 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Multi-head Knowledge Distillation for Model Compression
Dec 05, 2020
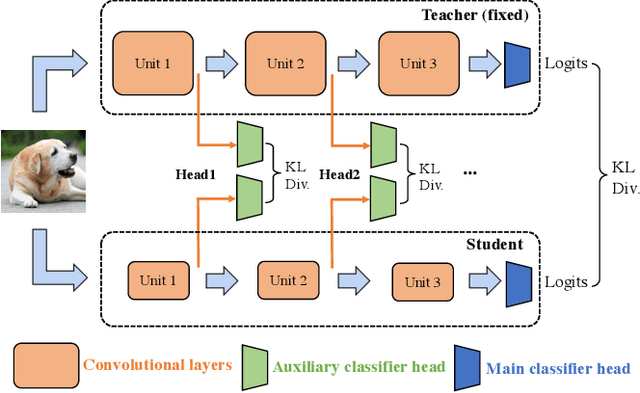
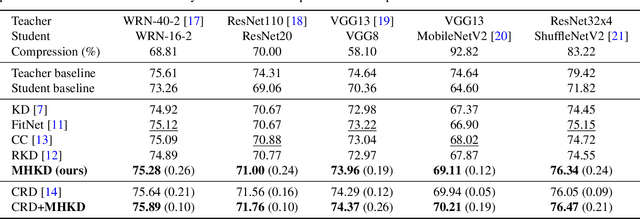

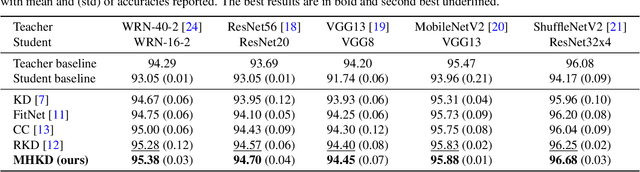
Several methods of knowledge distillation have been developed for neural network compression. While they all use the KL divergence loss to align the soft outputs of the student model more closely with that of the teacher, the various methods differ in how the intermediate features of the student are encouraged to match those of the teacher. In this paper, we propose a simple-to-implement method using auxiliary classifiers at intermediate layers for matching features, which we refer to as multi-head knowledge distillation (MHKD). We add loss terms for training the student that measure the dissimilarity between student and teacher outputs of the auxiliary classifiers. At the same time, the proposed method also provides a natural way to measure differences at the intermediate layers even though the dimensions of the internal teacher and student features may be different. Through several experiments in image classification on multiple datasets we show that the proposed method outperforms prior relevant approaches presented in the literature.
Revisiting Pre-training: An Efficient Training Method for Image Classification
Nov 23, 2018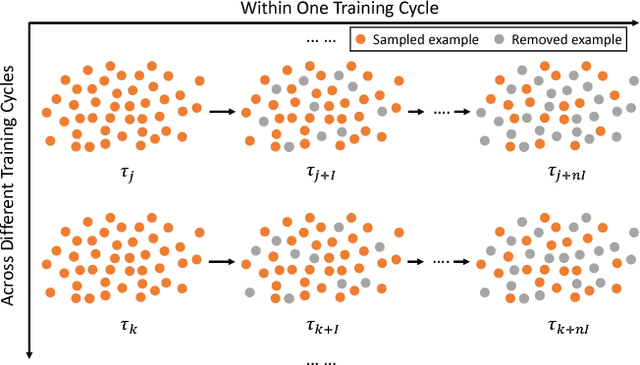

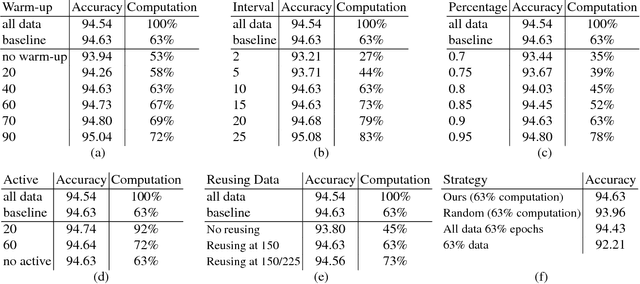

The training method of repetitively feeding all samples into a pre-defined network for image classification has been widely adopted by current state-of-the-art. In this work, we provide a new method, which can be leveraged to train classification networks in a more efficient way. Starting with a warm-up step, we propose to continually repeat a Drop-and-Pick (DaP) learning strategy. In particular, we drop those easy samples to encourage the network to focus on studying hard ones. Meanwhile, by picking up all samples periodically during training, we aim to recall the memory of the networks to prevent catastrophic forgetting of previously learned knowledge. Our DaP learning method can recover 99.88%, 99.60%, 99.83% top-1 accuracy on ImageNet for ResNet-50, DenseNet-121, and MobileNet-V1 but only requires 75% computation in training compared to those using the classic training schedule. Furthermore, our pre-trained models are equipped with strong knowledge transferability when used for downstream tasks, especially for hard cases. Extensive experiments on object detection, instance segmentation and pose estimation can well demonstrate the effectiveness of our DaP training method.
Tensor Alignment Based Domain Adaptation for Hyperspectral Image Classification
Sep 04, 2018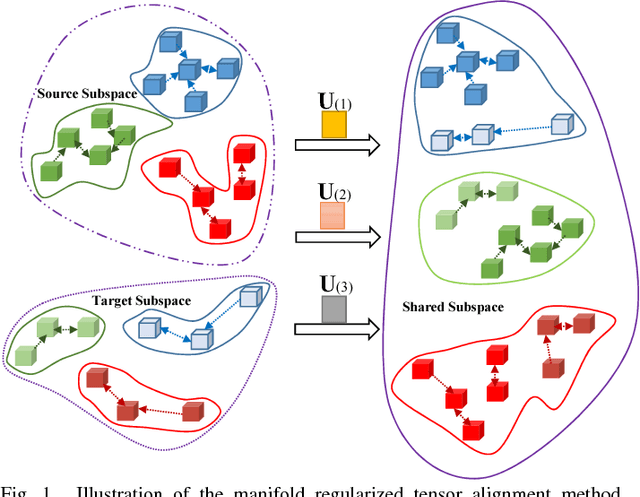
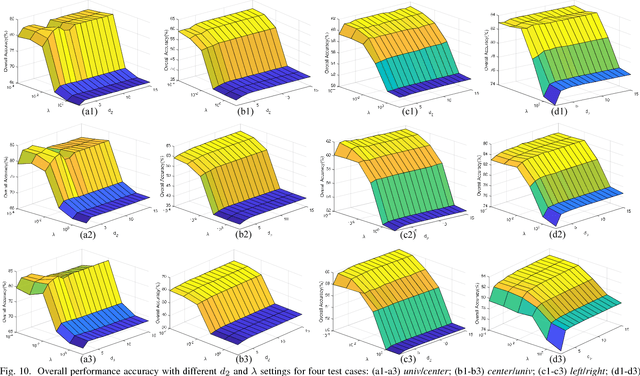
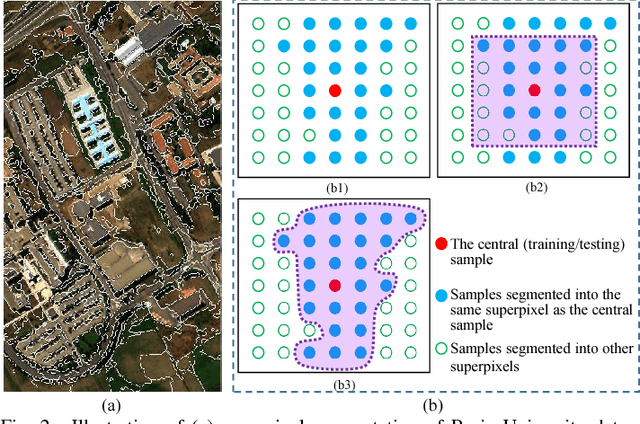
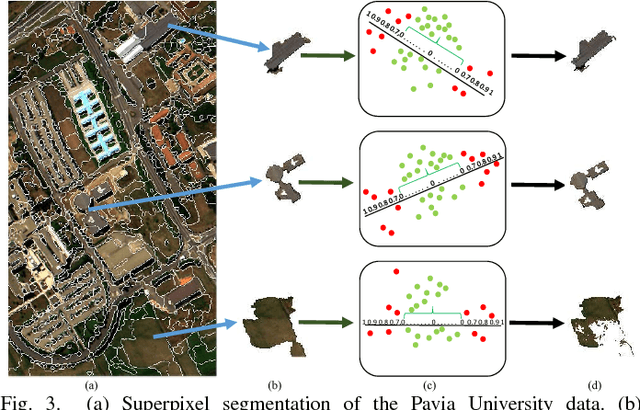
This paper presents a tensor alignment (TA) based domain adaptation method for hyperspectral image (HSI) classification. To be specific, HSIs in both domains are first segmented into superpixels and tensors of both domains are constructed to include neighboring samples from single superpixel. Then we consider the subspace invariance between two domains as projection matrices and original tensors are projected as core tensors with lower dimensions into the invariant tensor subspace by applying Tucker decomposition. To preserve geometric information in original tensors, we employ a manifold regularization term for core tensors into the decomposition progress. The projection matrices and core tensors are solved in an alternating optimization manner and the convergence of TA algorithm is analyzed. In addition, a post-processing strategy is defined via pure samples extraction for each superpixel to further improve classification performance. Experimental results on four real HSIs demonstrate that the proposed method can achieve better performance compared with the state-of-the-art subspace learning methods when a limited amount of source labeled samples are available.
Deep Co-Attention Network for Multi-View Subspace Learning
Feb 15, 2021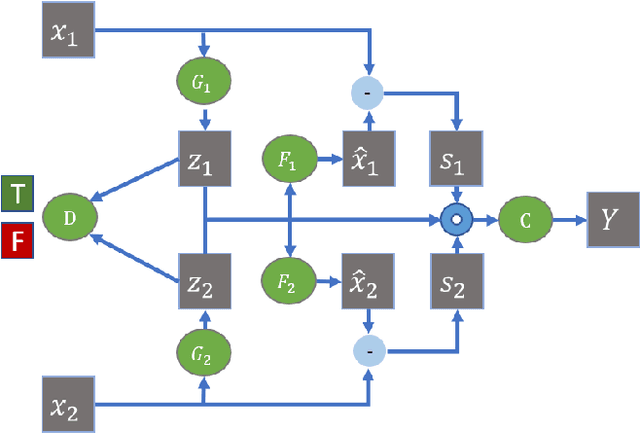
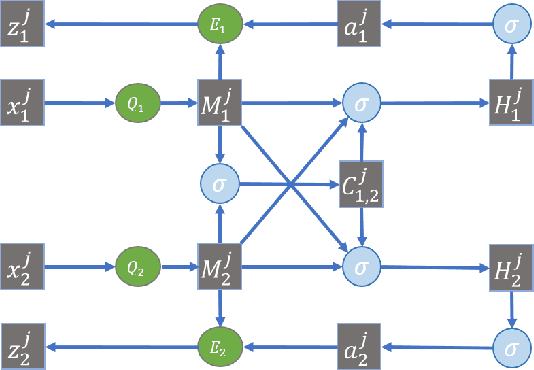
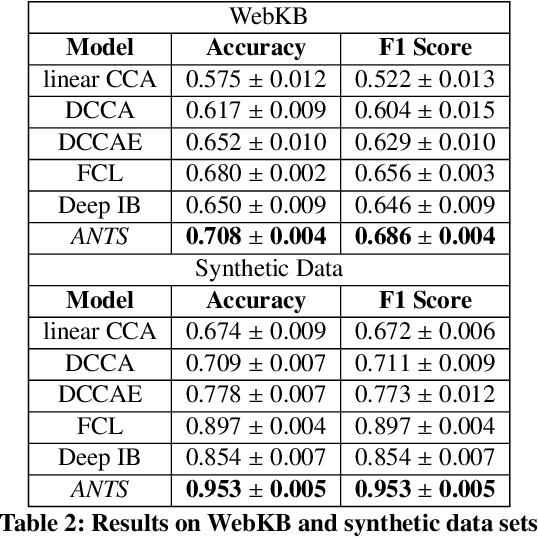
Many real-world applications involve data from multiple modalities and thus exhibit the view heterogeneity. For example, user modeling on social media might leverage both the topology of the underlying social network and the content of the users' posts; in the medical domain, multiple views could be X-ray images taken at different poses. To date, various techniques have been proposed to achieve promising results, such as canonical correlation analysis based methods, etc. In the meanwhile, it is critical for decision-makers to be able to understand the prediction results from these methods. For example, given the diagnostic result that a model provided based on the X-ray images of a patient at different poses, the doctor needs to know why the model made such a prediction. However, state-of-the-art techniques usually suffer from the inability to utilize the complementary information of each view and to explain the predictions in an interpretable manner. To address these issues, in this paper, we propose a deep co-attention network for multi-view subspace learning, which aims to extract both the common information and the complementary information in an adversarial setting and provide robust interpretations behind the prediction to the end-users via the co-attention mechanism. In particular, it uses a novel cross reconstruction loss and leverages the label information to guide the construction of the latent representation by incorporating the classifier into our model. This improves the quality of latent representation and accelerates the convergence speed. Finally, we develop an efficient iterative algorithm to find the optimal encoders and discriminator, which are evaluated extensively on synthetic and real-world data sets. We also conduct a case study to demonstrate how the proposed method robustly interprets the predictions on an image data set.
Generate and Verify: Semantically Meaningful Formal Analysis of Neural Network Perception Systems
Dec 16, 2020

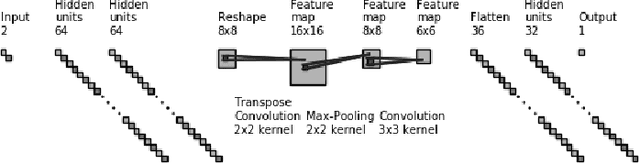
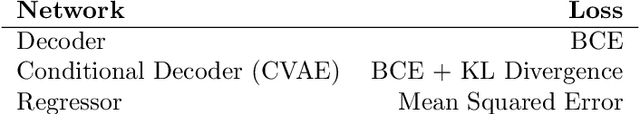
Testing remains the primary method to evaluate the accuracy of neural network perception systems. Prior work on the formal verification of neural network perception models has been limited to notions of local adversarial robustness for classification with respect to individual image inputs. In this work, we propose a notion of global correctness for neural network perception models performing regression with respect to a generative neural network with a semantically meaningful latent space. That is, against an infinite set of images produced by a generative model over an interval of its latent space, we employ neural network verification to prove that the model will always produce estimates within some error bound of the ground truth. Where the perception model fails, we obtain semantically meaningful counter-examples which carry information on concrete states of the system of interest that can be used programmatically without human inspection of corresponding generated images. Our approach, Generate and Verify, provides a new technique to gather insight into the failure cases of neural network perception systems and provide meaningful guarantees of correct behavior in safety critical applications.
In-N-Out: Pre-Training and Self-Training using Auxiliary Information for Out-of-Distribution Robustness
Dec 16, 2020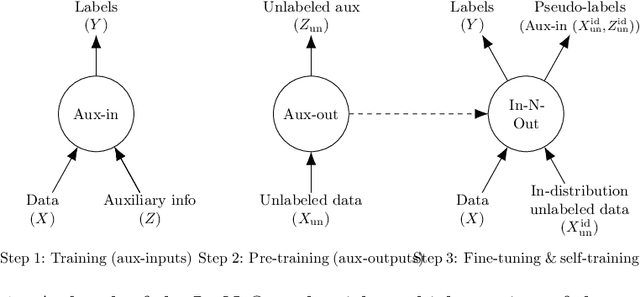
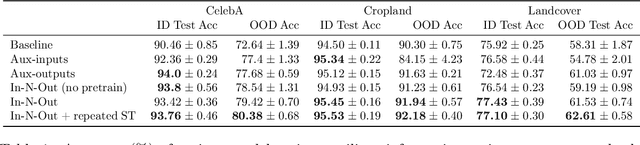

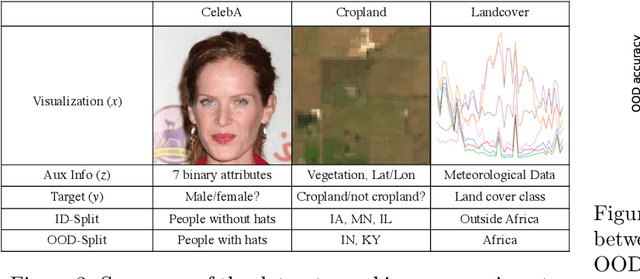
Consider a prediction setting where a few inputs (e.g., satellite images) are expensively annotated with the prediction targets (e.g., crop types), and many inputs are cheaply annotated with auxiliary information (e.g., climate information). How should we best leverage this auxiliary information for the prediction task? Empirically across three image and time-series datasets, and theoretically in a multi-task linear regression setting, we show that (i) using auxiliary information as input features improves in-distribution error but can hurt out-of-distribution (OOD) error; while (ii) using auxiliary information as outputs of auxiliary tasks to pre-train a model improves OOD error. To get the best of both worlds, we introduce In-N-Out, which first trains a model with auxiliary inputs and uses it to pseudolabel all the in-distribution inputs, then pre-trains a model on OOD auxiliary outputs and fine-tunes this model with the pseudolabels (self-training). We show both theoretically and empirically that In-N-Out outperforms auxiliary inputs or outputs alone on both in-distribution and OOD error.
Deepzzle: Solving Visual Jigsaw Puzzles with Deep Learning andShortest Path Optimization
May 26, 2020
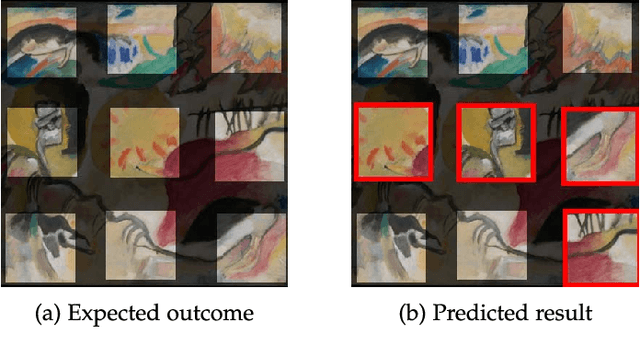

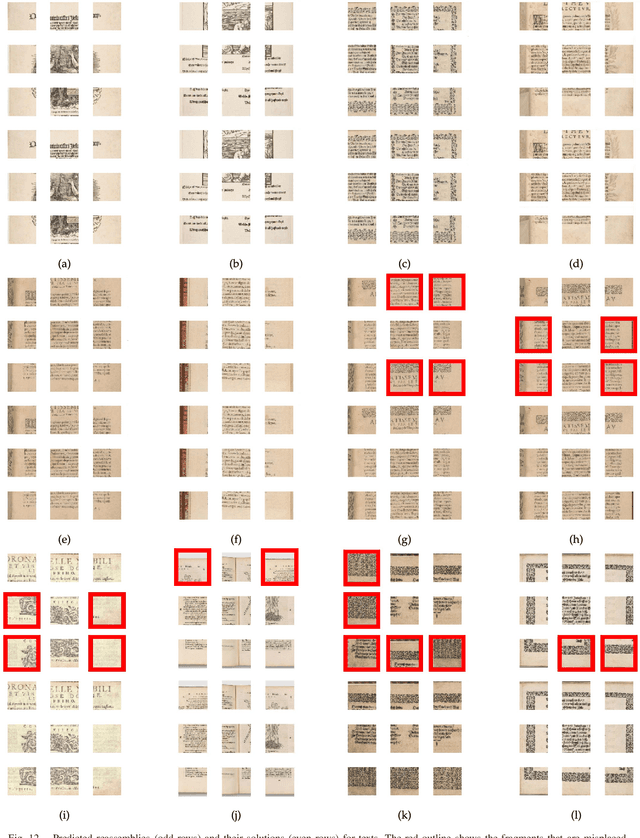
We tackle the image reassembly problem with wide space between the fragments, in such a way that the patterns and colors continuity is mostly unusable. The spacing emulates the erosion of which the archaeological fragments suffer. We crop-square the fragments borders to compel our algorithm to learn from the content of the fragments. We also complicate the image reassembly by removing fragments and adding pieces from other sources. We use a two-step method to obtain the reassemblies: 1) a neural network predicts the positions of the fragments despite the gaps between them; 2) a graph that leads to the best reassemblies is made from these predictions. In this paper, we notably investigate the effect of branch-cut in the graph of reassemblies. We also provide a comparison with the literature, solve complex images reassemblies, explore at length the dataset, and propose a new metric that suits its specificities. Keywords: image reassembly, jigsaw puzzle, deep learning, graph, branch-cut, cultural heritage
From Rain Removal to Rain Generation
Aug 08, 2020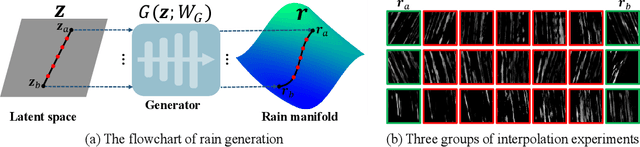
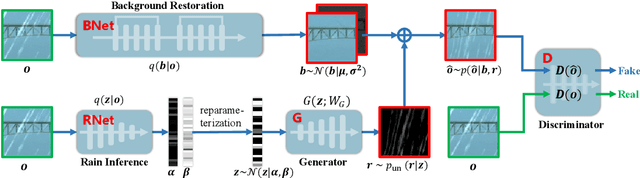
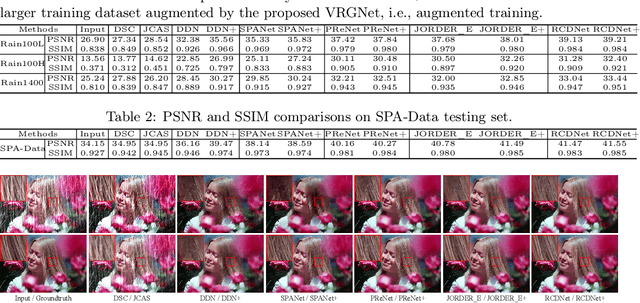

Single image deraining is an important yet challenging issue due to the complex and diverse rain structures in real scenes. Currently, the state-of-the-art performance on this task is achieved by deep learning (DL)-based methods that mainly benefit from abundant pre-collected paired rainy-clean samples either manually synthesized or semi-automatically generated under human supervision. This tends to bring a large labor for data collection and more importantly, such manner neglects to elaborately explore the intrinsic generative mechanism of rain streaks which should be related to the most insightful understanding of the task. Against this issue, we investigate the generative process of rainy image and construct a full Bayesian generative model for generating rains from automatically extracted latent variables that represent physical structural factors for depicting rains, like direction, scale, and thickness. To solve this model, we propose an algorithm where the posteriors of latent variables are parameterized as CNNs and all the involved parameters can be inferred under a concise variational inference framework in a data-driven manner. Especially, the rain layer is modeled as an implicit distribution, parameterized as a generator, which avoids subjective prior assumptions on rains as in traditional model-based methods. More practically, from the learned generator, rain patches can be automatically generated and utilized to simulate diverse training pairs so as to enrich and augment the existing benchmark datasets. Comprehensive experiments substantiate that the proposed model has fine capability of generating plausible samples that not only helps significantly improve the deraining performance of current DL-based single image derainers, but also largely loosens the requirement of large training sample pre-collection for the task.
Accelerating Road Sign Ground Truth Construction with Knowledge Graph and Machine Learning
Dec 04, 2020


Having a comprehensive, high-quality dataset of road sign annotation is critical to the success of AI-based Road Sign Recognition (RSR) systems. In practice, annotators often face difficulties in learning road sign systems of different countries; hence, the tasks are often time-consuming and produce poor results. We propose a novel approach using knowledge graphs and a machine learning algorithm - variational prototyping-encoder (VPE) - to assist human annotators in classifying road signs effectively. Annotators can query the Road Sign Knowledge Graph using visual attributes and receive closest matching candidates suggested by the VPE model. The VPE model uses the candidates from the knowledge graph and a real sign image patch as inputs. We show that our knowledge graph approach can reduce sign search space by 98.9%. Furthermore, with VPE, our system can propose the correct single candidate for 75% of signs in the tested datasets, eliminating the human search effort entirely in those cases.
* 12 pages, 5 figures
Rethinking CNN-Based Pansharpening: Guided Colorization of Panchromatic Images via GANs
Jun 30, 2020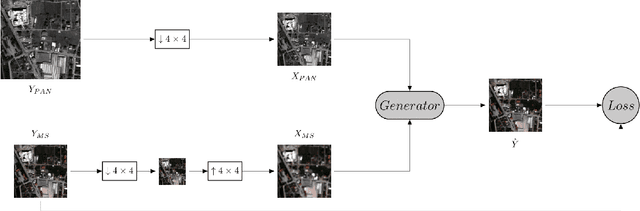


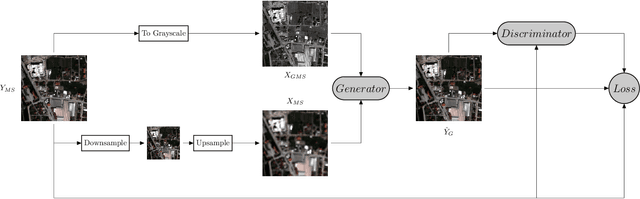
Convolutional Neural Networks (CNN)-based approaches have shown promising results in pansharpening of satellite images in recent years. However, they still exhibit limitations in producing high-quality pansharpening outputs. To that end, we propose a new self-supervised learning framework, where we treat pansharpening as a colorization problem, which brings an entirely novel perspective and solution to the problem compared to existing methods that base their solution solely on producing a super-resolution version of the multispectral image. Whereas CNN-based methods provide a reduced resolution panchromatic image as input to their model along with reduced resolution multispectral images, hence learn to increase their resolution together, we instead provide the grayscale transformed multispectral image as input, and train our model to learn the colorization of the grayscale input. We further address the fixed downscale ratio assumption during training, which does not generalize well to the full-resolution scenario. We introduce a noise injection into the training by randomly varying the downsampling ratios. Those two critical changes, along with the addition of adversarial training in the proposed PanColorization Generative Adversarial Networks (PanColorGAN) framework, help overcome the spatial detail loss and blur problems that are observed in CNN-based pansharpening. The proposed approach outperforms the previous CNN-based and traditional methods as demonstrated in our experiments.