 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Subjective Quality Assessment of Ground-based Camera Images
Dec 16, 2019

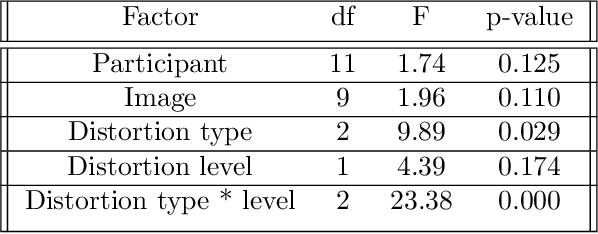

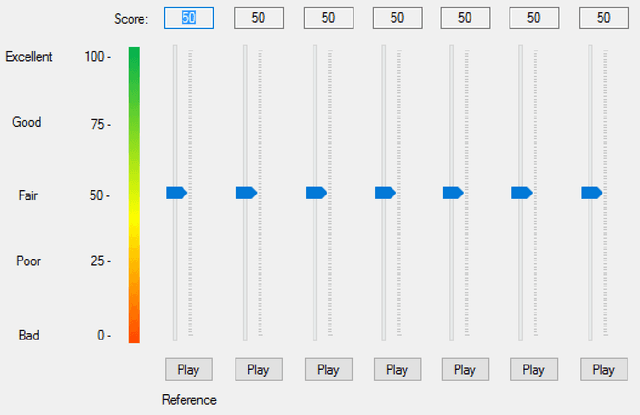
Image quality assessment is critical to control and maintain the perceived quality of visual content. Both subjective and objective evaluations can be utilised, however, subjective image quality assessment is currently considered the most reliable approach. Databases containing distorted images and mean opinion scores are needed in the field of atmospheric research with a view to improve the current state-of-the-art methodologies. In this paper, we focus on using ground-based sky camera images to understand the atmospheric events. We present a new image quality assessment dataset containing original and distorted nighttime images of sky/cloud from SWINSEG database. Subjective quality assessment was carried out in controlled conditions, as recommended by the ITU. Statistical analyses of the subjective scores showed the impact of noise type and distortion level on the perceived quality.
PointIso: Point Cloud Based Deep Learning Model for Detecting Arbitrary-Precision Peptide Features in LC-MS Map through Attention Based Segmentation
Sep 15, 2020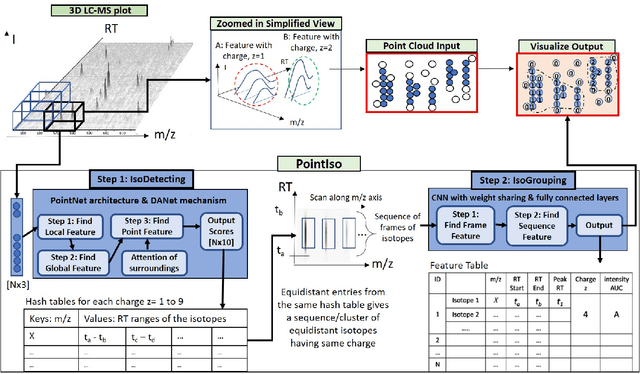

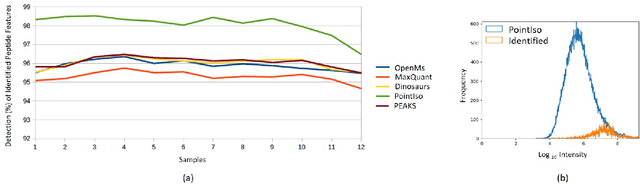

A promising technique of discovering disease biomarkers is to measure the relative protein abundance in multiple biofluid samples through liquid chromatography with tandem mass spectrometry (LC-MS/MS) based quantitative proteomics. The key step involves peptide feature detection in LC-MS map, along with its charge and intensity. Existing heuristic algorithms suffer from inaccurate parameters since different settings of the parameters result in significantly different outcomes. Therefore, we propose PointIso, to serve the necessity of an automated system for peptide feature detection that is able to find out the proper parameters itself, and is easily adaptable to different types of datasets. It consists of an attention based scanning step for segmenting the multi-isotopic pattern of peptide features along with charge and a sequence classification step for grouping those isotopes into potential peptide features. PointIso is the first point cloud based, arbitrary-precision deep learning network to address the problem and achieves 98% detection of high quality MS/MS identifications in a benchmark dataset, which is higher than several other widely used algorithms. Besides contributing to the proteomics study, we believe our novel segmentation technique should serve the general image processing domain as well.
3D_DEN: Open-ended 3D Object Recognition using Dynamically Expandable Networks
Sep 15, 2020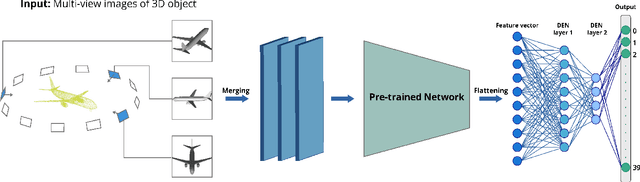
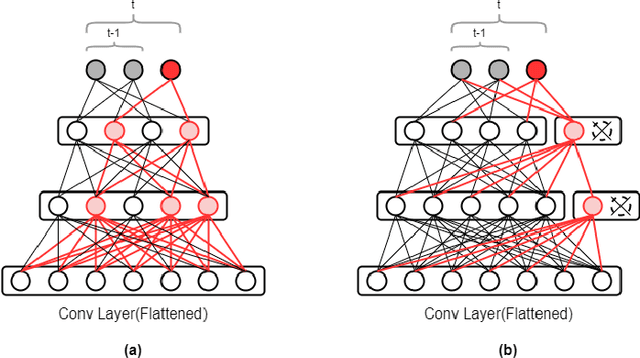
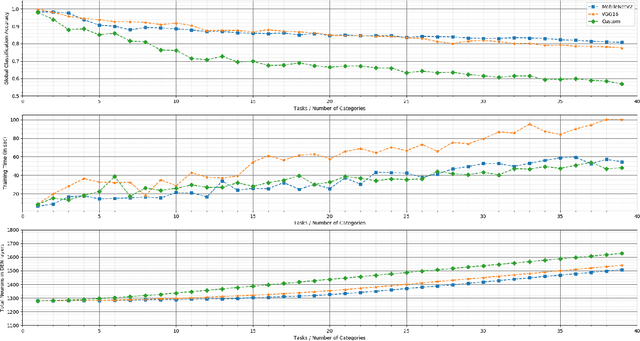
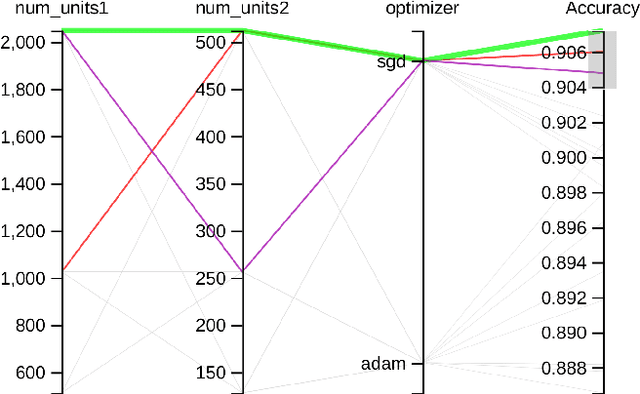
Service robots, in general, have to work independently and adapt to the dynamic changes in the environment. One important aspect in such scenarios is to continually learn to recognize new objects when they become available. This combines two main research problems namely continual learning and 3D object recognition. Most of the existing research approaches include the use of deep Convolutional Neural Networks (CNNs) focusing on image datasets. A modified approach might be needed for continually learning 3D objects. A major concern in using CNNs is the problem of catastrophic forgetting when a model tries to learn new data. In spite of various recent proposed solutions to mitigate this problem, there still exist a few side-effects (such as time/computational complexity) of such solutions. We propose a model capable of learning 3D objects in an open-ended fashion by employing deep transfer learning-based approach combined with dynamically expandable layers, which also makes sure that these side-effects are minimized to a great extent. We show that this model sets a new state-of-the-art standard not only with regards to accuracy but also for computational complexity.
Interactive Visual Study of Multiple Attributes Learning Model of X-Ray Scattering Images
Sep 03, 2020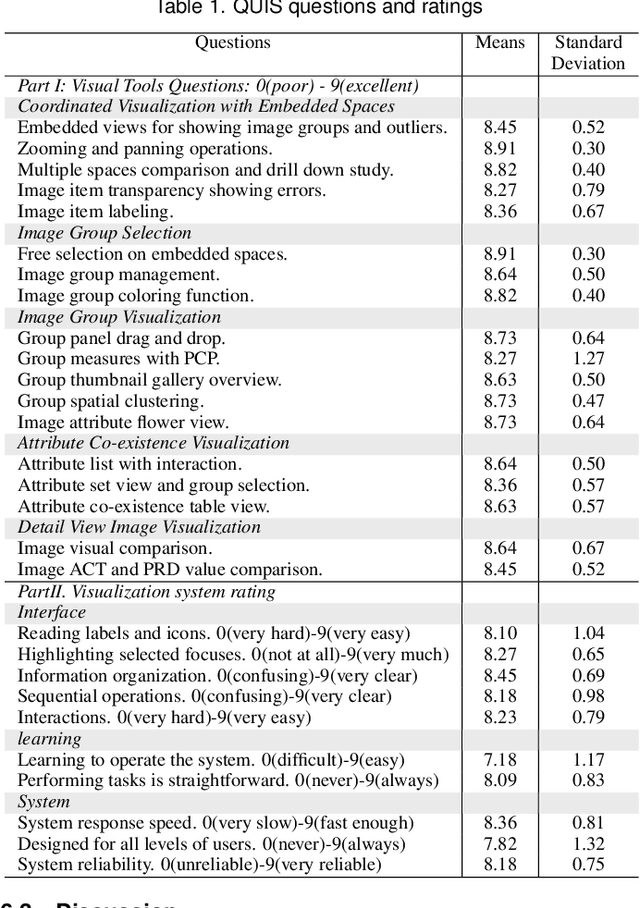

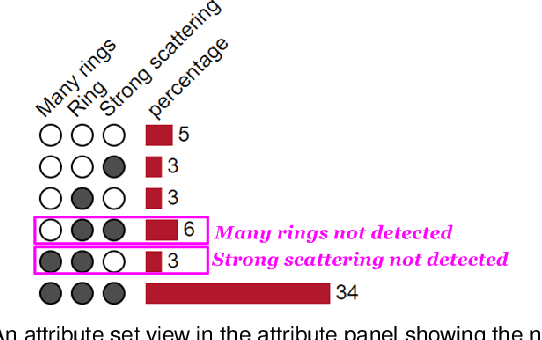

Existing interactive visualization tools for deep learning are mostly applied to the training, debugging, and refinement of neural network models working on natural images. However, visual analytics tools are lacking for the specific application of x-ray image classification with multiple structural attributes. In this paper, we present an interactive system for domain scientists to visually study the multiple attributes learning models applied to x-ray scattering images. It allows domain scientists to interactively explore this important type of scientific images in embedded spaces that are defined on the model prediction output, the actual labels, and the discovered feature space of neural networks. Users are allowed to flexibly select instance images, their clusters, and compare them regarding the specified visual representation of attributes. The exploration is guided by the manifestation of model performance related to mutual relationships among attributes, which often affect the learning accuracy and effectiveness. The system thus supports domain scientists to improve the training dataset and model, find questionable attributes labels, and identify outlier images or spurious data clusters. Case studies and scientists feedback demonstrate its functionalities and usefulness.
* IEEE SciVis Conference 2020
AMRNet: Chips Augmentation in Areial Images Object Detection
Sep 15, 2020
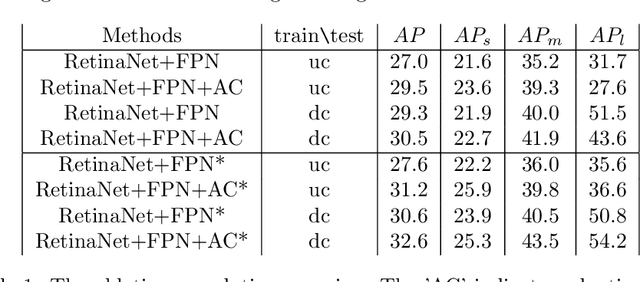
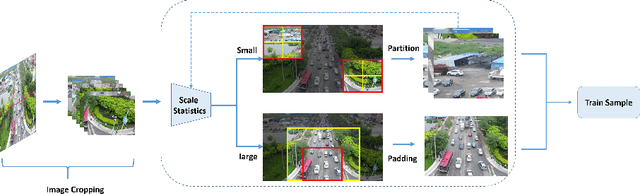
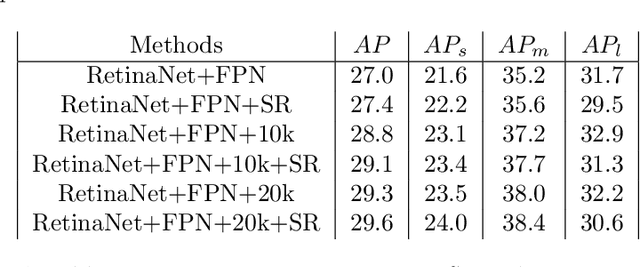
Detecting object in aerial image is challenging task due to 1) objects are often small and dense relative to images. 2) object scale varies in a large range. 3) object number in different classes is imbalanced. Current solutions almost adopt cropping method: splitting high resolution images into serials subregions (chips) and detecting on them. However, few works notice that some problems including scale variation, object sparsity exist when directly train network with chips. In this work, Three augmentation methods are introduced. Specifically, we propose a scale adaptive module compatable with all existing cropping method. It dynamically adjust cropping size to balance cover proportion between objects and chips, which narrows object scale variation in training and improves performance without bells and whistels; In addtion, we introduce mosaic effective sloving object sparity and background similarity problems in areial dataset; To balance catgory, we present mask resampling in chips providing higher quality training sample; Our model achieves state-of-the-art perfomance on two popular aerial images datasets of VisDrone and UAVDT. Remarkably, All methods can independent apply to detectiors increasing performance steady without the sacrifice of inference efficiency.
Maximum Entropy Regularization and Chinese Text Recognition
Jul 09, 2020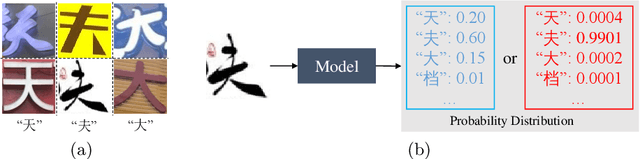

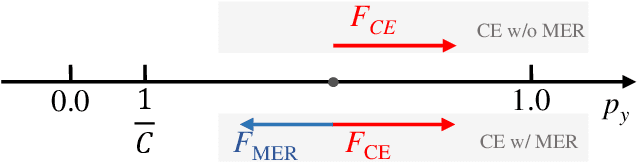

Chinese text recognition is more challenging than Latin text due to the large amount of fine-grained Chinese characters and the great imbalance over classes, which causes a serious overfitting problem. We propose to apply Maximum Entropy Regularization to regularize the training process, which is to simply add a negative entropy term to the canonical cross-entropy loss without any additional parameters and modification of a model. We theoretically give the convergence probability distribution and analyze how the regularization influence the learning process. Experiments on Chinese character recognition, Chinese text line recognition and fine-grained image classification achieve consistent improvement, proving that the regularization is beneficial to generalization and robustness of a recognition model.
A low cost non-wearable gaze detection system based on infrared image processing
Sep 12, 2017
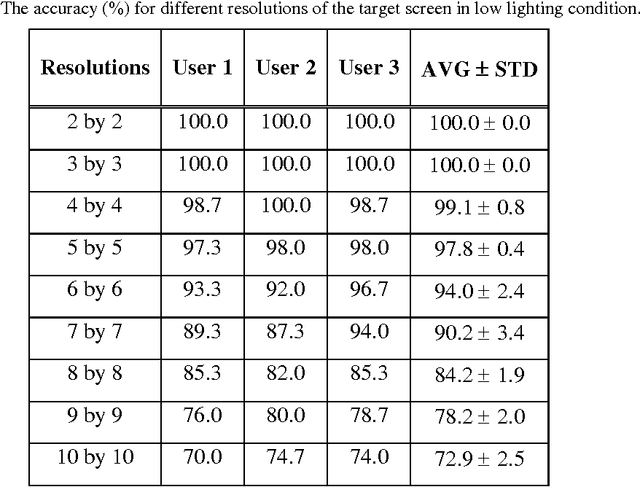
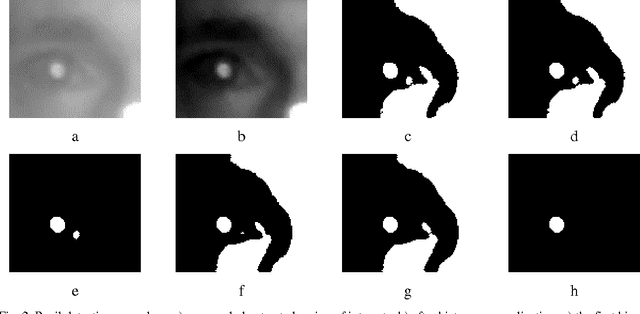
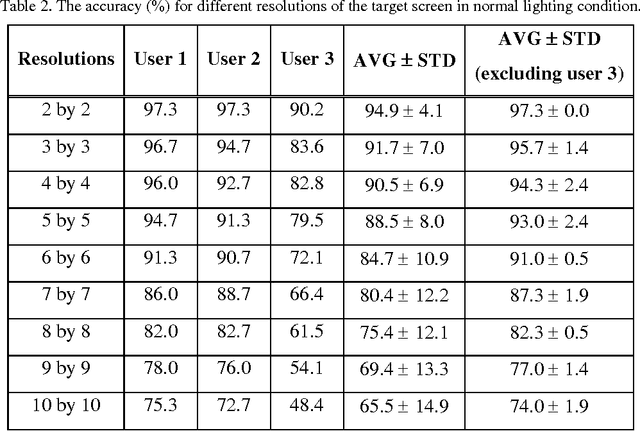
Human eye gaze detection plays an important role in various fields, including human-computer interaction, virtual reality and cognitive science. Although different relatively accurate systems of eye tracking and gaze detection exist, they are usually either too expensive to be bought for low cost applications or too complex to be implemented easily. In this article, we propose a non-wearable system for eye tracking and gaze detection with low complexity and cost. The proposed system provides a medium accuracy which makes it suitable for general applications in which low cost and easy implementation is more important than achieving very precise gaze detection. The proposed method includes pupil and marker detection using infrared image processing, and gaze evaluation using an interpolation-based strategy. The interpolation-based strategy exploits the positions of the detected pupils and markers in a target captured image and also in some previously captured training images for estimating the position of a point that the user is gazing at. The proposed system has been evaluated by three users in two different lighting conditions. The experimental results show that the accuracy of this low cost system can be between 90% and 100% for finding major gazing directions.
Learning Rich Image Region Representation for Visual Question Answering
Oct 29, 2019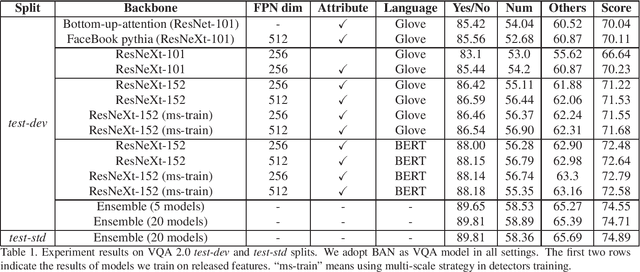
We propose to boost VQA by leveraging more powerful feature extractors by improving the representation ability of both visual and text features and the ensemble of models. For visual feature, some detection techniques are used to improve the detector. For text feature, we adopt BERT as the language model and find that it can significantly improve VQA performance. Our solution won the second place in the VQA Challenge 2019.
Null-sampling for Interpretable and Fair Representations
Aug 12, 2020

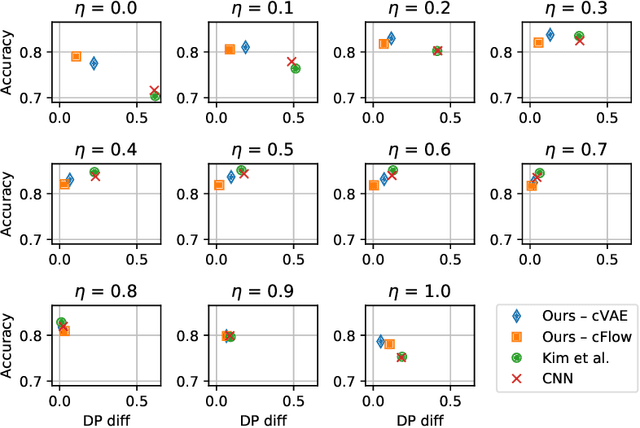

We propose to learn invariant representations, in the data domain, to achieve interpretability in algorithmic fairness. Invariance implies a selectivity for high level, relevant correlations w.r.t. class label annotations, and a robustness to irrelevant correlations with protected characteristics such as race or gender. We introduce a non-trivial setup in which the training set exhibits a strong bias such that class label annotations are irrelevant and spurious correlations cannot be distinguished. To address this problem, we introduce an adversarially trained model with a null-sampling procedure to produce invariant representations in the data domain. To enable disentanglement, a partially-labelled representative set is used. By placing the representations into the data domain, the changes made by the model are easily examinable by human auditors. We show the effectiveness of our method on both image and tabular datasets: Coloured MNIST, the CelebA and the Adult dataset.
Hidden Footprints: Learning Contextual Walkability from 3D Human Trails
Aug 19, 2020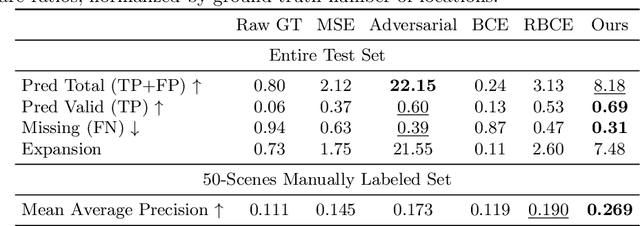
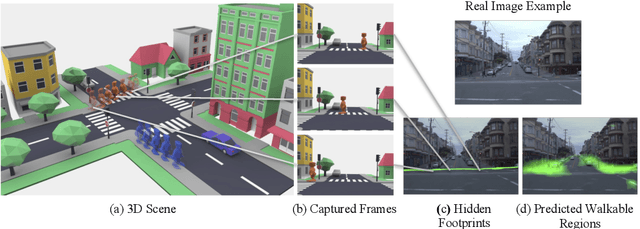
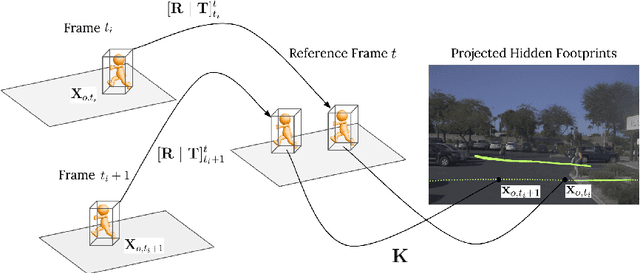

Predicting where people can walk in a scene is important for many tasks, including autonomous driving systems and human behavior analysis. Yet learning a computational model for this purpose is challenging due to semantic ambiguity and a lack of labeled data: current datasets only tell you where people are, not where they could be. We tackle this problem by leveraging information from existing datasets, without additional labeling. We first augment the set of valid, labeled walkable regions by propagating person observations between images, utilizing 3D information to create what we call hidden footprints. However, this augmented data is still sparse. We devise a training strategy designed for such sparse labels, combining a class-balanced classification loss with a contextual adversarial loss. Using this strategy, we demonstrate a model that learns to predict a walkability map from a single image. We evaluate our model on the Waymo and Cityscapes datasets, demonstrating superior performance compared to baselines and state-of-the-art models.