 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Suggestive Annotation of Brain Tumour Images with Gradient-guided Sampling
Jun 26, 2020
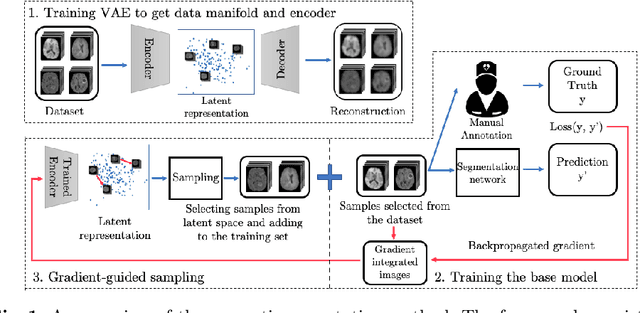
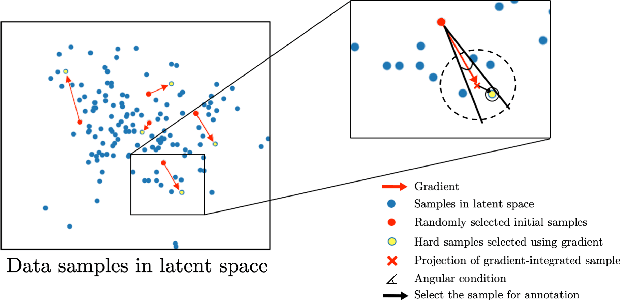
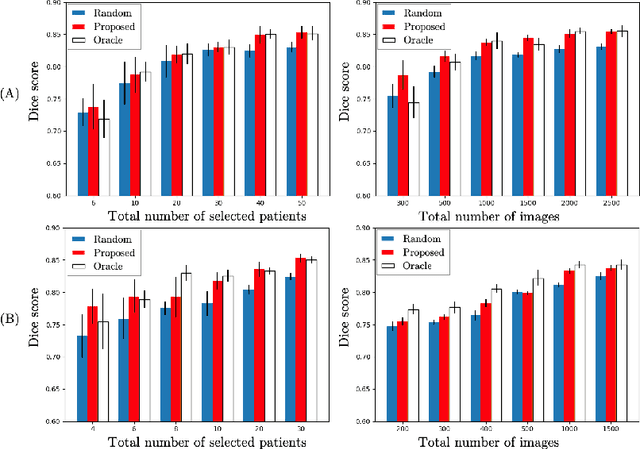
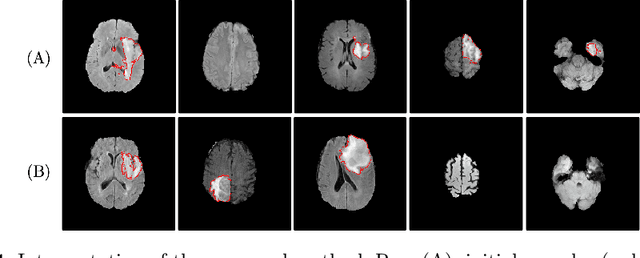
Machine learning has been widely adopted for medical image analysis in recent years given its promising performance in image segmentation and classification tasks. As a data-driven science, the success of machine learning, in particular supervised learning, largely depends on the availability of manually annotated datasets. For medical imaging applications, such annotated datasets are not easy to acquire. It takes a substantial amount of time and resource to curate an annotated medical image set. In this paper, we propose an efficient annotation framework for brain tumour images that is able to suggest informative sample images for human experts to annotate. Our experiments show that training a segmentation model with only 19% suggestively annotated patient scans from BraTS 2019 dataset can achieve a comparable performance to training a model on the full dataset for whole tumour segmentation task. It demonstrates a promising way to save manual annotation cost and improve data efficiency in medical imaging applications.
Image denoising using group sparsity residual and external nonlocal self-similarity prior
Jan 03, 2017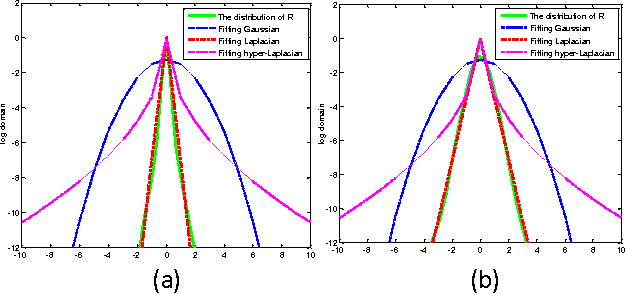
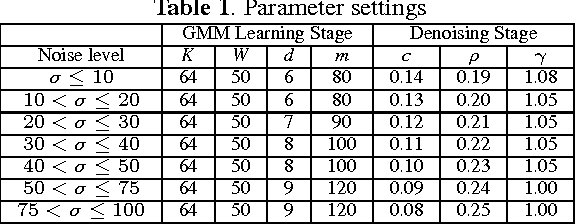


Nonlocal image representation has been successfully used in many image-related inverse problems including denoising, deblurring and deblocking. However, a majority of reconstruction methods only exploit the nonlocal self-similarity (NSS) prior of the degraded observation image, it is very challenging to reconstruct the latent clean image. In this paper we propose a novel model for image denoising via group sparsity residual and external NSS prior. To boost the performance of image denoising, the concept of group sparsity residual is proposed, and thus the problem of image denoising is transformed into one that reduces the group sparsity residual. Due to the fact that the groups contain a large amount of NSS information of natural images, we obtain a good estimation of the group sparse coefficients of the original image by the external NSS prior based on Gaussian Mixture model (GMM) learning and the group sparse coefficients of noisy image is used to approximate the estimation. Experimental results have demonstrated that the proposed method not only outperforms many state-of-the-art methods, but also delivers the best qualitative denoising results with finer details and less ringing artifacts.
Limitation of Acyclic Oriented Graphs Matching as Cell Tracking Accuracy Measure when Evaluating Mitosis
Dec 22, 2020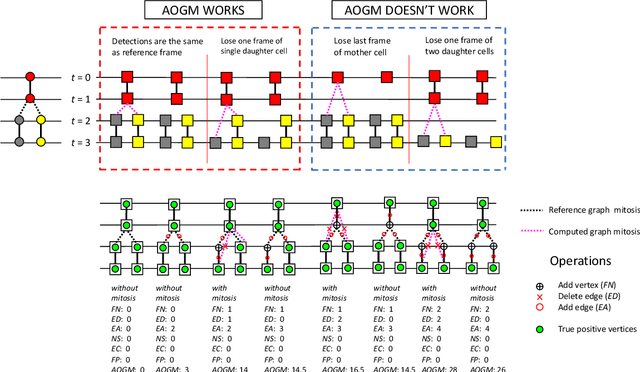
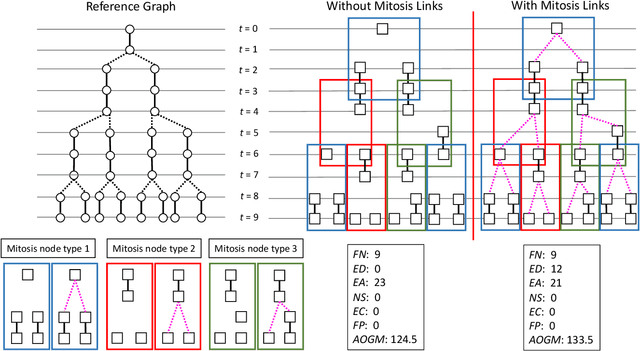
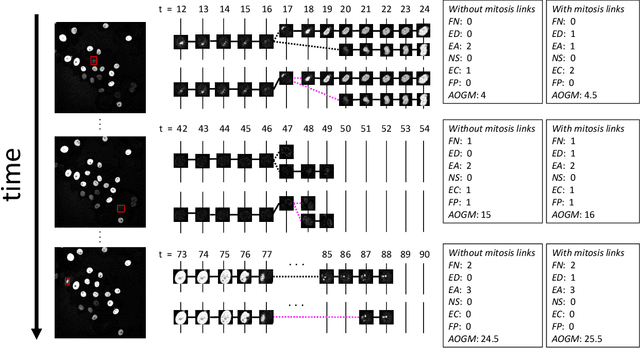
Multi-object tracking (MOT) in computer vision and cell tracking in biomedical image analysis are two similar research fields, whose common aim is to achieve instance level object detection/segmentation and associate such objects across different video frames. However, one major difference between these two tasks is that cell tracking also aim to detect mitosis (cell division), which is typically not considered in MOT tasks. Therefore, the acyclic oriented graphs matching (AOGM) has been used as de facto standard evaluation metrics for cell tracking, rather than directly using the evaluation metrics in computer vision, such as multiple object tracking accuracy (MOTA), ID Switches (IDS), ID F1 Score (IDF1) etc. However, based on our experiments, we realized that AOGM did not always function as expected for mitosis events. In this paper, we exhibit the limitations of evaluating mitosis with AOGM using both simulated and real cell tracking data.
Content adaptive screen image scaling
Oct 21, 2015
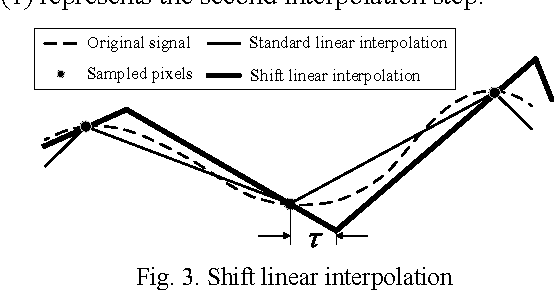
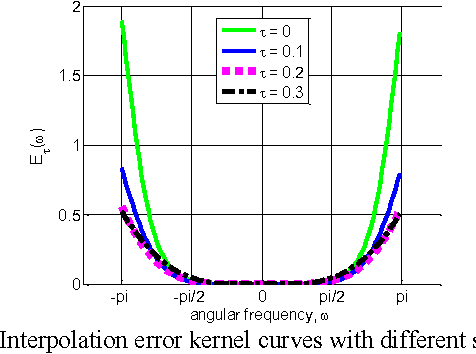
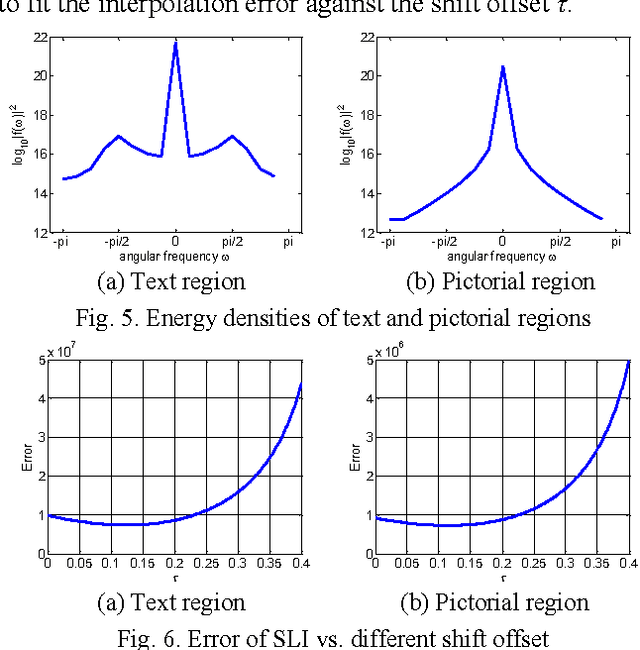
This paper proposes an efficient content adaptive screen image scaling scheme for the real-time screen applications like remote desktop and screen sharing. In the proposed screen scaling scheme, a screen content classification step is first introduced to classify the screen image into text and pictorial regions. Afterward, we propose an adaptive shift linear interpolation algorithm to predict the new pixel values with the shift offset adapted to the content type of each pixel. The shift offset for each screen content type is offline optimized by minimizing the theoretical interpolation error based on the training samples respectively. The proposed content adaptive screen image scaling scheme can achieve good visual quality and also keep the low complexity for real-time applications.
iSeeBetter: Spatio-temporal video super-resolution using recurrent generative back-projection networks
Jun 22, 2020
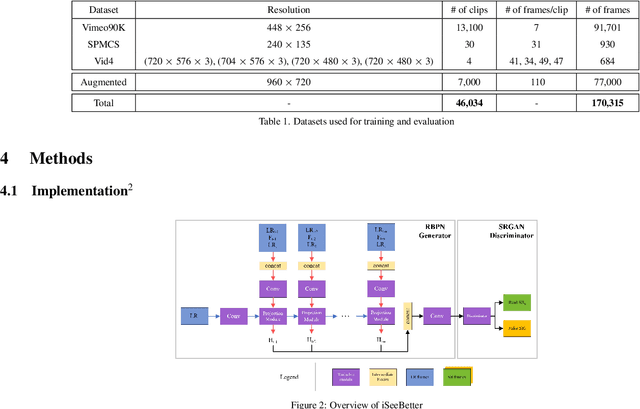
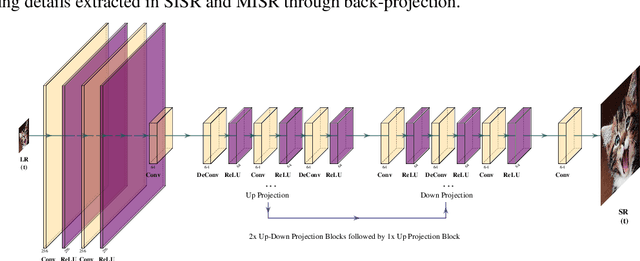
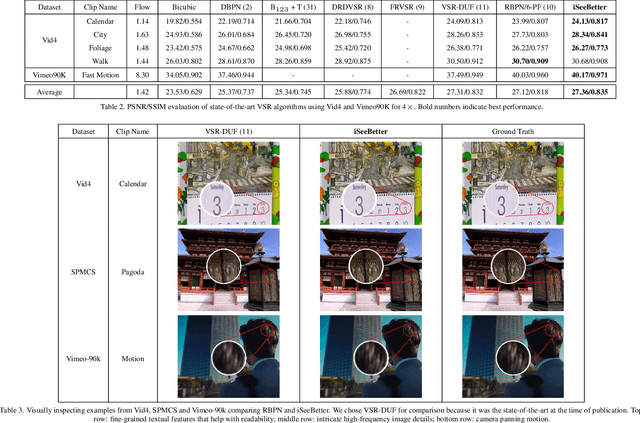
Recently, learning-based models have enhanced the performance of single-image super-resolution (SISR). However, applying SISR successively to each video frame leads to a lack of temporal coherency. Convolutional neural networks (CNNs) outperform traditional approaches in terms of image quality metrics such as peak signal to noise ratio (PSNR) and structural similarity (SSIM). However, generative adversarial networks (GANs) offer a competitive advantage by being able to mitigate the issue of a lack of finer texture details, usually seen with CNNs when super-resolving at large upscaling factors. We present iSeeBetter, a novel GAN-based spatio-temporal approach to video super-resolution (VSR) that renders temporally consistent super-resolution videos. iSeeBetter extracts spatial and temporal information from the current and neighboring frames using the concept of recurrent back-projection networks as its generator. Furthermore, to improve the "naturality" of the super-resolved image while eliminating artifacts seen with traditional algorithms, we utilize the discriminator from super-resolution generative adversarial network (SRGAN). Although mean squared error (MSE) as a primary loss-minimization objective improves PSNR/SSIM, these metrics may not capture fine details in the image resulting in misrepresentation of perceptual quality. To address this, we use a four-fold (MSE, perceptual, adversarial, and total-variation (TV)) loss function. Our results demonstrate that iSeeBetter offers superior VSR fidelity and surpasses state-of-the-art performance.
* 11 pages, 6 figures, 4 tables
Generative Adversarial Networks in Digital Pathology: A Survey on Trends and Future Potential
May 07, 2020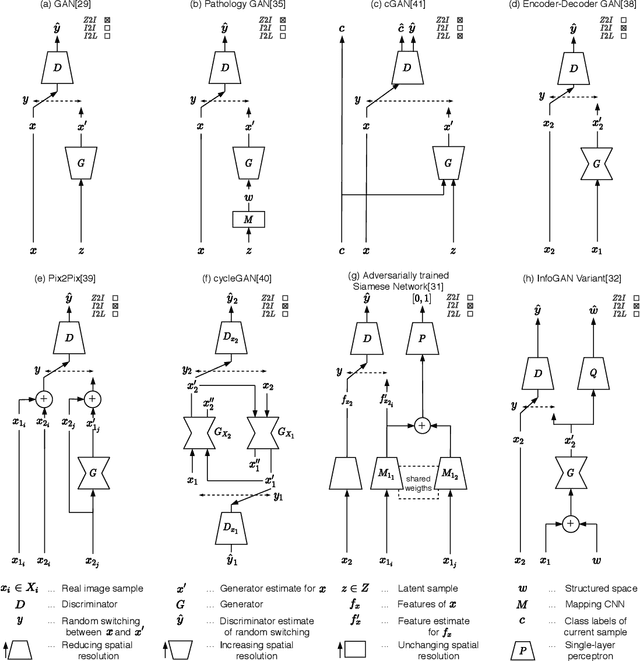
Image analysis in the field of digital pathology has recently gained increased popularity. The use of high-quality whole slide scanners enables the fast acquisition of large amounts of image data, showing extensive context and microscopic detail at the same time. Simultaneously, novel machine learning algorithms have boosted the performance of image analysis approaches. In this paper, we focus on a particularly powerful class of architectures, called Generative Adversarial Networks (GANs), applied to histological image data. Besides improving performance, GANs also enable application scenarios in this field, which were previously intractable. However, GANs could exhibit a potential for introducing bias. Hereby, we summarize the recent state-of-the-art developments in a generalizing notation, present the main applications of GANs and give an outlook of some chosen promising approaches and their possible future applications. In addition, we identify currently unavailable methods with potential for future applications.
STAIR Captions: Constructing a Large-Scale Japanese Image Caption Dataset
May 02, 2017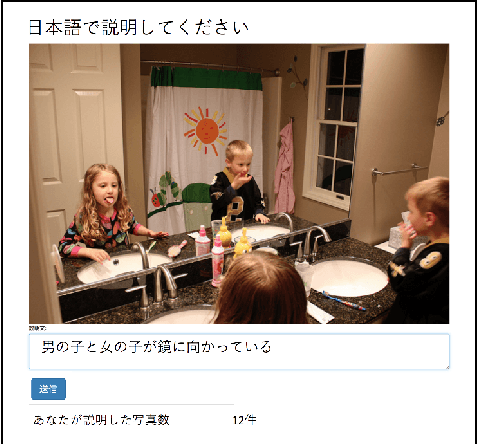



In recent years, automatic generation of image descriptions (captions), that is, image captioning, has attracted a great deal of attention. In this paper, we particularly consider generating Japanese captions for images. Since most available caption datasets have been constructed for English language, there are few datasets for Japanese. To tackle this problem, we construct a large-scale Japanese image caption dataset based on images from MS-COCO, which is called STAIR Captions. STAIR Captions consists of 820,310 Japanese captions for 164,062 images. In the experiment, we show that a neural network trained using STAIR Captions can generate more natural and better Japanese captions, compared to those generated using English-Japanese machine translation after generating English captions.
Instance-aware Image and Sentence Matching with Selective Multimodal LSTM
Nov 17, 2016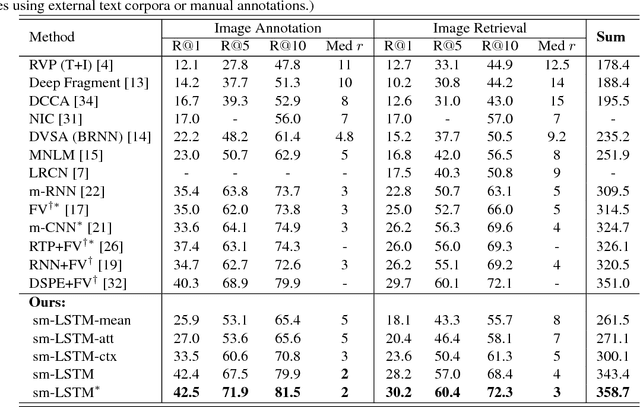
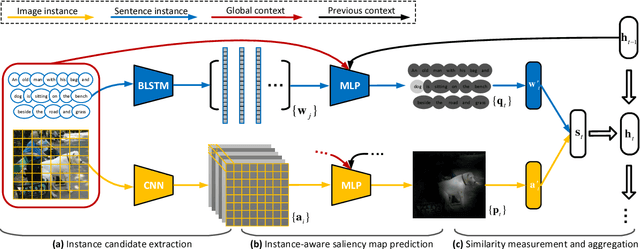
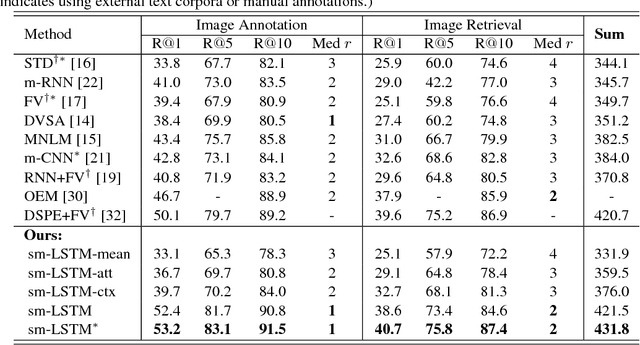
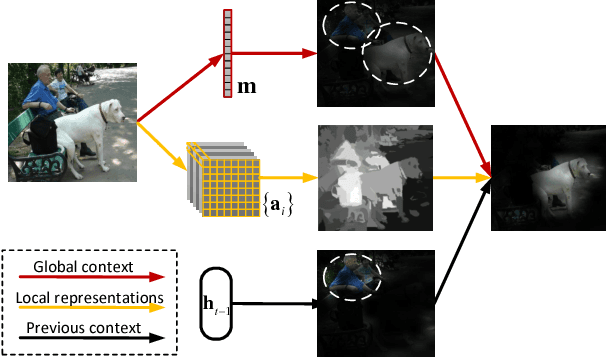
Effective image and sentence matching depends on how to well measure their global visual-semantic similarity. Based on the observation that such a global similarity arises from a complex aggregation of multiple local similarities between pairwise instances of image (objects) and sentence (words), we propose a selective multimodal Long Short-Term Memory network (sm-LSTM) for instance-aware image and sentence matching. The sm-LSTM includes a multimodal context-modulated attention scheme at each timestep that can selectively attend to a pair of instances of image and sentence, by predicting pairwise instance-aware saliency maps for image and sentence. For selected pairwise instances, their representations are obtained based on the predicted saliency maps, and then compared to measure their local similarity. By similarly measuring multiple local similarities within a few timesteps, the sm-LSTM sequentially aggregates them with hidden states to obtain a final matching score as the desired global similarity. Extensive experiments show that our model can well match image and sentence with complex content, and achieve the state-of-the-art results on two public benchmark datasets.
Federated Learning over Wireless Device-to-Device Networks: Algorithms and Convergence Analysis
Jan 29, 2021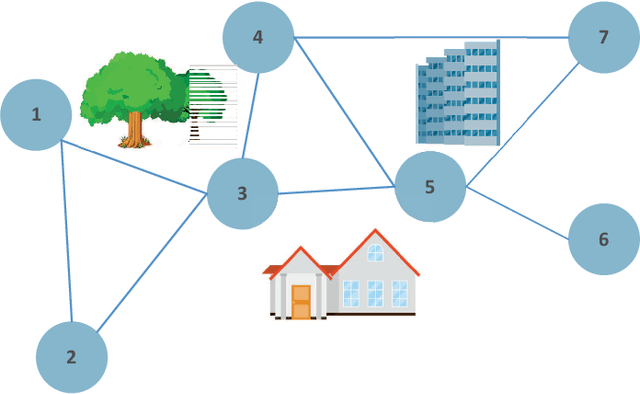
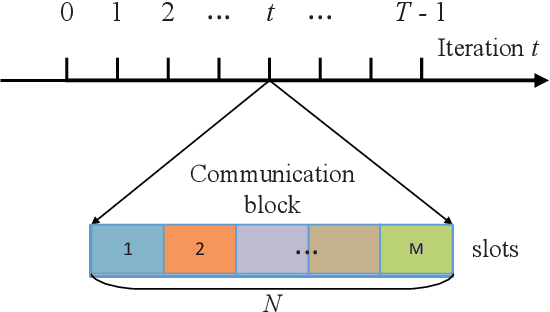
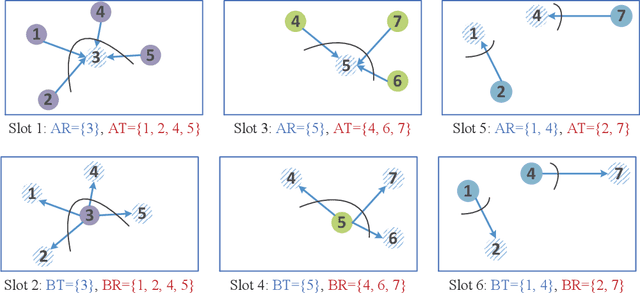
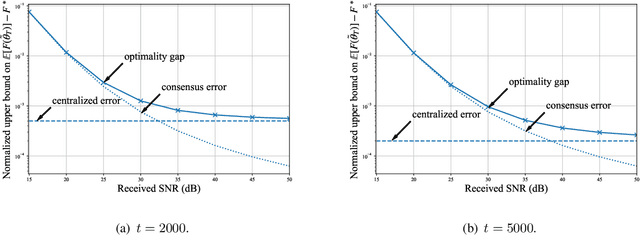
The proliferation of Internet-of-Things (IoT) devices and cloud-computing applications over siloed data centers is motivating renewed interest in the collaborative training of a shared model by multiple individual clients via federated learning (FL). To improve the communication efficiency of FL implementations in wireless systems, recent works have proposed compression and dimension reduction mechanisms, along with digital and analog transmission schemes that account for channel noise, fading, and interference. This prior art has mainly focused on star topologies consisting of distributed clients and a central server. In contrast, this paper studies FL over wireless device-to-device (D2D) networks by providing theoretical insights into the performance of digital and analog implementations of decentralized stochastic gradient descent (DSGD). First, we introduce generic digital and analog wireless implementations of communication-efficient DSGD algorithms, leveraging random linear coding (RLC) for compression and over-the-air computation (AirComp) for simultaneous analog transmissions. Next, under the assumptions of convexity and connectivity, we provide convergence bounds for both implementations. The results demonstrate the dependence of the optimality gap on the connectivity and on the signal-to-noise ratio (SNR) levels in the network. The analysis is corroborated by experiments on an image-classification task.
BubbleView: an interface for crowdsourcing image importance maps and tracking visual attention
Aug 09, 2017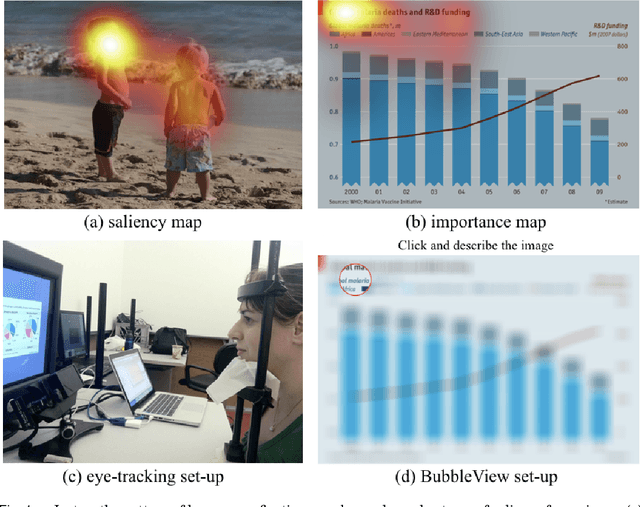
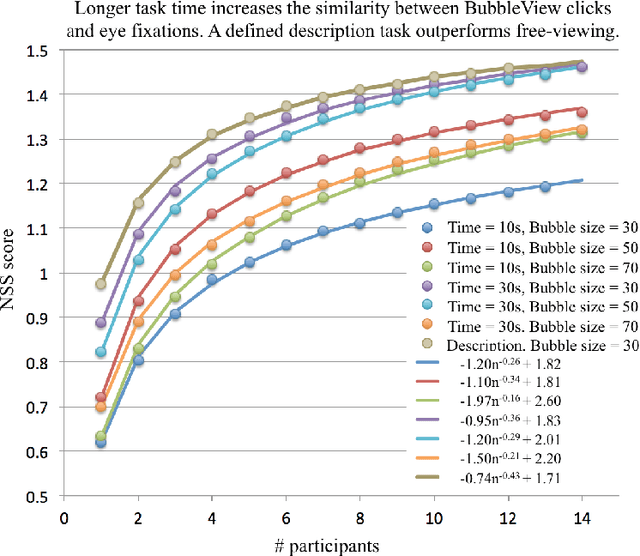

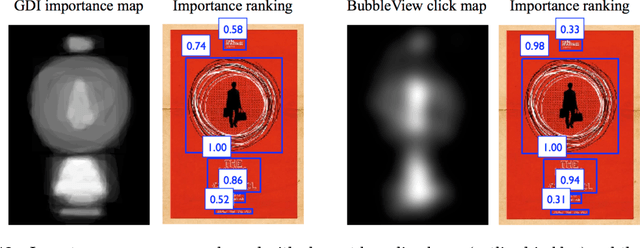
In this paper, we present BubbleView, an alternative methodology for eye tracking using discrete mouse clicks to measure which information people consciously choose to examine. BubbleView is a mouse-contingent, moving-window interface in which participants are presented with a series of blurred images and click to reveal "bubbles" - small, circular areas of the image at original resolution, similar to having a confined area of focus like the eye fovea. Across 10 experiments with 28 different parameter combinations, we evaluated BubbleView on a variety of image types: information visualizations, natural images, static webpages, and graphic designs, and compared the clicks to eye fixations collected with eye-trackers in controlled lab settings. We found that BubbleView clicks can both (i) successfully approximate eye fixations on different images, and (ii) be used to rank image and design elements by importance. BubbleView is designed to collect clicks on static images, and works best for defined tasks such as describing the content of an information visualization or measuring image importance. BubbleView data is cleaner and more consistent than related methodologies that use continuous mouse movements. Our analyses validate the use of mouse-contingent, moving-window methodologies as approximating eye fixations for different image and task types.