 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuiding Energy-Efficient Locomotion through Impact Mitigation Rewards
Oct 10, 2025Animals achieve energy-efficient locomotion by their implicit passive dynamics, a marvel that has captivated roboticists for decades.Recently, methods incorporated Adversarial Motion Prior (AMP) and Reinforcement learning (RL) shows promising progress to replicate Animals' naturalistic motion. However, such imitation learning approaches predominantly capture explicit kinematic patterns, so-called gaits, while overlooking the implicit passive dynamics. This work bridges this gap by incorporating a reward term guided by Impact Mitigation Factor (IMF), a physics-informed metric that quantifies a robot's ability to passively mitigate impacts. By integrating IMF with AMP, our approach enables RL policies to learn both explicit motion trajectories from animal reference motion and the implicit passive dynamic. We demonstrate energy efficiency improvements of up to 32%, as measured by the Cost of Transport (CoT), across both AMP and handcrafted reward structure.
Dynamic Quadrupedal Legged and Aerial Locomotion via Structure Repurposing
Oct 10, 2025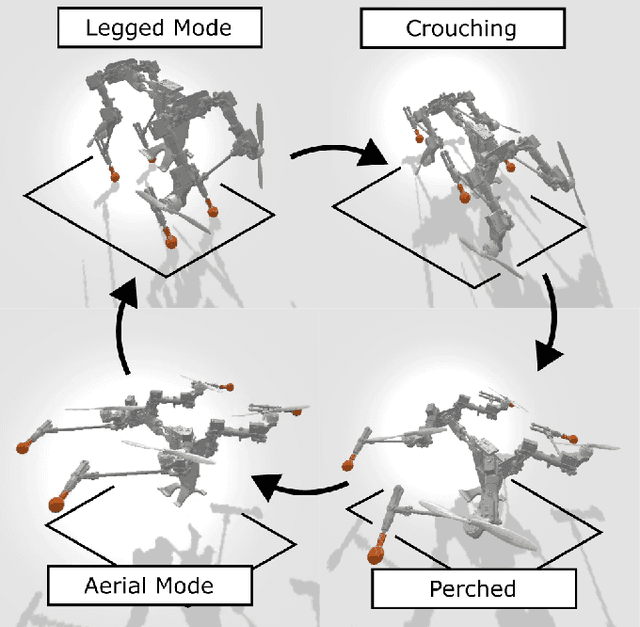
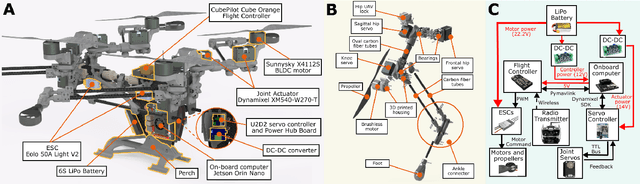

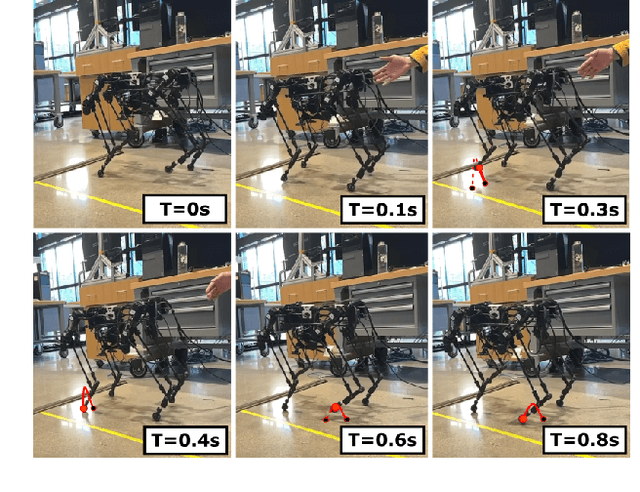
Multi-modal ground-aerial robots have been extensively studied, with a significant challenge lying in the integration of conflicting requirements across different modes of operation. The Husky robot family, developed at Northeastern University, and specifically the Husky v.2 discussed in this study, addresses this challenge by incorporating posture manipulation and thrust vectoring into multi-modal locomotion through structure repurposing. This quadrupedal robot features leg structures that can be repurposed for dynamic legged locomotion and flight. In this paper, we present the hardware design of the robot and report primary results on dynamic quadrupedal legged locomotion and hovering.
Recursive Deep Inverse Reinforcement Learning
Apr 21, 2025Inferring an adversary's goals from exhibited behavior is crucial for counterplanning and non-cooperative multi-agent systems in domains like cybersecurity, military, and strategy games. Deep Inverse Reinforcement Learning (IRL) methods based on maximum entropy principles show promise in recovering adversaries' goals but are typically offline, require large batch sizes with gradient descent, and rely on first-order updates, limiting their applicability in real-time scenarios. We propose an online Recursive Deep Inverse Reinforcement Learning (RDIRL) approach to recover the cost function governing the adversary actions and goals. Specifically, we minimize an upper bound on the standard Guided Cost Learning (GCL) objective using sequential second-order Newton updates, akin to the Extended Kalman Filter (EKF), leading to a fast (in terms of convergence) learning algorithm. We demonstrate that RDIRL is able to recover cost and reward functions of expert agents in standard and adversarial benchmark tasks. Experiments on benchmark tasks show that our proposed approach outperforms several leading IRL algorithms.
Reduced-Order Model-Based Gait Generation for Snake Robot Locomotion using NMPC
Mar 09, 2025



This paper presents an optimization-based motion planning methodology for snake robots operating in constrained environments. By using a reduced-order model, the proposed approach simplifies the planning process, enabling the optimizer to autonomously generate gaits while constraining the robot's footprint within tight spaces. The method is validated through high-fidelity simulations that accurately model contact dynamics and the robot's motion. Key locomotion strategies are identified and further demonstrated through hardware experiments, including successful navigation through narrow corridors.
Learning Physics Informed Neural ODEs With Partial Measurements
Dec 11, 2024



Learning dynamics governing physical and spatiotemporal processes is a challenging problem, especially in scenarios where states are partially measured. In this work, we tackle the problem of learning dynamics governing these systems when parts of the system's states are not measured, specifically when the dynamics generating the non-measured states are unknown. Inspired by state estimation theory and Physics Informed Neural ODEs, we present a sequential optimization framework in which dynamics governing unmeasured processes can be learned. We demonstrate the performance of the proposed approach leveraging numerical simulations and a real dataset extracted from an electro-mechanical positioning system. We show how the underlying equations fit into our formalism and demonstrate the improved performance of the proposed method when compared with baselines.
Self-supervised cost of transport estimation for multimodal path planning
Dec 08, 2024Autonomous robots operating in real environments are often faced with decisions on how best to navigate their surroundings. In this work, we address a particular instance of this problem: how can a robot autonomously decide on the energetically optimal path to follow given a high-level objective and information about the surroundings? To tackle this problem we developed a self-supervised learning method that allows the robot to estimate the cost of transport of its surroundings using only vision inputs. We apply our method to the multi-modal mobility morphobot (M4), a robot that can drive, fly, segway, and crawl through its environment. By deploying our system in the real world, we show that our method accurately assigns different cost of transports to various types of environments e.g. grass vs smooth road. We also highlight the low computational cost of our method, which is deployed on an Nvidia Jetson Orin Nano robotic compute unit. We believe that this work will allow multi-modal robotic platforms to unlock their full potential for navigation and exploration tasks.
Conjugate momentum based thruster force estimate in dynamic multimodal robot
Nov 21, 2024In a multi-modal system which combines thruster and legged locomotion such our state-of-the-art Harpy platform to perform dynamic locomotion. Therefore, it is very important to have a proper estimate of Thruster force. Harpy is a bipedal robot capable of legged-aerial locomotion using its legs and thrusters attached to its main frame. we can characterize thruster force using a thrust stand but it generally does not account for working conditions such as battery voltage. In this study, we present a momentum-based thruster force estimator. One of the key information required to estimate is terrain information. we show estimation results with and without terrain knowledge. In this work, we derive a conjugate momentum thruster force estimator and implement it on a numerical simulator that uses thruster force to perform thruster-assisted walking.
Enhanced Capture Point Control Using Thruster Dynamics and QP-Based Optimization for Harpy
Nov 21, 2024Our work aims to make significant strides in understanding unexplored locomotion control paradigms based on the integration of posture manipulation and thrust vectoring. These techniques are commonly seen in nature, such as Chukar birds using their wings to run on a nearly vertical wall. In this work, we developed a capture-point-based controller integrated with a quadratic programming (QP) solver which is used to create a thruster-assisted dynamic bipedal walking controller for our state-of-the-art Harpy platform. Harpy is a bipedal robot capable of legged-aerial locomotion using its legs and thrusters attached to its main frame. While capture point control based on centroidal models for bipedal systems has been extensively studied, the use of these thrusters in determining the capture point for a bipedal robot has not been extensively explored. The addition of these external thrust forces can lead to interesting interpretations of locomotion, such as virtual buoyancy studied in aquatic-legged locomotion. In this work, we derive a thruster-assisted bipedal walking with the capture point controller and implement it in simulation to study its performance.
Validation of Tumbling Robot Dynamics with Posture Manipulation for Closed-Loop Heading Angle Control
Nov 20, 2024Navigating rugged terrain and steep slopes is a challenge for mobile robots. Conventional legged and wheeled systems struggle with these environments due to limited traction and stability. Northeastern University's COBRA (Crater Observing Bio-inspired Rolling Articulator), a novel multi-modal snake-like robot, addresses these issues by combining traditional snake gaits for locomotion on flat and inclined surfaces with a tumbling mode for controlled descent on steep slopes. Through dynamic posture manipulation, COBRA can modulate its heading angle and velocity during tumbling. This paper presents a reduced-order cascade model for COBRA's tumbling locomotion and validates it against a high-fidelity rigid-body simulation, presenting simulation results that show that the model captures key system dynamics.
Quadratic Programming Optimization for Bio-Inspired Thruster-Assisted Bipedal Locomotion on Inclined Slopes
Nov 20, 2024



Our work aims to make significant strides in understanding unexplored locomotion control paradigms based on the integration of posture manipulation and thrust vectoring. These techniques are commonly seen in nature, such as Chukar birds using their wings to run on a nearly vertical wall. In this work, we show quadratic programming with contact constraints which is then given to the whole body controller to map on robot states to produce a thruster-assisted slope walking controller for our state-of-the-art Harpy platform. Harpy is a bipedal robot capable of legged-aerial locomotion using its legs and thrusters attached to its main frame. The optimization-based walking controller has been used for dynamic locomotion such as slope walking, but the addition of thrusters to perform inclined slope walking has not been extensively explored. In this work, we derive a thruster-assisted bipedal walking with the quadratic programming (QP) controller and implement it in simulation to study its performance.