 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer Query-Target Knowledge Discovery (TEND): Drug Discovery from CORD-19
Dec 11, 2020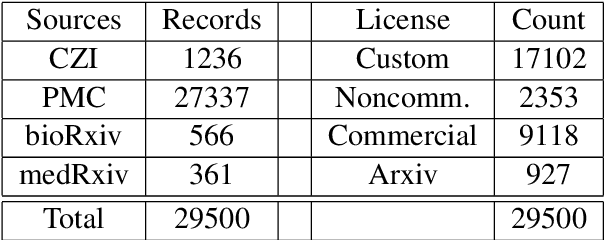
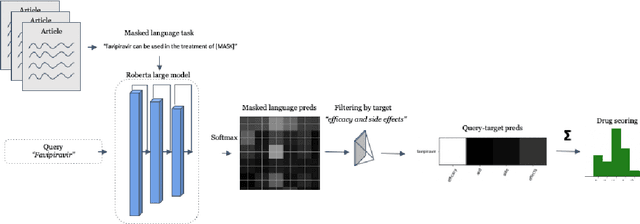
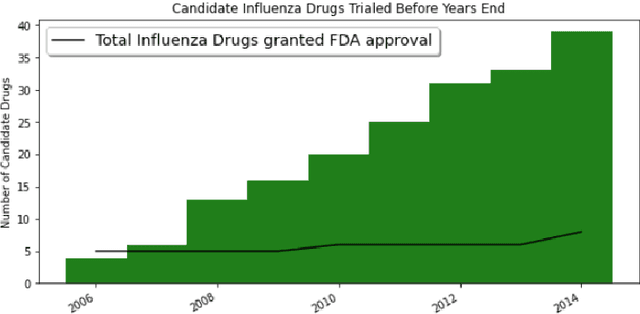
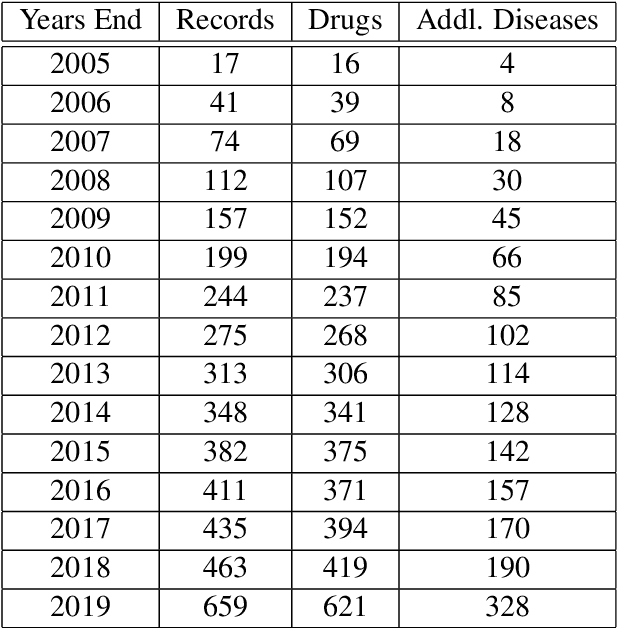
Previous work established skip-gram word2vec models could be used to mine knowledge in the materials science literature for the discovery of thermoelectrics. Recent transformer architectures have shown great progress in language modeling and associated fine-tuned tasks, but they have yet to be adapted for drug discovery. We present a RoBERTa transformer-based method that extends the masked language token prediction using query-target conditioning to treat the specificity challenge. The transformer discovery method entails several benefits over the word2vec method including domain-specific (antiviral) analogy performance, negation handling, and flexible query analysis (specific) and is demonstrated on influenza drug discovery. To stimulate COVID-19 research, we release an influenza clinical trials and antiviral analogies dataset used in conjunction with the COVID-19 Open Research Dataset Challenge (CORD-19) literature dataset in the study. We examine k-shot fine-tuning to improve the downstream analogies performance as well as to mine analogies for model explainability. Further, the query-target analysis is verified in a forward chaining analysis against the influenza drug clinical trials dataset, before adapted for COVID-19 drugs (combinations and side-effects) and on-going clinical trials. In consideration of the present topic, we release the model, dataset, and code.
Weakly supervised one-stage vision and language disease detection using large scale pneumonia and pneumothorax studies
Jul 31, 2020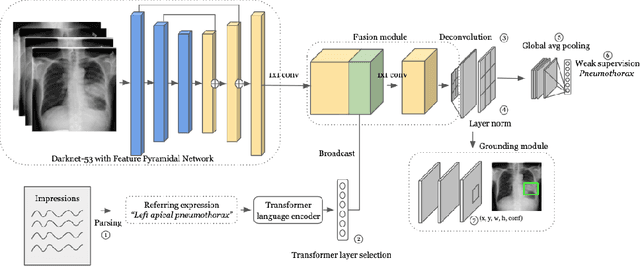
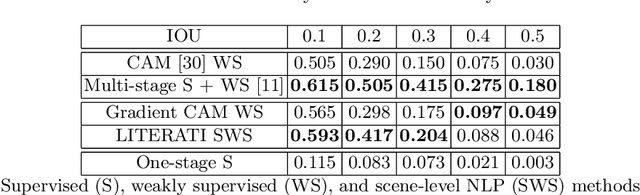
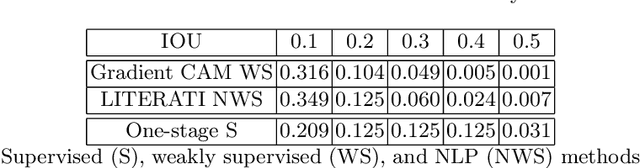
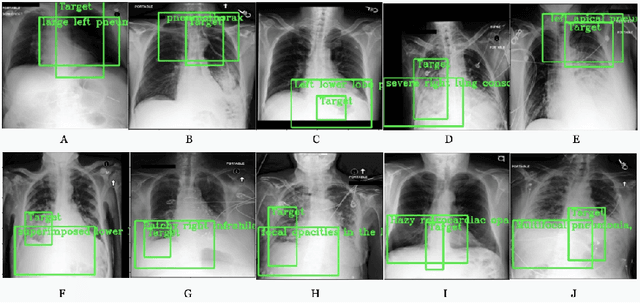
Detecting clinically relevant objects in medical images is a challenge despite large datasets due to the lack of detailed labels. To address the label issue, we utilize the scene-level labels with a detection architecture that incorporates natural language information. We present a challenging new set of radiologist paired bounding box and natural language annotations on the publicly available MIMIC-CXR dataset especially focussed on pneumonia and pneumothorax. Along with the dataset, we present a joint vision language weakly supervised transformer layer-selected one-stage dual head detection architecture (LITERATI) alongside strong baseline comparisons with class activation mapping (CAM), gradient CAM, and relevant implementations on the NIH ChestXray-14 and MIMIC-CXR dataset. Borrowing from advances in vision language architectures, the LITERATI method demonstrates joint image and referring expression (objects localized in the image using natural language) input for detection that scales in a purely weakly supervised fashion. The architectural modifications address three obstacles -- implementing a supervised vision and language detection method in a weakly supervised fashion, incorporating clinical referring expression natural language information, and generating high fidelity detections with map probabilities. Nevertheless, the challenging clinical nature of the radiologist annotations including subtle references, multi-instance specifications, and relatively verbose underlying medical reports, ensures the vision language detection task at scale remains stimulating for future investigation.