 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Self-Committee Approach for Image Restoration Problems using Convolutional Neural Network
Jun 12, 2017
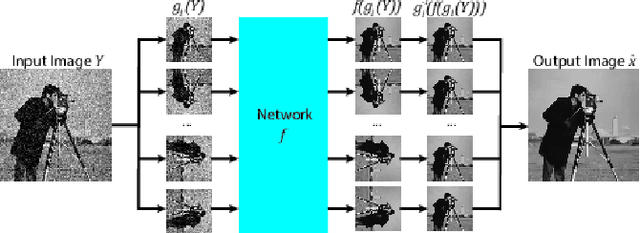

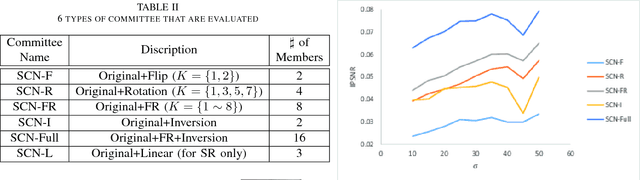

There have been many discriminative learning methods using convolutional neural networks (CNN) for several image restoration problems, which learn the mapping function from a degraded input to the clean output. In this letter, we propose a self-committee method that can find enhanced restoration results from the multiple trial of a trained CNN with different but related inputs. Specifically, it is noted that the CNN sometimes finds different mapping functions when the input is transformed by a reversible transform and thus produces different but related outputs with the original. Hence averaging the outputs for several different transformed inputs can enhance the results as evidenced by the network committee methods. Unlike the conventional committee approaches that require several networks, the proposed method needs only a single network. Experimental results show that adding an additional transform as a committee always brings additional gain on image denoising and single image supre-resolution problems.
Camera Model Anonymisation with Augmented cGANs
Feb 18, 2020
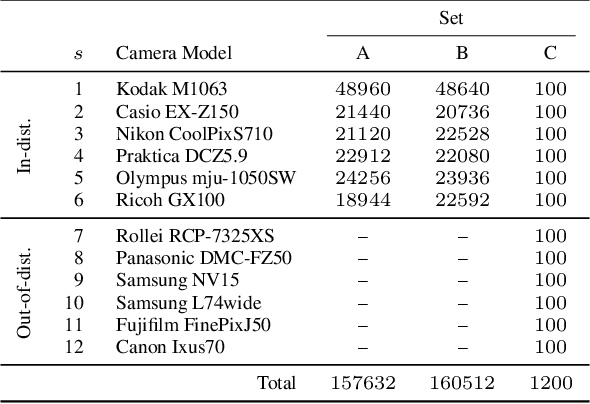
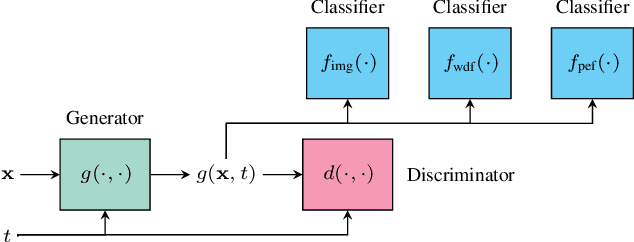
The model of camera that was used to capture a particular photographic image (model attribution) can be inferred from model-specific artefacts present within the image. Typically these artefacts are found in high-frequency pixel patterns, rather than image content. Model anonymisation is the process of transforming these artefacts such that the apparent capture model is changed. Improved methods for attribution and anonymisation are important for improving digital forensics, and understanding its limits. Through conditional adversarial training, we present an approach for learning these transformations. Significantly, we augment the objective with the losses from pre-trained auxiliary model attribution classifiers that constrain the generator to not only synthesise discriminative high-frequency artefacts, but also salient image-based artefacts lost during image content suppression. Quantitative comparisons against a recent representative approach demonstrate the efficacy of our framework in a non-interactive black-box setting.
A Generalization of Otsu's Method and Minimum Error Thresholding
Jul 14, 2020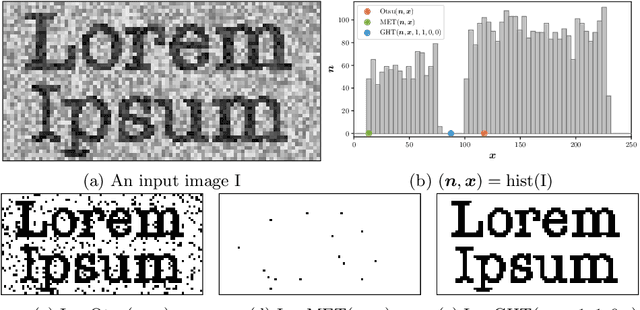
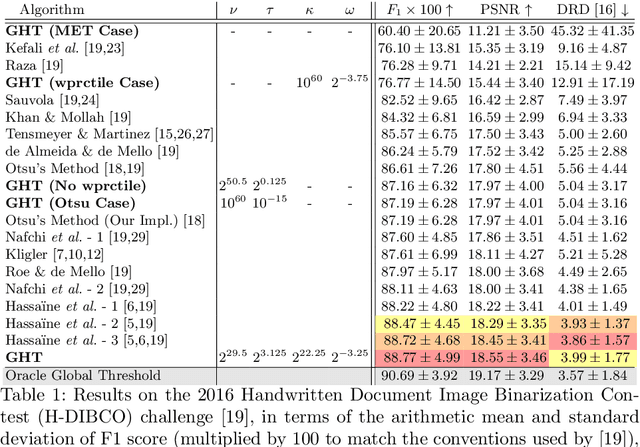
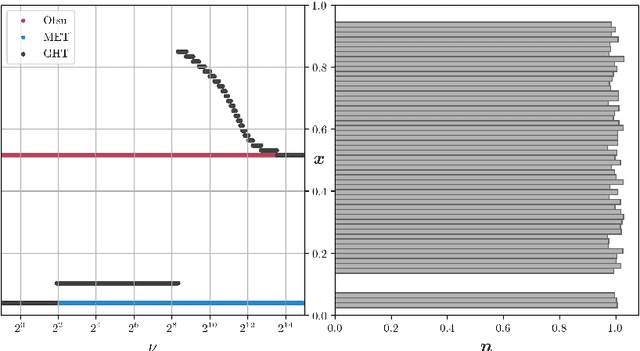
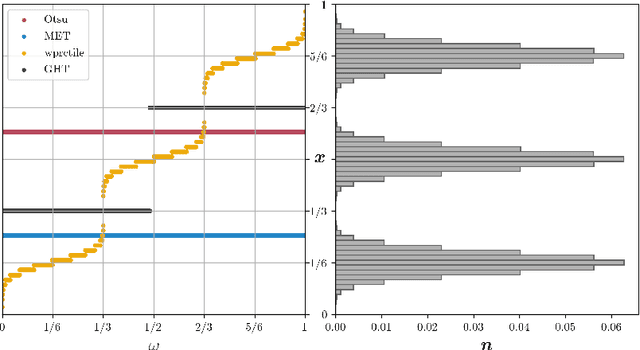
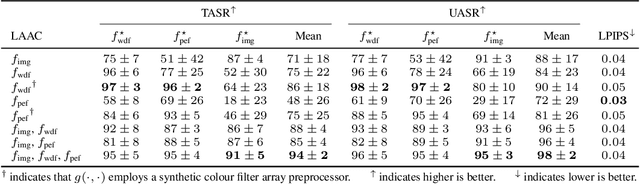
We present Generalized Histogram Thresholding (GHT), a simple, fast, and effective technique for histogram-based image thresholding. GHT works by performing approximate maximum a posteriori estimation of a mixture of Gaussians with appropriate priors. We demonstrate that GHT subsumes three classic thresholding techniques as special cases: Otsu's method, Minimum Error Thresholding (MET), and weighted percentile thresholding. GHT thereby enables the continuous interpolation between those three algorithms, which allows thresholding accuracy to be improved significantly. GHT also provides a clarifying interpretation of the common practice of coarsening a histogram's bin width during thresholding. We show that GHT outperforms or matches the performance of all algorithms on a recent challenge for handwritten document image binarization (including deep neural networks trained to produce per-pixel binarizations), and can be implemented in a dozen lines of code or as a trivial modification to Otsu's method or MET.
FPCC-Net: Fast Point Cloud Clustering for Instance Segmentation
Jan 19, 2021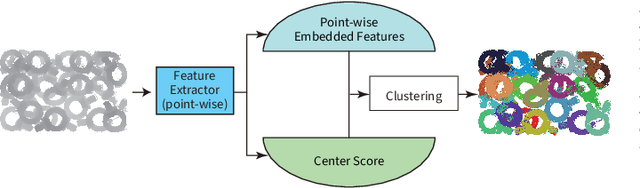

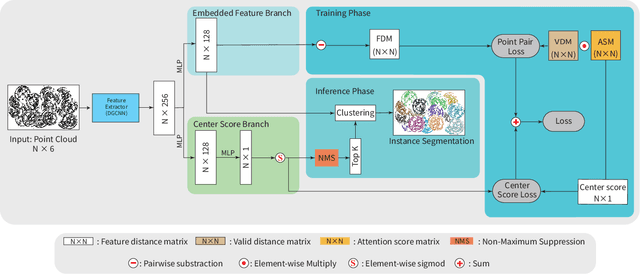
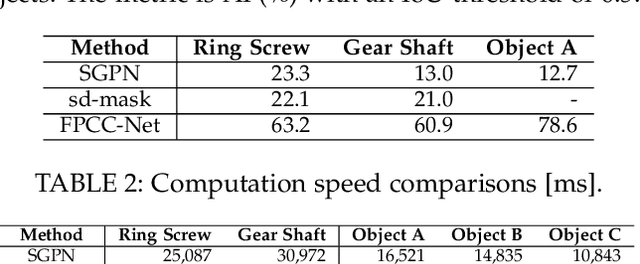
Instance segmentation is an important pre-processing task in numerous real-world applications, such as robotics, autonomous vehicles, and human-computer interaction. However, there has been little research on 3D point cloud instance segmentation of bin-picking scenes in which multiple objects of the same class are stacked together. Compared with the rapid development of deep learning for two-dimensional (2D) image tasks, deep learning-based 3D point cloud segmentation still has a lot of room for development. In such a situation, distinguishing a large number of occluded objects of the same class is a highly challenging problem. In a usual bin-picking scene, an object model is known and the number of object type is one. Thus, the semantic information can be ignored; instead, the focus is put on the segmentation of instances. Based on this task requirement, we propose a network (FPCC-Net) that infers feature centers of each instance and then clusters the remaining points to the closest feature center in feature embedding space. FPCC-Net includes two subnets, one for inferring the feature centers for clustering and the other for describing features of each point. The proposed method is compared with existing 3D point cloud and 2D segmentation methods in some bin-picking scenes. It is shown that FPCC-Net improves average precision (AP) by about 40\% than SGPN and can process about 60,000 points in about 0.8 [s].
Towards Musically Meaningful Explanations Using Source Separation
Sep 04, 2020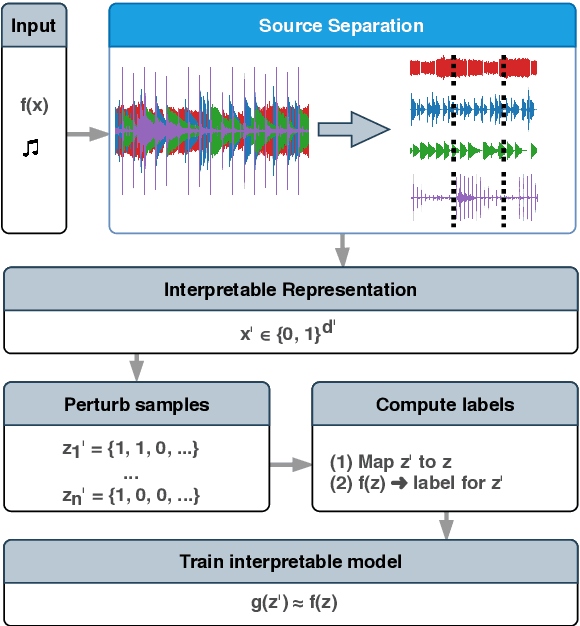


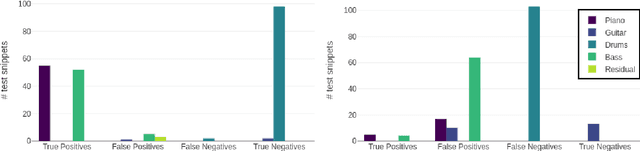
Deep neural networks (DNNs) are successfully applied in a wide variety of music information retrieval (MIR) tasks. Such models are usually considered "black boxes", meaning that their predictions are not interpretable. Prior work on explainable models in MIR has generally used image processing tools to produce explanations for DNN predictions, but these are not necessarily musically meaningful, or can be listened to (which, arguably, is important in music). We propose audioLIME, a method based on Local Interpretable Model-agnostic Explanation (LIME), extended by a musical definition of locality. LIME learns locally linear models on perturbations of an example that we want to explain. Instead of extracting components of the spectrogram using image segmentation as part of the LIME pipeline, we propose using source separation. The perturbations are created by switching on/off sources which makes our explanations listenable. We first validate audioLIME on a classifier that was deliberately trained to confuse the true target with a spurious signal, and show that this can easily be detected using our method. We then show that it passes a sanity check that many available explanation methods fail. Finally, we demonstrate the general applicability of our (model-agnostic) method on a third-party music tagger.
Image Segmentation to Distinguish Between Overlapping Human Chromosomes
Dec 20, 2017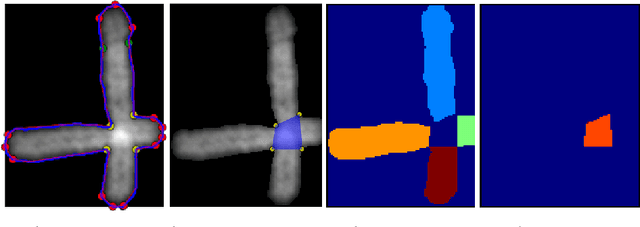
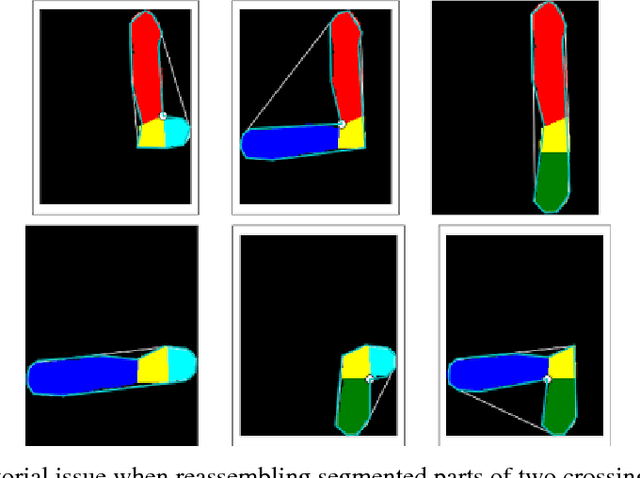
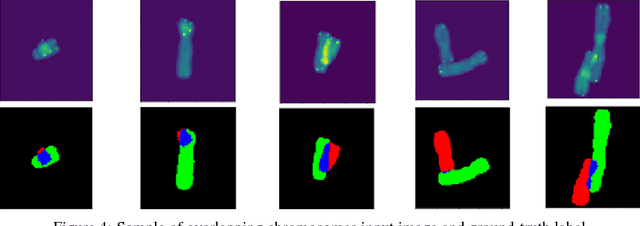
In medicine, visualizing chromosomes is important for medical diagnostics, drug development, and biomedical research. Unfortunately, chromosomes often overlap and it is necessary to identify and distinguish between the overlapping chromosomes. A segmentation solution that is fast and automated will enable scaling of cost effective medicine and biomedical research. We apply neural network-based image segmentation to the problem of distinguishing between partially overlapping DNA chromosomes. A convolutional neural network is customized for this problem. The results achieved intersection over union (IOU) scores of 94.7% for the overlapping region and 88-94% on the non-overlapping chromosome regions.
Semi-supervised few-shot learning for medical image segmentation
Mar 18, 2020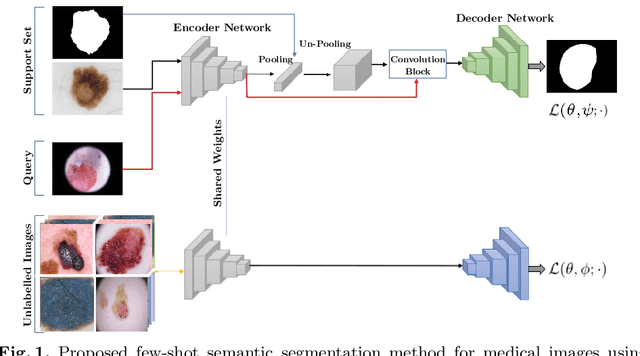
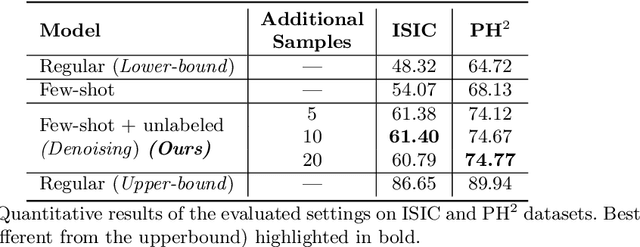


Recent years have witnessed the great progress of deep neural networks on semantic segmentation, particularly in medical imaging. Nevertheless, training high-performing models require large amounts of pixel-level ground truth masks, which can be prohibitive to obtain in the medical domain. Furthermore, training such models in a low-data regime highly increases the risk of overfitting. Recent attempts to alleviate the need for large annotated datasets have developed training strategies under the few-shot learning paradigm, which addresses this shortcoming by learning a novel class from only a few labeled examples. In this context, a segmentation model is trained on episodes, which represent different segmentation problems, each of them trained with a very small labeled dataset. In this work, we propose a novel few-shot learning framework for semantic segmentation, where unlabeled images are also made available at each episode. To handle this new learning paradigm, we propose to include surrogate tasks that can leverage very powerful supervisory signals --derived from the data itself-- for semantic feature learning. We show that including unlabeled surrogate tasks in the episodic training leads to more powerful feature representations, which ultimately results in better generability to unseen tasks. We demonstrate the efficiency of our method in the task of skin lesion segmentation in two publicly available datasets. Furthermore, our approach is general and model-agnostic, which can be combined with different deep architectures.
Recent Progress in Image Deblurring
Sep 24, 2014



This paper comprehensively reviews the recent development of image deblurring, including non-blind/blind, spatially invariant/variant deblurring techniques. Indeed, these techniques share the same objective of inferring a latent sharp image from one or several corresponding blurry images, while the blind deblurring techniques are also required to derive an accurate blur kernel. Considering the critical role of image restoration in modern imaging systems to provide high-quality images under complex environments such as motion, undesirable lighting conditions, and imperfect system components, image deblurring has attracted growing attention in recent years. From the viewpoint of how to handle the ill-posedness which is a crucial issue in deblurring tasks, existing methods can be grouped into five categories: Bayesian inference framework, variational methods, sparse representation-based methods, homography-based modeling, and region-based methods. In spite of achieving a certain level of development, image deblurring, especially the blind case, is limited in its success by complex application conditions which make the blur kernel hard to obtain and be spatially variant. We provide a holistic understanding and deep insight into image deblurring in this review. An analysis of the empirical evidence for representative methods, practical issues, as well as a discussion of promising future directions are also presented.
When Radiology Report Generation Meets Knowledge Graph
Feb 19, 2020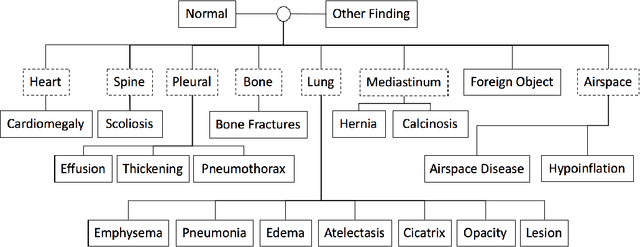
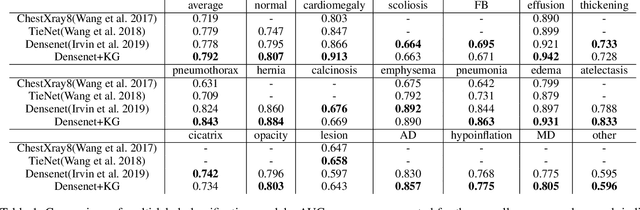
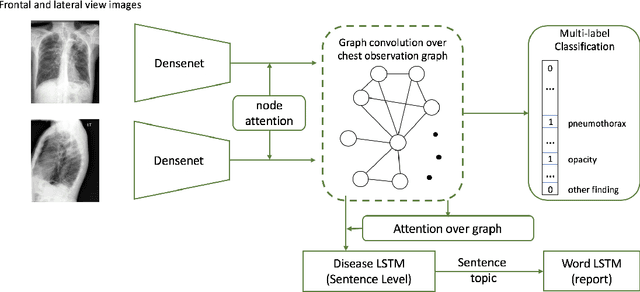
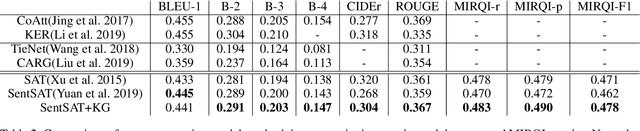
Automatic radiology report generation has been an attracting research problem towards computer-aided diagnosis to alleviate the workload of doctors in recent years. Deep learning techniques for natural image captioning are successfully adapted to generating radiology reports. However, radiology image reporting is different from the natural image captioning task in two aspects: 1) the accuracy of positive disease keyword mentions is critical in radiology image reporting in comparison to the equivalent importance of every single word in a natural image caption; 2) the evaluation of reporting quality should focus more on matching the disease keywords and their associated attributes instead of counting the occurrence of N-gram. Based on these concerns, we propose to utilize a pre-constructed graph embedding module (modeled with a graph convolutional neural network) on multiple disease findings to assist the generation of reports in this work. The incorporation of knowledge graph allows for dedicated feature learning for each disease finding and the relationship modeling between them. In addition, we proposed a new evaluation metric for radiology image reporting with the assistance of the same composed graph. Experimental results demonstrate the superior performance of the methods integrated with the proposed graph embedding module on a publicly accessible dataset (IU-RR) of chest radiographs compared with previous approaches using both the conventional evaluation metrics commonly adopted for image captioning and our proposed ones.
Deep Learning Based Brain Tumor Segmentation: A Survey
Jul 21, 2020
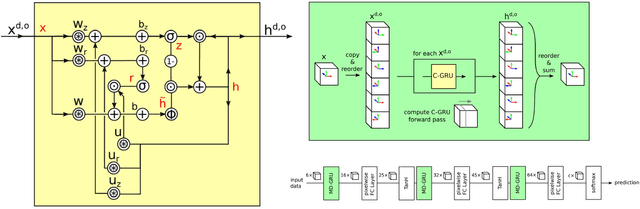
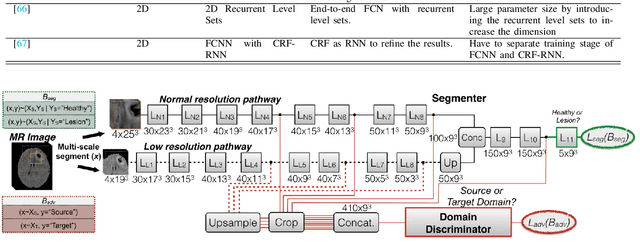
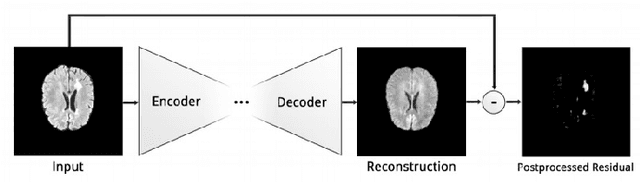
Brain tumor segmentation is a challenging problem in medical image analysis. The goal of brain tumor segmentation is to generate accurate delineation of brain tumor regions with correctly located masks. In recent years, deep learning methods have shown very promising performance in solving various computer vision problems, such as image classification, object detection and semantic segmentation. A number of deep learning based methods have been applied to brain tumor segmentation and achieved impressive system performance. Considering state-of-the-art technologies and their performance, the purpose of this paper is to provide a comprehensive survey of recently developed deep learning based brain tumor segmentation techniques. The established works included in this survey extensively cover technical aspects such as the strengths and weaknesses of different approaches, pre- and post-processing frameworks, datasets and evaluation metrics. Finally, we conclude this survey by discussing the potential development in future research work.