 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuided Disentanglement in Generative Networks
Jul 29, 2021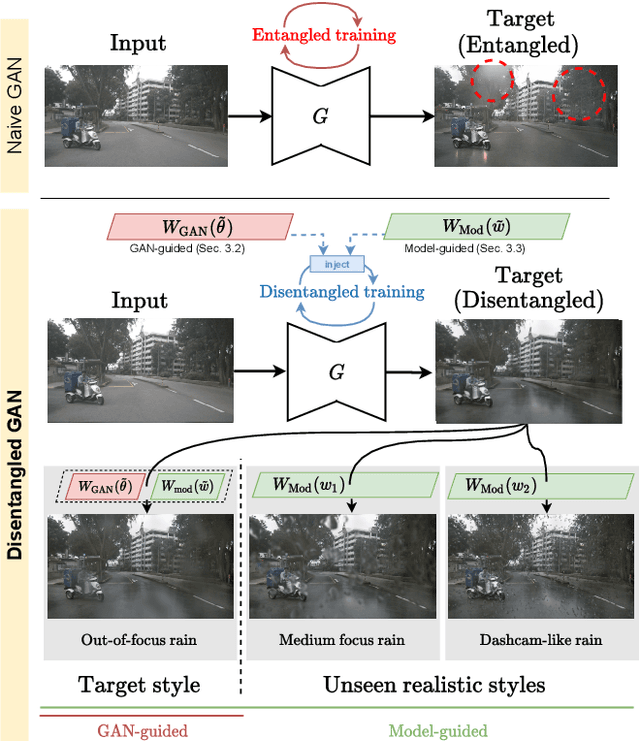
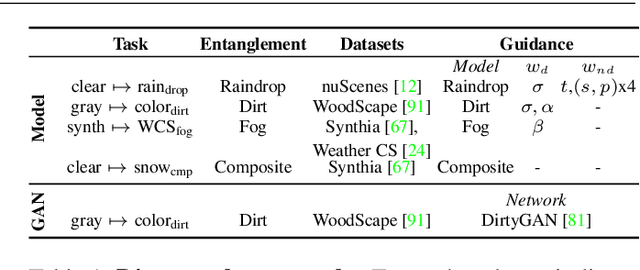
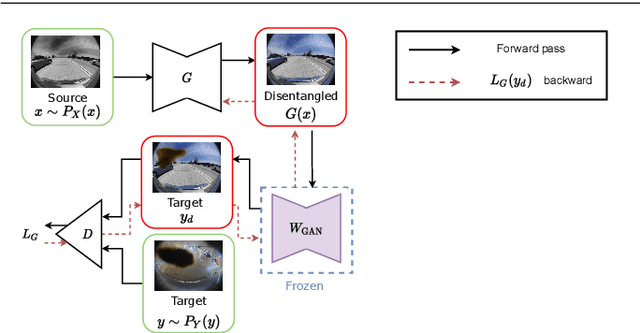
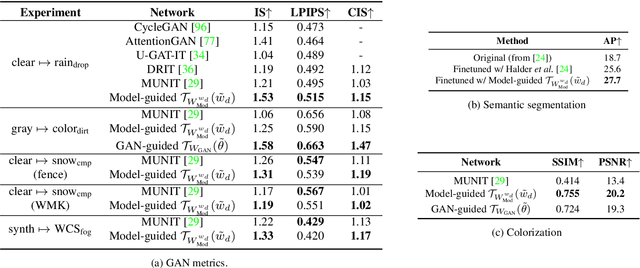
Image-to-image translation (i2i) networks suffer from entanglement effects in presence of physics-related phenomena in target domain (such as occlusions, fog, etc), thus lowering the translation quality and variability. In this paper, we present a comprehensive method for disentangling physics-based traits in the translation, guiding the learning process with neural or physical models. For the latter, we integrate adversarial estimation and genetic algorithms to correctly achieve disentanglement. The results show our approach dramatically increase performances in many challenging scenarios for image translation.
CoMoGAN: continuous model-guided image-to-image translation
Apr 08, 2021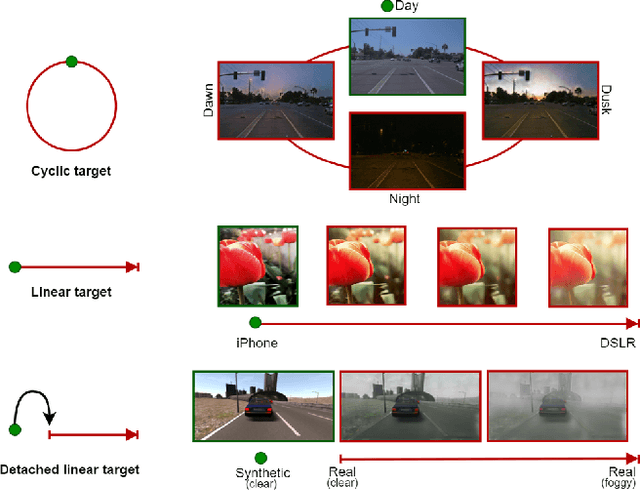

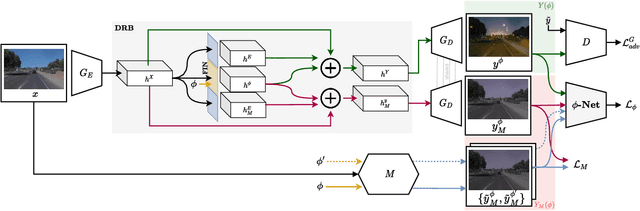
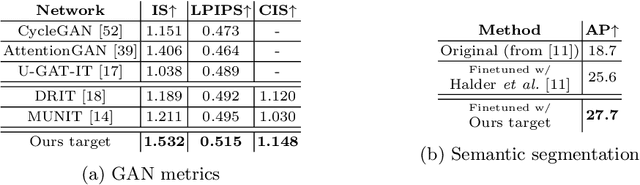
CoMoGAN is a continuous GAN relying on the unsupervised reorganization of the target data on a functional manifold. To that matter, we introduce a new Functional Instance Normalization layer and residual mechanism, which together disentangle image content from position on target manifold. We rely on naive physics-inspired models to guide the training while allowing private model/translations features. CoMoGAN can be used with any GAN backbone and allows new types of image translation, such as cyclic image translation like timelapse generation, or detached linear translation. On all datasets, it outperforms the literature. Our code is available at http://github.com/cv-rits/CoMoGAN .
Model-based disentanglement of lens occlusions
Apr 02, 2020
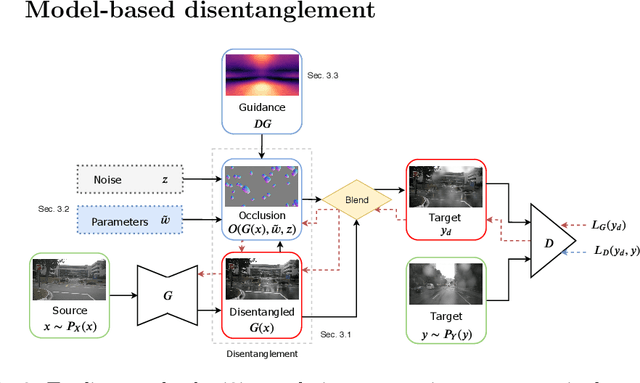
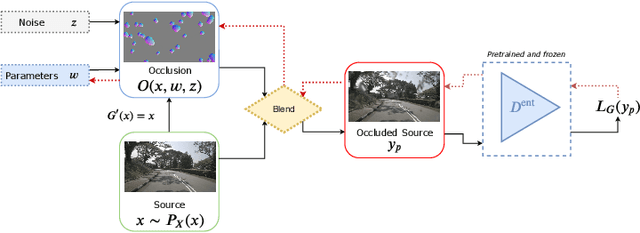
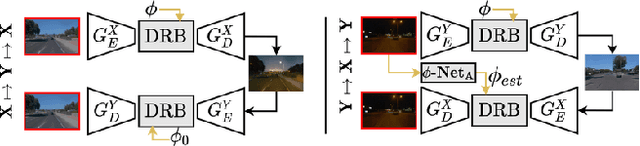
With lens occlusions, naive image-to-image networks fail to learn an accurate source to target mapping, due to the partial entanglement of the scene and occlusion domains. We propose an unsupervised model-based disentanglement training, which learns to disentangle scene from lens occlusion and can regress the occlusion model parameters from target database. The experiments demonstrate our method is able to handle varying types of occlusions (raindrops, dirt, watermarks, etc.) and generate highly realistic translations, qualitatively and quantitatively outperforming the state-of-the-art on multiple datasets.
Domain Bridge for Unpaired Image-to-Image Translation and Unsupervised Domain Adaptation
Oct 23, 2019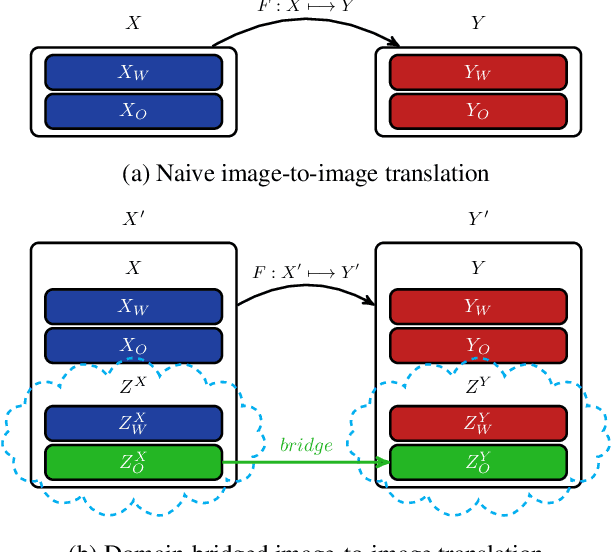
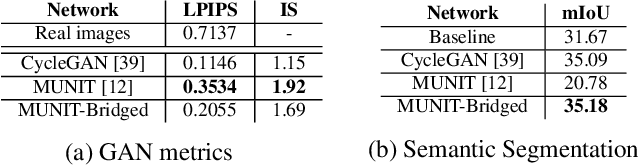
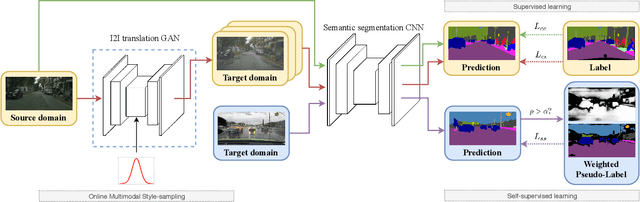

Image-to-image translation architectures may have limited effectiveness in some circumstances. For example, while generating rainy scenarios, they may fail to model typical traits of rain as water drops, and this ultimately impacts the synthetic images realism. With our method, called domain bridge, web-crawled data are exploited to reduce the domain gap, leading to the inclusion of previously ignored elements in the generated images. We make use of a network for clear to rain translation trained with the domain bridge to extend our work to Unsupervised Domain Adaptation (UDA). In that context, we introduce an online multimodal style-sampling strategy, where image translation multimodality is exploited at training time to improve performances. Finally, a novel approach for self-supervised learning is presented, and used to further align the domains. With our contributions, we simultaneously increase the realism of the generated images, while reaching on par performances w.r.t. the UDA state-of-the-art, with a simpler approach.