 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
An off-the-grid approach to multi-compartment magnetic resonance fingerprinting
Nov 23, 2020
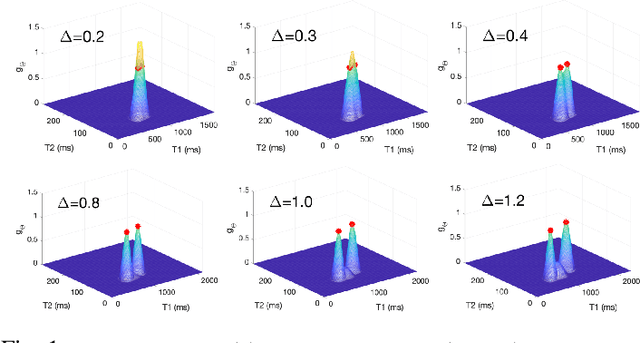
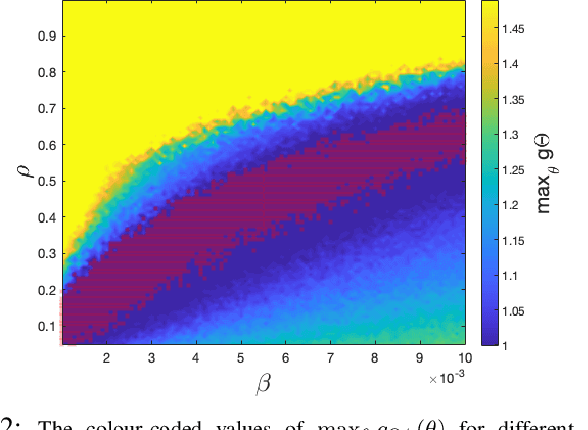
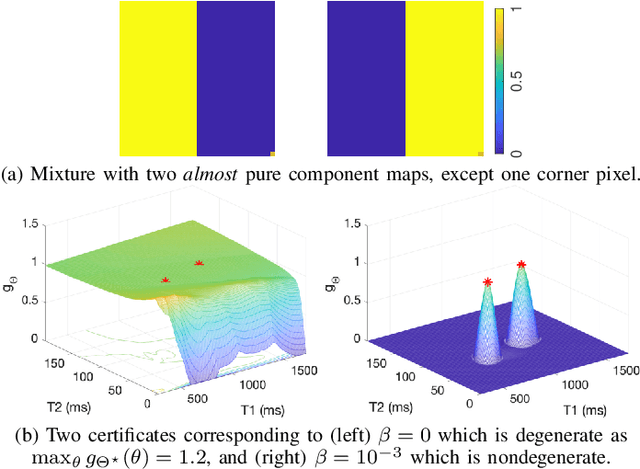
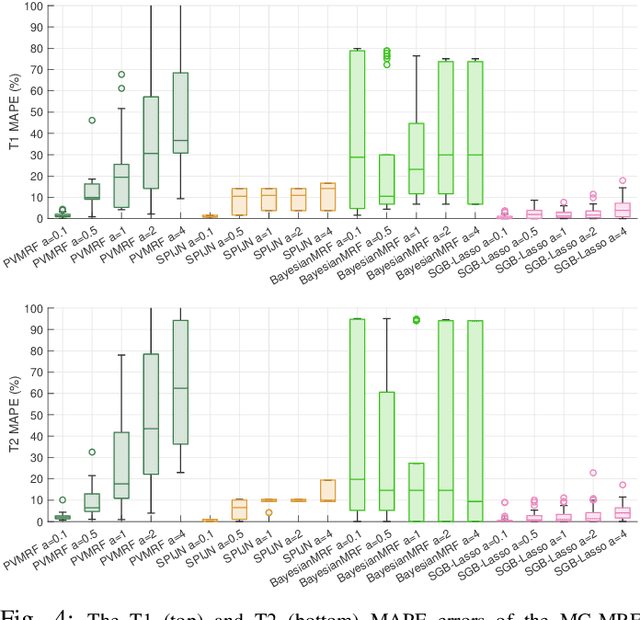
We propose a novel numerical approach to separate multiple tissue compartments in image voxels and to estimate quantitatively their nuclear magnetic resonance (NMR) properties and mixture fractions, given magnetic resonance fingerprinting (MRF) measurements. The number of tissues, their types or quantitative properties are not a-priori known, but the image is assumed to be composed of sparse compartments with linearly mixed Bloch magnetisation responses within voxels. Fine-grid discretisation of the multi-dimensional NMR properties creates large and highly coherent MRF dictionaries that can challenge scalability and precision of the numerical methods for (discrete) sparse approximation. To overcome these issues, we propose an off-the-grid approach equipped with an extended notion of the sparse group lasso regularisation for sparse approximation using continuous (non-discretised) Bloch response models. Further, the nonlinear and non-analytical Bloch responses are approximated by a neural network, enabling efficient back-propagation of the gradients through the proposed algorithm. Tested on simulated and in-vivo healthy brain MRF data, we demonstrate effectiveness of the proposed scheme compared to the baseline multicompartment MRF methods.
Measuring Discrimination to Boost Comparative Testing for Multiple Deep Learning Models
Mar 09, 2021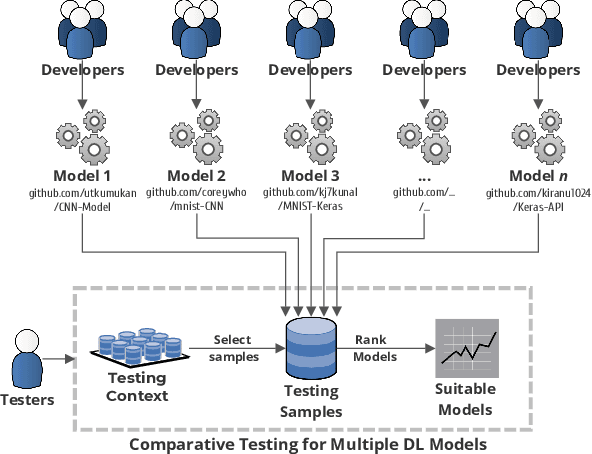
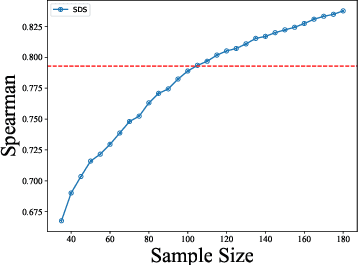
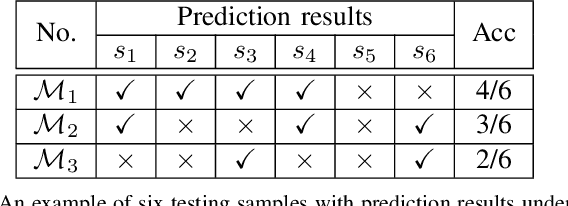
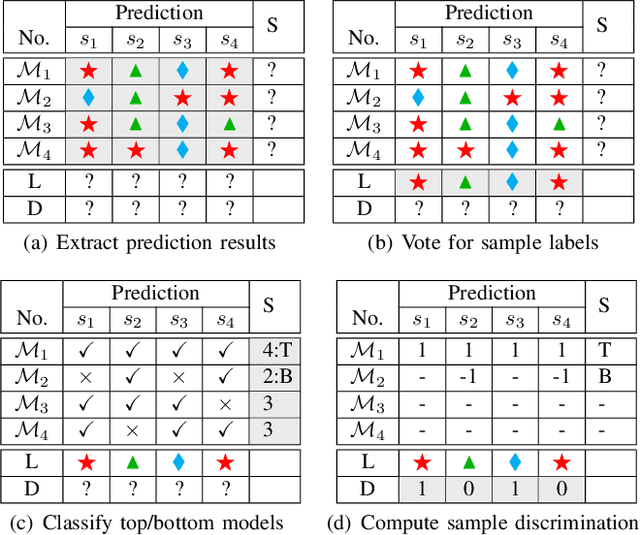
The boom of DL technology leads to massive DL models built and shared, which facilitates the acquisition and reuse of DL models. For a given task, we encounter multiple DL models available with the same functionality, which are considered as candidates to achieve this task. Testers are expected to compare multiple DL models and select the more suitable ones w.r.t. the whole testing context. Due to the limitation of labeling effort, testers aim to select an efficient subset of samples to make an as precise rank estimation as possible for these models. To tackle this problem, we propose Sample Discrimination based Selection (SDS) to select efficient samples that could discriminate multiple models, i.e., the prediction behaviors (right/wrong) of these samples would be helpful to indicate the trend of model performance. To evaluate SDS, we conduct an extensive empirical study with three widely-used image datasets and 80 real world DL models. The experimental results show that, compared with state-of-the-art baseline methods, SDS is an effective and efficient sample selection method to rank multiple DL models.
Text to Image Synthesis Using Generative Adversarial Networks
May 02, 2018Generating images from natural language is one of the primary applications of recent conditional generative models. Besides testing our ability to model conditional, highly dimensional distributions, text to image synthesis has many exciting and practical applications such as photo editing or computer-aided content creation. Recent progress has been made using Generative Adversarial Networks (GANs). This material starts with a gentle introduction to these topics and discusses the existent state of the art models. Moreover, I propose Wasserstein GAN-CLS, a new model for conditional image generation based on the Wasserstein distance which offers guarantees of stability. Then, I show how the novel loss function of Wasserstein GAN-CLS can be used in a Conditional Progressive Growing GAN. In combination with the proposed loss, the model boosts by 7.07% the best Inception Score (on the Caltech birds dataset) of the models which use only the sentence-level visual semantics. The only model which performs better than the Conditional Wasserstein Progressive Growing GAN is the recently proposed AttnGAN which uses word-level visual semantics as well.
3D medical image segmentation with labeled and unlabeled data using autoencoders at the example of liver segmentation in CT images
Mar 17, 2020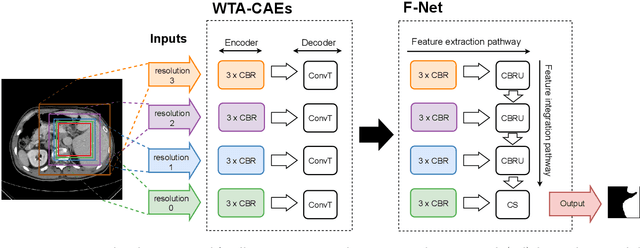
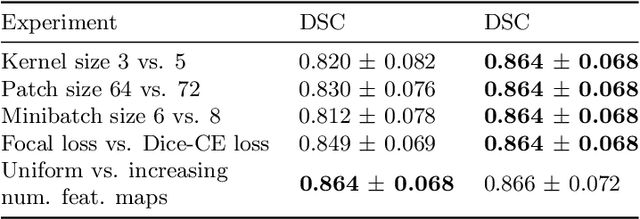

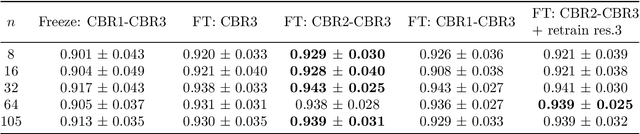
Automatic segmentation of anatomical structures with convolutional neural networks (CNNs) constitutes a large portion of research in medical image analysis. The majority of CNN-based methods rely on an abundance of labeled data for proper training. Labeled medical data is often scarce, but unlabeled data is more widely available. This necessitates approaches that go beyond traditional supervised learning and leverage unlabeled data for segmentation tasks. This work investigates the potential of autoencoder-extracted features to improve segmentation with a CNN. Two strategies were considered. First, transfer learning where pretrained autoencoder features were used as initialization for the convolutional layers in the segmentation network. Second, multi-task learning where the tasks of segmentation and feature extraction, by means of input reconstruction, were learned and optimized simultaneously. A convolutional autoencoder was used to extract features from unlabeled data and a multi-scale, fully convolutional CNN was used to perform the target task of 3D liver segmentation in CT images. For both strategies, experiments were conducted with varying amounts of labeled and unlabeled training data. The proposed learning strategies improved results in $75\%$ of the experiments compared to training from scratch and increased the dice score by up to $0.040$ and $0.024$ for a ratio of unlabeled to labeled training data of about $32 : 1$ and $12.5 : 1$, respectively. The results indicate that both training strategies are more effective with a large ratio of unlabeled to labeled training data.
"You might also like this model": Data Driven Approach for Recommending Deep Learning Models for Unknown Image Datasets
Nov 26, 2019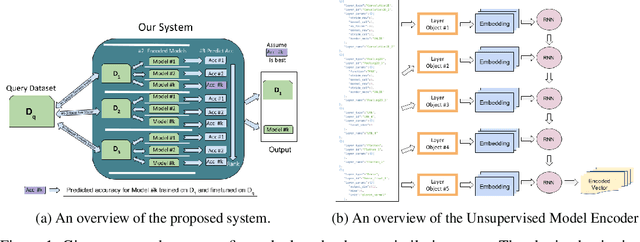
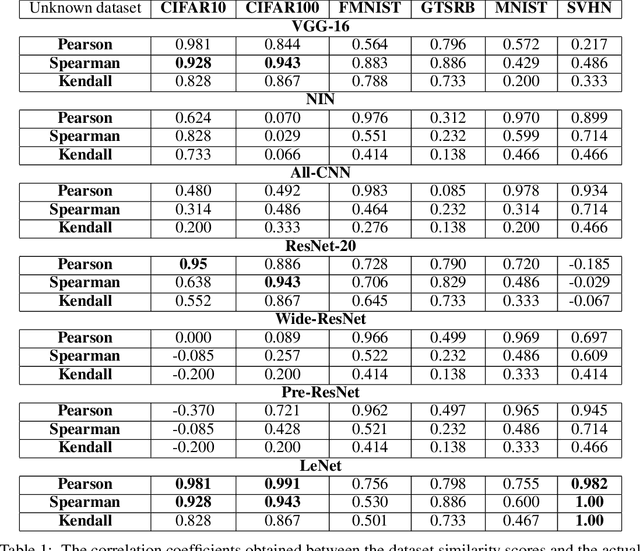
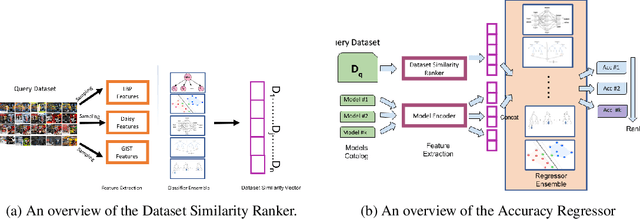

For an unknown (new) classification dataset, choosing an appropriate deep learning architecture is often a recursive, time-taking, and laborious process. In this research, we propose a novel technique to recommend a suitable architecture from a repository of known models. Further, we predict the performance accuracy of the recommended architecture on the given unknown dataset, without the need for training the model. We propose a model encoder approach to learn a fixed length representation of deep learning architectures along with its hyperparameters, in an unsupervised fashion. We manually curate a repository of image datasets with corresponding known deep learning models and show that the predicted accuracy is a good estimator of the actual accuracy. We discuss the implications of the proposed approach for three benchmark images datasets and also the challenges in using the approach for text modality. To further increase the reproducibility of the proposed approach, the entire implementation is made publicly available along with the trained models.
DeepViT: Towards Deeper Vision Transformer
Mar 28, 2021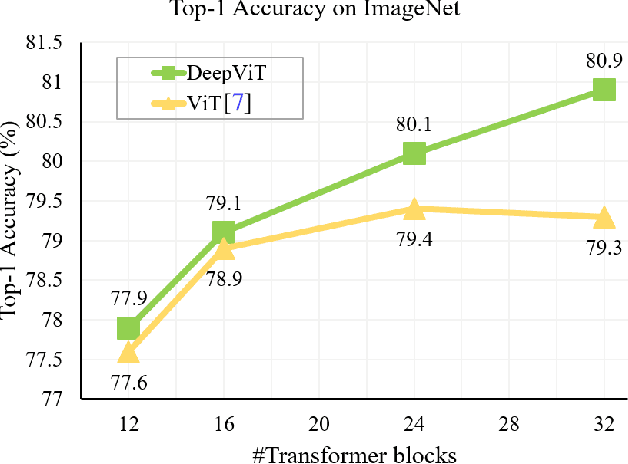
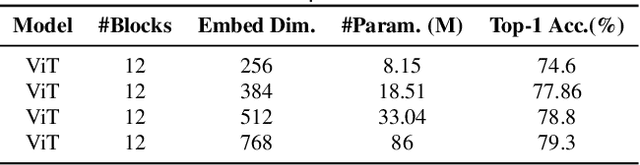
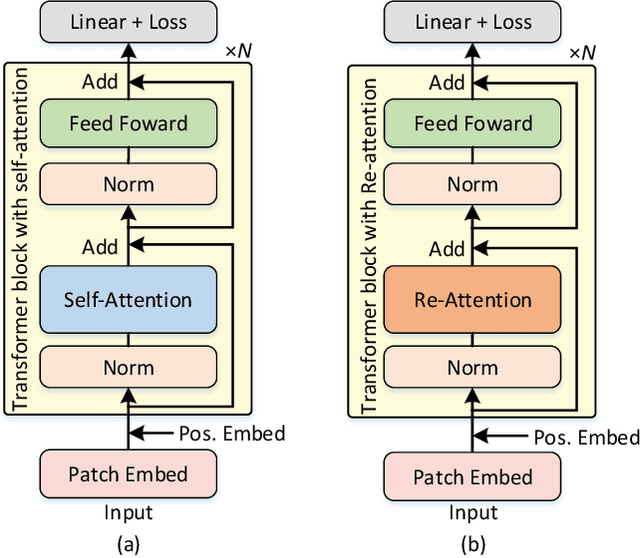

Vision transformers (ViTs) have been successfully applied in image classification tasks recently. In this paper, we show that, unlike convolution neural networks (CNNs)that can be improved by stacking more convolutional layers, the performance of ViTs saturate fast when scaled to be deeper. More specifically, we empirically observe that such scaling difficulty is caused by the attention collapse issue: as the transformer goes deeper, the attention maps gradually become similar and even much the same after certain layers. In other words, the feature maps tend to be identical in the top layers of deep ViT models. This fact demonstrates that in deeper layers of ViTs, the self-attention mechanism fails to learn effective concepts for representation learning and hinders the model from getting expected performance gain. Based on above observation, we propose a simple yet effective method, named Re-attention, to re-generate the attention maps to increase their diversity at different layers with negligible computation and memory cost. The pro-posed method makes it feasible to train deeper ViT models with consistent performance improvements via minor modification to existing ViT models. Notably, when training a deep ViT model with 32 transformer blocks, the Top-1 classification accuracy can be improved by 1.6% on ImageNet. Code will be made publicly available
Innovative 3D Depth Map Generation From A Holoscopic 3D Image Based on Graph Cut Technique
Nov 10, 2018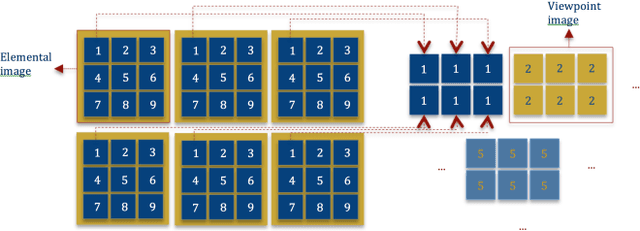

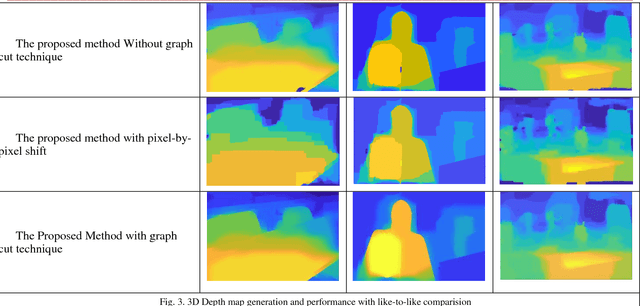
Holoscopic 3D imaging is a promising technique for capturing full colour spatial 3D images using a single aperture holoscopic 3D camera. It mimics fly's eye technique with a microlens array, which views the scene at a slightly different angle to its adjacent lens that records three dimensional information onto a two dimensional surface. This paper proposes a method of depth map generation from a holoscopic 3D image based on graph cut technique. The principal objective of this study is to estimate the depth information presented in a holoscopic 3D image with high precision. As such, depth map extraction is measured from a single still holoscopic 3D image which consists of multiple viewpoint images. The viewpoints are extracted and utilised for disparity calculation via disparity space image technique and pixels displacement is measured with sub pixel accuracy to overcome the issue of the narrow baseline between the viewpoint images for stereo matching. In addition, cost aggregation is used to correlate the matching costs within a particular neighbouring region using sum of absolute difference SAD combined with gradient-based metric and winner takes all algorithm is employed to select the minimum elements in the array as optimal disparity value. Finally, the optimal depth map is obtained using graph cut technique. The proposed method extends the utilisation of holoscopic 3D imaging system and enables the expansion of the technology for various applications of autonomous robotics, medical, inspection, AR VR, security and entertainment where 3D depth sensing and measurement are a concern.
Utilizing Transfer Learning and a Customized Loss Function for Optic Disc Segmentation from Retinal Images
Oct 01, 2020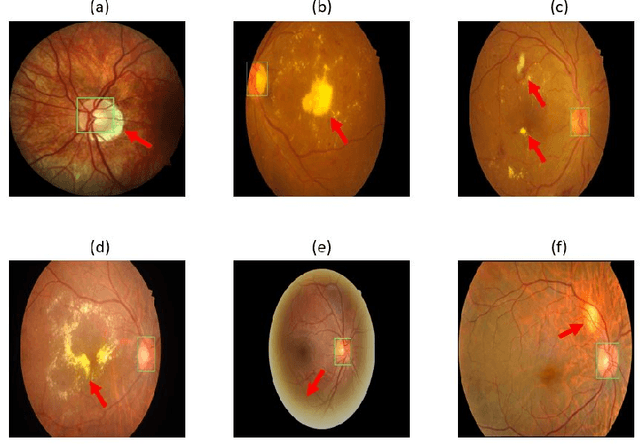
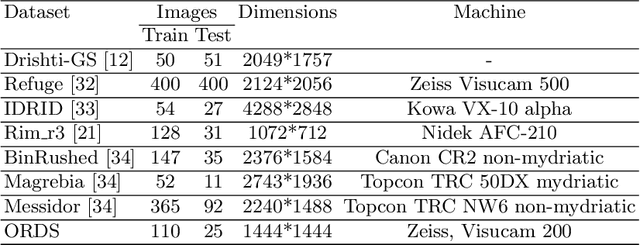
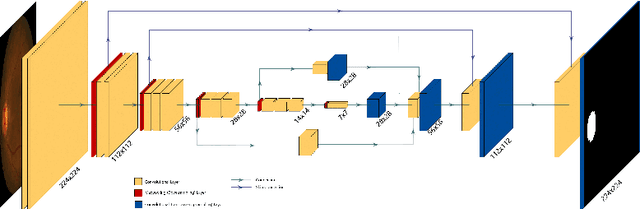
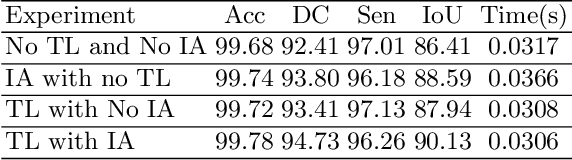
Accurate segmentation of the optic disc from a retinal image is vital to extracting retinal features that may be highly correlated with retinal conditions such as glaucoma. In this paper, we propose a deep-learning based approach capable of segmenting the optic disc given a high-precision retinal fundus image. Our approach utilizes a UNET-based model with a VGG16 encoder trained on the ImageNet dataset. This study can be distinguished from other studies in the customization made for the VGG16 model, the diversity of the datasets adopted, the duration of disc segmentation, the loss function utilized, and the number of parameters required to train our model. Our approach was tested on seven publicly available datasets augmented by a dataset from a private clinic that was annotated by two Doctors of Optometry through a web portal built for this purpose. We achieved an accuracy of 99.78\% and a Dice coefficient of 94.73\% for a disc segmentation from a retinal image in 0.03 seconds. The results obtained from comprehensive experiments demonstrate the robustness of our approach to disc segmentation of retinal images obtained from different sources.
Unsupervised Landmark Learning from Unpaired Data
Jun 29, 2020
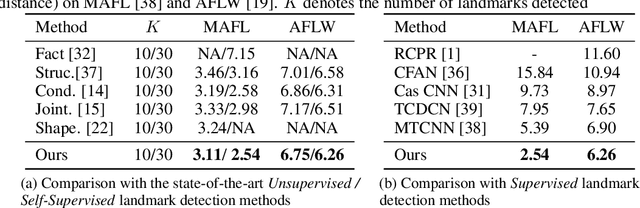
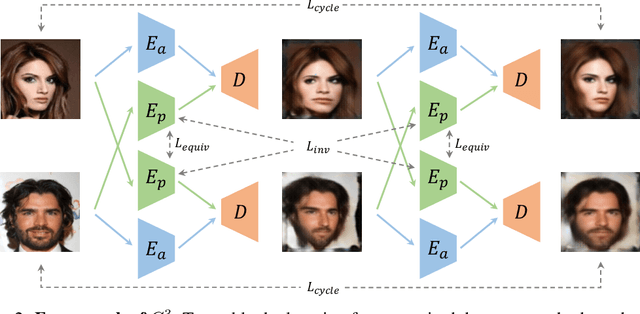
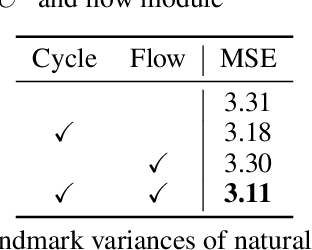
Recent attempts for unsupervised landmark learning leverage synthesized image pairs that are similar in appearance but different in poses. These methods learn landmarks by encouraging the consistency between the original images and the images reconstructed from swapped appearances and poses. While synthesized image pairs are created by applying pre-defined transformations, they can not fully reflect the real variances in both appearances and poses. In this paper, we aim to open the possibility of learning landmarks on unpaired data (i.e. unaligned image pairs) sampled from a natural image collection, so that they can be different in both appearances and poses. To this end, we propose a cross-image cycle consistency framework ($C^3$) which applies the swapping-reconstruction strategy twice to obtain the final supervision. Moreover, a cross-image flow module is further introduced to impose the equivariance between estimated landmarks across images. Through comprehensive experiments, our proposed framework is shown to outperform strong baselines by a large margin. Besides quantitative results, we also provide visualization and interpretation on our learned models, which not only verifies the effectiveness of the learned landmarks, but also leads to important insights that are beneficial for future research.
Chaining Identity Mapping Modules for Image Denoising
Dec 08, 2017

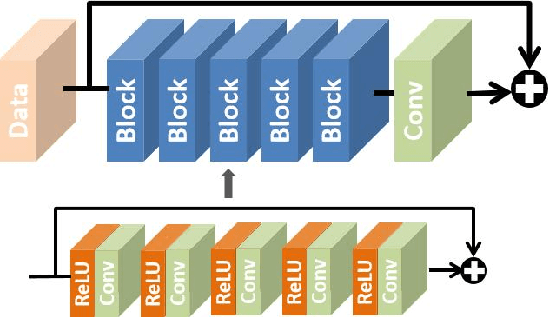

We propose to learn a fully-convolutional network model that consists of a Chain of Identity Mapping Modules (CIMM) for image denoising. The CIMM structure possesses two distinctive features that are important for the noise removal task. Firstly, each residual unit employs identity mappings as the skip connections and receives pre-activated input in order to preserve the gradient magnitude propagated in both the forward and backward directions. Secondly, by utilizing dilated kernels for the convolution layers in the residual branch, in other words within an identity mapping module, each neuron in the last convolution layer can observe the full receptive field of the first layer. After being trained on the BSD400 dataset, the proposed network produces remarkably higher numerical accuracy and better visual image quality than the state-of-the-art when being evaluated on conventional benchmark images and the BSD68 dataset.