 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Meta-learning Convolutional Neural Architectures for Multi-target Concrete Defect Classification with the COncrete DEfect BRidge IMage Dataset
Apr 02, 2019

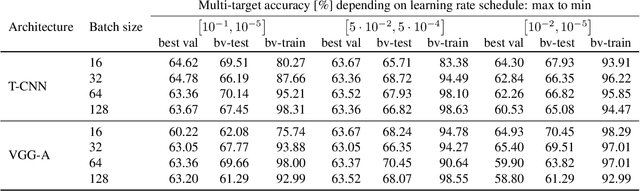
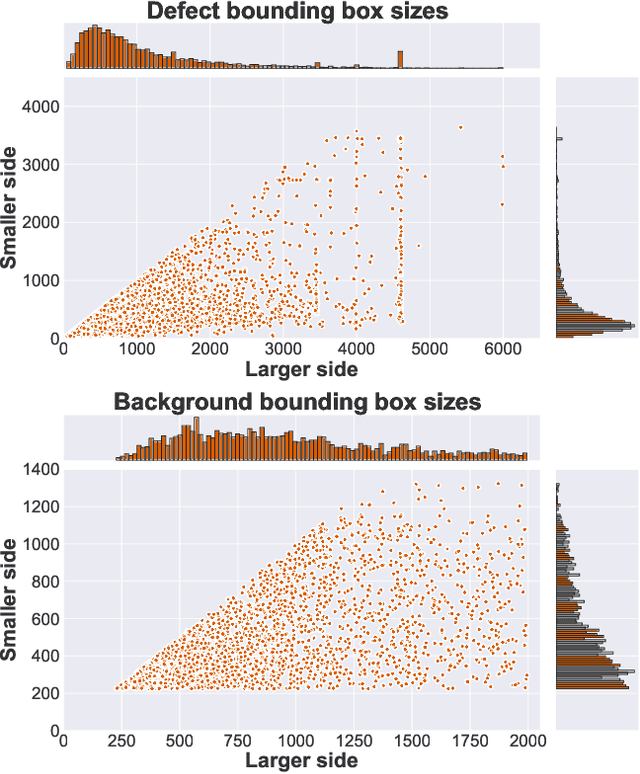
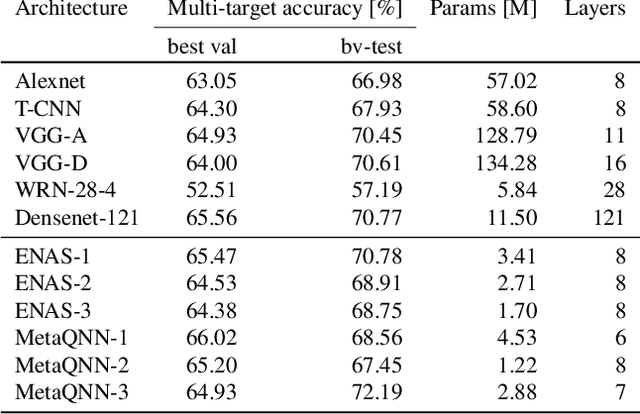
Recognition of defects in concrete infrastructure, especially in bridges, is a costly and time consuming crucial first step in the assessment of the structural integrity. Large variation in appearance of the concrete material, changing illumination and weather conditions, a variety of possible surface markings as well as the possibility for different types of defects to overlap, make it a challenging real-world task. In this work we introduce the novel COncrete DEfect BRidge IMage dataset (CODEBRIM) for multi-target classification of five commonly appearing concrete defects. We investigate and compare two reinforcement learning based meta-learning approaches, MetaQNN and efficient neural architecture search, to find suitable convolutional neural network architectures for this challenging multi-class multi-target task. We show that learned architectures have fewer overall parameters in addition to yielding better multi-target accuracy in comparison to popular neural architectures from the literature evaluated in the context of our application.
Are Gradient-based Saliency Maps Useful in Deep Reinforcement Learning?
Dec 02, 2020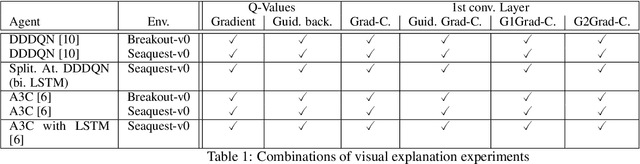


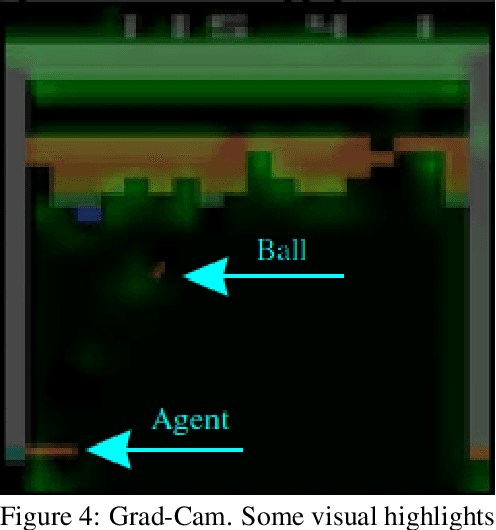
Deep Reinforcement Learning (DRL) connects the classic Reinforcement Learning algorithms with Deep Neural Networks. A problem in DRL is that CNNs are black-boxes and it is hard to understand the decision-making process of agents. In order to be able to use RL agents in highly dangerous environments for humans and machines, the developer needs a debugging tool to assure that the agent does what is expected. Currently, rewards are primarily used to interpret how well an agent is learning. However, this can lead to deceptive conclusions if the agent receives more rewards by memorizing a policy and not learning to respond to the environment. In this work, it is shown that this problem can be recognized with the help of gradient visualization techniques. This work brings some of the best-known visualization methods from the field of image classification to the area of Deep Reinforcement Learning. Furthermore, two new visualization techniques have been developed, one of which provides particularly good results. It is being proven to what extent the algorithms can be used in the area of Reinforcement learning. Also, the question arises on how well the DRL algorithms can be visualized across different environments with varying visualization techniques.
Matching-space Stereo Networks for Cross-domain Generalization
Oct 14, 2020
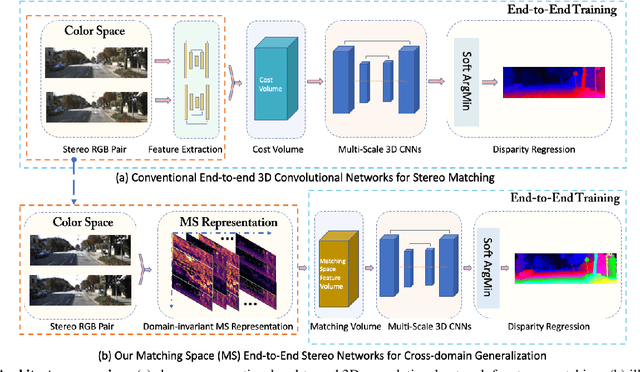

End-to-end deep networks represent the state of the art for stereo matching. While excelling on images framing environments similar to the training set, major drops in accuracy occur in unseen domains (e.g., when moving from synthetic to real scenes). In this paper we introduce a novel family of architectures, namely Matching-Space Networks (MS-Nets), with improved generalization properties. By replacing learning-based feature extraction from image RGB values with matching functions and confidence measures from conventional wisdom, we move the learning process from the color space to the Matching Space, avoiding over-specialization to domain specific features. Extensive experimental results on four real datasets highlight that our proposal leads to superior generalization to unseen environments over conventional deep architectures, keeping accuracy on the source domain almost unaltered. Our code is available at https://github.com/ccj5351/MS-Nets.
Joint Super-Resolution and Rectification for Solar Cell Inspection
Nov 10, 2020
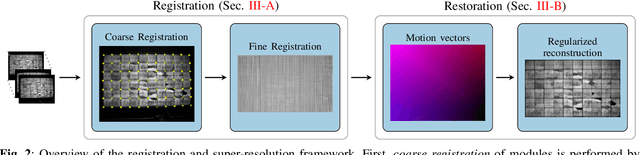
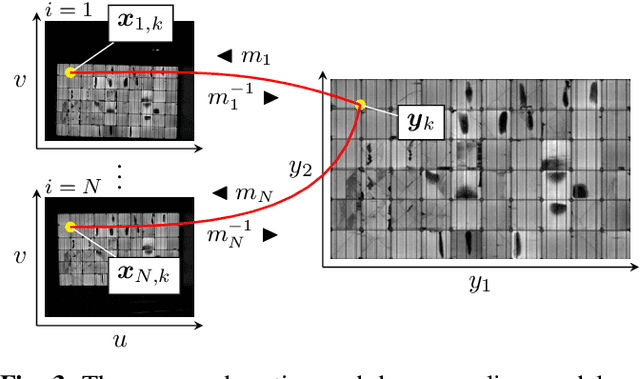

Visual inspection of solar modules is an important monitoring facility in photovoltaic power plants. Since a single measurement of fast CMOS sensors is limited in spatial resolution and often not sufficient to reliably detect small defects, we apply multi-frame super-resolution (MFSR) to a sequence of low resolution measurements. In addition, the rectification and removal of lens distortion simplifies subsequent analysis. Therefore, we propose to fuse this pre-processing with standard MFSR algorithms. This is advantageous, because we omit a separate processing step, the motion estimation becomes more stable and the spacing of high-resolution (HR) pixels on the rectified module image becomes uniform w.r.t. the module plane, regardless of perspective distortion. We present a comprehensive user study showing that MFSR is beneficial for defect recognition by human experts and that the proposed method performs better than the state of the art. Furthermore, we apply automated crack segmentation and show that the proposed method performs 3x better than bicubic upsampling and 2x better than the state of the art for automated inspection.
Removing Brightness Bias in Rectified Gradients
Nov 10, 2020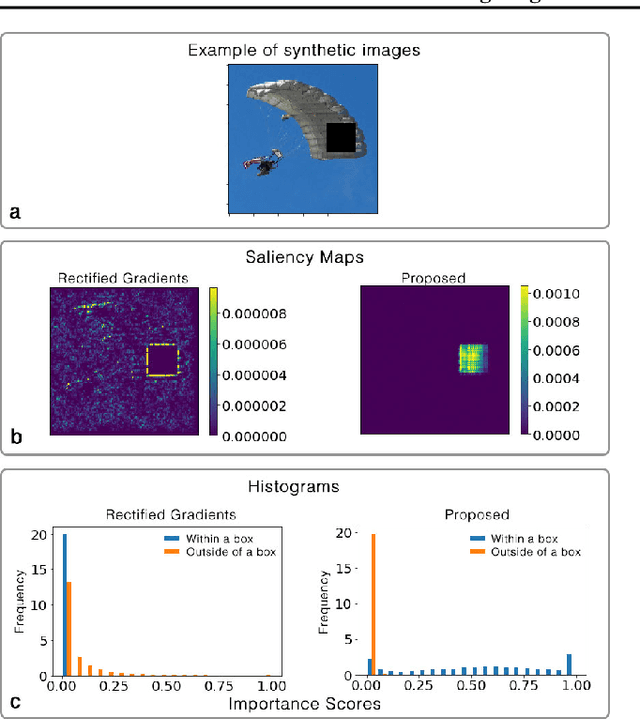
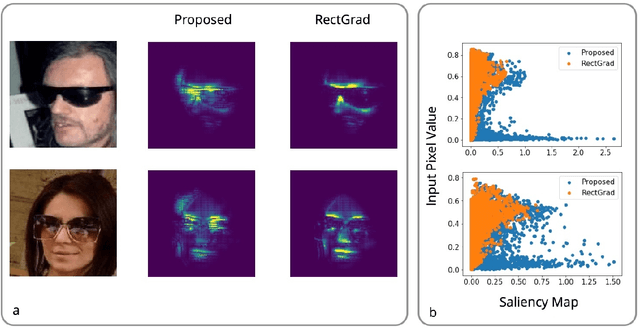
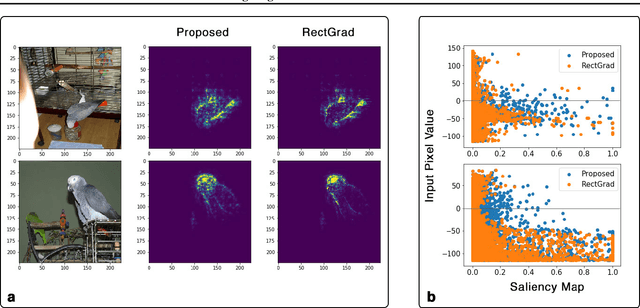
Interpretation and improvement of deep neural networks relies on better understanding of their underlying mechanisms. In particular, gradients of classes or concepts with respect to the input features (e.g., pixels in images) are often used as importance scores, which are visualized in saliency maps. Thus, a family of saliency methods provide an intuitive way to identify input features with substantial influences on classifications or latent concepts. Rectified Gradients \cite{Kim2019} is a new method which introduce layer-wise thresholding in order to denoise the saliency maps. While visually coherent in certain cases, we identify a brightness bias in Rectified Gradients. We demonstrate that dark areas of an input image are not highlighted by a saliency map using Rectified Gradients, even if it is relevant for the class or concept. Even in the scaled images, the bias exists around an artificial point in color spectrum. Our simple modification removes this bias and recovers input features that were removed due to their colors. "No Bias Rectified Gradient" is available at \url{https://github.com/lenbrocki/NoBias-Rectified-Gradient}
Resist : Reconstruction of irises from templates
Jul 31, 2020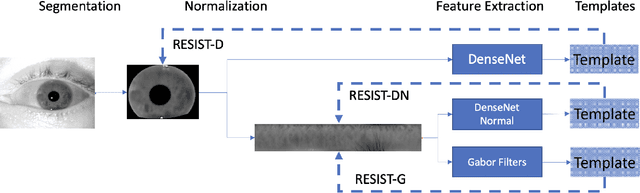

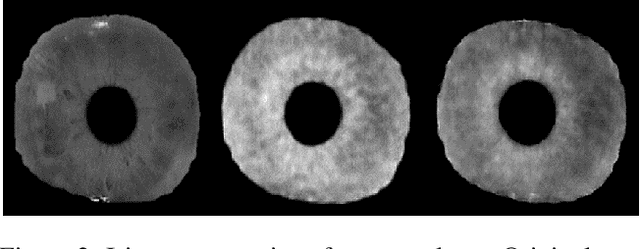
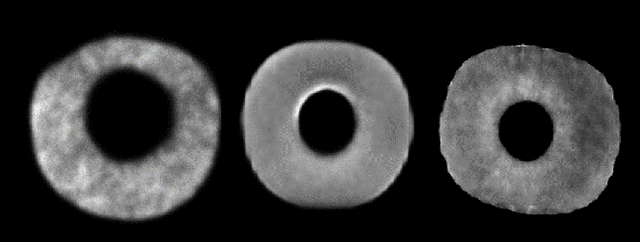
Iris recognition systems transform an iris image into a feature vector. The seminal pipeline segments an image into iris and non-iris pixels, normalizes this region into a fixed-dimension rectangle, and extracts features which are stored and called a template (Daugman, 2009). This template is stored on a system. A future reading of an iris can be transformed and compared against template vectors to determine or verify the identity of an individual. As templates are often stored together, they are a valuable target to an attacker. We show how to invert templates across a variety of iris recognition systems. Our inversion is based on a convolutional neural network architecture we call RESIST (REconStructing IriSes from Templates). We apply RESIST to a traditional Gabor filter pipeline, to a DenseNet (Huang et al., CVPR 2017) feature extractor, and to a DenseNet architecture that works without normalization. Both DenseNet feature extractors are based on the recent ThirdEye recognition system (Ahmad and Fuller, BTAS 2019). When training and testing using the ND-0405 dataset, reconstructed images demonstrate a rank-1 accuracy of 100%, 76%, and 96% respectively for the three pipelines. The core of our approach is similar to an autoencoder. To obtain high accuracy this core is integrated into an adversarial network (Goodfellow et al., NeurIPS, 2014)
Deep learning approaches in food recognition
Apr 08, 2020

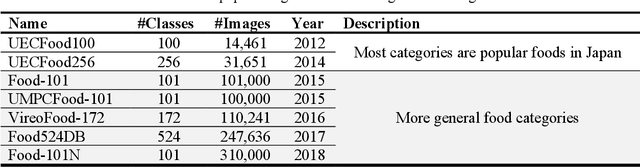
Automatic image-based food recognition is a particularly challenging task. Traditional image analysis approaches have achieved low classification accuracy in the past, whereas deep learning approaches enabled the identification of food types and their ingredients. The contents of food dishes are typically deformable objects, usually including complex semantics, which makes the task of defining their structure very difficult. Deep learning methods have already shown very promising results in such challenges, so this chapter focuses on the presentation of some popular approaches and techniques applied in image-based food recognition. The three main lines of solutions, namely the design from scratch, the transfer learning and the platform-based approaches, are outlined, particularly for the task at hand, and are tested and compared to reveal the inherent strengths and weaknesses. The chapter is complemented with basic background material, a section devoted to the relevant datasets that are crucial in light of the empirical approaches adopted, and some concluding remarks that underline the future directions.
Neural Codes for Image Retrieval
Jul 07, 2014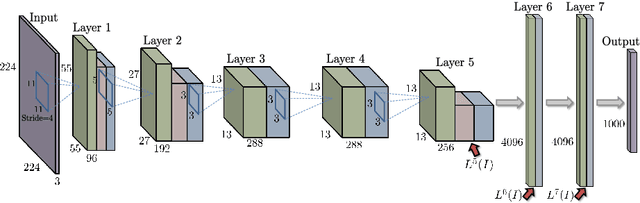
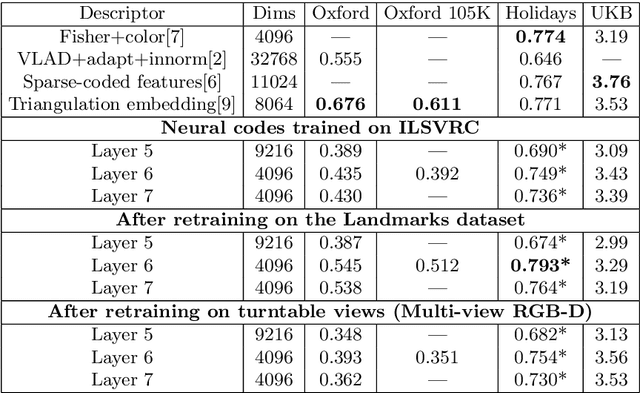

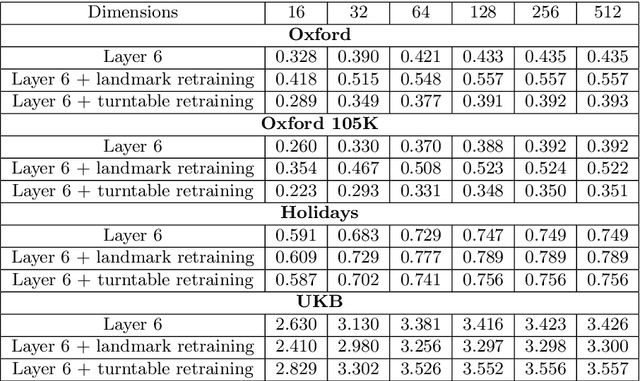
It has been shown that the activations invoked by an image within the top layers of a large convolutional neural network provide a high-level descriptor of the visual content of the image. In this paper, we investigate the use of such descriptors (neural codes) within the image retrieval application. In the experiments with several standard retrieval benchmarks, we establish that neural codes perform competitively even when the convolutional neural network has been trained for an unrelated classification task (e.g.\ Image-Net). We also evaluate the improvement in the retrieval performance of neural codes, when the network is retrained on a dataset of images that are similar to images encountered at test time. We further evaluate the performance of the compressed neural codes and show that a simple PCA compression provides very good short codes that give state-of-the-art accuracy on a number of datasets. In general, neural codes turn out to be much more resilient to such compression in comparison other state-of-the-art descriptors. Finally, we show that discriminative dimensionality reduction trained on a dataset of pairs of matched photographs improves the performance of PCA-compressed neural codes even further. Overall, our quantitative experiments demonstrate the promise of neural codes as visual descriptors for image retrieval.
BiO-Net: Learning Recurrent Bi-directional Connections for Encoder-Decoder Architecture
Jul 06, 2020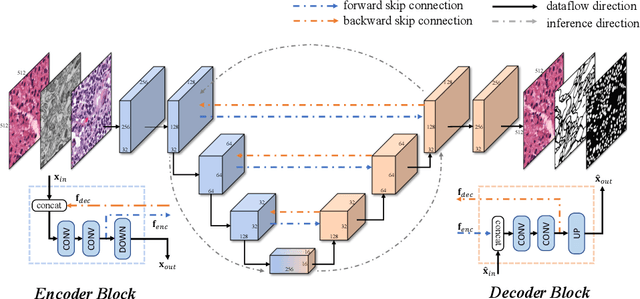


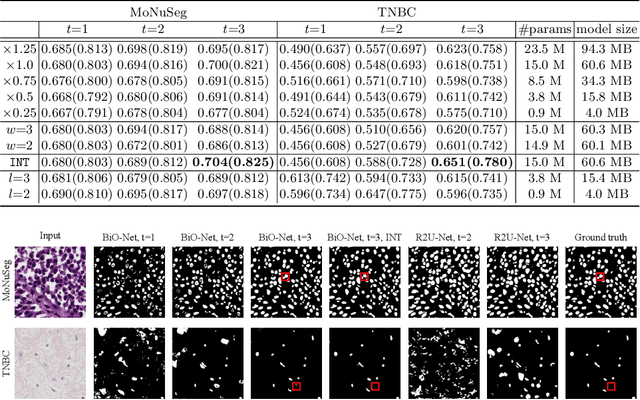
U-Net has become one of the state-of-the-art deep learning-based approaches for modern computer vision tasks such as semantic segmentation, super resolution, image denoising, and inpainting. Previous extensions of U-Net have focused mainly on the modification of its existing building blocks or the development of new functional modules for performance gains. As a result, these variants usually lead to an unneglectable increase in model complexity. To tackle this issue in such U-Net variants, in this paper, we present a novel Bi-directional O-shape network (BiO-Net) that reuses the building blocks in a recurrent manner without introducing any extra parameters. Our proposed bi-directional skip connections can be directly adopted into any encoder-decoder architecture to further enhance its capabilities in various task domains. We evaluated our method on various medical image analysis tasks and the results show that our BiO-Net significantly outperforms the vanilla U-Net as well as other state-of-the-art methods. Our code is available at https://github.com/tiangexiang/BiO-Net.
IamNN: Iterative and Adaptive Mobile Neural Network for Efficient Image Classification
Apr 26, 2018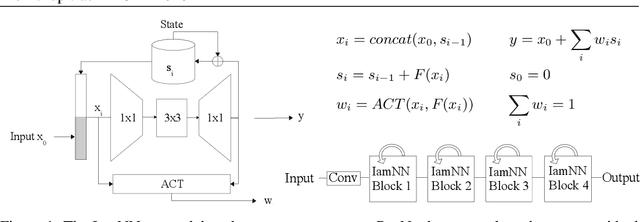
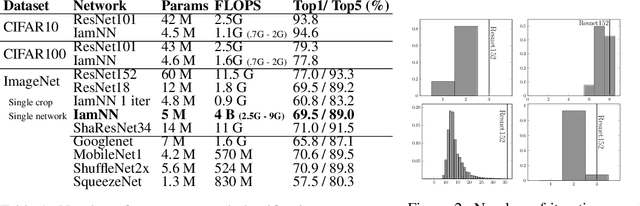

Deep residual networks (ResNets) made a recent breakthrough in deep learning. The core idea of ResNets is to have shortcut connections between layers that allow the network to be much deeper while still being easy to optimize avoiding vanishing gradients. These shortcut connections have interesting side-effects that make ResNets behave differently from other typical network architectures. In this work we use these properties to design a network based on a ResNet but with parameter sharing and with adaptive computation time. The resulting network is much smaller than the original network and can adapt the computational cost to the complexity of the input image.