 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Iterative PET Image Reconstruction Using Convolutional Neural Network Representation
Oct 09, 2017
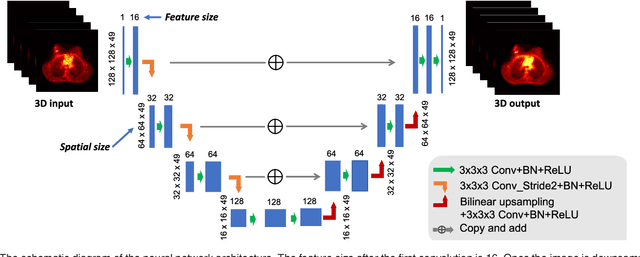
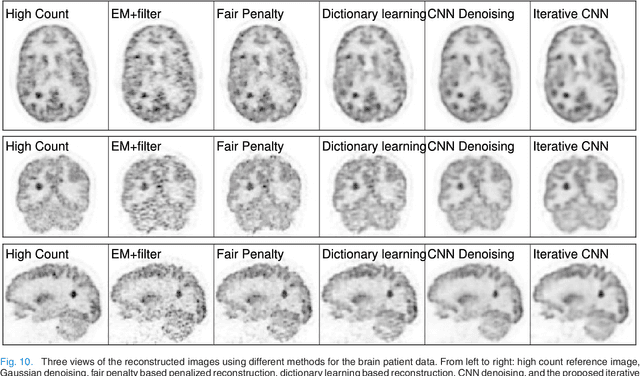
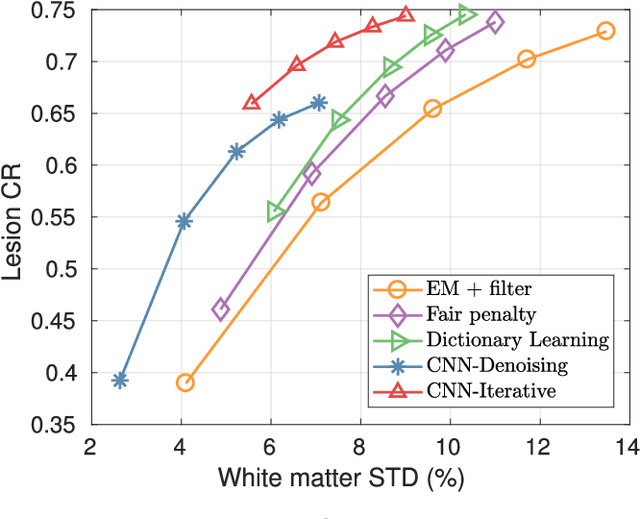
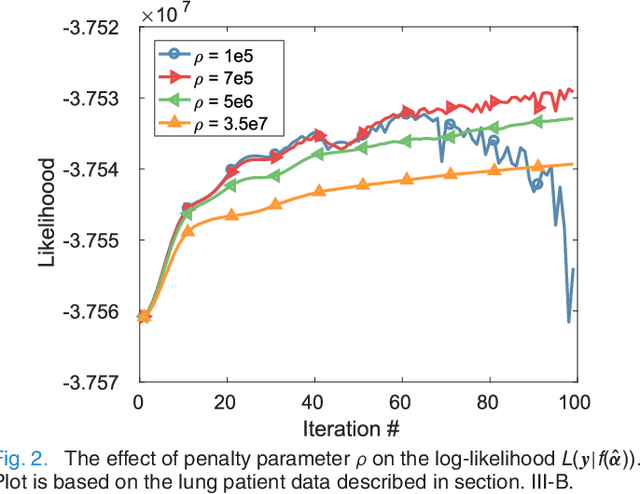
PET image reconstruction is challenging due to the ill-poseness of the inverse problem and limited number of detected photons. Recently deep neural networks have been widely and successfully used in computer vision tasks and attracted growing interests in medical imaging. In this work, we trained a deep residual convolutional neural network to improve PET image quality by using the existing inter-patient information. An innovative feature of the proposed method is that we embed the neural network in the iterative reconstruction framework for image representation, rather than using it as a post-processing tool. We formulate the objective function as a constraint optimization problem and solve it using the alternating direction method of multipliers (ADMM) algorithm. Both simulation data and hybrid real data are used to evaluate the proposed method. Quantification results show that our proposed iterative neural network method can outperform the neural network denoising and conventional penalized maximum likelihood methods.
Accurate Visual-Inertial SLAM by Feature Re-identification
Feb 26, 2021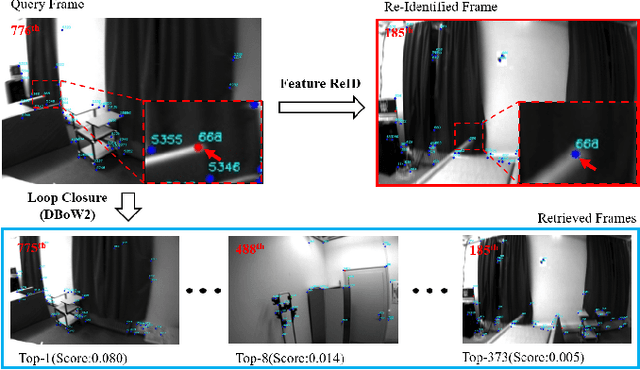
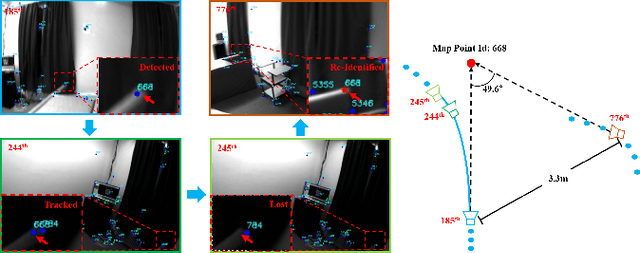
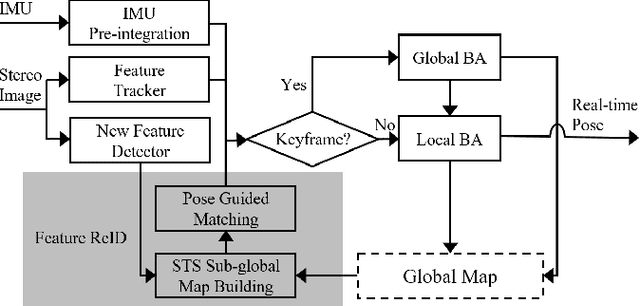
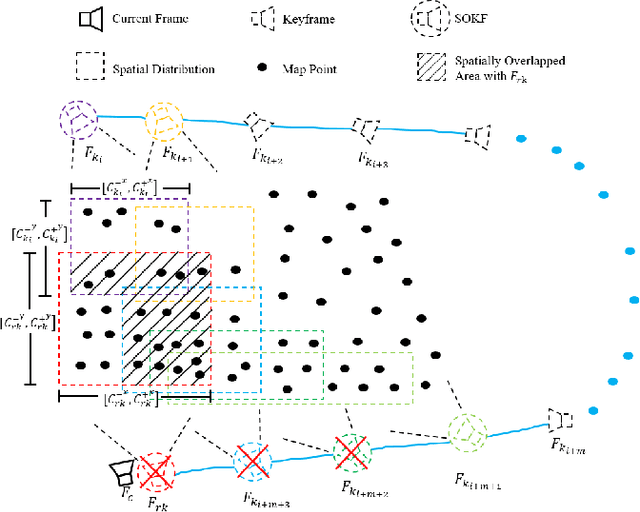
We propose a novel feature re-identification method for real-time visual-inertial SLAM. The front-end module of the state-of-the-art visual-inertial SLAM methods (e.g. visual feature extraction and matching schemes) relies on feature tracks across image frames, which are easily broken in challenging scenarios, resulting in insufficient visual measurement and accumulated error in pose estimation. In this paper, we propose an efficient drift-less SLAM method by re-identifying existing features from a spatial-temporal sensitive sub-global map. The re-identified features over a long time span serve as augmented visual measurements and are incorporated into the optimization module which can gradually decrease the accumulative error in the long run, and further build a drift-less global map in the system. Extensive experiments show that our feature re-identification method is both effective and efficient. Specifically, when combining the feature re-identification with the state-of-the-art SLAM method [11], our method achieves 67.3% and 87.5% absolute translation error reduction with only a small additional computational cost on two public SLAM benchmark DBs: EuRoC and TUM-VI respectively.
NeRF--: Neural Radiance Fields Without Known Camera Parameters
Feb 16, 2021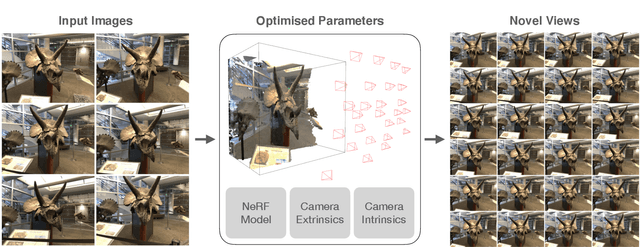
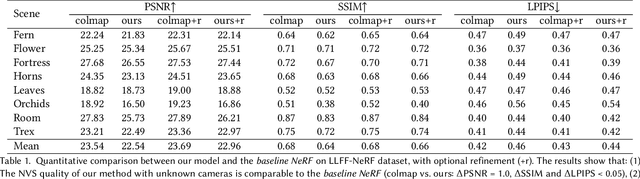
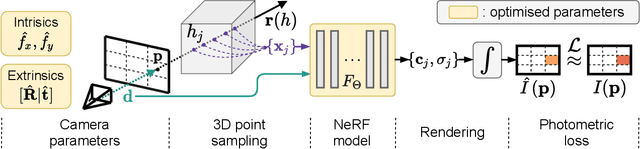
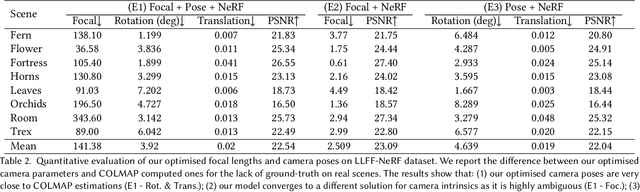
This paper tackles the problem of novel view synthesis (NVS) from 2D images without known camera poses and intrinsics. Among various NVS techniques, Neural Radiance Field (NeRF) has recently gained popularity due to its remarkable synthesis quality. Existing NeRF-based approaches assume that the camera parameters associated with each input image are either directly accessible at training, or can be accurately estimated with conventional techniques based on correspondences, such as Structure-from-Motion. In this work, we propose an end-to-end framework, termed NeRF--, for training NeRF models given only RGB images, without pre-computed camera parameters. Specifically, we show that the camera parameters, including both intrinsics and extrinsics, can be automatically discovered via joint optimisation during the training of the NeRF model. On the standard LLFF benchmark, our model achieves comparable novel view synthesis results compared to the baseline trained with COLMAP pre-computed camera parameters. We also conduct extensive analyses to understand the model behaviour under different camera trajectories, and show that in scenarios where COLMAP fails, our model still produces robust results.
Retrospective Approximation for Smooth Stochastic Optimization
Mar 07, 2021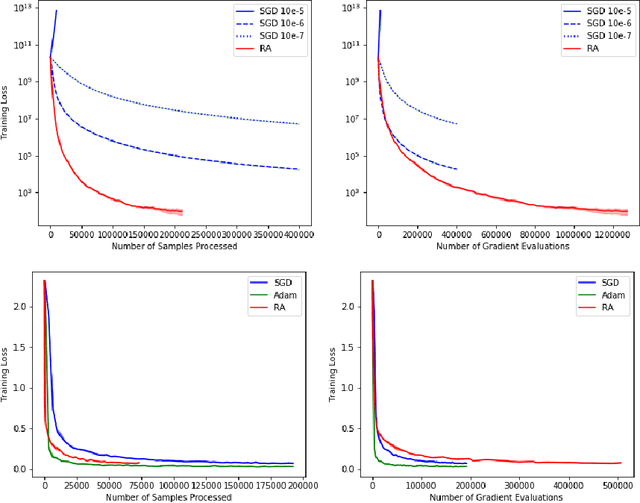
We consider stochastic optimization problems where a smooth (and potentially nonconvex) objective is to be minimized using a stochastic first-order oracle. These type of problems arise in many settings from simulation optimization to deep learning. We present Retrospective Approximation (RA) as a universal sequential sample-average approximation (SAA) paradigm where during each iteration $k$, a sample-path approximation problem is implicitly generated using an adapted sample size $M_k$, and solved (with prior solutions as "warm start") to an adapted error tolerance $\epsilon_k$, using a "deterministic method" such as the line search quasi-Newton method. The principal advantage of RA is that decouples optimization from stochastic approximation, allowing the direct adoption of existing deterministic algorithms without modification, thus mitigating the need to redesign algorithms for the stochastic context. A second advantage is the obvious manner in which RA lends itself to parallelization. We identify conditions on $\{M_k, k \geq 1\}$ and $\{\epsilon_k, k\geq 1\}$ that ensure almost sure convergence and convergence in $L_1$-norm, along with optimal iteration and work complexity rates. We illustrate the performance of RA with line-search quasi-Newton on an ill-conditioned least squares problem, as well as an image classification problem using a deep convolutional neural net.
Learning to Read and Follow Music in Complete Score Sheet Images
Jul 21, 2020

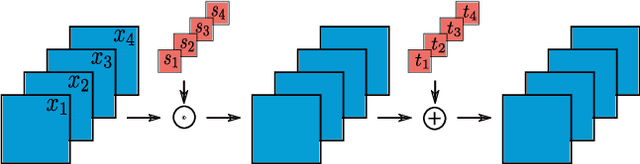
This paper addresses the task of score following in sheet music given as unprocessed images. While existing work either relies on OMR software to obtain a computer-readable score representation, or crucially relies on prepared sheet image excerpts, we propose the first system that directly performs score following in full-page, completely unprocessed sheet images. Based on incoming audio and a given image of the score, our system directly predicts the most likely position within the page that matches the audio, outperforming current state-of-the-art image-based score followers in terms of alignment precision. We also compare our method to an OMR-based approach and empirically show that it can be a viable alternative to such a system.
Structure-Consistent Weakly Supervised Salient Object Detection with Local Saliency Coherence
Dec 09, 2020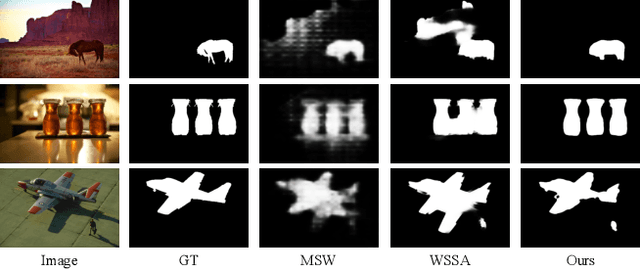
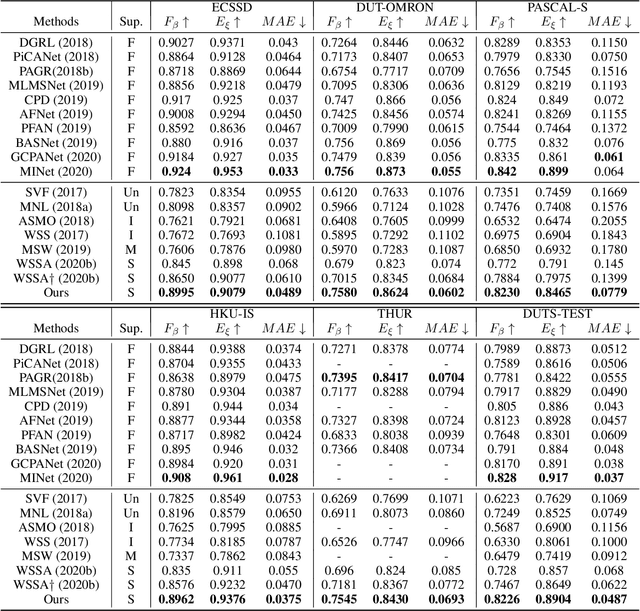
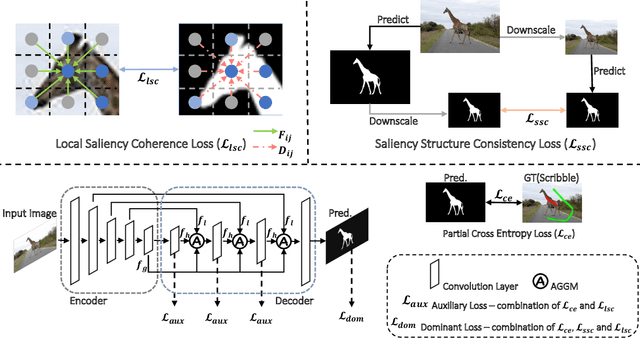
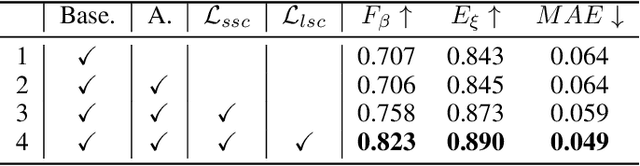
Sparse labels have been attracting much attention in recent years. However, the performance gap between weakly supervised and fully supervised salient object detection methods is huge, and most previous weakly supervised works adopt complex training methods with many bells and whistles. In this work, we propose a one-round end-to-end training approach for weakly supervised salient object detection via scribble annotations without pre/post-processing operations or extra supervision data. Since scribble labels fail to offer detailed salient regions, we propose a local coherence loss to propagate the labels to unlabeled regions based on image features and pixel distance, so as to predict integral salient regions with complete object structures. We design a saliency structure consistency loss as self-consistent mechanism to ensure consistent saliency maps are predicted with different scales of the same image as input, which could be viewed as a regularization technique to enhance the model generalization ability. Additionally, we design an aggregation module (AGGM) to better integrate high-level features, low-level features and global context information for the decoder to aggregate various information. Extensive experiments show that our method achieves a new state-of-the-art performance on six benchmarks (e.g. for the ECSSD dataset: F_\beta = 0.8995, E_\xi = 0.9079 and MAE = 0.0489$), with an average gain of 4.60\% for F-measure, 2.05\% for E-measure and 1.88\% for MAE over the previous best method on this task. Source code is available at http://github.com/siyueyu/SCWSSOD.
ResNet-like Architecture with Low Hardware Requirements
Sep 15, 2020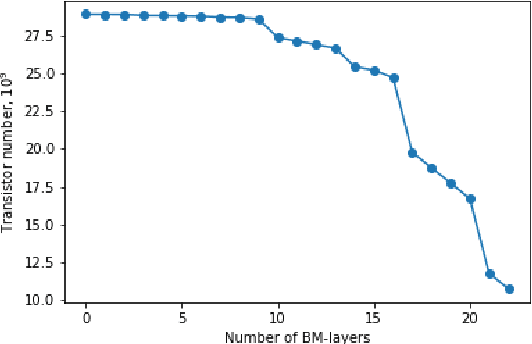
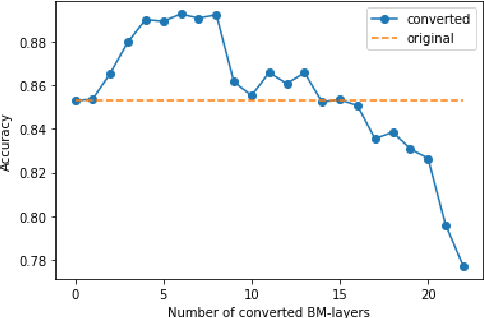
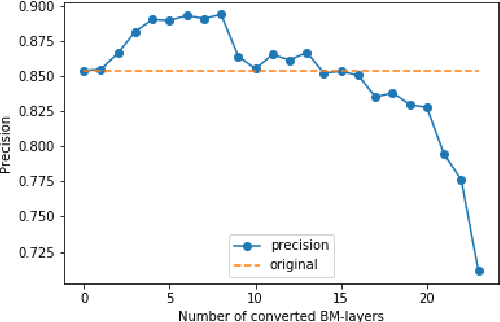
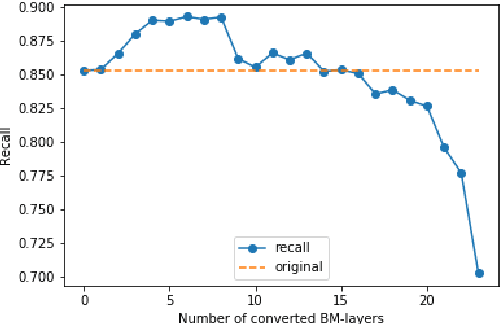
One of the most computationally intensive parts in modern recognition systems is an inference of deep neural networks that are used for image classification, segmentation, enhancement, and recognition. The growing popularity of edge computing makes us look for ways to reduce its time for mobile and embedded devices. One way to decrease the neural network inference time is to modify a neuron model to make it moreefficient for computations on a specific device. The example ofsuch a model is a bipolar morphological neuron model. The bipolar morphological neuron is based on the idea of replacing multiplication with addition and maximum operations. This model has been demonstrated for simple image classification with LeNet-like architectures [1]. In the paper, we introduce a bipolar morphological ResNet (BM-ResNet) model obtained from a much more complex ResNet architecture by converting its layers to bipolar morphological ones. We apply BM-ResNet to image classification on MNIST and CIFAR-10 datasets with only a moderate accuracy decrease from 99.3% to 99.1% and from 85.3% to 85.1%. We also estimate the computational complexity of the resulting model. We show that for the majority of ResNet layers, the considered model requires 2.1-2.9 times fewer logic gates for implementation and 15-30% lower latency.
A modified Bayesian Convolutional Neural Network for Breast Histopathology Image Classification and Uncertainty Quantification
Oct 07, 2020
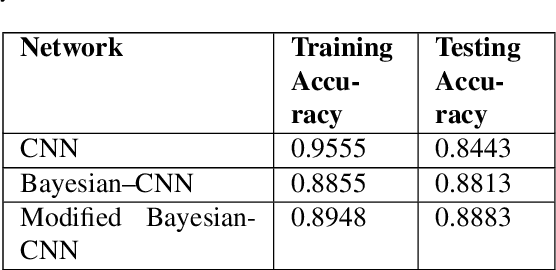
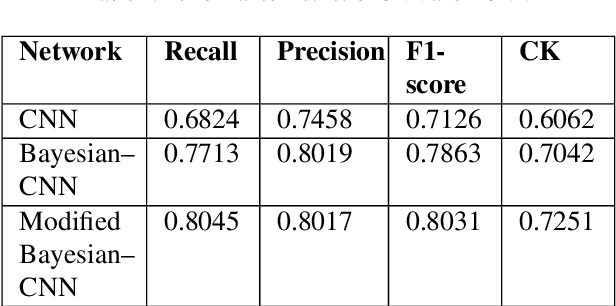
Convolutional neural network (CNN) based classification models have been successfully used on histopathological images for the detection of diseases. Despite its success, CNN may yield erroneous or overfitted results when the data is not sufficiently large or is biased. To overcome these limitations of CNN and to provide uncertainty quantification Bayesian CNN is recently proposed. However, we show that Bayesian-CNN still suffers from inaccuracies, especially in negative predictions. In the present work, we extend the Bayesian-CNN to improve accuracy and the rate of convergence. The proposed model is called modified Bayesian-CNN. The novelty of the proposed model lies in an adaptive activation function that contains a learnable parameter for each of the neurons. This adaptive activation function dynamically changes the loss function thereby providing faster convergence and better accuracy. The uncertainties associated with the predictions are obtained since the model learns a probability distribution on the network parameters. It reduces overfitting through an ensemble averaging over networks, which in turn improves accuracy on the unknown data. The proposed model demonstrates significant improvement by nearly eliminating overfitting and remarkably reducing (about 38%) the number of false-negative predictions. We found that the proposed model predicts higher uncertainty for images having features of both the classes. The uncertainty in the predictions of individual images can be used to decide when further human-expert intervention is needed. These findings have the potential to advance the state-of-the-art machine learning based automatic classification for histopathological images.
Phrase-based Image Captioning
Apr 09, 2015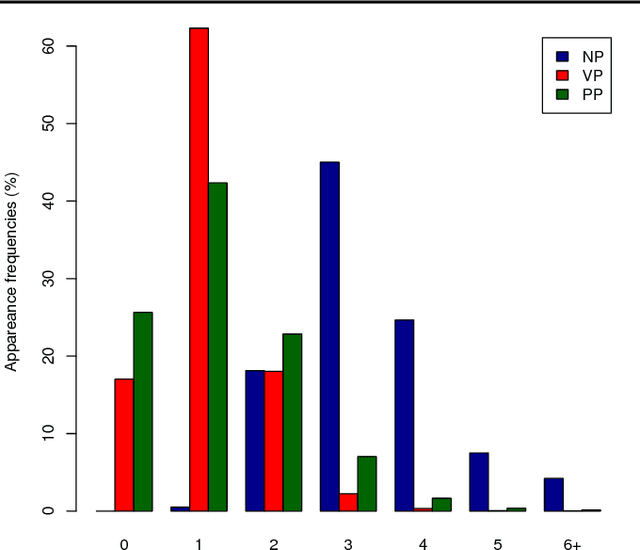
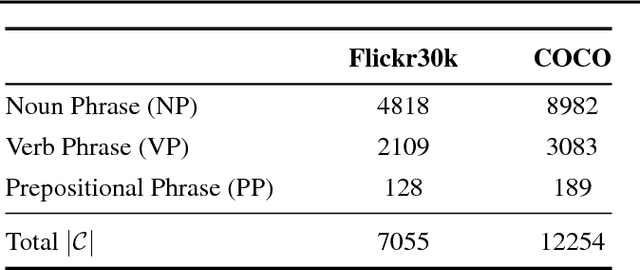
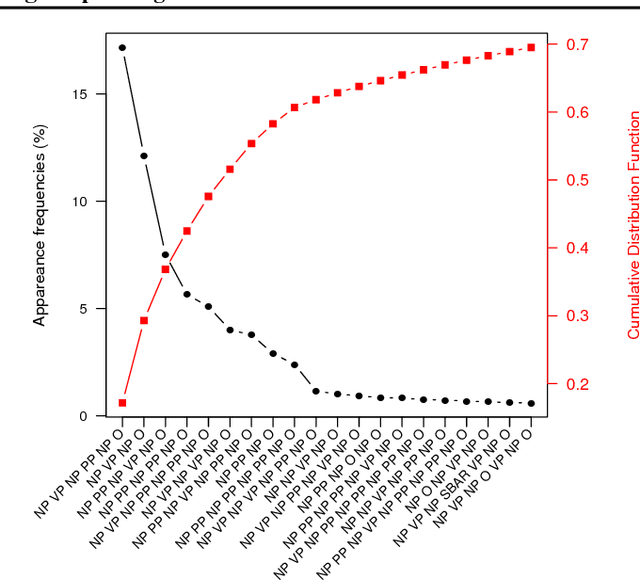
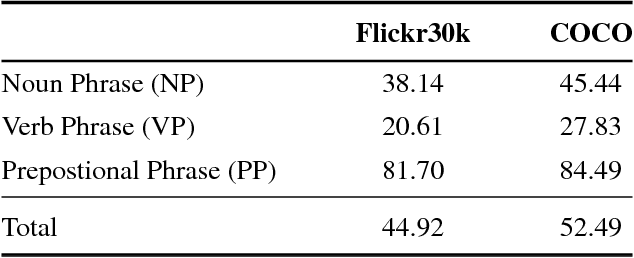
Generating a novel textual description of an image is an interesting problem that connects computer vision and natural language processing. In this paper, we present a simple model that is able to generate descriptive sentences given a sample image. This model has a strong focus on the syntax of the descriptions. We train a purely bilinear model that learns a metric between an image representation (generated from a previously trained Convolutional Neural Network) and phrases that are used to described them. The system is then able to infer phrases from a given image sample. Based on caption syntax statistics, we propose a simple language model that can produce relevant descriptions for a given test image using the phrases inferred. Our approach, which is considerably simpler than state-of-the-art models, achieves comparable results in two popular datasets for the task: Flickr30k and the recently proposed Microsoft COCO.
LEAD: LiDAR Extender for Autonomous Driving
Feb 16, 2021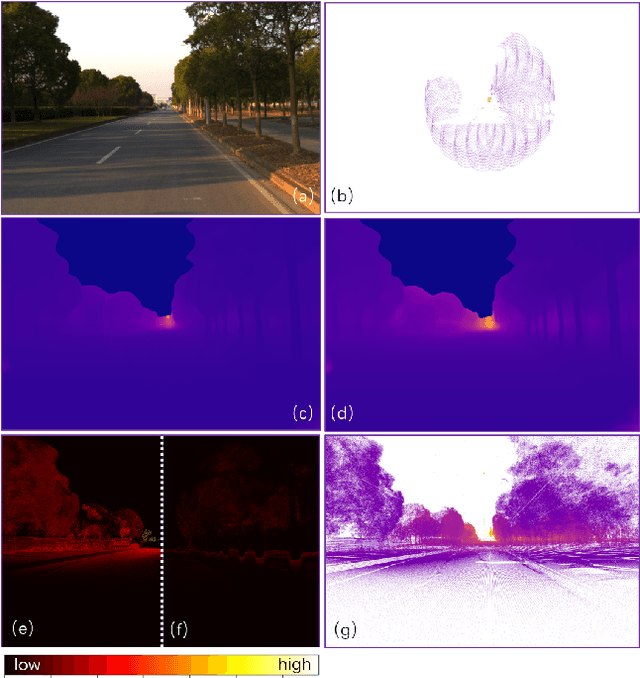
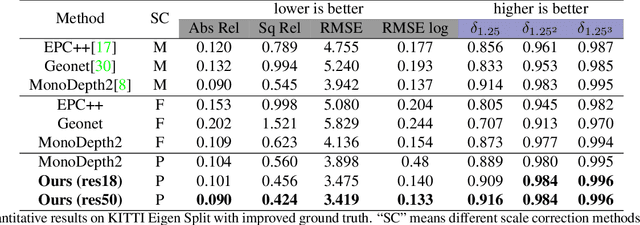
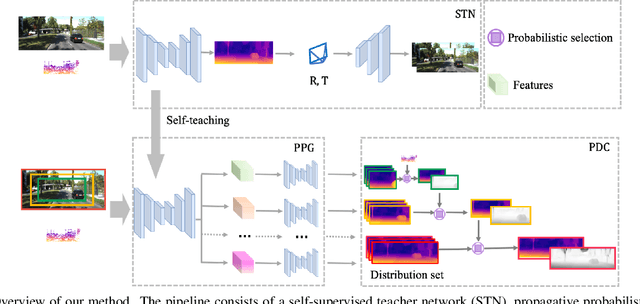
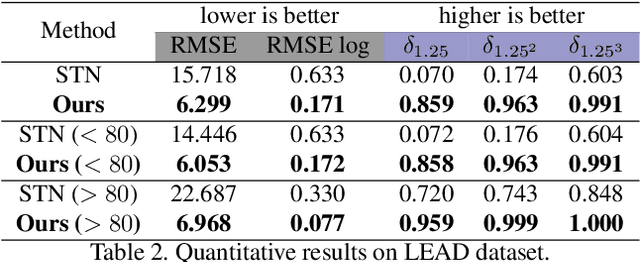
3D perception using sensors under vehicle industrial standard is the rigid demand in autonomous driving. MEMS LiDAR emerges with irresistible trend due to its lower cost, more robust, and meeting the mass-production standards. However, it suffers small field of view (FoV), slowing down the step of its population. In this paper, we propose LEAD, i.e., LiDAR Extender for Autonomous Driving, to extend the MEMS LiDAR by coupled image w.r.t both FoV and range. We propose a multi-stage propagation strategy based on depth distributions and uncertainty map, which shows effective propagation ability. Moreover, our depth outpainting/propagation network follows a teacher-student training fashion, which transfers depth estimation ability to depth completion network without any scale error passed. To validate the LiDAR extension quality, we utilize a high-precise laser scanner to generate a ground-truth dataset. Quantitative and qualitative evaluations show that our scheme outperforms SOTAs with a large margin. We believe the proposed LEAD along with the dataset would benefit the community w.r.t depth researches.