 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Gleason Grading of Histology Prostate Images through Semantic Segmentation via Residual U-Net
May 22, 2020
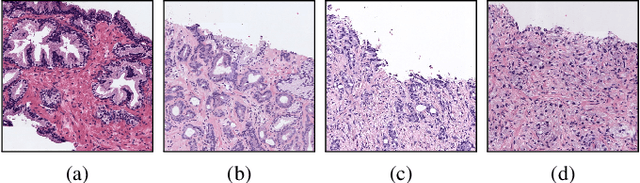
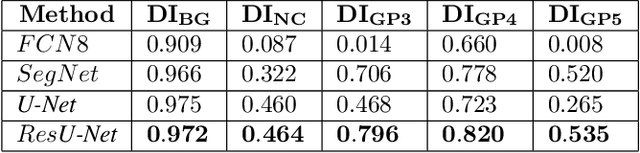
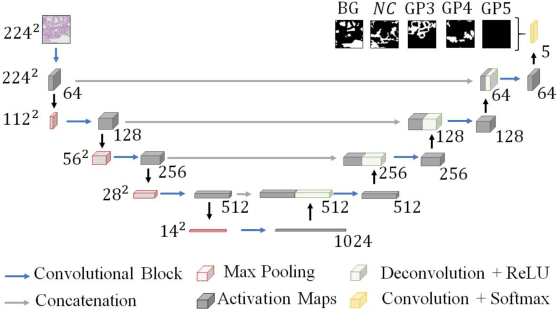
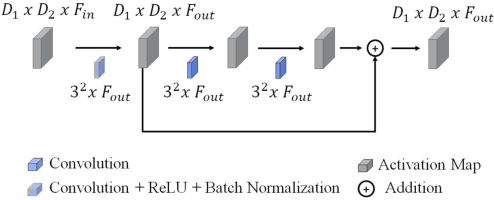
Worldwide, prostate cancer is one of the main cancers affecting men. The final diagnosis of prostate cancer is based on the visual detection of Gleason patterns in prostate biopsy by pathologists. Computer-aided-diagnosis systems allow to delineate and classify the cancerous patterns in the tissue via computer-vision algorithms in order to support the physicians' task. The methodological core of this work is a U-Net convolutional neural network for image segmentation modified with residual blocks able to segment cancerous tissue according to the full Gleason system. This model outperforms other well-known architectures, and reaches a pixel-level Cohen's quadratic Kappa of 0.52, at the level of previous image-level works in the literature, but providing also a detailed localisation of the patterns.
Auditing ImageNet: Towards a Model-driven Framework for Annotating Demographic Attributes of Large-Scale Image Datasets
May 03, 2019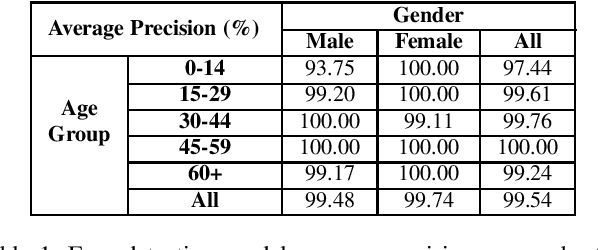
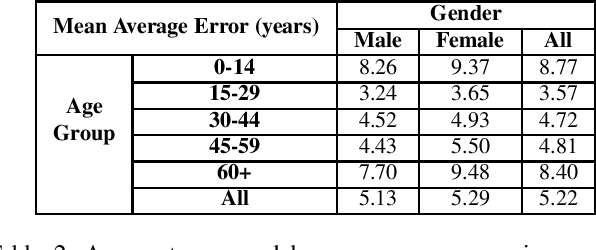
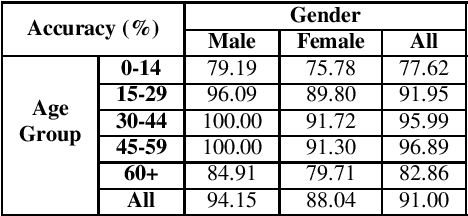
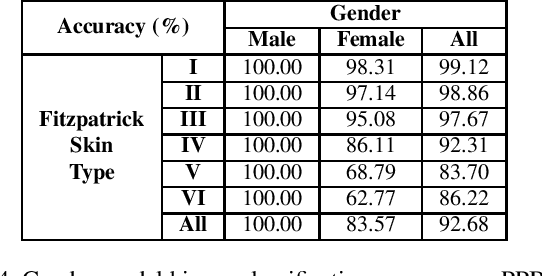
The ImageNet dataset ushered in a flood of academic and industry interest in leveraging deep learning for computer vision applications. Despite the significant impact of the dataset on the field, there has not been a comprehensive investigation into the demographic attributes of the images contained within this dataset. Such an investigation could lead to new insights on inherent biases deep within the dataset, which is particularly important given it is frequently used to pretrain models for a wide variety of computer vision tasks. In this study, we introduce a model-driven framework for the automatic annotation of apparent age and gender attributes in large-scale image datasets. Using this framework, we conduct a comprehensive demographic audit of the 2012 ImageNet Large Scale Visual Recognition Challenge (ILSVRC) subset of ImageNet and the 'person' hierarchical category of ImageNet by studying the resulting annotations. We find that 41.62% of faces in ILSVRC appear as female, 1.71% appear as individuals above the age of 60, and males aged 15 to 29 account for the largest subgroup, at 27.11%. Such significant imbalances in the apparent demographics of ImageNet are important to identify so the indirect effects of such biases can be better studied. Code and annotations for this work are available at: http://bit.ly/ImageNetDemoAudit
Fast Mixing of Multi-Scale Langevin Dynamics under the Manifold Hypothesis
Jun 22, 2020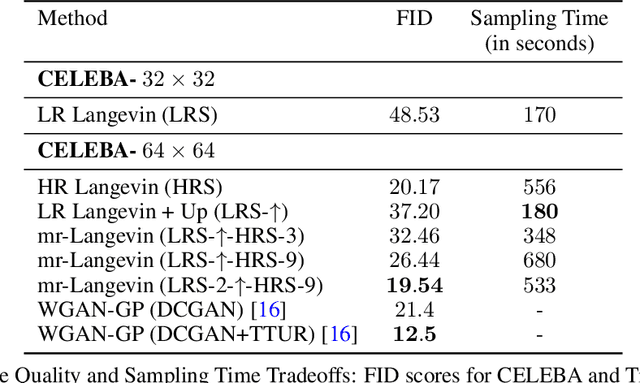

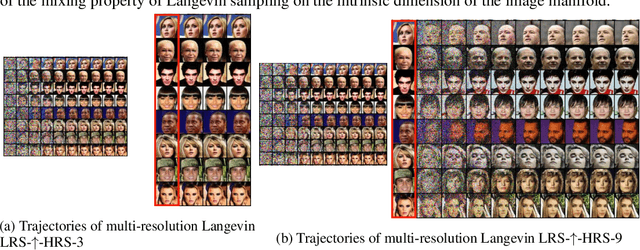
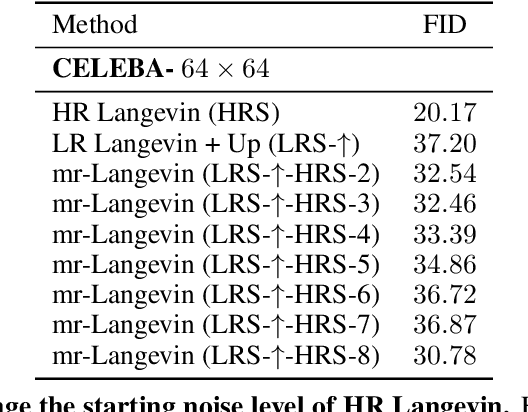
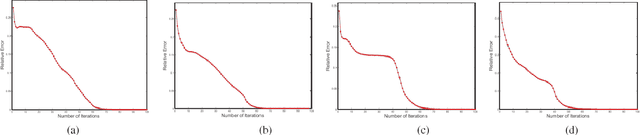
Recently, the task of image generation has attracted much attention. In particular, the recent empirical successes of the Markov Chain Monte Carlo (MCMC) technique of Langevin Dynamics have prompted a number of theoretical advances; despite this, several outstanding problems remain. First, the Langevin Dynamics is run in very high dimension on a nonconvex landscape; in the worst case, due to the NP-hardness of nonconvex optimization, it is thought that Langevin Dynamics mixes only in time exponential in the dimension. In this work, we demonstrate how the manifold hypothesis allows for the considerable reduction of mixing time, from exponential in the ambient dimension to depending only on the (much smaller) intrinsic dimension of the data. Second, the high dimension of the sampling space significantly hurts the performance of Langevin Dynamics; we leverage a multi-scale approach to help ameliorate this issue and observe that this multi-resolution algorithm allows for a trade-off between image quality and computational expense in generation.
Discriminative Block-Diagonal Representation Learning for Image Recognition
Jul 12, 2017
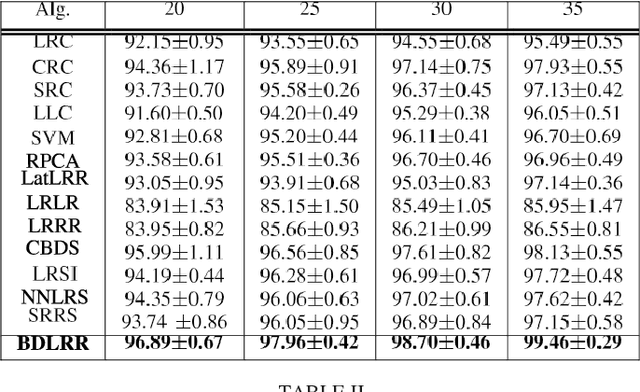
Existing block-diagonal representation researches mainly focuses on casting block-diagonal regularization on training data, while only little attention is dedicated to concurrently learning both block-diagonal representations of training and test data. In this paper, we propose a discriminative block-diagonal low-rank representation (BDLRR) method for recognition. In particular, the elaborate BDLRR is formulated as a joint optimization problem of shrinking the unfavorable representation from off-block-diagonal elements and strengthening the compact block-diagonal representation under the semi-supervised framework of low-rank representation. To this end, we first impose penalty constraints on the negative representation to eliminate the correlation between different classes such that the incoherence criterion of the extra-class representation is boosted. Moreover, a constructed subspace model is developed to enhance the self-expressive power of training samples and further build the representation bridge between the training and test samples, such that the coherence of the learned intra-class representation is consistently heightened. Finally, the resulting optimization problem is solved elegantly by employing an alternative optimization strategy, and a simple recognition algorithm on the learned representation is utilized for final prediction. Extensive experimental results demonstrate that the proposed method achieves superb recognition results on four face image datasets, three character datasets, and the fifteen scene multi-categories dataset. It not only shows superior potential on image recognition but also outperforms state-of-the-art methods.
Applying a random projection algorithm to optimize machine learning model for predicting peritoneal metastasis in gastric cancer patients using CT images
Sep 01, 2020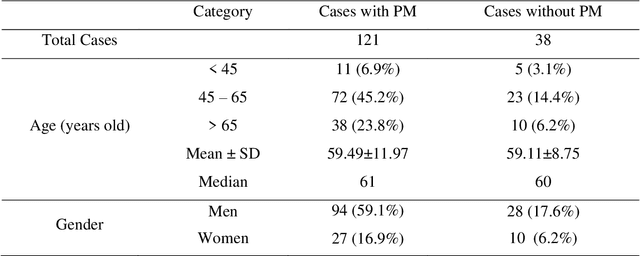
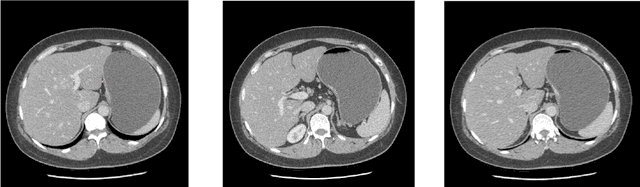

Background and Objective: Non-invasively predicting the risk of cancer metastasis before surgery plays an essential role in determining optimal treatment methods for cancer patients (including who can benefit from neoadjuvant chemotherapy). Although developing radiomics based machine learning (ML) models has attracted broad research interest for this purpose, it often faces a challenge of how to build a highly performed and robust ML model using small and imbalanced image datasets. Methods: In this study, we explore a new approach to build an optimal ML model. A retrospective dataset involving abdominal computed tomography (CT) images acquired from 159 patients diagnosed with gastric cancer is assembled. Among them, 121 cases have peritoneal metastasis (PM), while 38 cases do not have PM. A computer-aided detection (CAD) scheme is first applied to segment primary gastric tumor volumes and initially computes 315 image features. Then, two Gradient Boosting Machine (GBM) models embedded with two different feature dimensionality reduction methods, namely, the principal component analysis (PCA) and a random projection algorithm (RPA) and a synthetic minority oversampling technique, are built to predict the risk of the patients having PM. All GBM models are trained and tested using a leave-one-case-out cross-validation method. Results: Results show that the GBM embedded with RPA yielded a significantly higher prediction accuracy (71.2%) than using PCA (65.2%) (p<0.05). Conclusions: The study demonstrated that CT images of the primary gastric tumors contain discriminatory information to predict the risk of PM, and RPA is a promising method to generate optimal feature vector, improving the performance of ML models of medical images.
Tensor-based algorithms for image classification
Oct 04, 2019

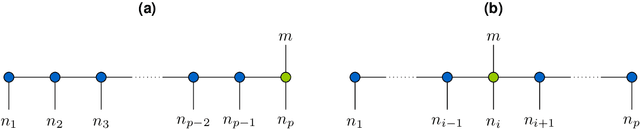
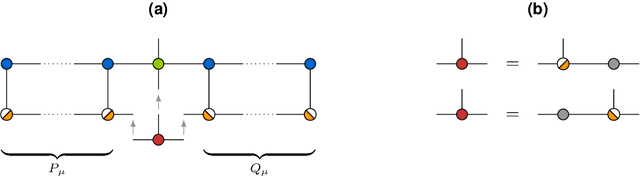
The interest in machine learning with tensor networks has been growing rapidly in recent years. The goal is to exploit tensor-structured basis functions in order to generate exponentially large feature spaces which are then used for supervised learning. We will propose two different tensor approaches for quantum-inspired machine learning. One is a kernel-based reformulation of the previously introduced MANDy, the other an alternating ridge regression in the tensor-train format. We will apply both methods to the MNIST and fashion MNIST data set and compare the results with state-of-the-art neural network-based classifiers.
Single image super-resolution by approximated Heaviside functions
Mar 12, 2015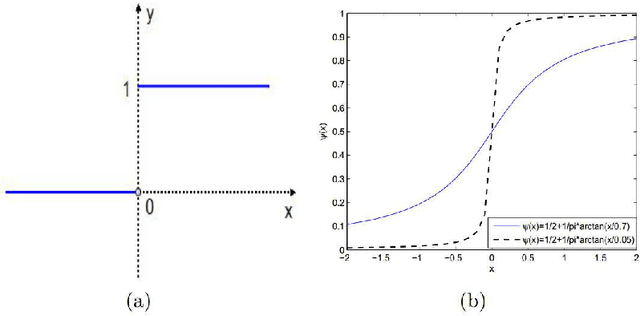
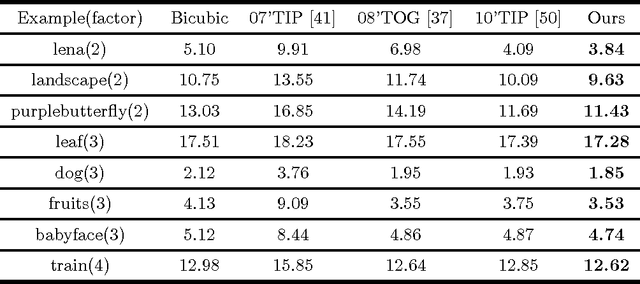
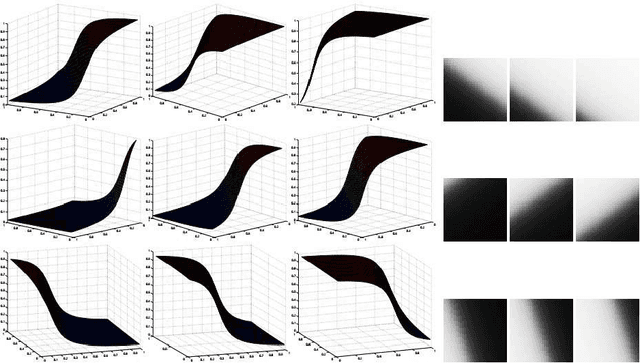
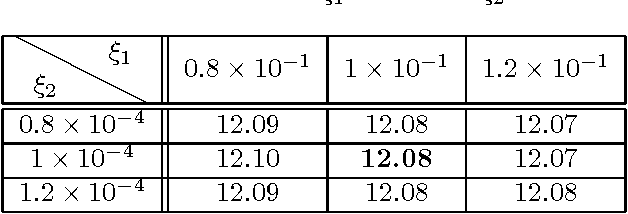
Image super-resolution is a process to enhance image resolution. It is widely used in medical imaging, satellite imaging, target recognition, etc. In this paper, we conduct continuous modeling and assume that the unknown image intensity function is defined on a continuous domain and belongs to a space with a redundant basis. We propose a new iterative model for single image super-resolution based on an observation: an image is consisted of smooth components and non-smooth components, and we use two classes of approximated Heaviside functions (AHFs) to represent them respectively. Due to sparsity of the non-smooth components, a $L_{1}$ model is employed. In addition, we apply the proposed iterative model to image patches to reduce computation and storage. Comparisons with some existing competitive methods show the effectiveness of the proposed method.
GUN: Gradual Upsampling Network for Single Image Super-Resolution
Jul 04, 2018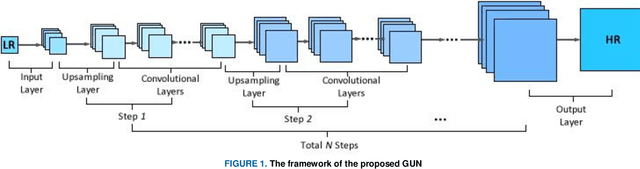

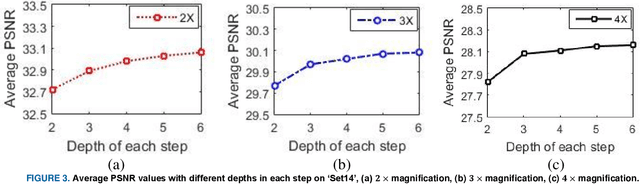
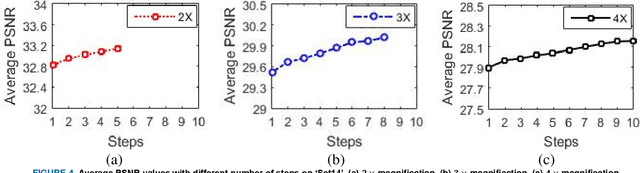
In this paper, an efficient super-resolution (SR) method based on deep convolutional neural network (CNN) is proposed, namely Gradual Upsampling Network (GUN). Recent CNN based SR methods often preliminarily magnify the low resolution (LR) input to high resolution (HR) and then reconstruct the HR input, or directly reconstruct the LR input and then recover the HR result at the last layer. The proposed GUN utilizes a gradual process instead of these two commonly used frameworks. The GUN consists of an input layer, multiple upsampling and convolutional layers, and an output layer. By means of the gradual process, the proposed network can simplify the direct SR problem to multistep easier upsampling tasks with very small magnification factor in each step. Furthermore, a gradual training strategy is presented for the GUN. In the proposed training process, an initial network can be easily trained with edge-like samples, and then the weights are gradually tuned with more complex samples. The GUN can recover fine and vivid results, and is easy to be trained. The experimental results on several image sets demonstrate the effectiveness of the proposed network.
From a Fourier-Domain Perspective on Adversarial Examples to a Wiener Filter Defense for Semantic Segmentation
Dec 02, 2020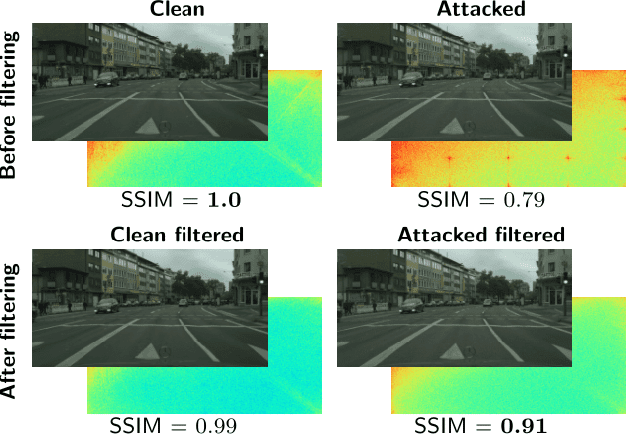
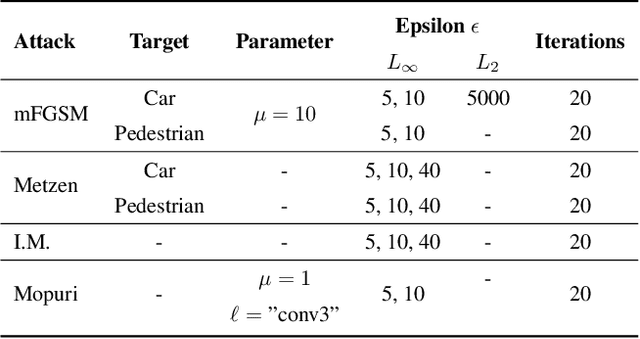
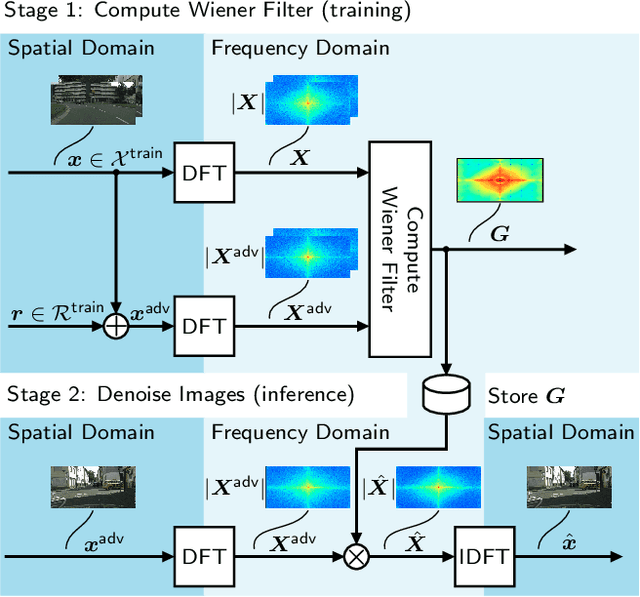
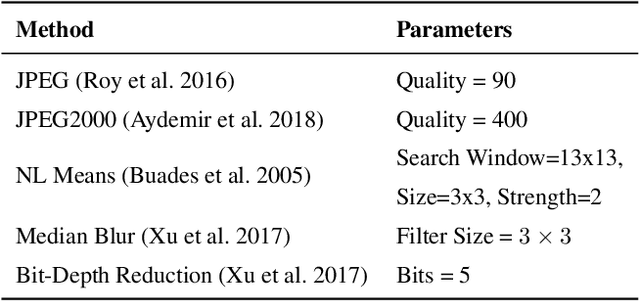
Despite recent advancements, deep neural networks are not robust against adversarial perturbations. Many of the proposed adversarial defense approaches use computationally expensive training mechanisms that do not scale to complex real-world tasks such as semantic segmentation, and offer only marginal improvements. In addition, fundamental questions on the nature of adversarial perturbations and their relation to the network architecture are largely understudied. In this work, we study the adversarial problem from a frequency domain perspective. More specifically, we analyze discrete Fourier transform (DFT) spectra of several adversarial images and report two major findings: First, there exists a strong connection between a model architecture and the nature of adversarial perturbations that can be observed and addressed in the frequency domain. Second, the observed frequency patterns are largely image- and attack-type independent, which is important for the practical impact of any defense making use of such patterns. Motivated by these findings, we additionally propose an adversarial defense method based on the well-known Wiener filters that captures and suppresses adversarial frequencies in a data-driven manner. Our proposed method not only generalizes across unseen attacks but also beats five existing state-of-the-art methods across two models in a variety of attack settings.
Universal Weighting Metric Learning for Cross-Modal Matching
Oct 07, 2020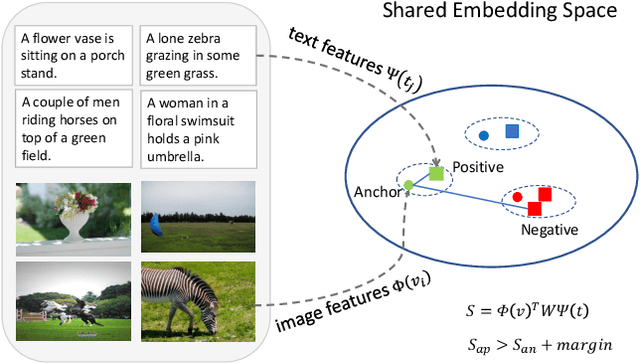
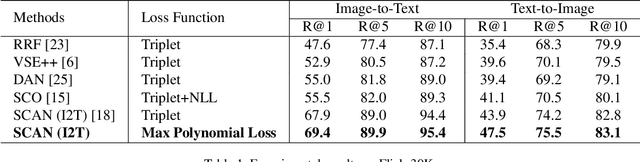
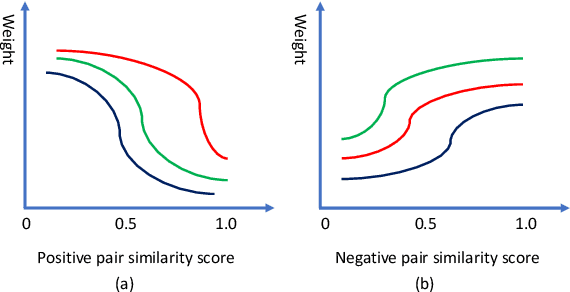
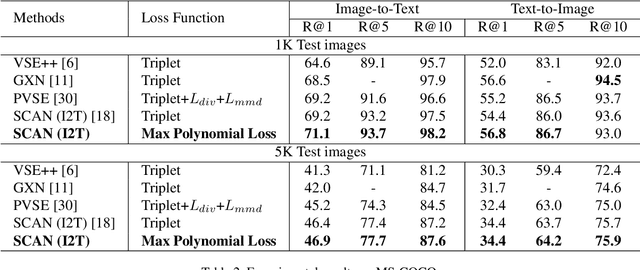
Cross-modal matching has been a highlighted research topic in both vision and language areas. Learning appropriate mining strategy to sample and weight informative pairs is crucial for the cross-modal matching performance. However, most existing metric learning methods are developed for unimodal matching, which is unsuitable for cross-modal matching on multimodal data with heterogeneous features. To address this problem, we propose a simple and interpretable universal weighting framework for cross-modal matching, which provides a tool to analyze the interpretability of various loss functions. Furthermore, we introduce a new polynomial loss under the universal weighting framework, which defines a weight function for the positive and negative informative pairs respectively. Experimental results on two image-text matching benchmarks and two video-text matching benchmarks validate the efficacy of the proposed method.