 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Synthesize then Compare: Detecting Failures and Anomalies for Semantic Segmentation
Mar 18, 2020
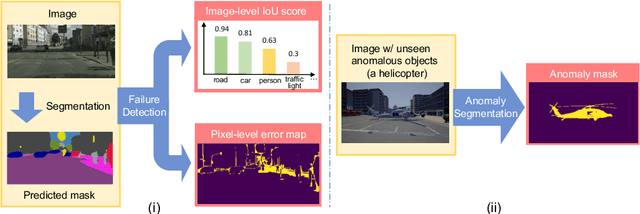
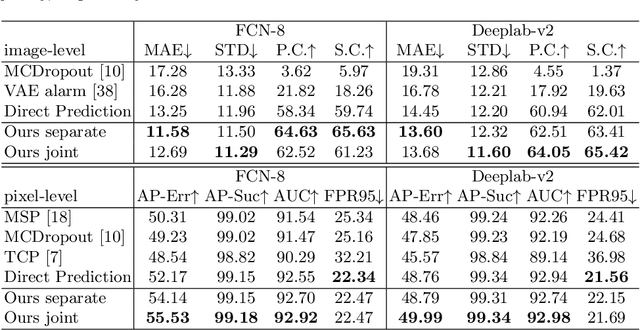
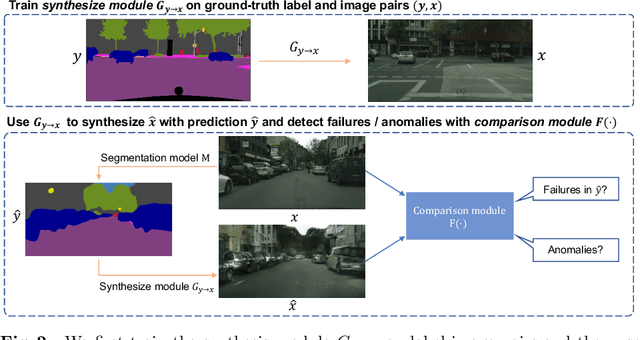
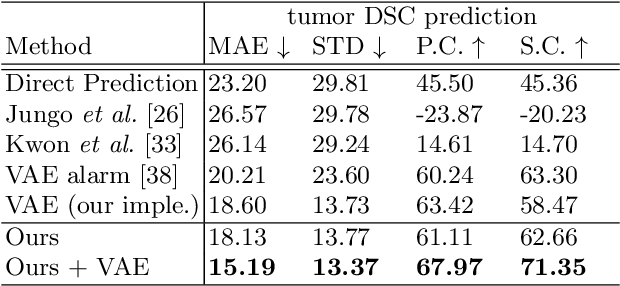
The ability to detect failures and anomalies are fundamental requirements for building reliable systems for computer vision applications, especially safety-critical applications of semantic segmentation, such as autonomous driving and medical image analysis. In this paper, we systematically study failure and anomaly detection for semantic segmentation and propose a unified framework, consisting of two modules, to address these two related problems. The first module is an image synthesis module, which generates a synthesized image from a segmentation layout map, and the second is a comparison module, which computes the difference between the synthesized image and the input image. We validate our framework on three challenging datasets and improve the state-of-the-arts by large margins, i.e., 6% AUPR-Error on Cityscapes, 10% DSC correlation on pancreatic tumor segmentation in MSD and 20% AUPR on StreetHazards anomaly segmentation.
A Review of Automatically Diagnosing COVID-19 based on Scanning Image
Jun 09, 2020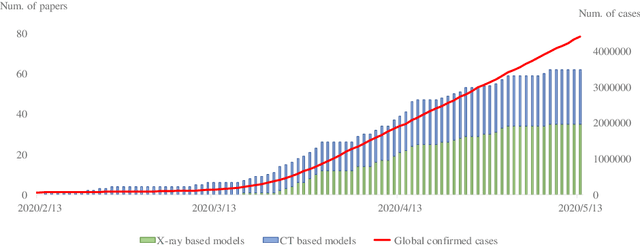
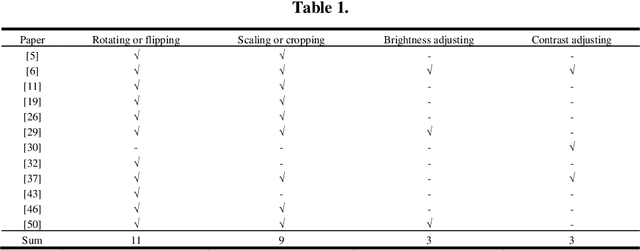
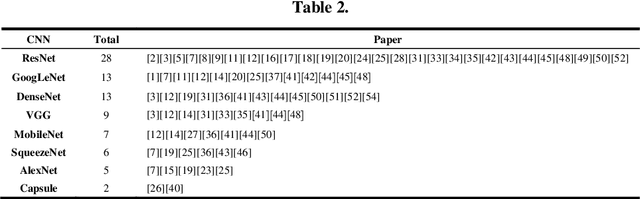
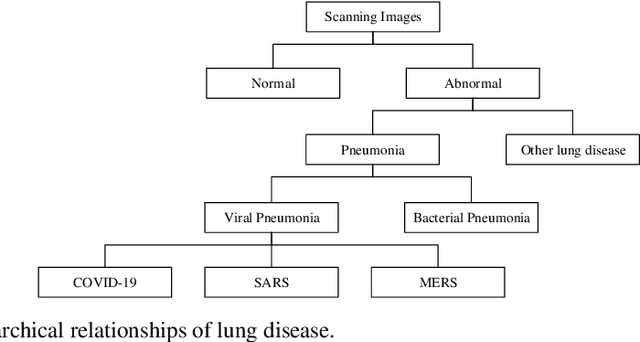
The pandemic of COVID-19 has caused millions of infectious. Due to the false-negative rate and the time cost of conventional RT-PCR tests, X-ray images and Computed Tomography (CT) images based diagnosing become widely adopted. Therefore, researchers of the computer vision area have developed many automatic diagnosing models to help the radiologists and pro-mote the diagnosing accuracy. In this paper, we present a review of these recently emerging automatic diagnosing models. 62 models from 14, February to 5, May, 2020 are involved. We analyzed the models from the perspective of preprocessing, feature extraction, classification, and evaluation. Then we pointed out that domain adaption in transfer learning and interpretability promotion are the possible future directions.
Complementary Pseudo Labels For Unsupervised Domain Adaptation On Person Re-identification
Jan 29, 2021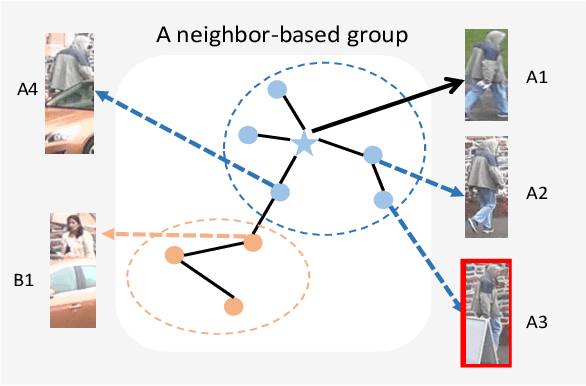
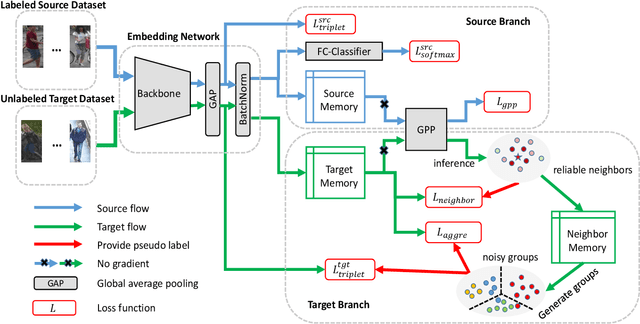
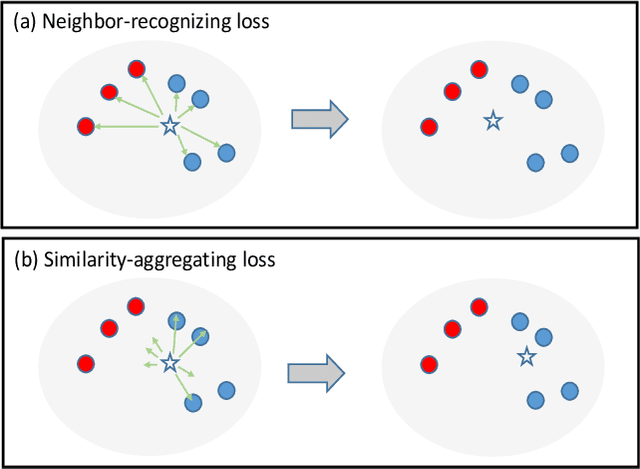
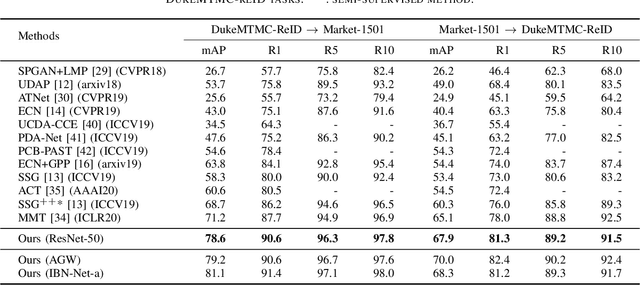
In recent years, supervised person re-identification (re-ID) models have received increasing studies. However, these models trained on the source domain always suffer dramatic performance drop when tested on an unseen domain. Existing methods are primary to use pseudo labels to alleviate this problem. One of the most successful approaches predicts neighbors of each unlabeled image and then uses them to train the model. Although the predicted neighbors are credible, they always miss some hard positive samples, which may hinder the model from discovering important discriminative information of the unlabeled domain. In this paper, to complement these low recall neighbor pseudo labels, we propose a joint learning framework to learn better feature embeddings via high precision neighbor pseudo labels and high recall group pseudo labels. The group pseudo labels are generated by transitively merging neighbors of different samples into a group to achieve higher recall. However, the merging operation may cause subgroups in the group due to imperfect neighbor predictions. To utilize these group pseudo labels properly, we propose using a similarity-aggregating loss to mitigate the influence of these subgroups by pulling the input sample towards the most similar embeddings. Extensive experiments on three large-scale datasets demonstrate that our method can achieve state-of-the-art performance under the unsupervised domain adaptation re-ID setting.
Detection of data drift and outliers affecting machine learning model performance over time
Jan 20, 2021

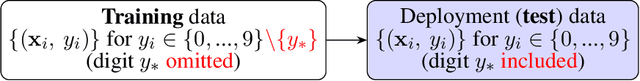
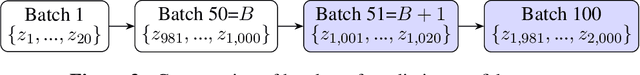
A trained ML model is deployed on another `test' dataset where target feature values (labels) are unknown. Drift is distribution change between the training and deployment data, which is concerning if model performance changes. For a cat/dog image classifier, for instance, drift during deployment could be rabbit images (new class) or cat/dog images with changed characteristics (change in distribution). We wish to detect these changes but can't measure accuracy without deployment data labels. We instead detect drift indirectly by nonparametrically testing the distribution of model prediction confidence for changes. This generalizes our method and sidesteps domain-specific feature representation. We address important statistical issues, particularly Type-1 error control in sequential testing, using Change Point Models (CPMs; see Adams and Ross 2012). We also use nonparametric outlier methods to show the user suspicious observations for model diagnosis, since the before/after change confidence distributions overlap significantly. In experiments to demonstrate robustness, we train on a subset of MNIST digit classes, then insert drift (e.g., unseen digit class) in deployment data in various settings (gradual/sudden changes in the drift proportion). A novel loss function is introduced to compare the performance (detection delay, Type-1 and 2 errors) of a drift detector under different levels of drift class contamination.
A persistent homology-based topological loss function for multi-class CNN segmentation of cardiac MRI
Aug 21, 2020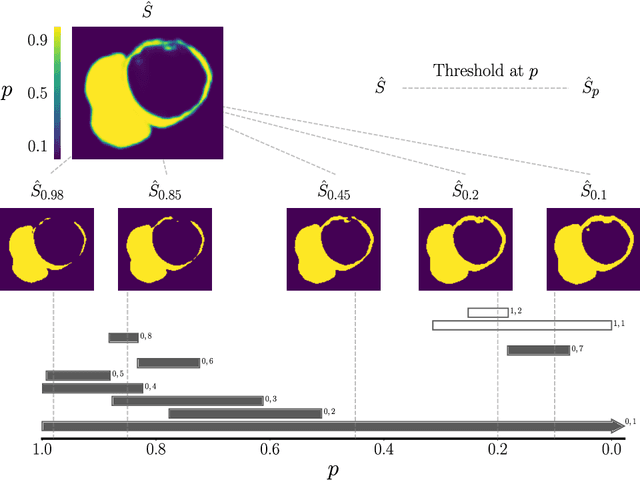
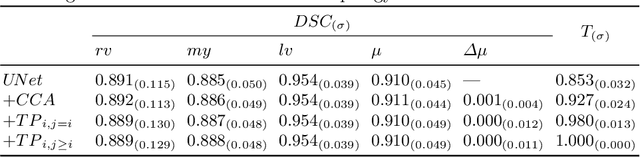
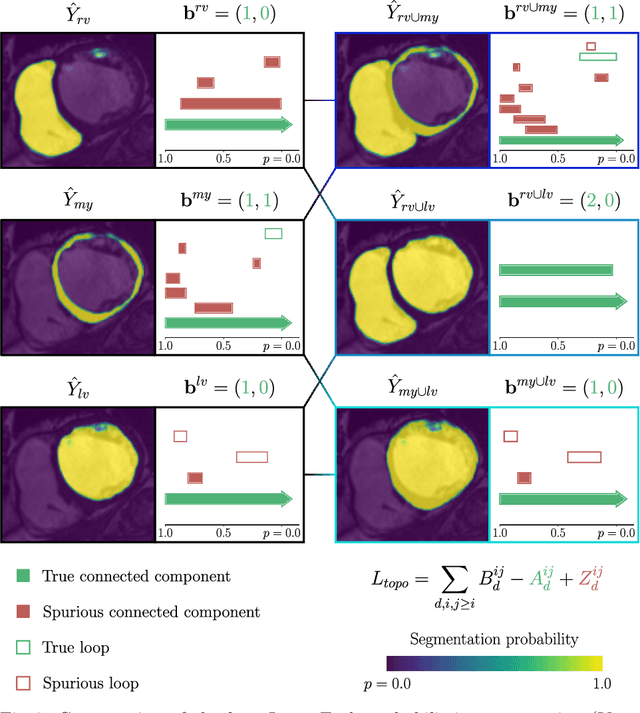
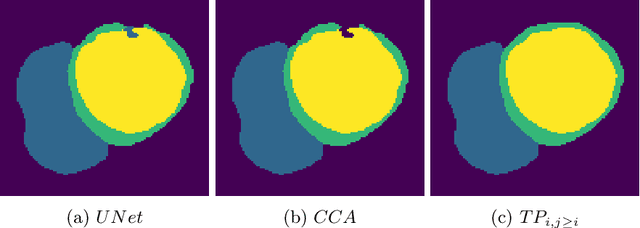
With respect to spatial overlap, CNN-based segmentation of short axis cardiovascular magnetic resonance (CMR) images has achieved a level of performance consistent with inter observer variation. However, conventional training procedures frequently depend on pixel-wise loss functions, limiting optimisation with respect to extended or global features. As a result, inferred segmentations can lack spatial coherence, including spurious connected components or holes. Such results are implausible, violating the anticipated topology of image segments, which is frequently known a priori. Addressing this challenge, published work has employed persistent homology, constructing topological loss functions for the evaluation of image segments against an explicit prior. Building a richer description of segmentation topology by considering all possible labels and label pairs, we extend these losses to the task of multi-class segmentation. These topological priors allow us to resolve all topological errors in a subset of 150 examples from the ACDC short axis CMR training data set, without sacrificing overlap performance.
Heightmap Reconstruction of Macula on Color Fundus Images Using Conditional Generative Adversarial Networks
Sep 03, 2020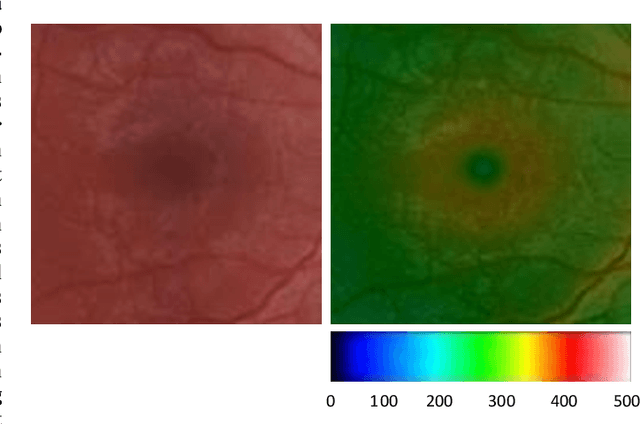
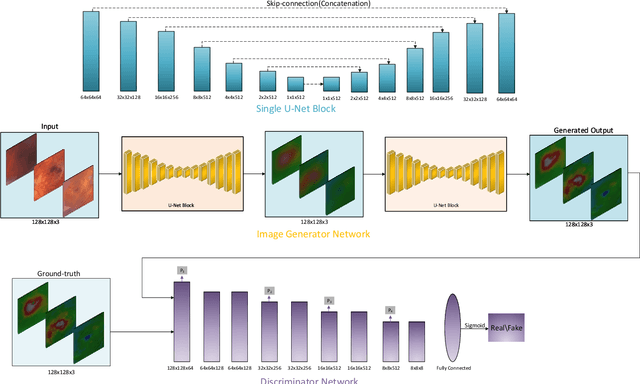
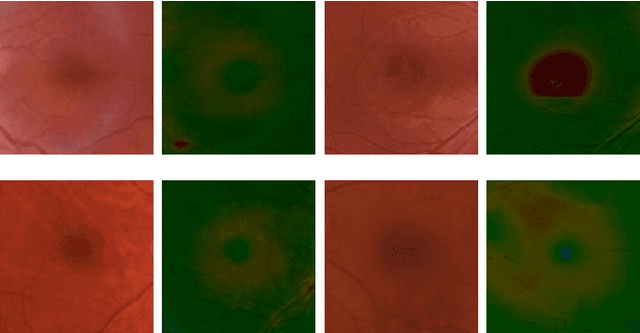
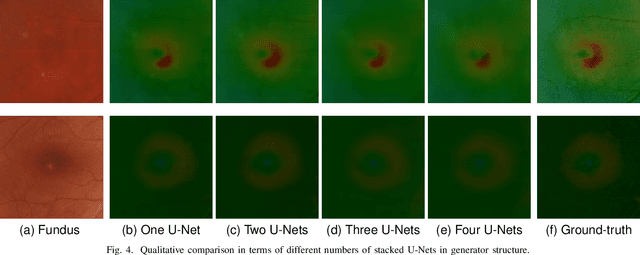
For medical diagnosis based on retinal images, a clear understanding of 3D structure is often required but due to the 2D nature of images captured, we cannot infer that information. However, by utilizing 3D reconstruction methods, we can construct the 3D structure of the macula area on fundus images which can be helpful for diagnosis and screening of macular disorders. Recent approaches have used shading information for 3D reconstruction or heightmap prediction but their output was not accurate since they ignored the dependency between nearby pixels. Additionally, other methods were dependent on the availability of more than one image of the eye which is not available in practice. In this paper, we use conditional generative adversarial networks (cGANs) to generate images that contain height information of the macula area on a fundus image. Results using our dataset show a 0.6077 improvement in Structural Similarity Index (SSIM) and 0.071 improvements in Mean Squared Error (MSE) metric over Shape from Shading (SFS) method. Additionally, Qualitative studies also indicate that our method outperforms recent approaches.
Style Your Face Morph and Improve Your Face Morphing Attack Detector
Apr 23, 2020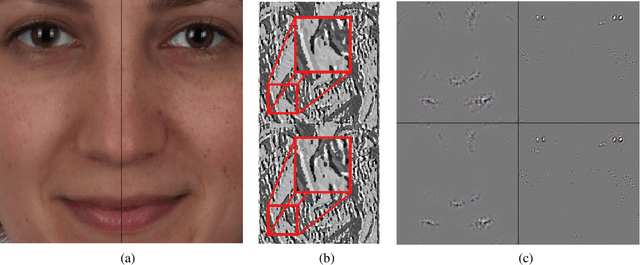
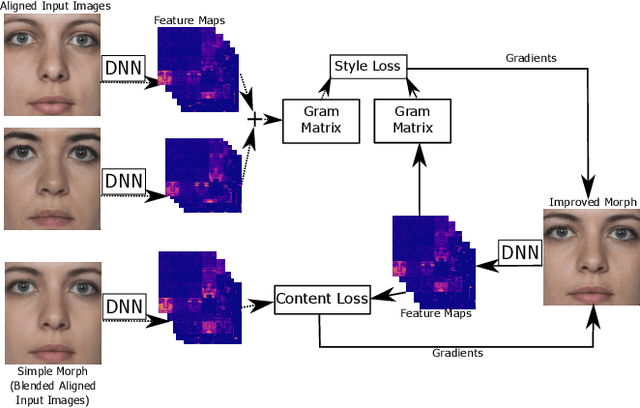
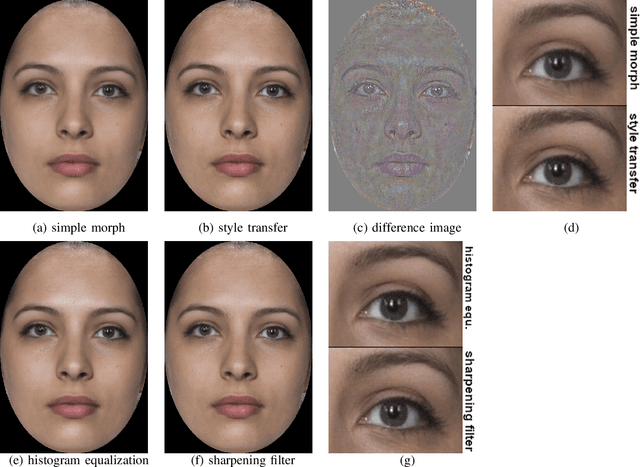
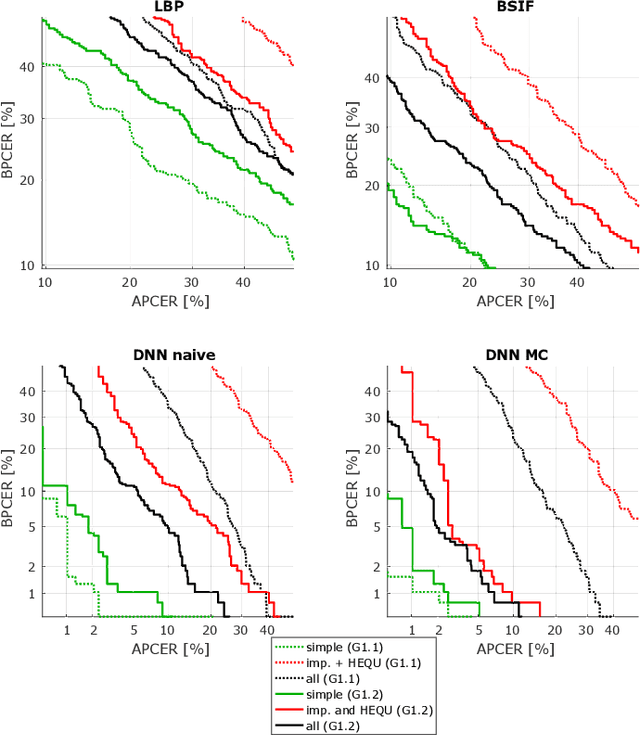
A morphed face image is a synthetically created image that looks so similar to the faces of two subjects that both can use it for verification against a biometric verification system. It can be easily created by aligning and blending face images of the two subjects. In this paper, we propose a style transfer based method that improves the quality of morphed face images. It counters the image degeneration during the creation of morphed face images caused by blending. We analyze different state of the art face morphing attack detection systems regarding their performance against our improved morphed face images and other methods that improve the image quality. All detection systems perform significantly worse, when first confronted with our improved morphed face images. Most of them can be enhanced by adding our quality improved morphs to the training data, which further improves the robustness against other means of quality improvement.
Random Style Transfer based Domain Generalization Networks Integrating Shape and Spatial Information
Sep 03, 2020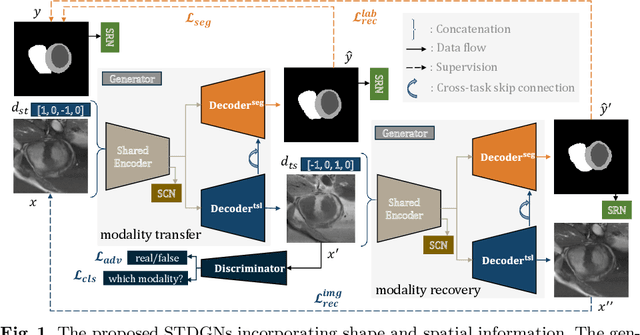
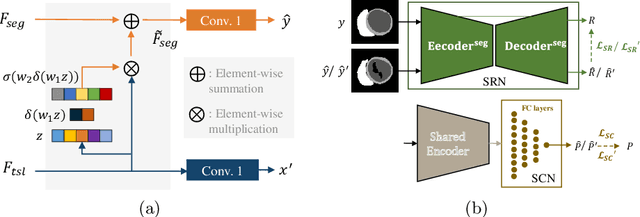
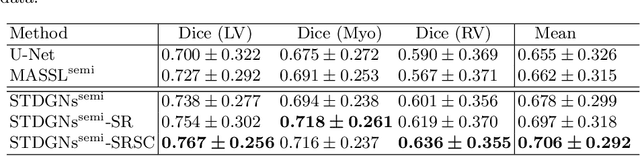
Deep learning (DL)-based models have demonstrated good performance in medical image segmentation. However, the models trained on a known dataset often fail when performed on an unseen dataset collected from different centers, vendors and disease populations. In this work, we present a random style transfer network to tackle the domain generalization problem for multi-vendor and center cardiac image segmentation. Style transfer is used to generate training data with a wider distribution/ heterogeneity, namely domain augmentation. As the target domain could be unknown, we randomly generate a modality vector for the target modality in the style transfer stage, to simulate the domain shift for unknown domains. The model can be trained in a semi-supervised manner by simultaneously optimizing a supervised segmentation and an unsupervised style translation objective. Besides, the framework incorporates the spatial information and shape prior of the target by introducing two regularization terms. We evaluated the proposed framework on 40 subjects from the M\&Ms challenge2020, and obtained promising performance in the segmentation for data from unknown vendors and centers.
Image classification using local tensor singular value decompositions
Jun 29, 2017
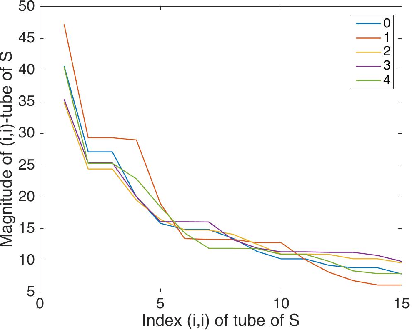
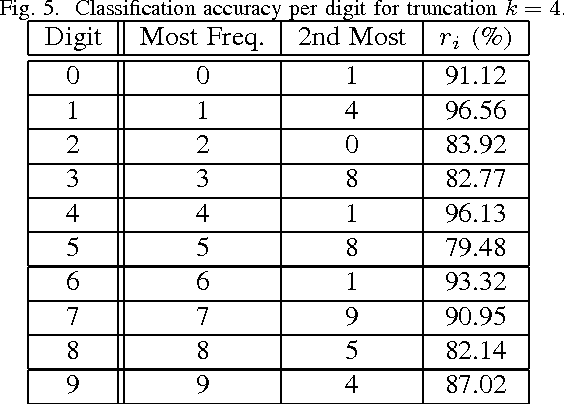
From linear classifiers to neural networks, image classification has been a widely explored topic in mathematics, and many algorithms have proven to be effective classifiers. However, the most accurate classifiers typically have significantly high storage costs, or require complicated procedures that may be computationally expensive. We present a novel (nonlinear) classification approach using truncation of local tensor singular value decompositions (tSVD) that robustly offers accurate results, while maintaining manageable storage costs. Our approach takes advantage of the optimality of the representation under the tensor algebra described to determine to which class an image belongs. We extend our approach to a method that can determine specific pairwise match scores, which could be useful in, for example, object recognition problems where pose/position are different. We demonstrate the promise of our new techniques on the MNIST data set.
Separation and Concentration in Deep Networks
Dec 18, 2020

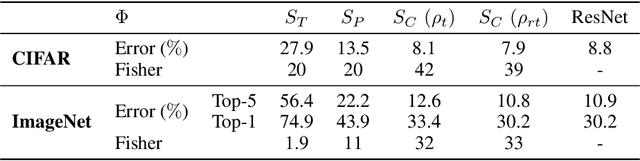

Numerical experiments demonstrate that deep neural network classifiers progressively separate class distributions around their mean, achieving linear separability on the training set, and increasing the Fisher discriminant ratio. We explain this mechanism with two types of operators. We prove that a rectifier without biases applied to sign-invariant tight frames can separate class means and increase Fisher ratios. On the opposite, a soft-thresholding on tight frames can reduce within-class variabilities while preserving class means. Variance reduction bounds are proved for Gaussian mixture models. For image classification, we show that separation of class means can be achieved with rectified wavelet tight frames that are not learned. It defines a scattering transform. Learning $1 \times 1$ convolutional tight frames along scattering channels and applying a soft-thresholding reduces within-class variabilities. The resulting scattering network reaches the classification accuracy of ResNet-18 on CIFAR-10 and ImageNet, with fewer layers and no learned biases.