 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Random Projections for Adversarial Attack Detection
Dec 11, 2020
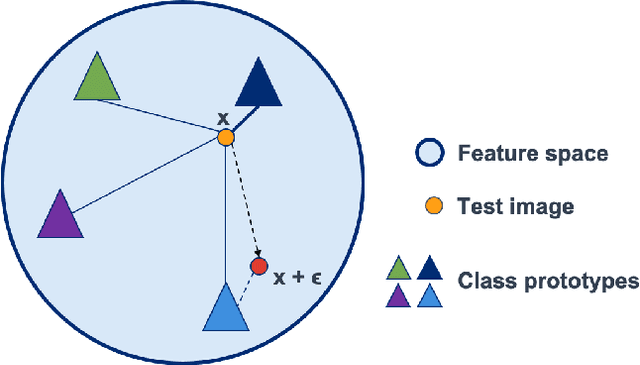
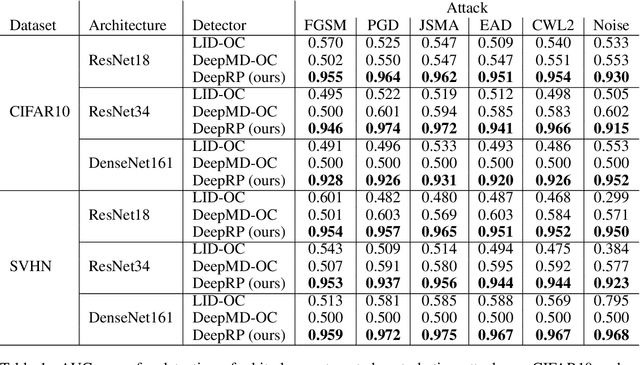
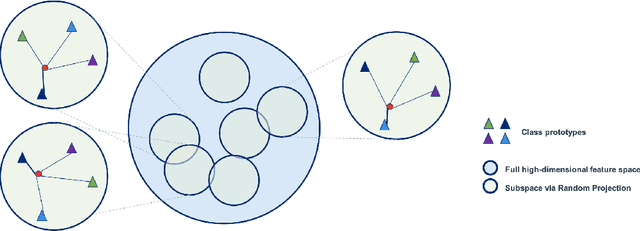
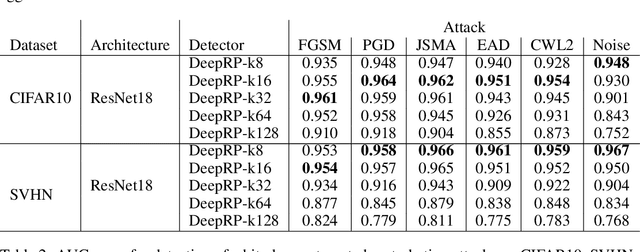
Whilst adversarial attack detection has received considerable attention, it remains a fundamentally challenging problem from two perspectives. First, while threat models can be well-defined, attacker strategies may still vary widely within those constraints. Therefore, detection should be considered as an open-set problem, standing in contrast to most current detection strategies. These methods take a closed-set view and train binary detectors, thus biasing detection toward attacks seen during detector training. Second, information is limited at test time and confounded by nuisance factors including the label and underlying content of the image. Many of the current high-performing techniques use training sets for dealing with some of these issues, but can be limited by the overall size and diversity of those sets during the detection step. We address these challenges via a novel strategy based on random subspace analysis. We present a technique that makes use of special properties of random projections, whereby we can characterize the behavior of clean and adversarial examples across a diverse set of subspaces. We then leverage the self-consistency (or inconsistency) of model activations to discern clean from adversarial examples. Performance evaluation demonstrates that our technique outperforms ($>0.92$ AUC) competing state of the art (SOTA) attack strategies, while remaining truly agnostic to the attack method itself. It also requires significantly less training data, composed only of clean examples, when compared to competing SOTA methods, which achieve only chance performance, when evaluated in a more rigorous testing scenario.
GuCNet: A Guided Clustering-based Network for Improved Classification
Oct 11, 2020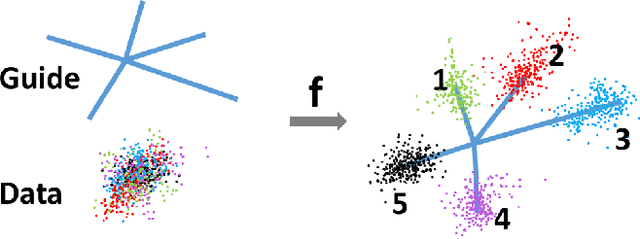
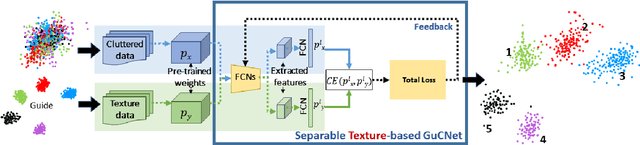
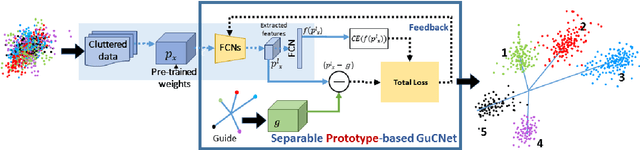

We deal with the problem of semantic classification of challenging and highly-cluttered dataset. We present a novel, and yet a very simple classification technique by leveraging the ease of classifiability of any existing well separable dataset for guidance. Since the guide dataset which may or may not have any semantic relationship with the experimental dataset, forms well separable clusters in the feature set, the proposed network tries to embed class-wise features of the challenging dataset to those distinct clusters of the guide set, making them more separable. Depending on the availability, we propose two types of guide sets: one using texture (image) guides and another using prototype vectors representing cluster centers. Experimental results obtained on the challenging benchmark RSSCN, LSUN, and TU-Berlin datasets establish the efficacy of the proposed method as we outperform the existing state-of-the-art techniques by a considerable margin.
3D Point Cloud Feature Explanations Using Gradient-Based Methods
Jun 09, 2020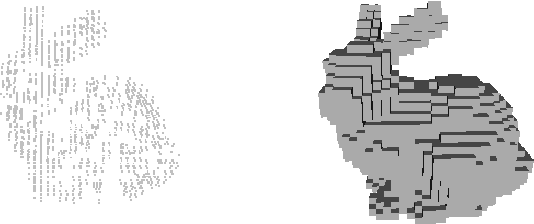
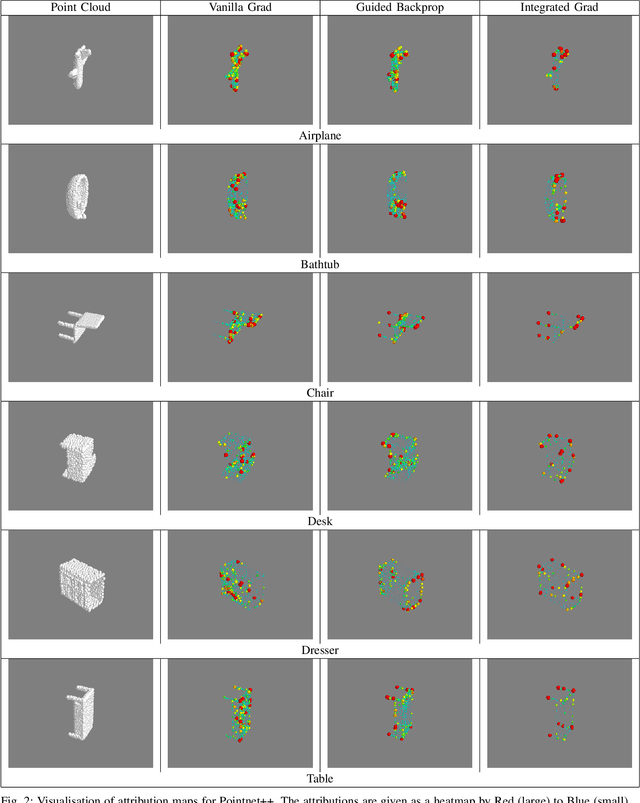
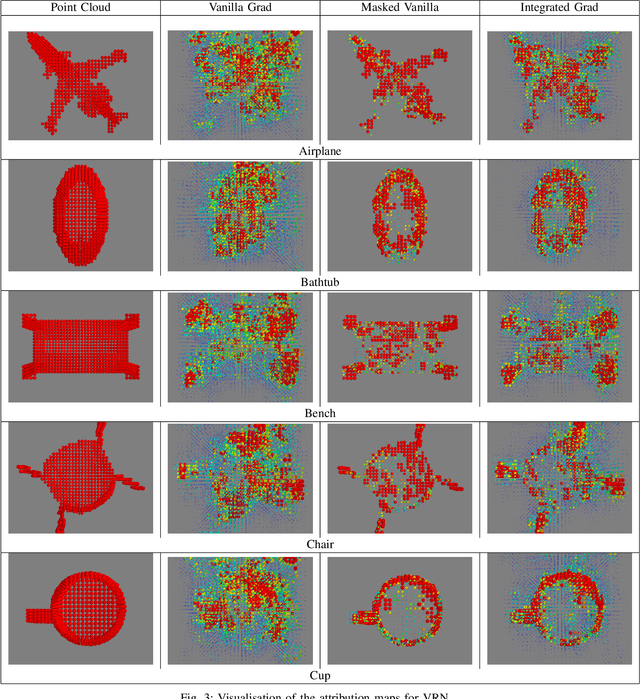

Explainability is an important factor to drive user trust in the use of neural networks for tasks with material impact. However, most of the work done in this area focuses on image analysis and does not take into account 3D data. We extend the saliency methods that have been shown to work on image data to deal with 3D data. We analyse the features in point clouds and voxel spaces and show that edges and corners in 3D data are deemed as important features while planar surfaces are deemed less important. The approach is model-agnostic and can provide useful information about learnt features. Driven by the insight that 3D data is inherently sparse, we visualise the features learnt by a voxel-based classification network and show that these features are also sparse and can be pruned relatively easily, leading to more efficient neural networks. Our results show that the Voxception-ResNet model can be pruned down to 5\% of its parameters with negligible loss in accuracy.
Model-based disentanglement of lens occlusions
Apr 02, 2020
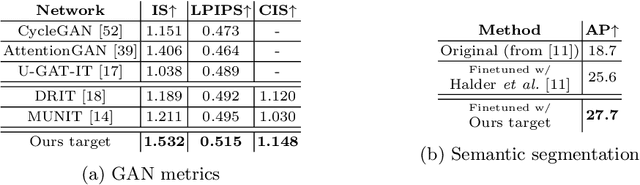
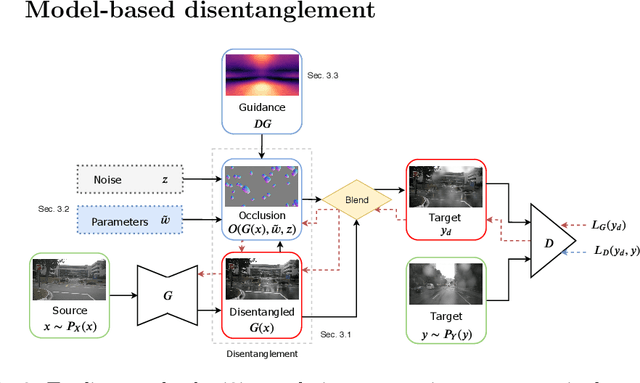
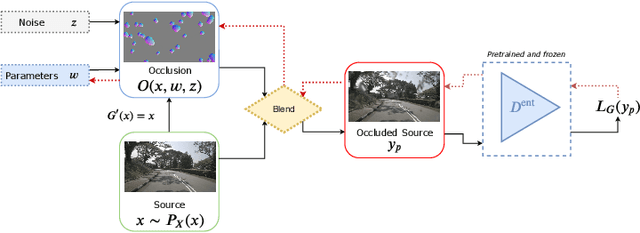
With lens occlusions, naive image-to-image networks fail to learn an accurate source to target mapping, due to the partial entanglement of the scene and occlusion domains. We propose an unsupervised model-based disentanglement training, which learns to disentangle scene from lens occlusion and can regress the occlusion model parameters from target database. The experiments demonstrate our method is able to handle varying types of occlusions (raindrops, dirt, watermarks, etc.) and generate highly realistic translations, qualitatively and quantitatively outperforming the state-of-the-art on multiple datasets.
Resolution-Enhanced MRI-Guided Navigation of Spinal Cellular Injection Robot
Jun 09, 2020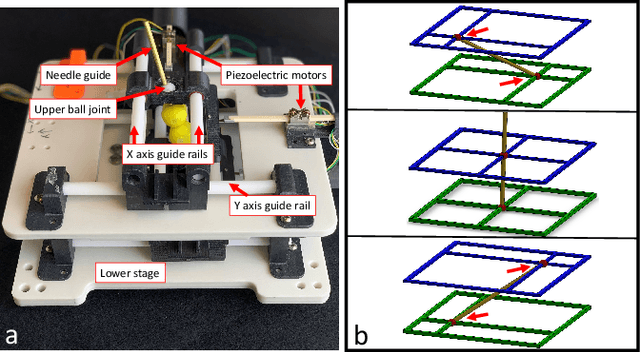
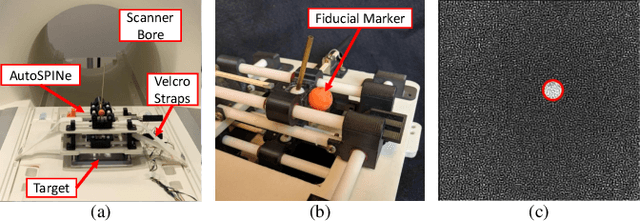
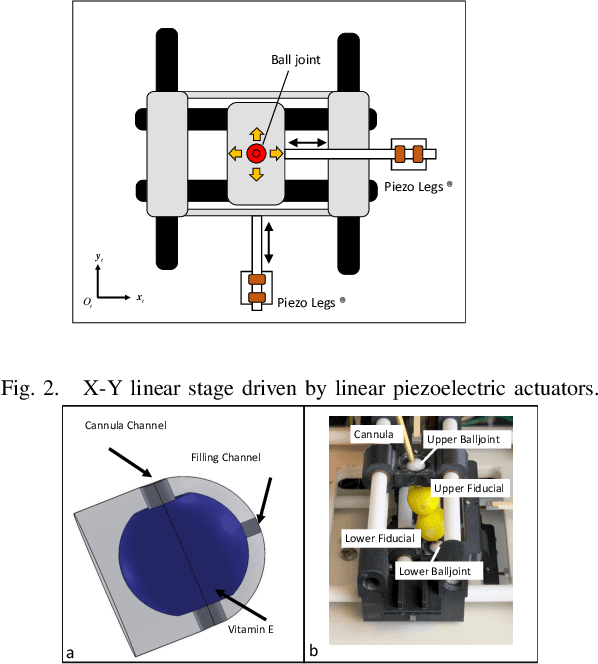
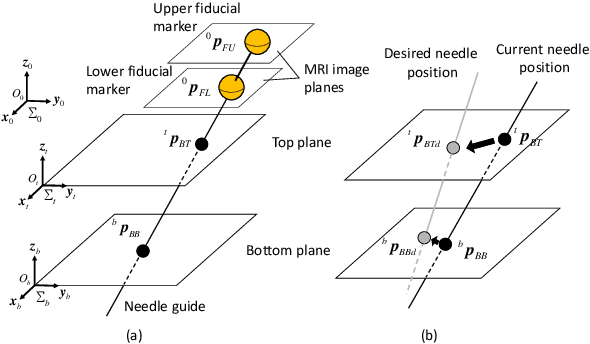
This paper presents a method of navigating a surgical robot beyond the resolution of magnetic resonance imaging (MRI) by using a resolution enhancement technique enabled by high-precision piezoelectric actuation. The surgical robot was specifically designed for injecting stem cells into the spinal cord. This particular therapy can be performed in a shorter time by using a MRI-compatible robotic platform than by using a manual needle positioning platform. Imaging resolution of fiducial markers attached to the needle guide tubing was enhanced by reconstructing a high-resolution image from multiple images with sub-pixel movements of the robot. The parallel-plane direct-drive needle positioning mechanism positioned the needle guide with a high spatial precision that is two orders of magnitude higher than typical MRI resolution up to 1 mm. Reconstructed resolution enhanced images were used to navigate the robot precisely that would not have been possible by using standard MRI. Experiments were conducted to verify the effectiveness of the proposed enhanced-resolution image-guided intervention.
Multi-species Seagrass Detection and Classification from Underwater Images
Sep 18, 2020
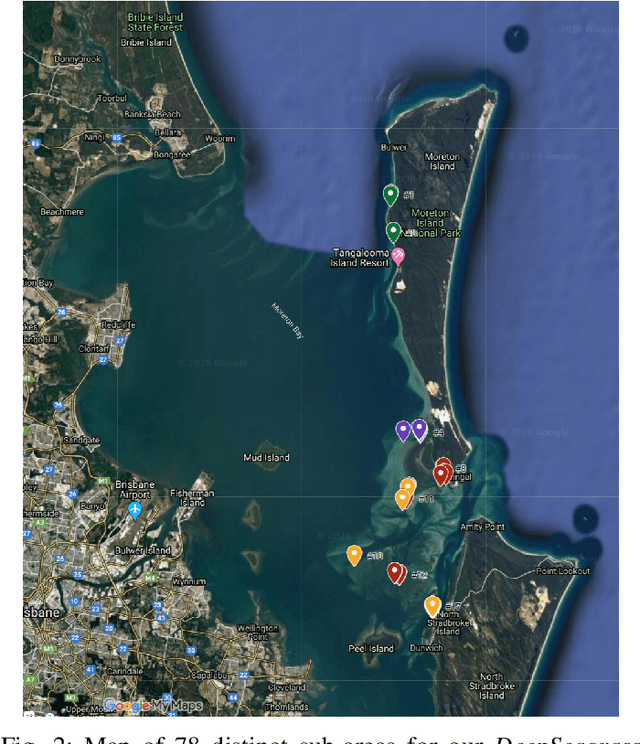
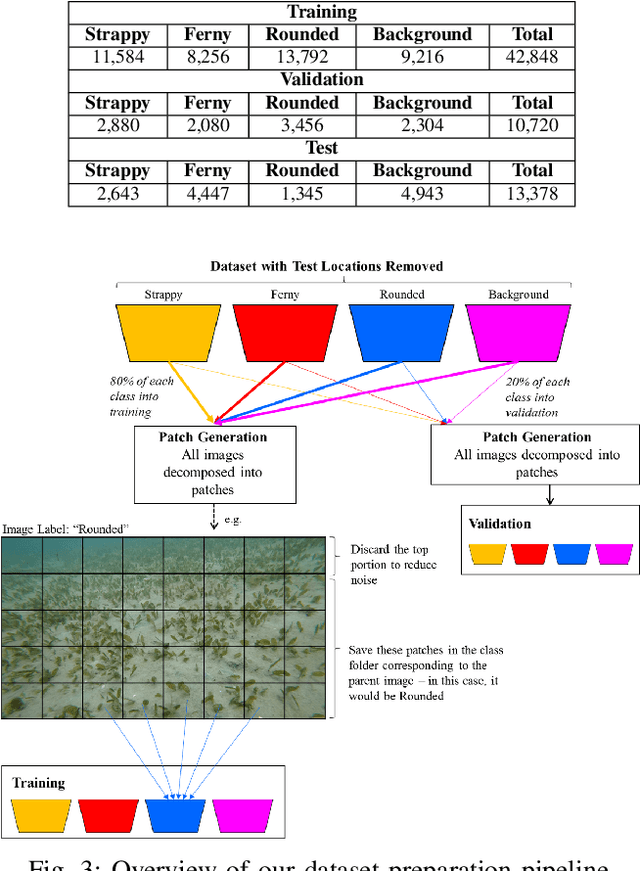

Underwater surveys conducted using divers or robots equipped with customized camera payloads can generate a large number of images. Manual review of these images to extract ecological data is prohibitive in terms of time and cost, thus providing strong incentive to automate this process using machine learning solutions. In this paper, we introduce a multi-species detector and classifier for seagrasses based on a deep convolutional neural network (achieved an overall accuracy of 92.4%). We also introduce a simple method to semi-automatically label image patches and therefore minimize manual labelling requirement. We describe and release publicly the dataset collected in this study as well as the code and pre-trained models to replicate our experiments at: https://github.com/csiro-robotics/deepseagrass
Learning Order Parameters from Videos of Dynamical Phases for Skyrmions with Neural Networks
Dec 02, 2020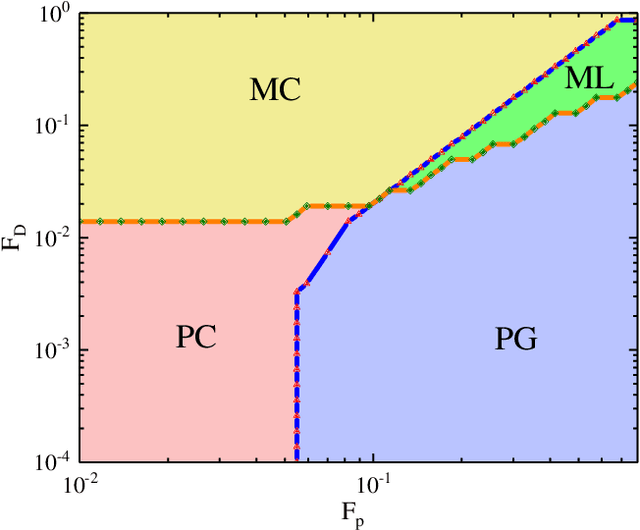

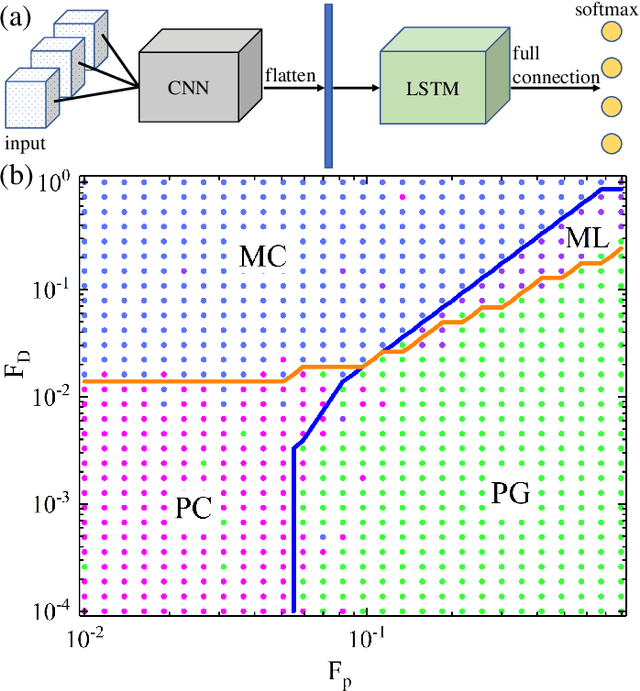
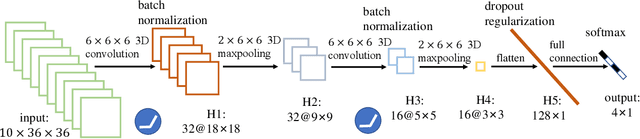
The ability to recognize dynamical phenomena (e.g., dynamical phases) and dynamical processes in physical events from videos, then to abstract physical concepts and reveal physical laws, lies at the core of human intelligence. The main purposes of this paper are to use neural networks for classifying the dynamical phases of some videos and to demonstrate that neural networks can learn physical concepts from them. To this end, we employ multiple neural networks to recognize the static phases (image format) and dynamical phases (video format) of a particle-based skyrmion model. Our results show that neural networks, without any prior knowledge, can not only correctly classify these phases, but also predict the phase boundaries which agree with those obtained by simulation. We further propose a parameter visualization scheme to interpret what neural networks have learned. We show that neural networks can learn two order parameters from videos of dynamical phases and predict the critical values of two order parameters. Finally, we demonstrate that only two order parameters are needed to identify videos of skyrmion dynamical phases. It shows that this parameter visualization scheme can be used to determine how many order parameters are needed to fully recognize the input phases. Our work sheds light on the future use of neural networks in discovering new physical concepts and revealing unknown yet physical laws from videos.
Weakly supervised one-stage vision and language disease detection using large scale pneumonia and pneumothorax studies
Jul 31, 2020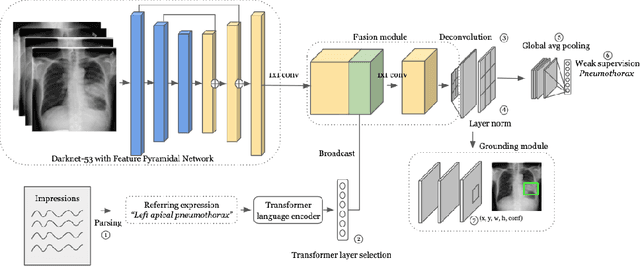
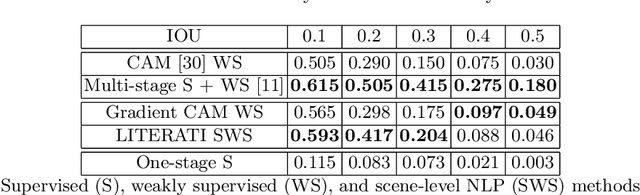
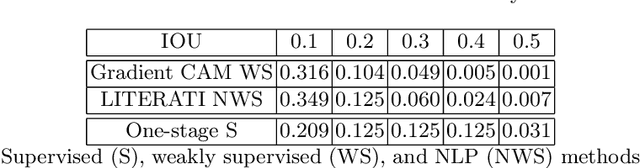
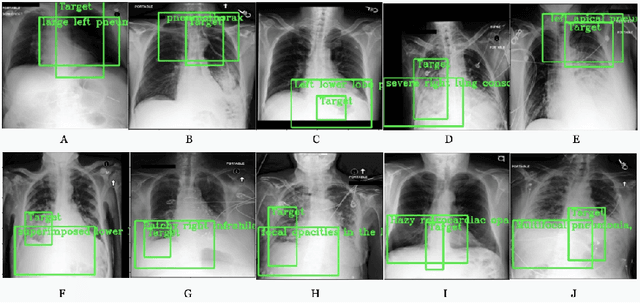
Detecting clinically relevant objects in medical images is a challenge despite large datasets due to the lack of detailed labels. To address the label issue, we utilize the scene-level labels with a detection architecture that incorporates natural language information. We present a challenging new set of radiologist paired bounding box and natural language annotations on the publicly available MIMIC-CXR dataset especially focussed on pneumonia and pneumothorax. Along with the dataset, we present a joint vision language weakly supervised transformer layer-selected one-stage dual head detection architecture (LITERATI) alongside strong baseline comparisons with class activation mapping (CAM), gradient CAM, and relevant implementations on the NIH ChestXray-14 and MIMIC-CXR dataset. Borrowing from advances in vision language architectures, the LITERATI method demonstrates joint image and referring expression (objects localized in the image using natural language) input for detection that scales in a purely weakly supervised fashion. The architectural modifications address three obstacles -- implementing a supervised vision and language detection method in a weakly supervised fashion, incorporating clinical referring expression natural language information, and generating high fidelity detections with map probabilities. Nevertheless, the challenging clinical nature of the radiologist annotations including subtle references, multi-instance specifications, and relatively verbose underlying medical reports, ensures the vision language detection task at scale remains stimulating for future investigation.
Learning for Scale-Arbitrary Super-Resolution from Scale-Specific Networks
Apr 08, 2020
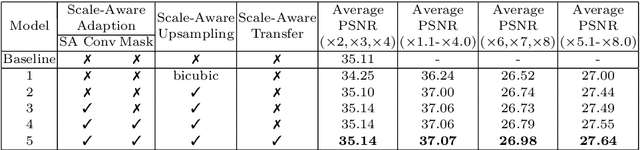
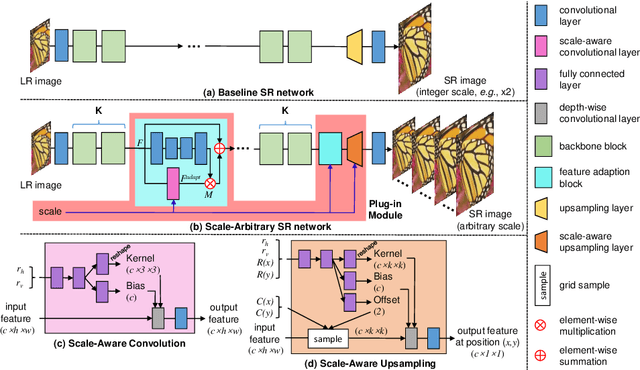
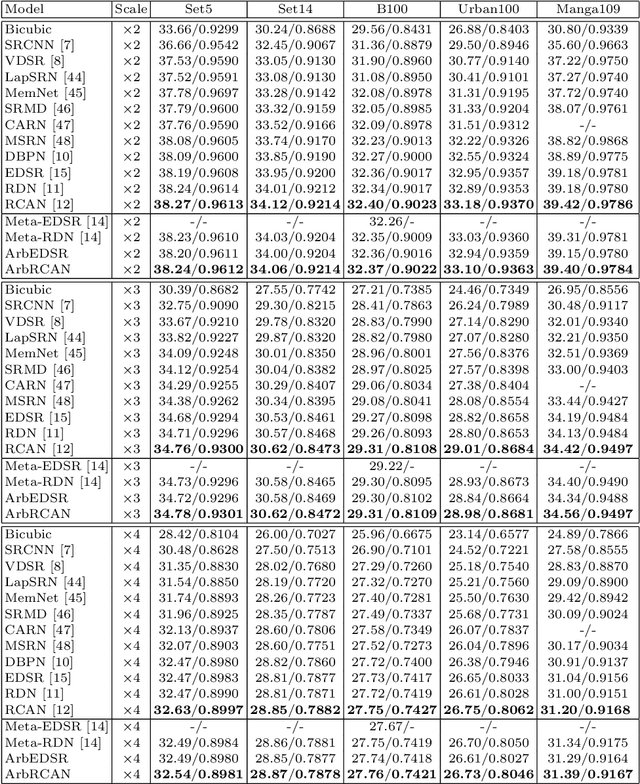
Recently, the performance of single image super-resolution (SR) has been significantly improved with powerful networks. However, these networks are developed for image SR with a single specific integer scale (e.g., x2;x3,x4), and cannot be used for non-integer and asymmetric SR. In this paper, we propose to learn a scale-arbitrary image SR network from scale-specific networks. Specifically, we propose a plug-in module for existing SR networks to perform scale-arbitrary SR, which consists of multiple scale-aware feature adaption blocks and a scale-aware upsampling layer. Moreover, we introduce a scale-aware knowledge transfer paradigm to transfer knowledge from scale-specific networks to the scale-arbitrary network. Our plug-in module can be easily adapted to existing networks to achieve scale-arbitrary SR. These networks plugged with our module can achieve promising results for non-integer and asymmetric SR while maintaining state-of-the-art performance for SR with integer scale factors. Besides, the additional computational and memory cost of our module is very small.
DeepAveragers: Offline Reinforcement Learning by Solving Derived Non-Parametric MDPs
Oct 18, 2020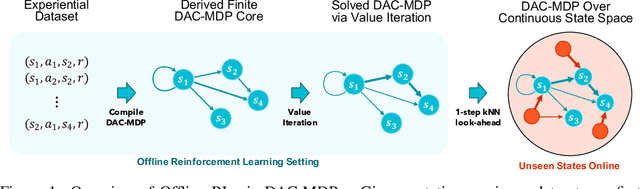

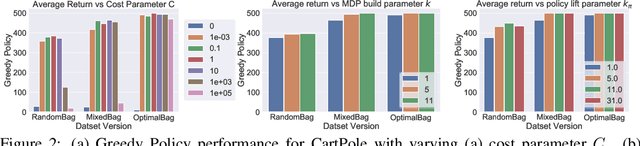
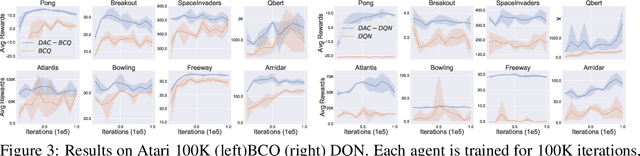
We study an approach to offline reinforcement learning (RL) based on optimally solving finitely-represented MDPs derived from a static dataset of experience. This approach can be applied on top of any learned representation and has the potential to easily support multiple solution objectives as well as zero-shot adjustment to changing environments and goals. Our main contribution is to introduce the Deep Averagers with Costs MDP (DAC-MDP) and to investigate its solutions for offline RL. DAC-MDPs are a non-parametric model that can leverage deep representations and account for limited data by introducing costs for exploiting under-represented parts of the model. In theory, we show conditions that allow for lower-bounding the performance of DAC-MDP solutions. We also investigate the empirical behavior in a number of environments, including those with image-based observations. Overall, the experiments demonstrate that the framework can work in practice and scale to large complex offline RL problems.