 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Worsening Perception: Real-time Degradation of Autonomous Vehicle Perception Performance for Simulation of Adverse Weather Conditions
Mar 03, 2021
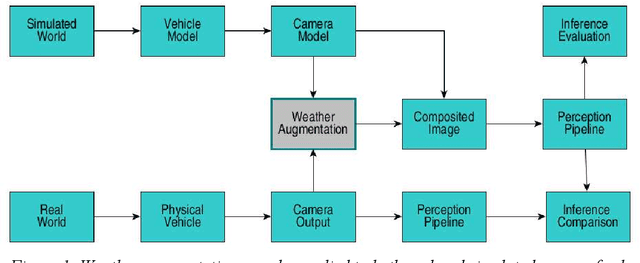


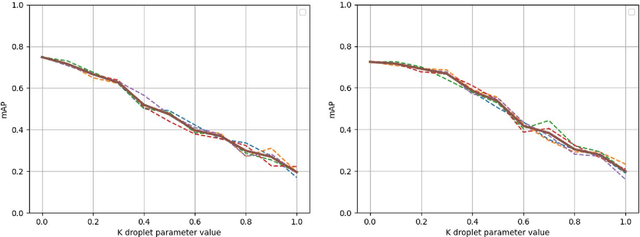
Autonomous vehicles rely heavily upon their perception subsystems to see the environment in which they operate. Unfortunately, the effect of varying weather conditions presents a significant challenge to object detection algorithms, and thus it is imperative to test the vehicle extensively in all conditions which it may experience. However, unpredictable weather can make real-world testing in adverse conditions an expensive and time consuming task requiring access to specialist facilities, and weatherproofing of sensitive electronics. Simulation provides an alternative to real world testing, with some studies developing increasingly visually realistic representations of the real world on powerful compute hardware. Given that subsequent subsystems in the autonomous vehicle pipeline are unaware of the visual realism of the simulation, when developing modules downstream of perception the appearance is of little consequence - rather it is how the perception system performs in the prevailing weather condition that is important. This study explores the potential of using a simple, lightweight image augmentation system in an autonomous racing vehicle - focusing not on visual accuracy, but rather the effect upon perception system performance. With minimal adjustment, the prototype system developed in this study can replicate the effects of both water droplets on the camera lens, and fading light conditions. The system introduces a latency of less than 8 ms using compute hardware that is well suited to being carried in the vehicle - rendering it ideally suited to real-time implementation that can be run during experiments in simulation, and augmented reality testing in the real world.
Boosting High-Level Vision with Joint Compression Artifacts Reduction and Super-Resolution
Oct 18, 2020
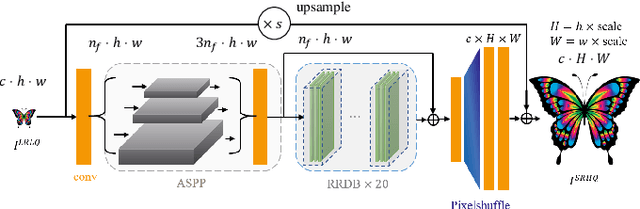
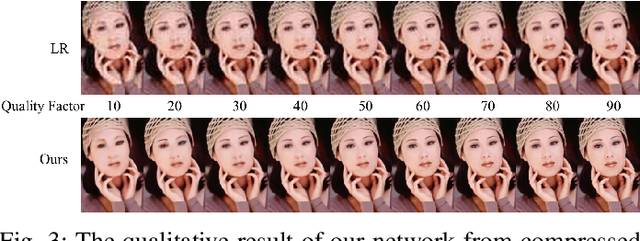

Due to the limits of bandwidth and storage space, digital images are usually down-scaled and compressed when transmitted over networks, resulting in loss of details and jarring artifacts that can lower the performance of high-level visual tasks. In this paper, we aim to generate an artifact-free high-resolution image from a low-resolution one compressed with an arbitrary quality factor by exploring joint compression artifacts reduction (CAR) and super-resolution (SR) tasks. First, we propose a context-aware joint CAR and SR neural network (CAJNN) that integrates both local and non-local features to solve CAR and SR in one-stage. Finally, a deep reconstruction network is adopted to predict high quality and high-resolution images. Evaluation on CAR and SR benchmark datasets shows that our CAJNN model outperforms previous methods and also takes 26.2% shorter runtime. Based on this model, we explore addressing two critical challenges in high-level computer vision: optical character recognition of low-resolution texts, and extremely tiny face detection. We demonstrate that CAJNN can serve as an effective image preprocessing method and improve the accuracy for real-scene text recognition (from 85.30% to 85.75%) and the average precision for tiny face detection (from 0.317 to 0.611).
ICAM: Interpretable Classification via Disentangled Representations and Feature Attribution Mapping
Jun 15, 2020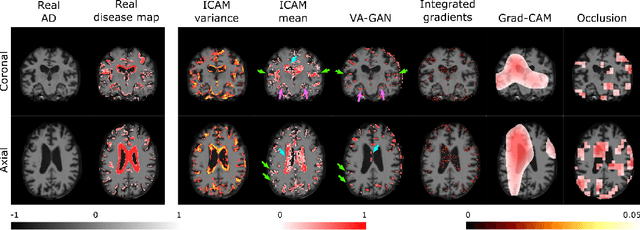

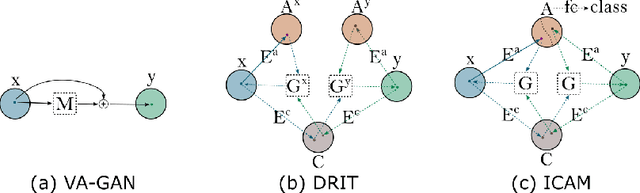
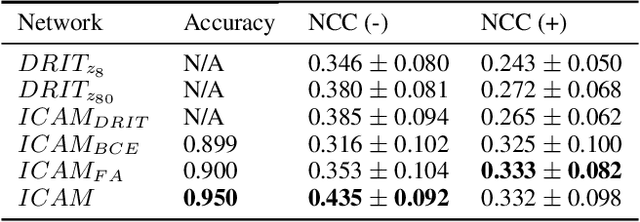
Feature attribution (FA), or the assignment of class-relevance to different locations in an image, is important for many classification problems but is particularly crucial within the neuroscience domain, where accurate mechanistic models of behaviours, or disease, require knowledge of all features discriminative of a trait. At the same time, predicting class relevance from brain images is challenging as phenotypes are typically heterogeneous, and changes occur against a background of significant natural variation. Here, we present a novel framework for creating class specific FA maps through image-to-image translation. We propose the use of a VAE-GAN to explicitly disentangle class relevance from background features for improved interpretability properties, which results in meaningful FA maps. We validate our method on 2D and 3D brain image datasets of dementia (ADNI dataset), ageing (UK Biobank), and (simulated) lesion detection. We show that FA maps generated by our method outperform baseline FA methods when validated against ground truth. More significantly, our approach is the first to use latent space sampling to support exploration of phenotype variation. Our code will be available online at https://github.com/CherBass/ICAM .
Learning Spatial Attention for Face Super-Resolution
Dec 02, 2020
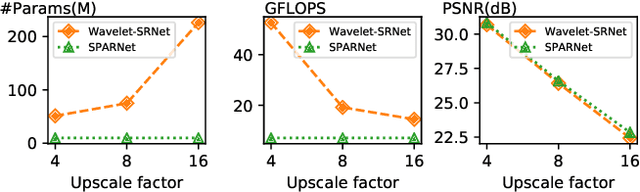
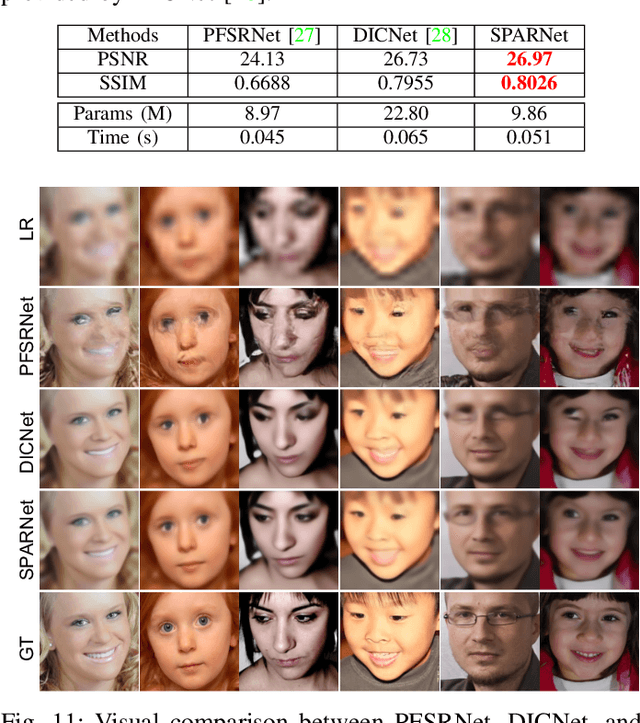

General image super-resolution techniques have difficulties in recovering detailed face structures when applying to low resolution face images. Recent deep learning based methods tailored for face images have achieved improved performance by jointly trained with additional task such as face parsing and landmark prediction. However, multi-task learning requires extra manually labeled data. Besides, most of the existing works can only generate relatively low resolution face images (e.g., $128\times128$), and their applications are therefore limited. In this paper, we introduce a novel SPatial Attention Residual Network (SPARNet) built on our newly proposed Face Attention Units (FAUs) for face super-resolution. Specifically, we introduce a spatial attention mechanism to the vanilla residual blocks. This enables the convolutional layers to adaptively bootstrap features related to the key face structures and pay less attention to those less feature-rich regions. This makes the training more effective and efficient as the key face structures only account for a very small portion of the face image. Visualization of the attention maps shows that our spatial attention network can capture the key face structures well even for very low resolution faces (e.g., $16\times16$). Quantitative comparisons on various kinds of metrics (including PSNR, SSIM, identity similarity, and landmark detection) demonstrate the superiority of our method over current state-of-the-arts. We further extend SPARNet with multi-scale discriminators, named as SPARNetHD, to produce high resolution results (i.e., $512\times512$). We show that SPARNetHD trained with synthetic data cannot only produce high quality and high resolution outputs for synthetically degraded face images, but also show good generalization ability to real world low quality face images. Codes are available at \url{https://github.com/chaofengc/Face-SPARNet}.
Regularization-Agnostic Compressed Sensing MRI Reconstruction with Hypernetworks
Jan 06, 2021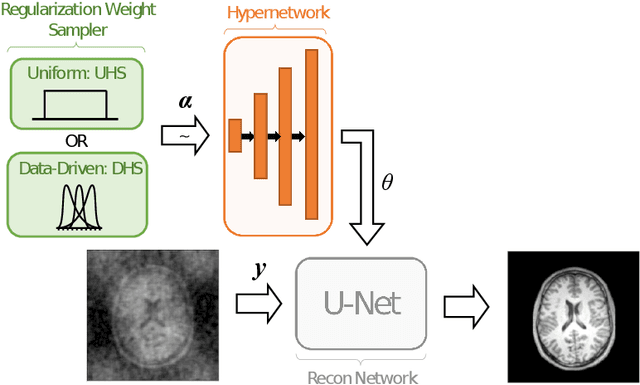


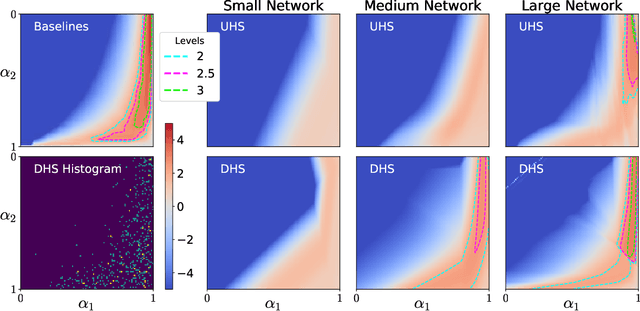
Reconstructing under-sampled k-space measurements in Compressed Sensing MRI (CS-MRI) is classically solved with regularized least-squares. Recently, deep learning has been used to amortize this optimization by training reconstruction networks on a dataset of under-sampled measurements. Here, a crucial design choice is the regularization function(s) and corresponding weight(s). In this paper, we explore a novel strategy of using a hypernetwork to generate the parameters of a separate reconstruction network as a function of the regularization weight(s), resulting in a regularization-agnostic reconstruction model. At test time, for a given under-sampled image, our model can rapidly compute reconstructions with different amounts of regularization. We analyze the variability of these reconstructions, especially in situations when the overall quality is similar. Finally, we propose and empirically demonstrate an efficient and data-driven way of maximizing reconstruction performance given limited hypernetwork capacity. Our code is publicly available at https://github.com/alanqrwang/RegAgnosticCSMRI.
A Global to Local Double Embedding Method for Multi-person Pose Estimation
Feb 16, 2021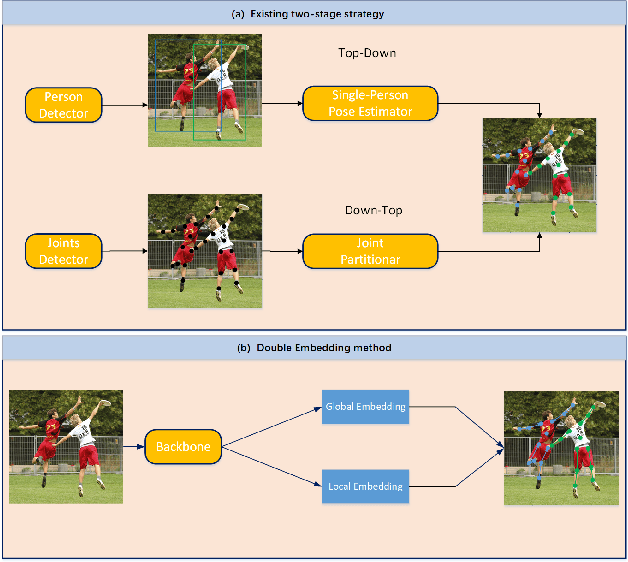
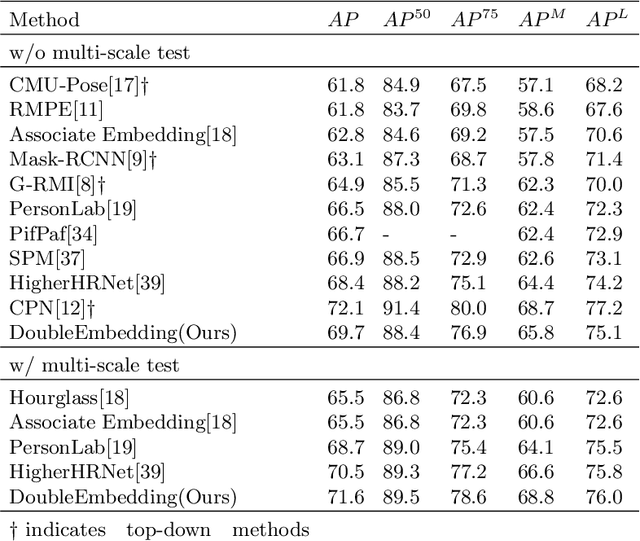
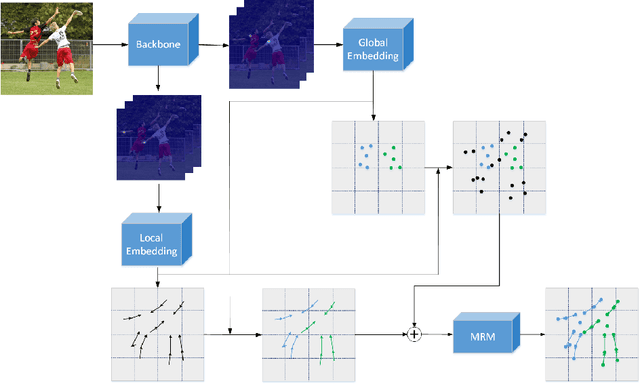
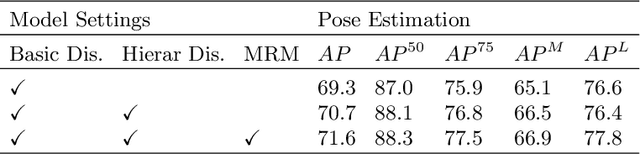
Multi-person pose estimation is a fundamental and challenging problem to many computer vision tasks. Most existing methods can be broadly categorized into two classes: top-down and bottom-up methods. Both of the two types of methods involve two stages, namely, person detection and joints detection. Conventionally, the two stages are implemented separately without considering their interactions between them, and this may inevitably cause some issue intrinsically. In this paper, we present a novel method to simplify the pipeline by implementing person detection and joints detection simultaneously. We propose a Double Embedding (DE) method to complete the multi-person pose estimation task in a global-to-local way. DE consists of Global Embedding (GE) and Local Embedding (LE). GE encodes different person instances and processes information covering the whole image and LE encodes the local limbs information. GE functions for the person detection in top-down strategy while LE connects the rest joints sequentially which functions for joint grouping and information processing in A bottom-up strategy. Based on LE, we design the Mutual Refine Machine (MRM) to reduce the prediction difficulty in complex scenarios. MRM can effectively realize the information communicating between keypoints and further improve the accuracy. We achieve the competitive results on benchmarks MSCOCO, MPII and CrowdPose, demonstrating the effectiveness and generalization ability of our method.
Fighting Deepfake by Exposing the Convolutional Traces on Images
Aug 07, 2020
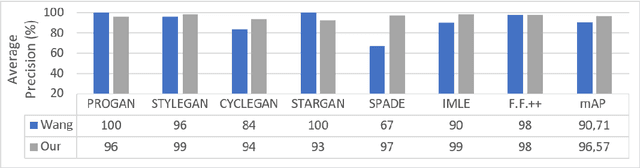
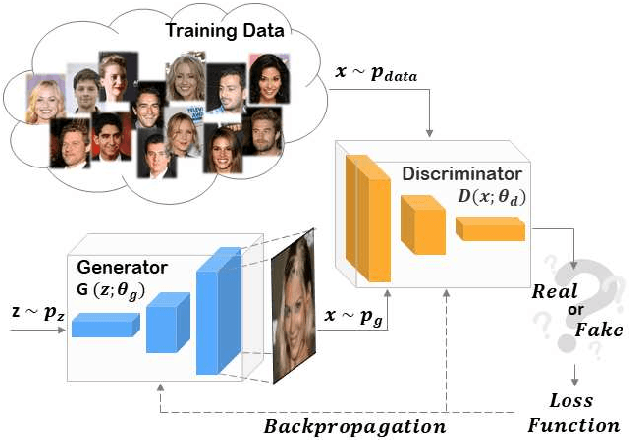

Advances in Artificial Intelligence and Image Processing are changing the way people interacts with digital images and video. Widespread mobile apps like FACEAPP make use of the most advanced Generative Adversarial Networks (GAN) to produce extreme transformations on human face photos such gender swap, aging, etc. The results are utterly realistic and extremely easy to be exploited even for non-experienced users. This kind of media object took the name of Deepfake and raised a new challenge in the multimedia forensics field: the Deepfake detection challenge. Indeed, discriminating a Deepfake from a real image could be a difficult task even for human eyes but recent works are trying to apply the same technology used for generating images for discriminating them with preliminary good results but with many limitations: employed Convolutional Neural Networks are not so robust, demonstrate to be specific to the context and tend to extract semantics from images. In this paper, a new approach aimed to extract a Deepfake fingerprint from images is proposed. The method is based on the Expectation-Maximization algorithm trained to detect and extract a fingerprint that represents the Convolutional Traces (CT) left by GANs during image generation. The CT demonstrates to have high discriminative power achieving better results than state-of-the-art in the Deepfake detection task also proving to be robust to different attacks. Achieving an overall classification accuracy of over 98%, considering Deepfakes from 10 different GAN architectures not only involved in images of faces, the CT demonstrates to be reliable and without any dependence on image semantic. Finally, tests carried out on Deepfakes generated by FACEAPP achieving 93% of accuracy in the fake detection task, demonstrated the effectiveness of the proposed technique on a real-case scenario.
Adversarial Imaging Pipelines
Feb 07, 2021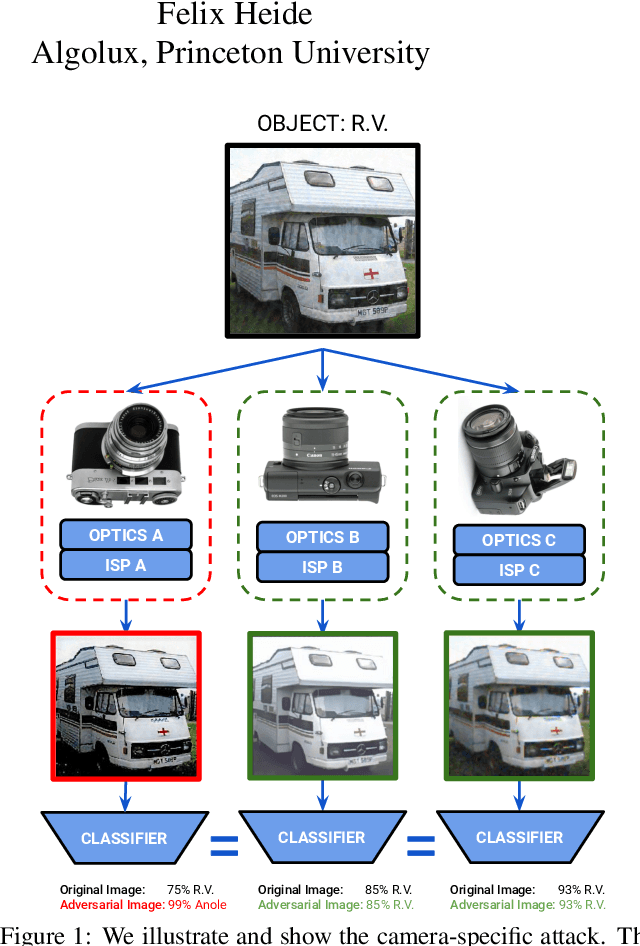
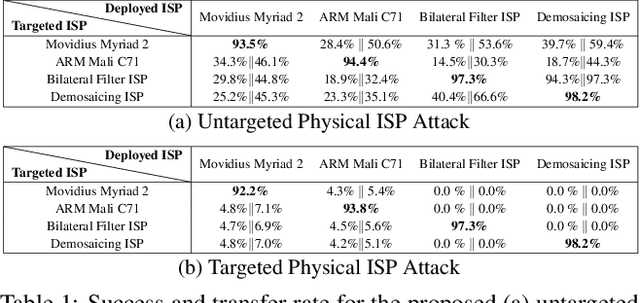
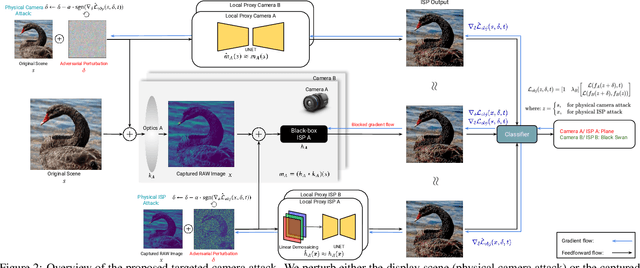
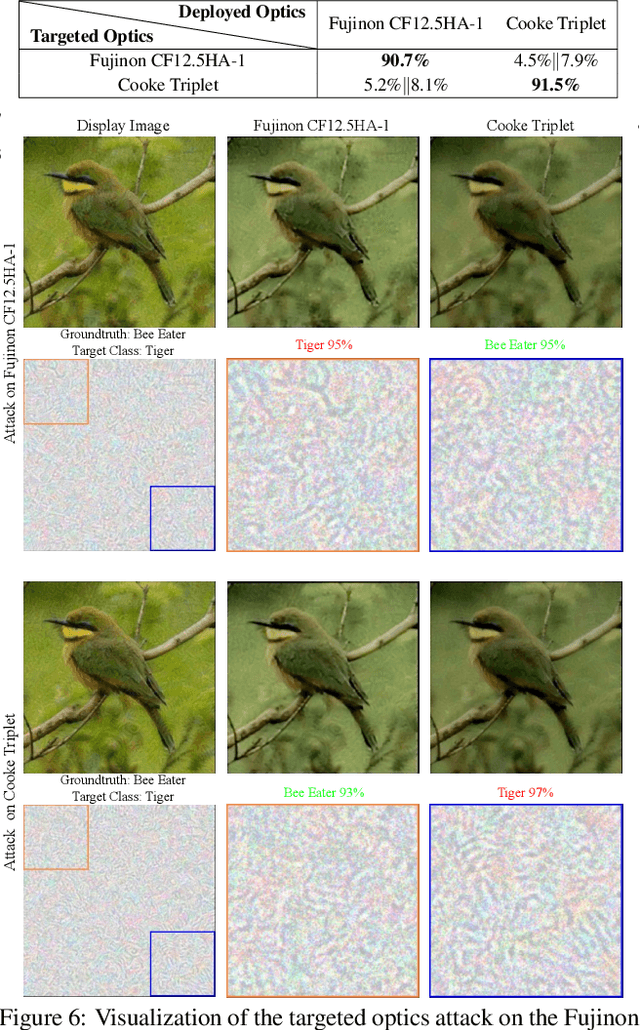
Adversarial attacks play an essential role in understanding deep neural network predictions and improving their robustness. Existing attack methods aim to deceive convolutional neural network (CNN)-based classifiers by manipulating RGB images that are fed directly to the classifiers. However, these approaches typically neglect the influence of the camera optics and image processing pipeline (ISP) that produce the network inputs. ISPs transform RAW measurements to RGB images and traditionally are assumed to preserve adversarial patterns. However, these low-level pipelines can, in fact, destroy, introduce or amplify adversarial patterns that can deceive a downstream detector. As a result, optimized patterns can become adversarial for the classifier after being transformed by a certain camera ISP and optic but not for others. In this work, we examine and develop such an attack that deceives a specific camera ISP while leaving others intact, using the same down-stream classifier. We frame camera-specific attacks as a multi-task optimization problem, relying on a differentiable approximation for the ISP itself. We validate the proposed method using recent state-of-the-art automotive hardware ISPs, achieving 92% fooling rate when attacking a specific ISP. We demonstrate physical optics attacks with 90% fooling rate for a specific camera lenses.
A Neural Few-Shot Text Classification Reality Check
Jan 28, 2021Modern classification models tend to struggle when the amount of annotated data is scarce. To overcome this issue, several neural few-shot classification models have emerged, yielding significant progress over time, both in Computer Vision and Natural Language Processing. In the latter, such models used to rely on fixed word embeddings before the advent of transformers. Additionally, some models used in Computer Vision are yet to be tested in NLP applications. In this paper, we compare all these models, first adapting those made in the field of image processing to NLP, and second providing them access to transformers. We then test these models equipped with the same transformer-based encoder on the intent detection task, known for having a large number of classes. Our results reveal that while methods perform almost equally on the ARSC dataset, this is not the case for the Intent Detection task, where the most recent and supposedly best competitors perform worse than older and simpler ones (while all are given access to transformers). We also show that a simple baseline is surprisingly strong. All the new developed models, as well as the evaluation framework, are made publicly available.
Quantization of Fully Convolutional Networks for Accurate Biomedical Image Segmentation
Mar 13, 2018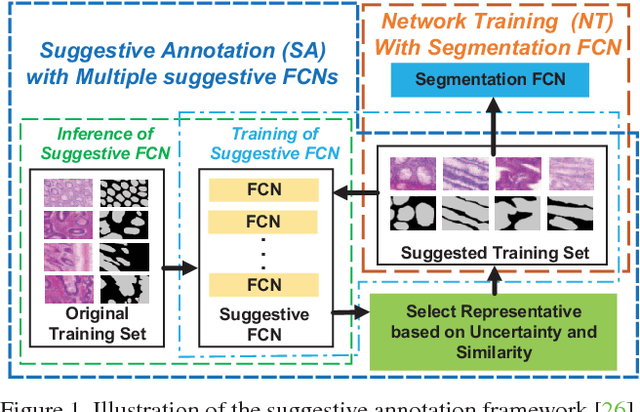
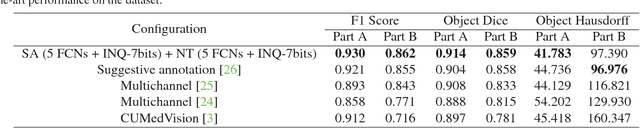
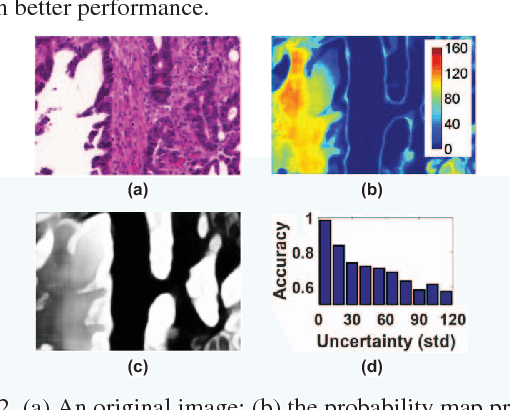
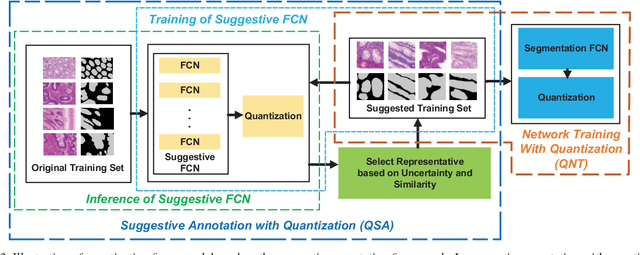
With pervasive applications of medical imaging in health-care, biomedical image segmentation plays a central role in quantitative analysis, clinical diagno- sis, and medical intervention. Since manual anno- tation su ers limited reproducibility, arduous e orts, and excessive time, automatic segmentation is desired to process increasingly larger scale histopathological data. Recently, deep neural networks (DNNs), par- ticularly fully convolutional networks (FCNs), have been widely applied to biomedical image segmenta- tion, attaining much improved performance. At the same time, quantization of DNNs has become an ac- tive research topic, which aims to represent weights with less memory (precision) to considerably reduce memory and computation requirements of DNNs while maintaining acceptable accuracy. In this paper, we apply quantization techniques to FCNs for accurate biomedical image segmentation. Unlike existing litera- ture on quantization which primarily targets memory and computation complexity reduction, we apply quan- tization as a method to reduce over tting in FCNs for better accuracy. Speci cally, we focus on a state-of- the-art segmentation framework, suggestive annotation [22], which judiciously extracts representative annota- tion samples from the original training dataset, obtain- ing an e ective small-sized balanced training dataset. We develop two new quantization processes for this framework: (1) suggestive annotation with quantiza- tion for highly representative training samples, and (2) network training with quantization for high accuracy. Extensive experiments on the MICCAI Gland dataset show that both quantization processes can improve the segmentation performance, and our proposed method exceeds the current state-of-the-art performance by up to 1%. In addition, our method has a reduction of up to 6.4x on memory usage.