 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandom Projections for Adversarial Attack Detection
Paper and Code
Dec 11, 2020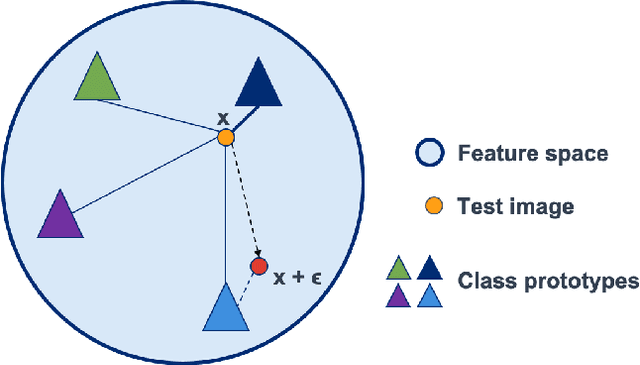
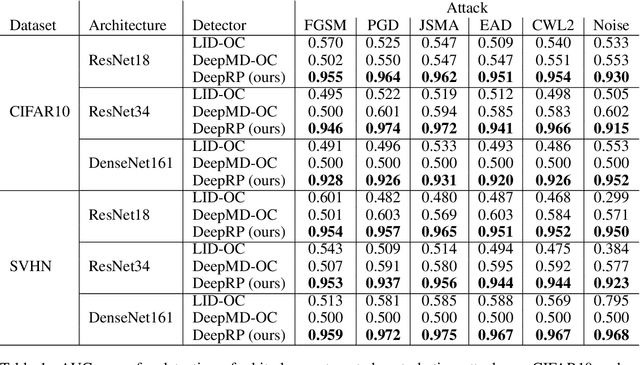
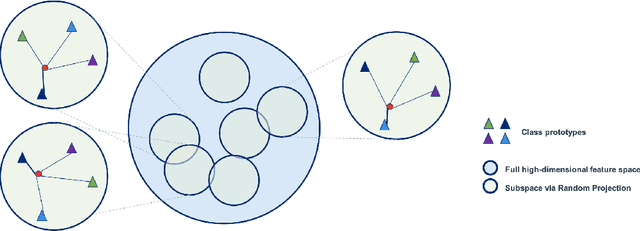
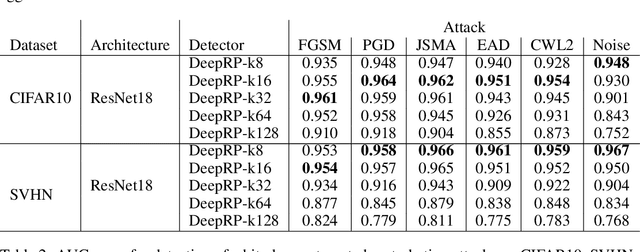
Whilst adversarial attack detection has received considerable attention, it remains a fundamentally challenging problem from two perspectives. First, while threat models can be well-defined, attacker strategies may still vary widely within those constraints. Therefore, detection should be considered as an open-set problem, standing in contrast to most current detection strategies. These methods take a closed-set view and train binary detectors, thus biasing detection toward attacks seen during detector training. Second, information is limited at test time and confounded by nuisance factors including the label and underlying content of the image. Many of the current high-performing techniques use training sets for dealing with some of these issues, but can be limited by the overall size and diversity of those sets during the detection step. We address these challenges via a novel strategy based on random subspace analysis. We present a technique that makes use of special properties of random projections, whereby we can characterize the behavior of clean and adversarial examples across a diverse set of subspaces. We then leverage the self-consistency (or inconsistency) of model activations to discern clean from adversarial examples. Performance evaluation demonstrates that our technique outperforms ($>0.92$ AUC) competing state of the art (SOTA) attack strategies, while remaining truly agnostic to the attack method itself. It also requires significantly less training data, composed only of clean examples, when compared to competing SOTA methods, which achieve only chance performance, when evaluated in a more rigorous testing scenario.