 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Demonstrating the Evolution of GANs through t-SNE
Jan 31, 2021
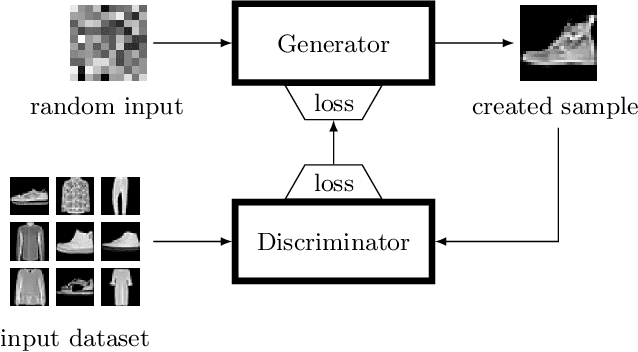
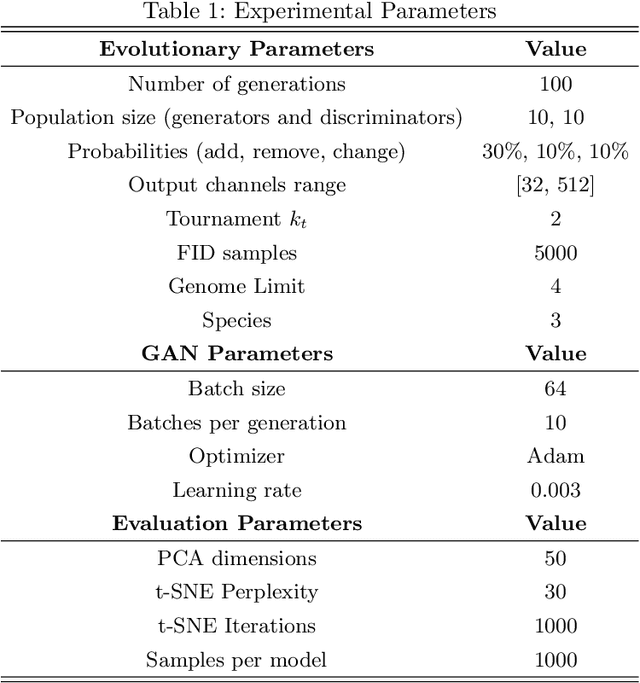
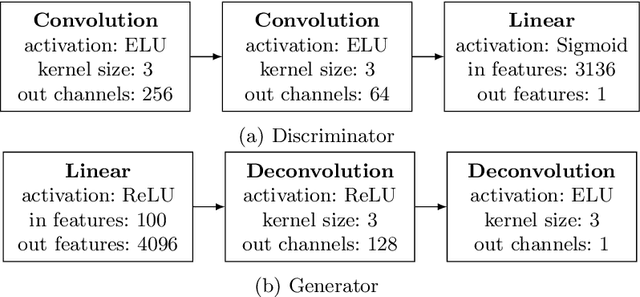
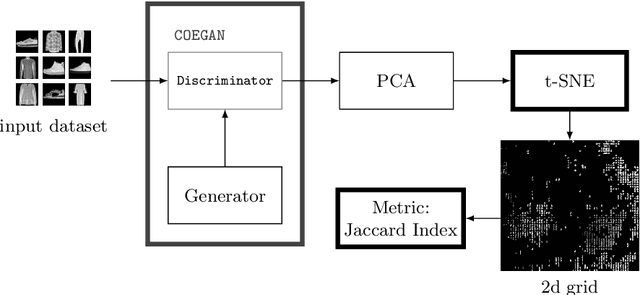
Generative Adversarial Networks (GANs) are powerful generative models that achieved strong results, mainly in the image domain. However, the training of GANs is not trivial, presenting some challenges tackled by different strategies. Evolutionary algorithms, such as COEGAN, were recently proposed as a solution to improve the GAN training, overcoming common problems that affect the model, such as vanishing gradient and mode collapse. In this work, we propose an evaluation method based on t-distributed Stochastic Neighbour Embedding (t-SNE) to assess the progress of GANs and visualize the distribution learned by generators in training. We propose the use of the feature space extracted from trained discriminators to evaluate samples produced by generators and from the input dataset. A metric based on the resulting t-SNE maps and the Jaccard index is proposed to represent the model quality. Experiments were conducted to assess the progress of GANs when trained using COEGAN. The results show both by visual inspection and metrics that the Evolutionary Algorithm gradually improves discriminators and generators through generations, avoiding problems such as mode collapse.
Object Detection for Understanding Assembly Instruction Using Context-aware Data Augmentation and Cascade Mask R-CNN
Jan 08, 2021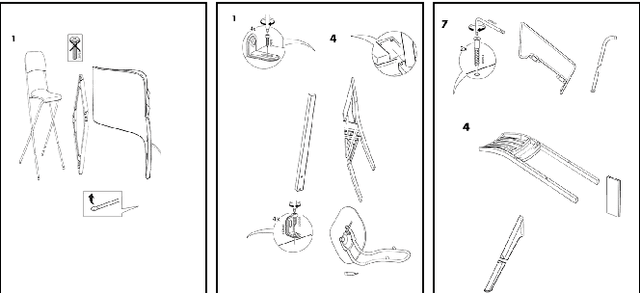

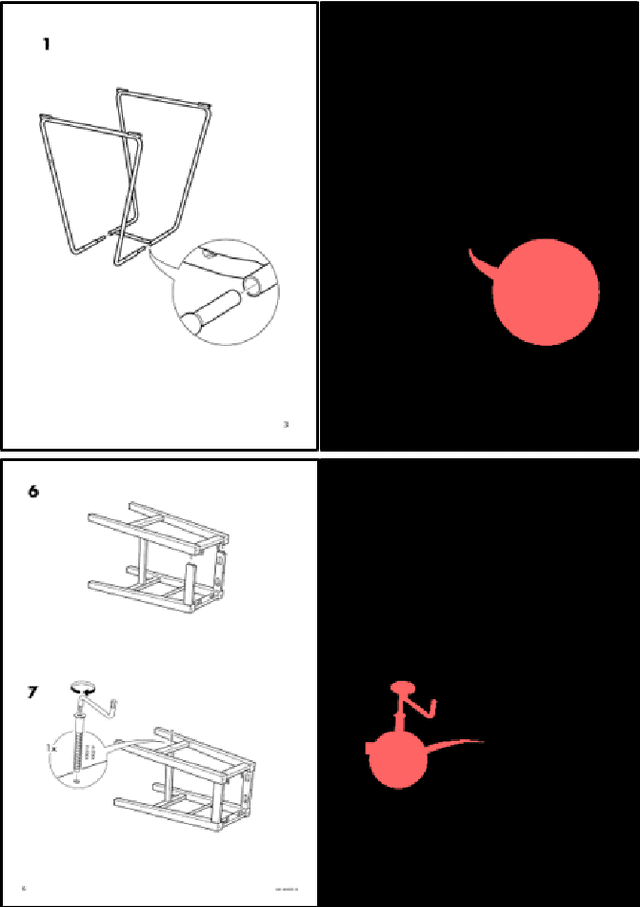
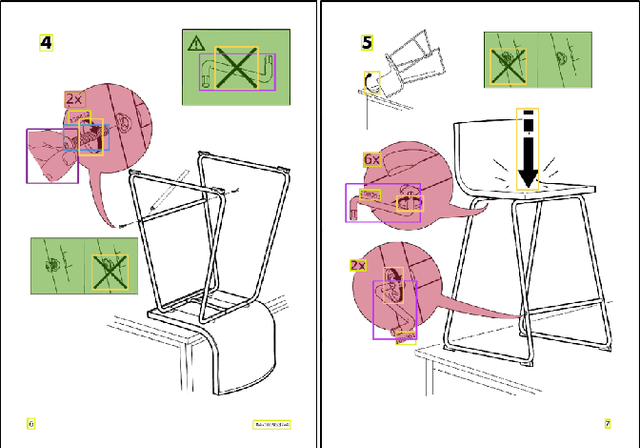
Understanding assembly instruction has the potential to enhance the robot s task planning ability and enables advanced robotic applications. To recognize the key components from the 2D assembly instruction image, We mainly focus on segmenting the speech bubble area, which contains lots of information about instructions. For this, We applied Cascade Mask R-CNN and developed a context-aware data augmentation scheme for speech bubble segmentation, which randomly combines images cuts by considering the context of assembly instructions. We showed that the proposed augmentation scheme achieves a better segmentation performance compared to the existing augmentation algorithm by increasing the diversity of trainable data while considering the distribution of components locations. Also, we showed that deep learning can be useful to understand assembly instruction by detecting the essential objects in the assembly instruction, such as tools and parts.
A Fast 3D CNN for Hyperspectral Image Classification
Apr 29, 2020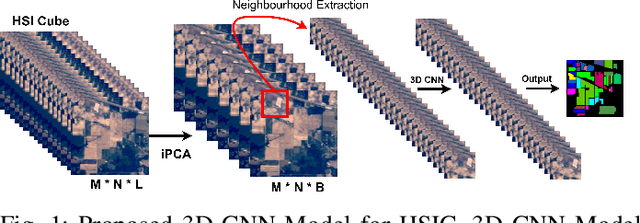

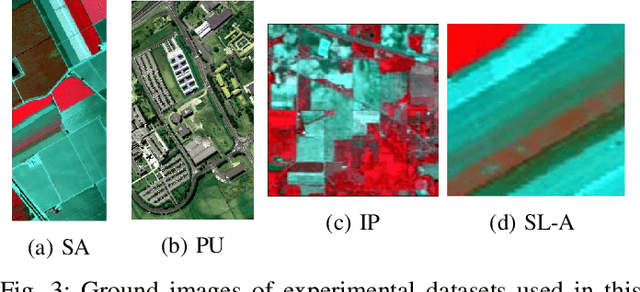
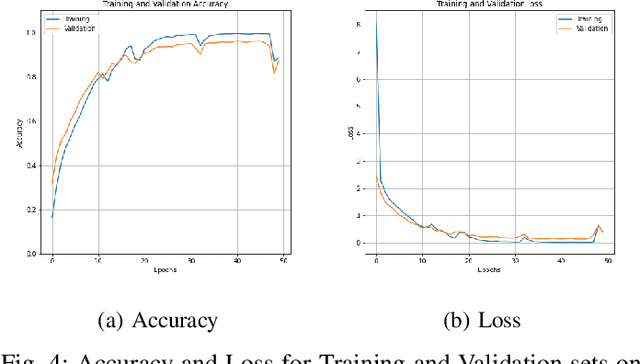
Hyperspectral imaging (HSI) has been extensively utilized for a number of real-world applications. HSI classification (HSIC) is a challenging task due to high inter-class similarity, high intra-class variability, overlapping, and nested regions. A 2D Convolutional Neural Network (CNN) is a viable approach whereby HSIC highly depends on both Spectral-Spatial information, therefore, 3D CNN can be an alternative but highly computational complex due to the volume and spectral dimensions. Furthermore, these models do not extract quality feature maps and may underperform over the regions having similar textures. Therefore, this work proposed a 3D CNN model that utilizes both spatial-spectral feature maps to attain good performance. In order to achieve the said performance, the HSI cube is first divided into small overlapping 3D patches. Later these patches are processed to generate 3D feature maps using a 3D kernel function over multiple contiguous bands that persevere the spectral information as well. Benchmark HSI datasets (Pavia University, Salinas and Indian Pines) are considered to validate the performance of our proposed method. The results are further compared with several state-of-the-art methods.
Exercise? I thought you said 'Extra Fries': Leveraging Sentence Demarcations and Multi-hop Attention for Meme Affect Analysis
Mar 23, 2021

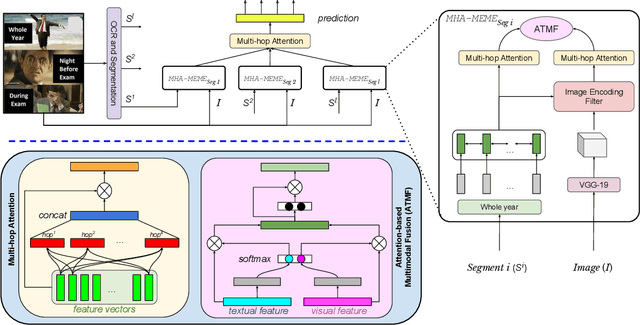
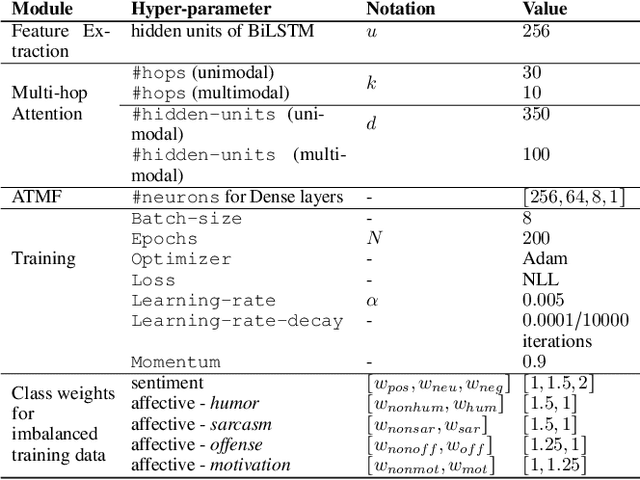
Today's Internet is awash in memes as they are humorous, satirical, or ironic which make people laugh. According to a survey, 33% of social media users in age bracket [13-35] send memes every day, whereas more than 50% send every week. Some of these memes spread rapidly within a very short time-frame, and their virality depends on the novelty of their (textual and visual) content. A few of them convey positive messages, such as funny or motivational quotes; while others are meant to mock/hurt someone's feelings through sarcastic or offensive messages. Despite the appealing nature of memes and their rapid emergence on social media, effective analysis of memes has not been adequately attempted to the extent it deserves. In this paper, we attempt to solve the same set of tasks suggested in the SemEval'20-Memotion Analysis competition. We propose a multi-hop attention-based deep neural network framework, called MHA-MEME, whose prime objective is to leverage the spatial-domain correspondence between the visual modality (an image) and various textual segments to extract fine-grained feature representations for classification. We evaluate MHA-MEME on the 'Memotion Analysis' dataset for all three sub-tasks - sentiment classification, affect classification, and affect class quantification. Our comparative study shows sota performances of MHA-MEME for all three tasks compared to the top systems that participated in the competition. Unlike all the baselines which perform inconsistently across all three tasks, MHA-MEME outperforms baselines in all the tasks on average. Moreover, we validate the generalization of MHA-MEME on another set of manually annotated test samples and observe it to be consistent. Finally, we establish the interpretability of MHA-MEME.
I Can See Clearly Now : Image Restoration via De-Raining
Jan 03, 2019
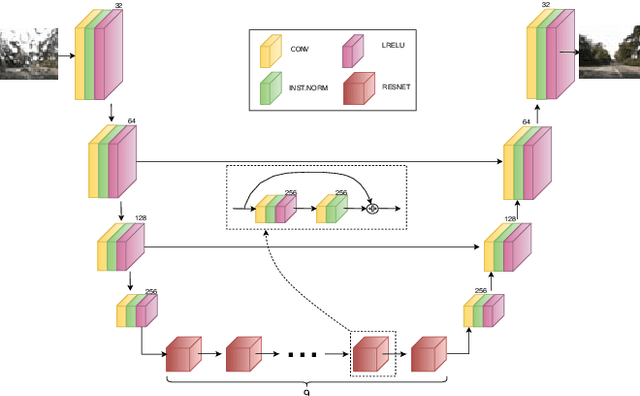
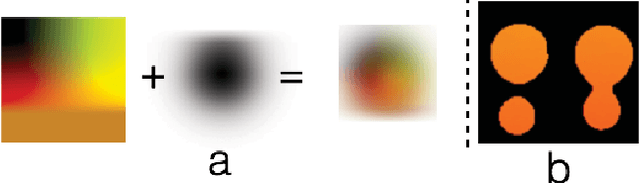

We present a method for improving segmentation tasks on images affected by adherent rain drops and streaks. We introduce a novel stereo dataset recorded using a system that allows one lens to be affected by real water droplets while keeping the other lens clear. We train a denoising generator using this dataset and show that it is effective at removing the effect of real water droplets, in the context of image reconstruction and road marking segmentation. To further test our de-noising approach, we describe a method of adding computer-generated adherent water droplets and streaks to any images, and use this technique as a proxy to demonstrate the effectiveness of our model in the context of general semantic segmentation. We benchmark our results using the CamVid road marking segmentation dataset, Cityscapes semantic segmentation datasets and our own real-rain dataset, and show significant improvement on all tasks.
Adversarial Attacks for Tabular Data: Application to Fraud Detection and Imbalanced Data
Jan 20, 2021
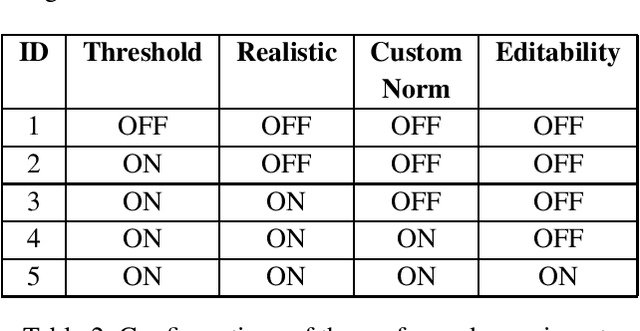
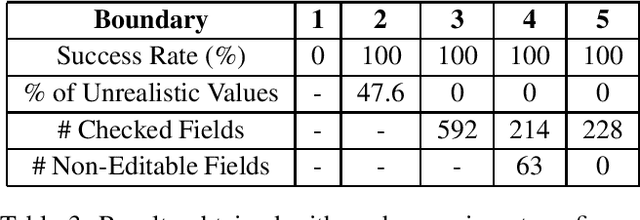
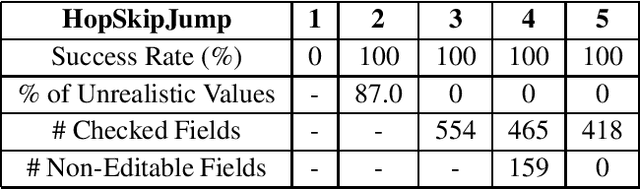
Guaranteeing the security of transactional systems is a crucial priority of all institutions that process transactions, in order to protect their businesses against cyberattacks and fraudulent attempts. Adversarial attacks are novel techniques that, other than being proven to be effective to fool image classification models, can also be applied to tabular data. Adversarial attacks aim at producing adversarial examples, in other words, slightly modified inputs that induce the Artificial Intelligence (AI) system to return incorrect outputs that are advantageous for the attacker. In this paper we illustrate a novel approach to modify and adapt state-of-the-art algorithms to imbalanced tabular data, in the context of fraud detection. Experimental results show that the proposed modifications lead to a perfect attack success rate, obtaining adversarial examples that are also less perceptible when analyzed by humans. Moreover, when applied to a real-world production system, the proposed techniques shows the possibility of posing a serious threat to the robustness of advanced AI-based fraud detection procedures.
Scalable Deep Compressive Sensing
Jan 20, 2021
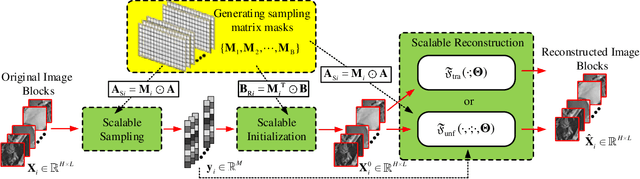
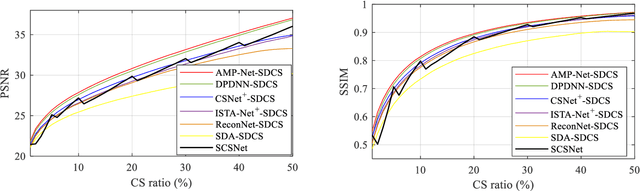
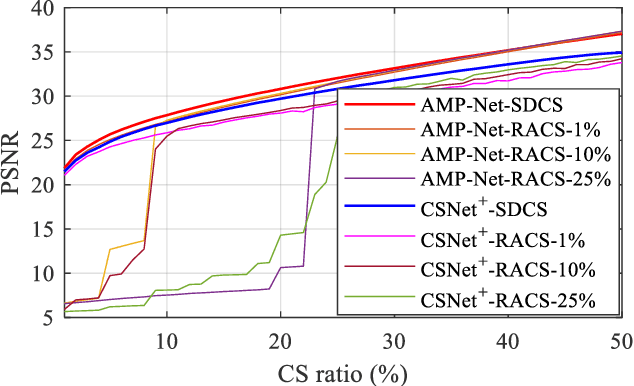
Deep learning has been used to image compressive sensing (CS) for enhanced reconstruction performance. However, most existing deep learning methods train different models for different subsampling ratios, which brings additional hardware burden. In this paper, we develop a general framework named scalable deep compressive sensing (SDCS) for the scalable sampling and reconstruction (SSR) of all existing end-to-end-trained models. In the proposed way, images are measured and initialized linearly. Two sampling masks are introduced to flexibly control the subsampling ratios used in sampling and reconstruction, respectively. To make the reconstruction model adapt to any subsampling ratio, a training strategy dubbed scalable training is developed. In scalable training, the model is trained with the sampling matrix and the initialization matrix at various subsampling ratios by integrating different sampling matrix masks. Experimental results show that models with SDCS can achieve SSR without changing their structure while maintaining good performance, and SDCS outperforms other SSR methods.
Deep Structured Feature Networks for Table Detection and Tabular Data Extraction from Scanned Financial Document Images
Feb 20, 2021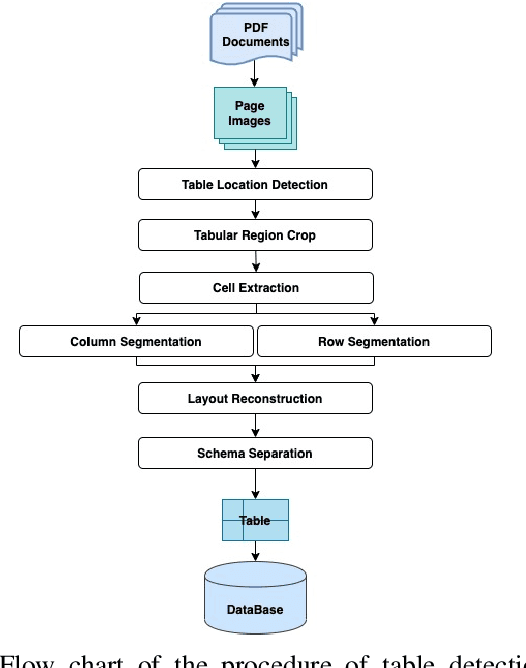
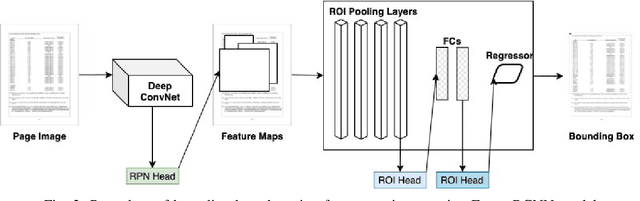
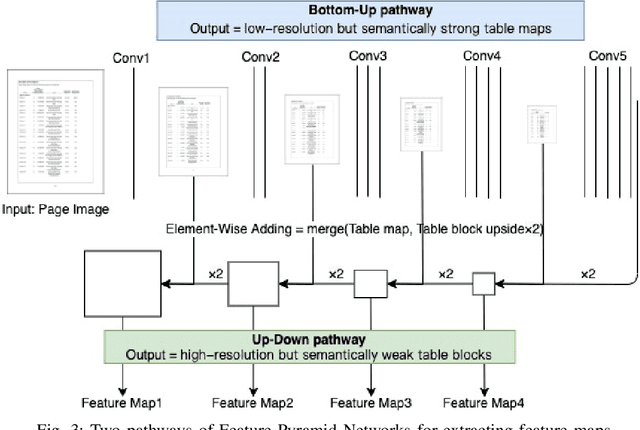
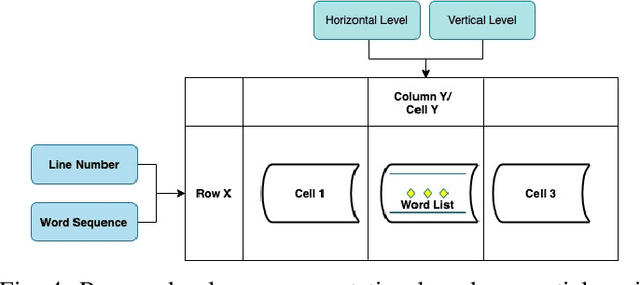
Automatic table detection in PDF documents has achieved a great success but tabular data extraction are still challenging due to the integrity and noise issues in detected table areas. The accurate data extraction is extremely crucial in finance area. Inspired by this, the aim of this research is proposing an automated table detection and tabular data extraction from financial PDF documents. We proposed a method that consists of three main processes, which are detecting table areas with a Faster R-CNN (Region-based Convolutional Neural Network) model with Feature Pyramid Network (FPN) on each page image, extracting contents and structures by a compounded layout segmentation technique based on optical character recognition (OCR) and formulating regular expression rules for table header separation. The tabular data extraction feature is embedded with rule-based filtering and restructuring functions that are highly scalable. We annotate a new Financial Documents dataset with table regions for the experiment. The excellent table detection performance of the detection model is obtained from our customized dataset. The main contributions of this paper are proposing the Financial Documents dataset with table-area annotations, the superior detection model and the rule-based layout segmentation technique for the tabular data extraction from PDF files.
PCT: Point Cloud Transformer
Dec 17, 2020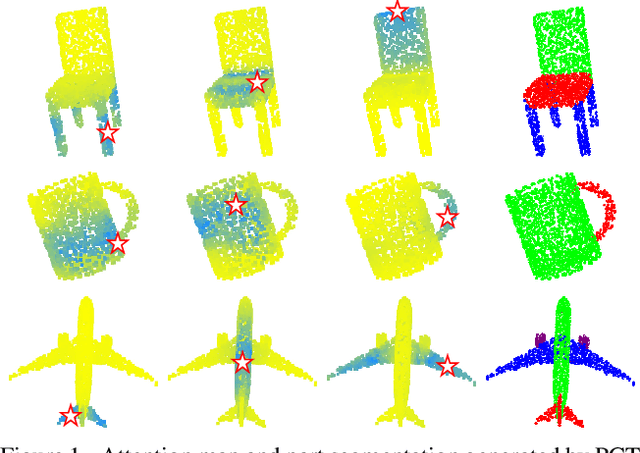
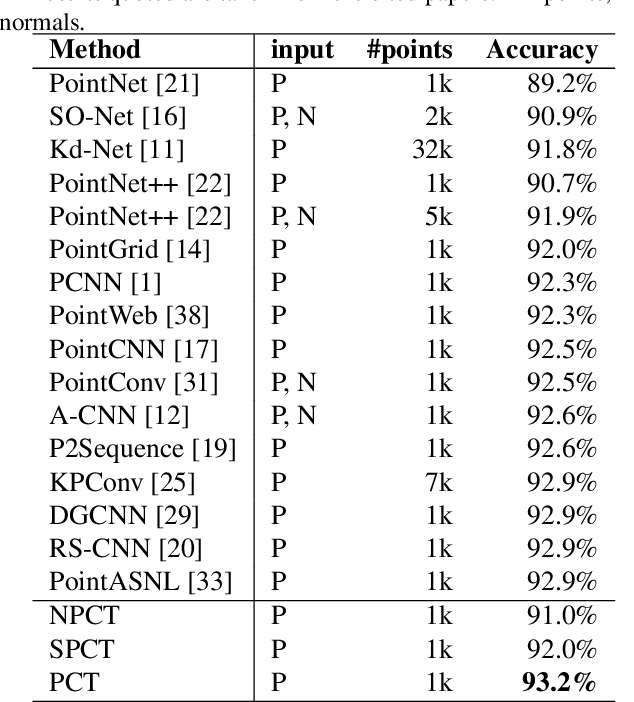
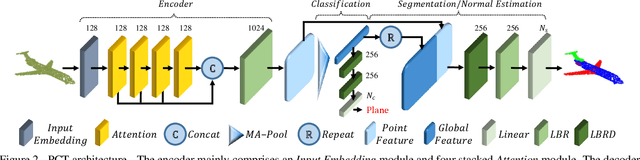
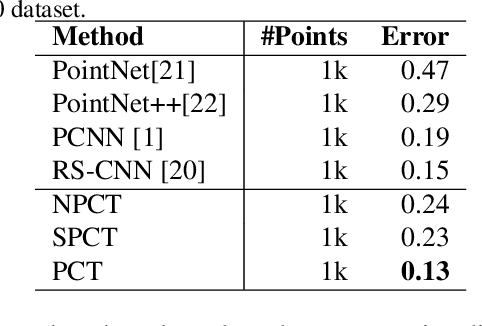
The irregular domain and lack of ordering make it challenging to design deep neural networks for point cloud processing. This paper presents a novel framework named Point Cloud Transformer(PCT) for point cloud learning. PCT is based on Transformer, which achieves huge success in natural language processing and displays great potential in image processing. It is inherently permutation invariant for processing a sequence of points, making it well-suited for point cloud learning. To better capture local context within the point cloud, we enhance input embedding with the support of farthest point sampling and nearest neighbor search. Extensive experiments demonstrate that the PCT achieves the state-of-the-art performance on shape classification, part segmentation and normal estimation tasks.
3D Graph Anatomy Geometry-Integrated Network for Pancreatic Mass Segmentation, Diagnosis, and Quantitative Patient Management
Dec 08, 2020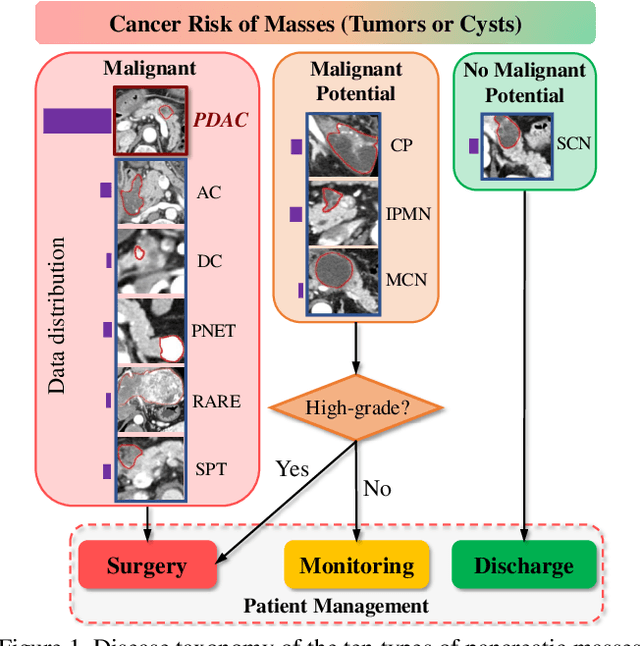

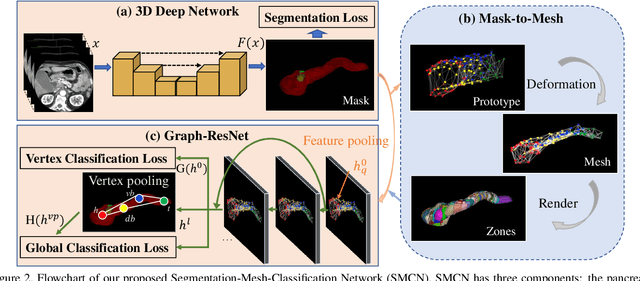

The pancreatic disease taxonomy includes ten types of masses (tumors or cysts)[20,8]. Previous work focuses on developing segmentation or classification methods only for certain mass types. Differential diagnosis of all mass types is clinically highly desirable [20] but has not been investigated using an automated image understanding approach. We exploit the feasibility to distinguish pancreatic ductal adenocarcinoma (PDAC) from the nine other nonPDAC masses using multi-phase CT imaging. Both image appearance and the 3D organ-mass geometry relationship are critical. We propose a holistic segmentation-mesh-classification network (SMCN) to provide patient-level diagnosis, by fully utilizing the geometry and location information, which is accomplished by combining the anatomical structure and the semantic detection-by-segmentation network. SMCN learns the pancreas and mass segmentation task and builds an anatomical correspondence-aware organ mesh model by progressively deforming a pancreas prototype on the raw segmentation mask (i.e., mask-to-mesh). A new graph-based residual convolutional network (Graph-ResNet), whose nodes fuse the information of the mesh model and feature vectors extracted from the segmentation network, is developed to produce the patient-level differential classification results. Extensive experiments on 661 patients' CT scans (five phases per patient) show that SMCN can improve the mass segmentation and detection accuracy compared to the strong baseline method nnUNet (e.g., for nonPDAC, Dice: 0.611 vs. 0.478; detection rate: 89% vs. 70%), achieve similar sensitivity and specificity in differentiating PDAC and nonPDAC as expert radiologists (i.e., 94% and 90%), and obtain results comparable to a multimodality test [20] that combines clinical, imaging, and molecular testing for clinical management of patients.