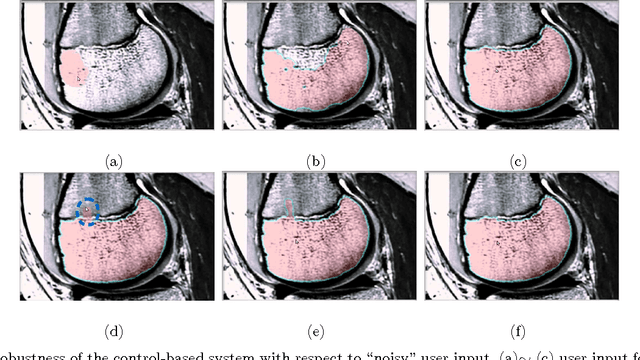

Image segmentation is a fundamental problem in computational vision and medical imaging. Designing a generic, automated method that works for various objects and imaging modalities is a formidable task. Instead of proposing a new specific segmentation algorithm, we present a general design principle on how to integrate user interactions from the perspective of feedback control theory. Impulsive control and Lyapunov stability analysis are employed to design and analyze an interactive segmentation system. Then stabilization conditions are derived to guide algorithm design. Finally, the effectiveness and robustness of proposed method are demonstrated.
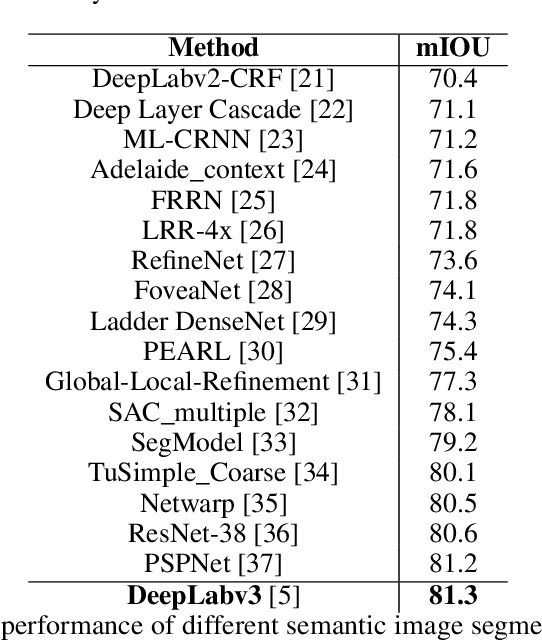
Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs
Jun 07, 2016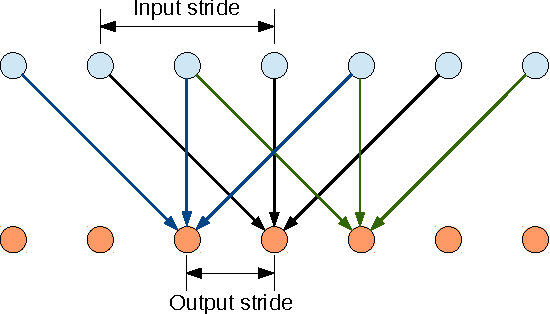

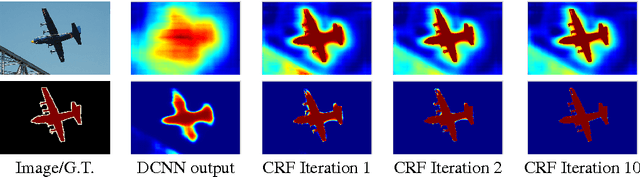

Deep Convolutional Neural Networks (DCNNs) have recently shown state of the art performance in high level vision tasks, such as image classification and object detection. This work brings together methods from DCNNs and probabilistic graphical models for addressing the task of pixel-level classification (also called "semantic image segmentation"). We show that responses at the final layer of DCNNs are not sufficiently localized for accurate object segmentation. This is due to the very invariance properties that make DCNNs good for high level tasks. We overcome this poor localization property of deep networks by combining the responses at the final DCNN layer with a fully connected Conditional Random Field (CRF). Qualitatively, our "DeepLab" system is able to localize segment boundaries at a level of accuracy which is beyond previous methods. Quantitatively, our method sets the new state-of-art at the PASCAL VOC-2012 semantic image segmentation task, reaching 71.6% IOU accuracy in the test set. We show how these results can be obtained efficiently: Careful network re-purposing and a novel application of the 'hole' algorithm from the wavelet community allow dense computation of neural net responses at 8 frames per second on a modern GPU.
Exploring Unlabeled Faces for Novel Attribute Discovery
Dec 06, 2019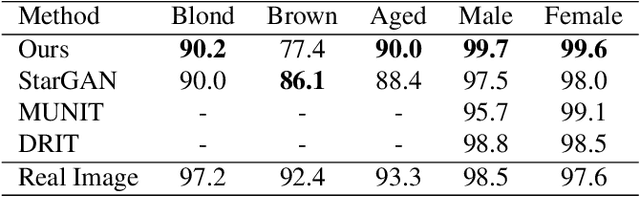

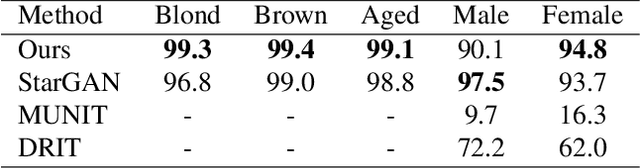

Despite remarkable success in unpaired image-to-image translation, existing systems still require a large amount of labeled images. This is a bottleneck for their real-world applications; in practice, a model trained on labeled CelebA dataset does not work well for test images from a different distribution -- greatly limiting their application to unlabeled images of a much larger quantity. In this paper, we attempt to alleviate this necessity for labeled data in the facial image translation domain. We aim to explore the degree to which you can discover novel attributes from unlabeled faces and perform high-quality translation. To this end, we use prior knowledge about the visual world as guidance to discover novel attributes and transfer them via a novel normalization method. Experiments show that our method trained on unlabeled data produces high-quality translations, preserves identity, and be perceptually realistic as good as, or better than, state-of-the-art methods trained on labeled data.
Synthesis and Edition of Ultrasound Images via Sketch Guided Progressive Growing GANs
Apr 01, 2020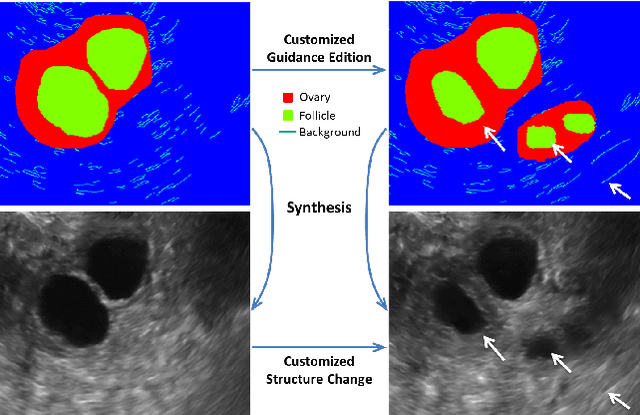
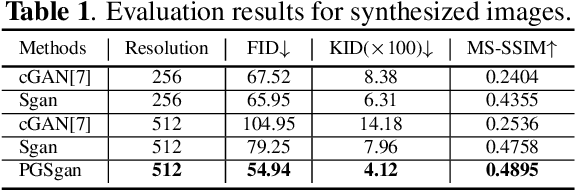
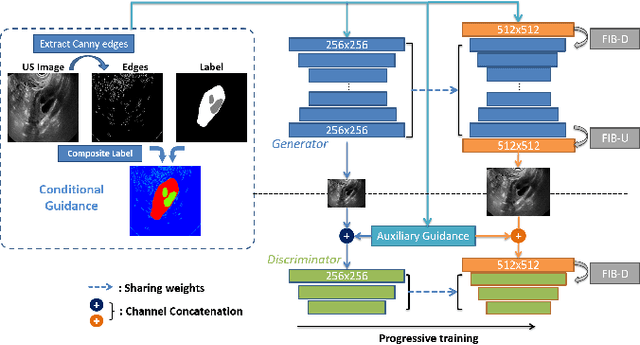
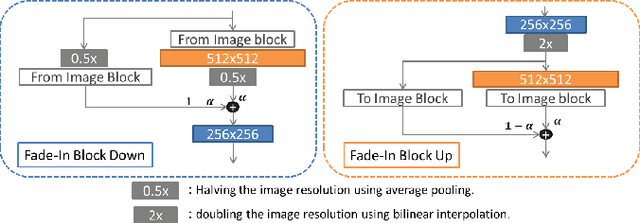
Ultrasound (US) is widely accepted in clinic for anatomical structure inspection. However, lacking in resources to practice US scan, novices often struggle to learn the operation skills. Also, in the deep learning era, automated US image analysis is limited by the lack of annotated samples. Efficiently synthesizing realistic, editable and high resolution US images can solve the problems. The task is challenging and previous methods can only partially complete it. In this paper, we devise a new framework for US image synthesis. Particularly, we firstly adopt a sketch generative adversarial networks (Sgan) to introduce background sketch upon object mask in a conditioned generative adversarial network. With enriched sketch cues, Sgan can generate realistic US images with editable and fine-grained structure details. Although effective, Sgan is hard to generate high resolution US images. To achieve this, we further implant the Sgan into a progressive growing scheme (PGSgan). By smoothly growing both generator and discriminator, PGSgan can gradually synthesize US images from low to high resolution. By synthesizing ovary and follicle US images, our extensive perceptual evaluation, user study and segmentation results prove the promising efficacy and efficiency of the proposed PGSgan.
Dissimilarity Mixture Autoencoder for Deep Clustering
Jun 22, 2020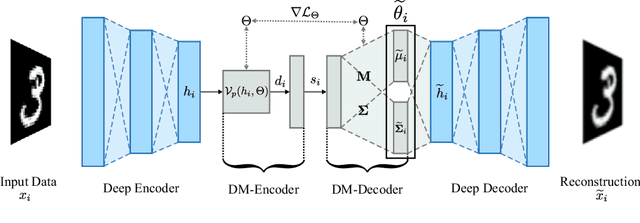
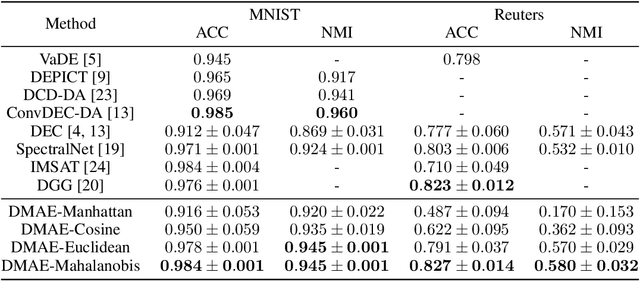
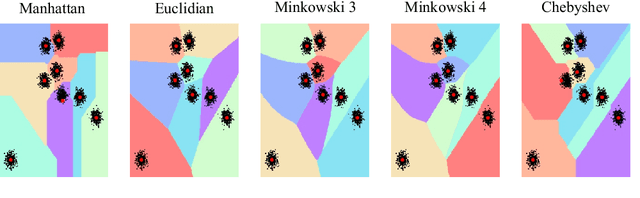
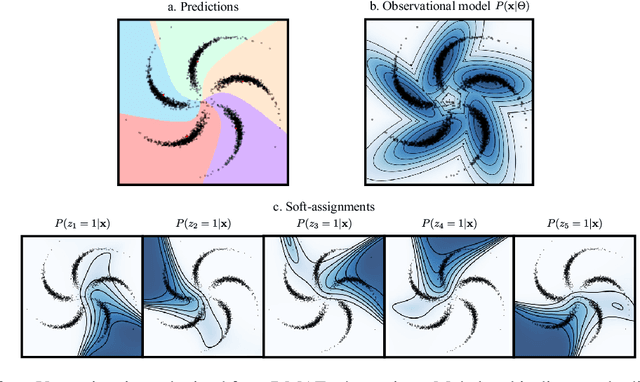
In this paper, we introduce the Dissimilarity Mixture Autoencoder (DMAE), a novel neural network model that uses a dissimilarity function to generalize a family of density estimation and clustering methods. It is formulated in such a way that it internally estimates the parameters of a probability distribution through gradient-based optimization. Also, the proposed model can leverage from deep representation learning due to its straightforward incorporation into deep learning architectures, because, it consists of an encoder-decoder network that computes a probabilistic representation. Experimental evaluation was performed on image and text clustering benchmark datasets showing that the method is competitive in terms of unsupervised classification accuracy and normalized mutual information. The source code to replicate the experiments is publicly available at https://github.com/larajuse/DMAE
Sequential image processing methods for improving semantic video segmentation algorithms
Oct 29, 2019

Recently, semantic video segmentation gained high attention especially for supporting autonomous driving systems. Deep learning methods made it possible to implement real time segmentation and object identification algorithms on videos. However, most of the available approaches process each video frame independently disregarding their sequential relation in time. Therefore their results suddenly miss some of the object segments in some of the frames even if they were detected properly in the earlier frames. Herein we propose two sequential probabilistic video frame analysis approaches to improve the segmentation performance of the existing algorithms. Our experiments show that using the information of the past frames we increase the performance and consistency of the state of the art algorithms.