 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning with Robust Rubric Rewards
May 28, 2026While Reinforcement Learning with Verifiable Rewards (RLVR) is effective for deterministically checkable tasks, many vision-language tasks are partially verifiable, demanding multi-criteria supervision (e.g., perceptual details, reasoning steps, and constraints). Rubrics provide a natural interface for this fine-grained supervision, but their effectiveness depends on the execution accuracy during online RL. We propose Reinforcement Learning with Robust Rubric Rewards ($\text{RLR}^3$), extending RLVR from task-level verification to criterion-level verification. $\text{RLR}^3$ routes instance-specific rubrics through two execution paths: an LLM-as-an-extractor paired with a deterministic verifier, or an LLM-as-a-Judge for non-verifiable criteria. To ensure faithful scoring, $\text{RLR}^3$ introduce a minimal exposure strategy that masks ground truths from extractors and images from judges. Furthermore, $\text{RLR}^3$ employs hierarchical aggregation to prioritize essential criteria over additional criteria, and mitigates score saturation within rollout groups. Evaluated on Qwen3-VL-30B-A3B across 15 benchmarks, $\text{RLR}^3$ consistently outperforms RLVR, yielding a 4.7-point improvement over the base model and exceeding the official instruct-to-thinking model gap. Controlled audits confirm our deterministic verification and minimal exposure significantly reduce exploitable false positives.
Visual Preference Optimization with Rubric Rewards
Apr 14, 2026The effectiveness of Direct Preference Optimization (DPO) depends on preference data that reflect the quality differences that matter in multimodal tasks. Existing pipelines often rely on off-policy perturbations or coarse outcome-based signals, which are not well suited to fine-grained visual reasoning. We propose rDPO, a preference optimization framework based on instance-specific rubrics. For each image-instruction pair, we create a checklist-style rubric of essential and additional criteria to score responses from any possible policies. The instruction-rubric pool is built offline and reused during the construction of on-policy data. On public reward modeling benchmarks, rubric-based prompting massively improves a 30B-A3B judge and brings it close to GPT-5.4. On public downstream benchmarks, rubric-based filtering raises the macro average to 82.69, whereas outcome-based filtering drops it to 75.82 from 81.14. When evaluating scalability on a comprehensive benchmark, rDPO achieves 61.01, markedly outperforming the style-constrained baseline (52.36) and surpassing the 59.48 base model. Together, these results show that visual preference optimization benefits from combining on-policy data construction with instance-specific criterion-level feedback.
Maximum Entropy Regularization and Chinese Text Recognition
Jul 09, 2020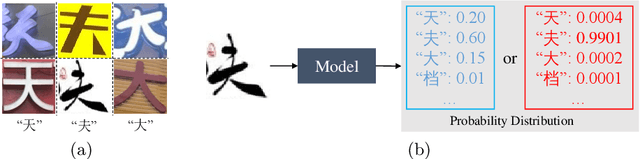

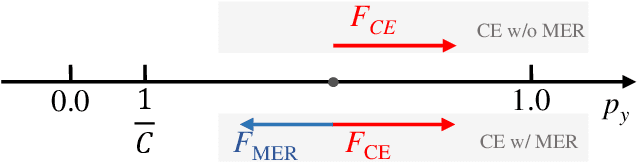

Chinese text recognition is more challenging than Latin text due to the large amount of fine-grained Chinese characters and the great imbalance over classes, which causes a serious overfitting problem. We propose to apply Maximum Entropy Regularization to regularize the training process, which is to simply add a negative entropy term to the canonical cross-entropy loss without any additional parameters and modification of a model. We theoretically give the convergence probability distribution and analyze how the regularization influence the learning process. Experiments on Chinese character recognition, Chinese text line recognition and fine-grained image classification achieve consistent improvement, proving that the regularization is beneficial to generalization and robustness of a recognition model.