 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeiSeeBetter: Spatio-temporal video super-resolution using recurrent generative back-projection networks
Jun 22, 2020
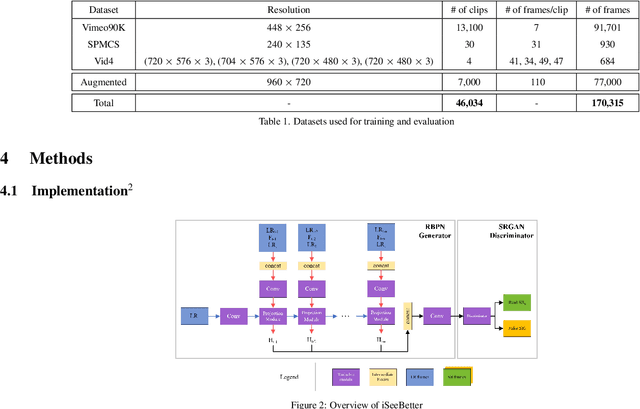
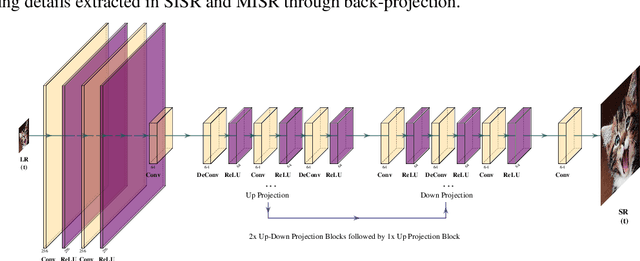
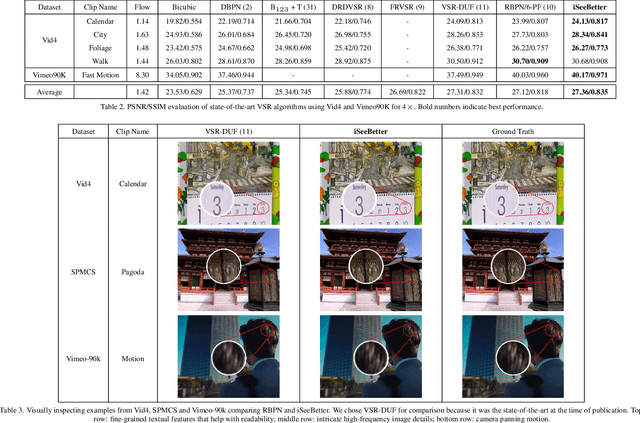
Recently, learning-based models have enhanced the performance of single-image super-resolution (SISR). However, applying SISR successively to each video frame leads to a lack of temporal coherency. Convolutional neural networks (CNNs) outperform traditional approaches in terms of image quality metrics such as peak signal to noise ratio (PSNR) and structural similarity (SSIM). However, generative adversarial networks (GANs) offer a competitive advantage by being able to mitigate the issue of a lack of finer texture details, usually seen with CNNs when super-resolving at large upscaling factors. We present iSeeBetter, a novel GAN-based spatio-temporal approach to video super-resolution (VSR) that renders temporally consistent super-resolution videos. iSeeBetter extracts spatial and temporal information from the current and neighboring frames using the concept of recurrent back-projection networks as its generator. Furthermore, to improve the "naturality" of the super-resolved image while eliminating artifacts seen with traditional algorithms, we utilize the discriminator from super-resolution generative adversarial network (SRGAN). Although mean squared error (MSE) as a primary loss-minimization objective improves PSNR/SSIM, these metrics may not capture fine details in the image resulting in misrepresentation of perceptual quality. To address this, we use a four-fold (MSE, perceptual, adversarial, and total-variation (TV)) loss function. Our results demonstrate that iSeeBetter offers superior VSR fidelity and surpasses state-of-the-art performance.
* 11 pages, 6 figures, 4 tables
Face Recognition Using Discrete Cosine Transform for Global and Local Features
Nov 06, 2011
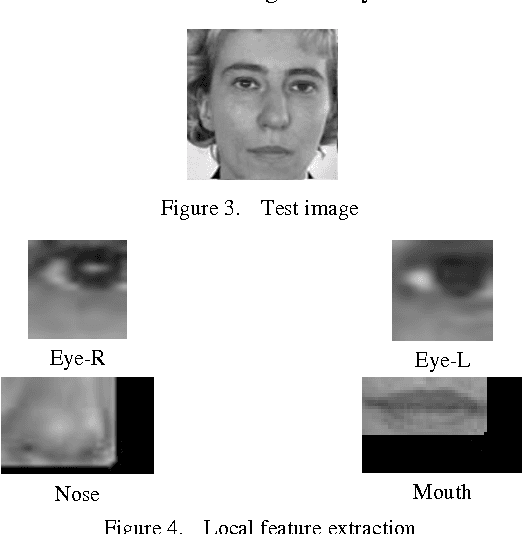


Face Recognition using Discrete Cosine Transform (DCT) for Local and Global Features involves recognizing the corresponding face image from the database. The face image obtained from the user is cropped such that only the frontal face image is extracted, eliminating the background. The image is restricted to a size of 128 x 128 pixels. All images in the database are gray level images. DCT is applied to the entire image. This gives DCT coefficients, which are global features. Local features such as eyes, nose and mouth are also extracted and DCT is applied to these features. Depending upon the recognition rate obtained for each feature, they are given weightage and then combined. Both local and global features are used for comparison. By comparing the ranks for global and local features, the false acceptance rate for DCT can be minimized.
A robust, low-cost approach to Face Detection and Face Recognition
Nov 04, 2011



In the domain of Biometrics, recognition systems based on iris, fingerprint or palm print scans etc. are often considered more dependable due to extremely low variance in the properties of these entities with respect to time. However, over the last decade data processing capability of computers has increased manifold, which has made real-time video content analysis possible. This shows that the need of the hour is a robust and highly automated Face Detection and Recognition algorithm with credible accuracy rate. The proposed Face Detection and Recognition system using Discrete Wavelet Transform (DWT) accepts face frames as input from a database containing images from low cost devices such as VGA cameras, webcams or even CCTV's, where image quality is inferior. Face region is then detected using properties of L*a*b* color space and only Frontal Face is extracted such that all additional background is eliminated. Further, this extracted image is converted to grayscale and its dimensions are resized to 128 x 128 pixels. DWT is then applied to entire image to obtain the coefficients. Recognition is carried out by comparison of the DWT coefficients belonging to the test image with those of the registered reference image. On comparison, Euclidean distance classifier is deployed to validate the test image from the database. Accuracy for various levels of DWT Decomposition is obtained and hence, compared.
* discrete wavelet transform, face detection, face recognition, person identification
Text-Independent Speaker Recognition for Low SNR Environments with Encryption
Oct 31, 2011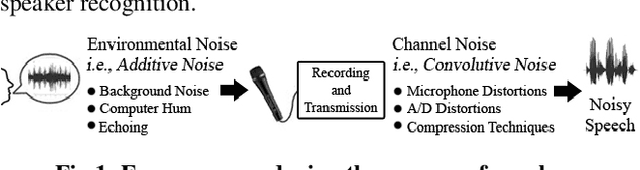


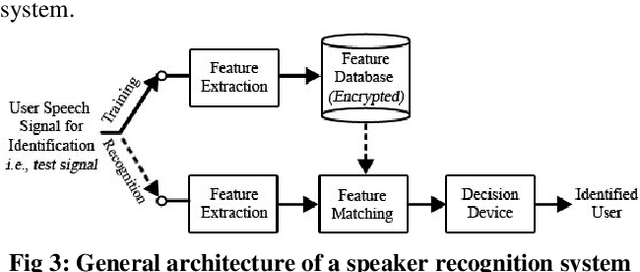
Recognition systems are commonly designed to authenticate users at the access control levels of a system. A number of voice recognition methods have been developed using a pitch estimation process which are very vulnerable in low Signal to Noise Ratio (SNR) environments thus, these programs fail to provide the desired level of accuracy and robustness. Also, most text independent speaker recognition programs are incapable of coping with unauthorized attempts to gain access by tampering with the samples or reference database. The proposed text-independent voice recognition system makes use of multilevel cryptography to preserve data integrity while in transit or storage. Encryption and decryption follow a transform based approach layered with pseudorandom noise addition whereas for pitch detection, a modified version of the autocorrelation pitch extraction algorithm is used. The experimental results show that the proposed algorithm can decrypt the signal under test with exponentially reducing Mean Square Error over an increasing range of SNR. Further, it outperforms the conventional algorithms in actual identification tasks even in noisy environments. The recognition rate thus obtained using the proposed method is compared with other conventional methods used for speaker identification.
* Biometrics, Pattern Recognition, Security, Speaker Individuality, Text-independence, Pitch Extraction, Voice Recognition, Autocorrelation; Published by Foundation of Computer Science, New York, USA
Rotation, Scaling and Translation Analysis of Biometric Signature Templates
Oct 06, 2011


Biometric authentication systems that make use of signature verification methods often render optimum performance only under limited and restricted conditions. Such methods utilize several training samples so as to achieve high accuracy. Moreover, several constraints are imposed on the end-user so that the system may work optimally, and as expected. For example, the user is made to sign within a small box, in order to limit their signature to a predefined set of dimensions, thus eliminating scaling. Moreover, the angular rotation with respect to the referenced signature that will be inadvertently introduced as human error, hampers performance of biometric signature verification systems. To eliminate this, traditionally, a user is asked to sign exactly on top of a reference line. In this paper, we propose a robust system that optimizes the signature obtained from the user for a large range of variation in Rotation-Scaling-Translation (RST) and resolves these error parameters in the user signature according to the reference signature stored in the database.
* rotation; scaling; translation; RST; image registration; signature verification