 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Noise-Equipped Convolutional Neural Networks
Dec 09, 2020

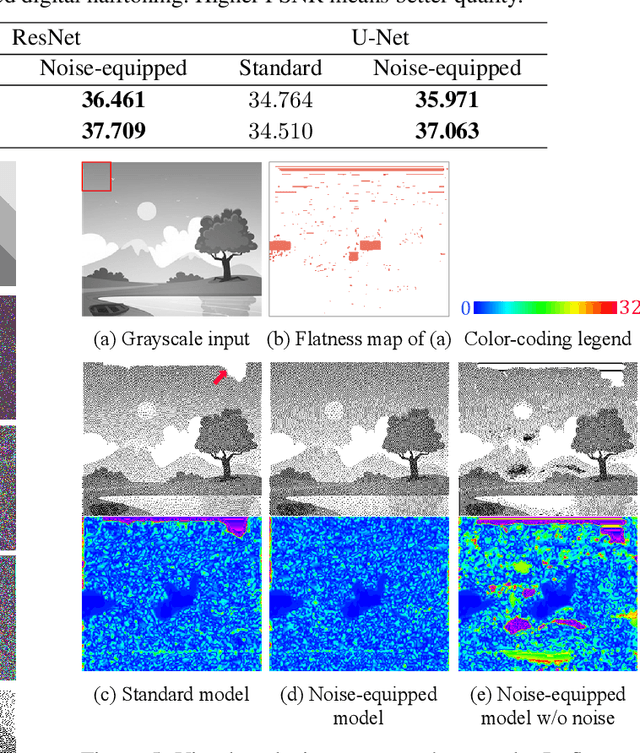
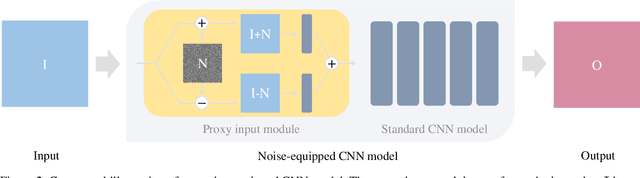

As a generic modeling tool, Convolutional Neural Network (CNN) has been widely employed in image synthesis and translation tasks. However, when a CNN model is fed with a flat input, the transformation degrades into a scaling operation due to the spatial sharing nature of convolution kernels. This inherent problem has been barely studied nor raised as an application restriction. In this paper, we point out that such convolution degradation actually hinders some specific image generation tasks that expect value-variant output from a flat input. We study the cause behind it and propose a generic solution to tackle it. Our key idea is to break the flat input condition through a proxy input module that perturbs the input data symmetrically with a noise map and reassembles them in feature domain. We call it noise-equipped CNN model and study its behavior through multiple analysis. Our experiments show that our model is free of degradation and hence serves as a superior alternative to standard CNN models. We further demonstrate improved performances of applying our model to existing applications, e.g. semantic photo synthesis and color-encoded grayscale generation.
Ordinal Distance Metric Learning with MDS for Image Ranking
Feb 27, 2019

Image ranking is to rank images based on some known ranked images. In this paper, we propose an improved linear ordinal distance metric learning approach based on the linear distance metric learning model. By decomposing the distance metric $A$ as $L^TL$, the problem can be cast as looking for a linear map between two sets of points in different spaces, meanwhile maintaining some data structures. The ordinal relation of the labels can be maintained via classical multidimensional scaling, a popular tool for dimension reduction in statistics. A least squares fitting term is then introduced to the cost function, which can also maintain the local data structure. The resulting model is an unconstrained problem, and can better fit the data structure. Extensive numerical results demonstrate the improvement of the new approach over the linear distance metric learning model both in speed and ranking performance.
ISP4ML: Understanding the Role of Image Signal Processing in Efficient Deep Learning Vision Systems
Nov 18, 2019

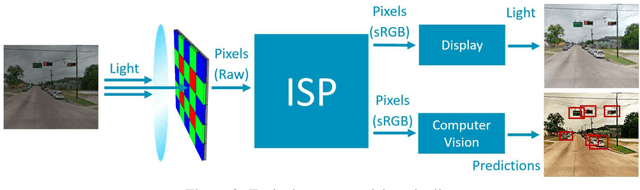
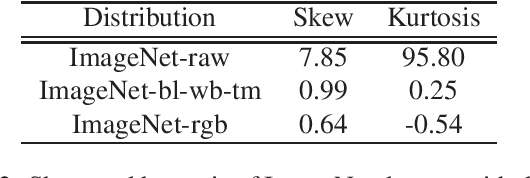
Convolutional neural networks (CNNs) are now predominant components in a variety of computer vision (CV) systems. These systems typically include an image signal processor (ISP), even though the ISP is traditionally designed to produce images that look appealing to humans. In CV systems, it is not clear what the role of the ISP is, or if it is even required at all for accurate prediction. In this work, we investigate the efficacy of the ISP in CNN classification tasks, and outline the system-level trade-offs between prediction accuracy and computational cost. To do so, we build software models of a configurable ISP and an imaging sensor in order to train CNNs on ImageNet with a range of different ISP settings and functionality. Results on ImageNet show that an ISP improves accuracy by 4.6%-12.2% on MobileNet architectures of different widths. Results using ResNets demonstrate that these trends also generalize to deeper networks. An ablation study of the various processing stages in a typical ISP reveals that the tone mapper is the most significant stage when operating on high dynamic range (HDR) images, by providing 5.8% average accuracy improvement alone. Overall, the ISP benefits system efficiency because the memory and computational costs of the ISP is minimal compared to the cost of using a larger CNN to achieve the same accuracy.
Dictionary learning based image enhancement for rarity detection
Sep 13, 2016
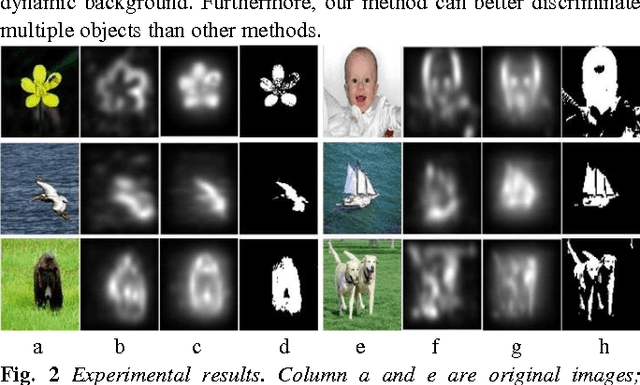
Image enhancement is an important image processing technique that processes images suitably for a specific application e.g. image editing. The conventional solutions of image enhancement are grouped into two categories which are spatial domain processing method and transform domain processing method such as contrast manipulation, histogram equalization, homomorphic filtering. This paper proposes a new image enhance method based on dictionary learning. Particularly, the proposed method adjusts the image by manipulating the rarity of dictionary atoms. Firstly, learn the dictionary through sparse coding algorithms on divided sub-image blocks. Secondly, compute the rarity of dictionary atoms on statistics of the corresponding sparse coefficients. Thirdly, adjust the rarity according to specific application and form a new dictionary. Finally, reconstruct the image using the updated dictionary and sparse coefficients. Compared with the traditional techniques, the proposed method enhances image based on the image content not on distribution of pixel grey value or frequency. The advantages of the proposed method lie in that it is in better correspondence with the response of the human visual system and more suitable for salient objects extraction. The experimental results demonstrate the effectiveness of the proposed image enhance method.
Unsupervised Learning of Dense Visual Representations
Nov 11, 2020


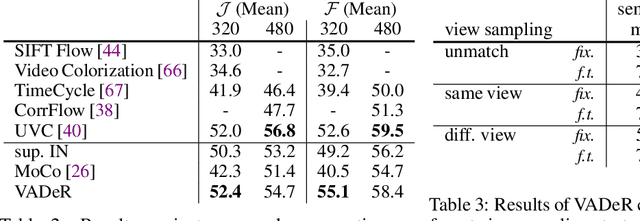
Contrastive self-supervised learning has emerged as a promising approach to unsupervised visual representation learning. In general, these methods learn global (image-level) representations that are invariant to different views (i.e., compositions of data augmentation) of the same image. However, many visual understanding tasks require dense (pixel-level) representations. In this paper, we propose View-Agnostic Dense Representation (VADeR) for unsupervised learning of dense representations. VADeR learns pixelwise representations by forcing local features to remain constant over different viewing conditions. Specifically, this is achieved through pixel-level contrastive learning: matching features (that is, features that describes the same location of the scene on different views) should be close in an embedding space, while non-matching features should be apart. VADeR provides a natural representation for dense prediction tasks and transfers well to downstream tasks. Our method outperforms ImageNet supervised pretraining (and strong unsupervised baselines) in multiple dense prediction tasks.
An Automatic System to Monitor the Physical Distance and Face Mask Wearing of Construction Workers in COVID-19 Pandemic
Jan 30, 2021

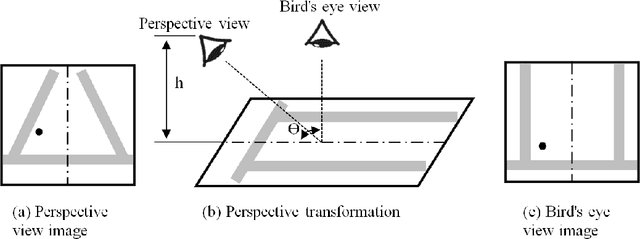
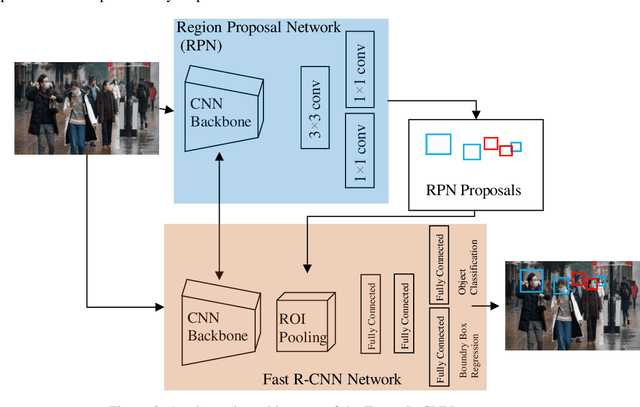
The COVID-19 pandemic has caused many shutdowns in different industries around the world. Sectors such as infrastructure construction and maintenance projects have not been suspended due to their significant effect on people's routine life. In such projects, workers work close together that makes a high risk of infection. The World Health Organization recommends wearing a face mask and practicing physical distancing to mitigate the virus's spread. This paper developed a computer vision system to automatically detect the violation of face mask wearing and physical distancing among construction workers to assure their safety on infrastructure projects during the pandemic. For the face mask detection, the paper collected and annotated 1,000 images, including different types of face mask wearing, and added them to a pre-existing face mask dataset to develop a dataset of 1,853 images. Then trained and tested multiple Tensorflow state-of-the-art object detection models on the face mask dataset and chose the Faster R-CNN Inception ResNet V2 network that yielded the accuracy of 99.8%. For physical distance detection, the paper employed the Faster R-CNN Inception V2 to detect people. A transformation matrix was used to eliminate the camera angle's effect on the object distances on the image. The Euclidian distance used the pixels of the transformed image to compute the actual distance between people. A threshold of six feet was considered to capture physical distance violation. The paper also used transfer learning for training the model. The final model was applied on four videos of road maintenance projects in Houston, TX, that effectively detected the face mask and physical distance. We recommend that construction owners use the proposed system to enhance construction workers' safety in the pandemic situation.
Carrying out CNN Channel Pruning in a White Box
Apr 24, 2021
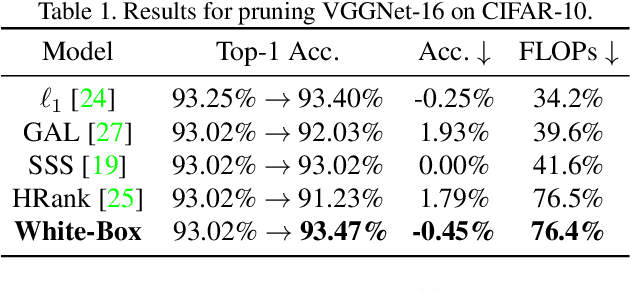
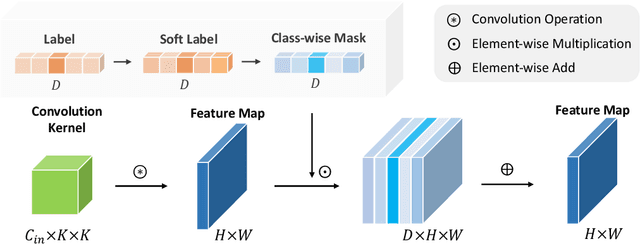
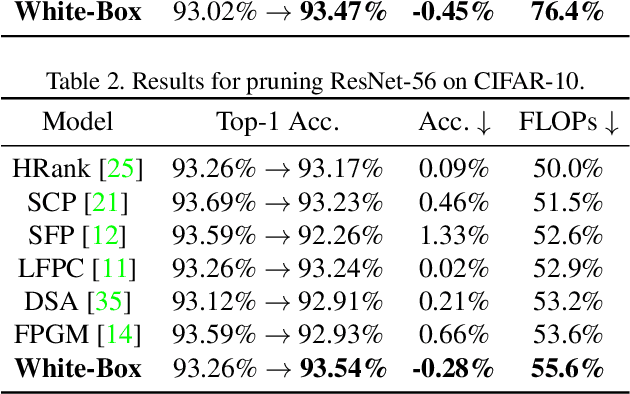
Channel Pruning has been long adopted for compressing CNNs, which significantly reduces the overall computation. Prior works implement channel pruning in an unexplainable manner, which tends to reduce the final classification errors while failing to consider the internal influence of each channel. In this paper, we conduct channel pruning in a white box. Through deep visualization of feature maps activated by different channels, we observe that different channels have a varying contribution to different categories in image classification. Inspired by this, we choose to preserve channels contributing to most categories. Specifically, to model the contribution of each channel to differentiating categories, we develop a class-wise mask for each channel, implemented in a dynamic training manner w.r.t. the input image's category. On the basis of the learned class-wise mask, we perform a global voting mechanism to remove channels with less category discrimination. Lastly, a fine-tuning process is conducted to recover the performance of the pruned model. To our best knowledge, it is the first time that CNN interpretability theory is considered to guide channel pruning. Extensive experiments demonstrate the superiority of our White-Box over many state-of-the-arts. For instance, on CIFAR-10, it reduces 65.23% FLOPs with even 0.62% accuracy improvement for ResNet-110. On ILSVRC-2012, White-Box achieves a 45.6% FLOPs reduction with only a small loss of 0.83% in the top-1 accuracy for ResNet-50. Code, training logs and pruned models are anonymously at https://github.com/zyxxmu/White-Box.
A Data-Driven Approach to Full-Field Damage and Failure Pattern Prediction in Microstructure-Dependent Composites using Deep Learning
Apr 09, 2021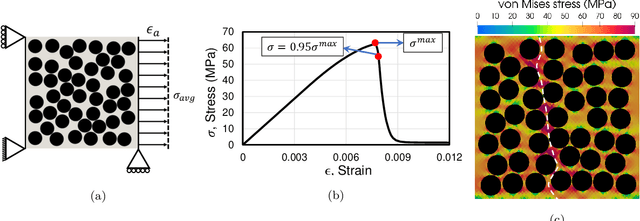
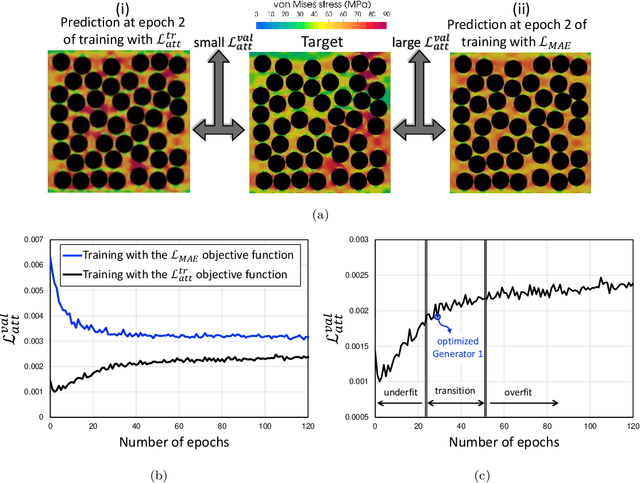

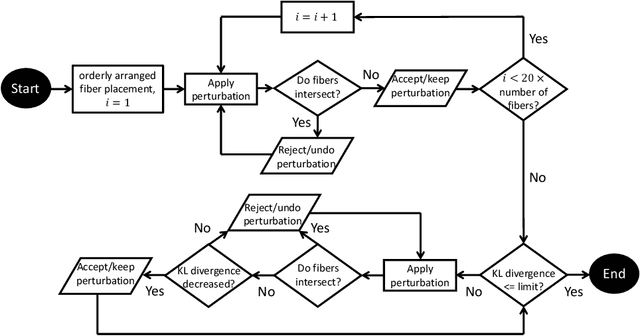
An image-based deep learning framework is developed in this paper to predict damage and failure in microstructure-dependent composite materials. The work is motivated by the complexity and computational cost of high-fidelity simulations of such materials. The proposed deep learning framework predicts the post-failure full-field stress distribution and crack pattern in two-dimensional representations of the composites based on the geometry of microstructures. The material of interest is selected to be a high-performance unidirectional carbon fiber-reinforced polymer composite. The deep learning framework contains two stacked fully-convolutional networks, namely, Generator 1 and Generator 2, trained sequentially. First, Generator 1 learns to translate the microstructural geometry to the full-field post-failure stress distribution. Then, Generator 2 learns to translate the output of Generator 1 to the failure pattern. A physics-informed loss function is also designed and incorporated to further improve the performance of the proposed framework and facilitate the validation process. In order to provide a sufficiently large data set for training and validating the deep learning framework, 4500 microstructural representations are synthetically generated and simulated in an efficient finite element framework. It is shown that the proposed deep learning approach can effectively predict the composites' post-failure full-field stress distribution and failure pattern, two of the most complex phenomena to simulate in computational solid mechanics.
Stochastic Image Deformation in Frequency Domain and Parameter Estimation using Moment Evolutions
Dec 13, 2018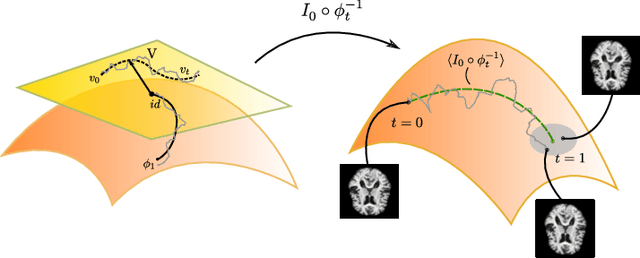
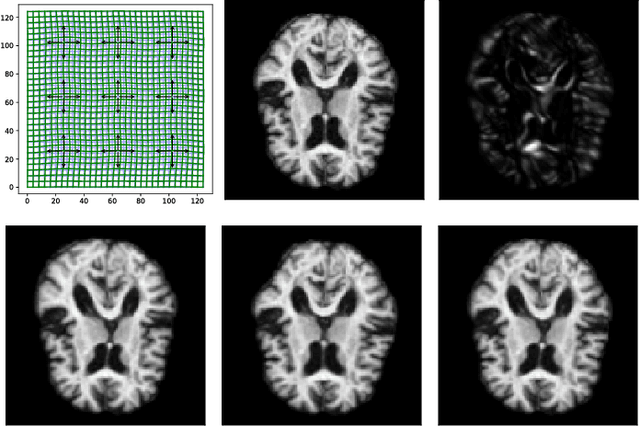
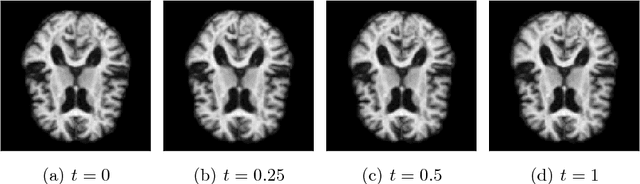
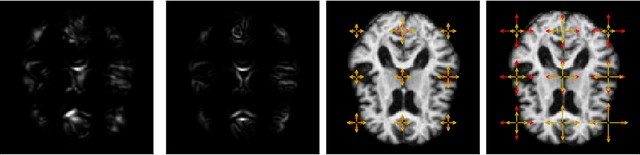
Modelling deformation of anatomical objects observed in medical images can help describe disease progression patterns and variations in anatomy across populations. We apply a stochastic generalisation of the Large Deformation Diffeomorphic Metric Mapping (LDDMM) framework to model differences in the evolution of anatomical objects detected in populations of image data. The computational challenges that are prevalent even in the deterministic LDDMM setting are handled by extending the FLASH LDDMM representation to the stochastic setting keeping a finite discretisation of the infinite dimensional space of image deformations. In this computationally efficient setting, we perform estimation to infer parameters for noise correlations and local variability in datasets of images. Fundamental for the optimisation procedure is using the finite dimensional Fourier representation to derive approximations of the evolution of moments for the stochastic warps. Particularly, the first moment allows us to infer deformation mean trajectories. The second moment encodes variation around the mean, and thus provides information on the noise correlation. We show on simulated datasets of 2D MR brain images that the estimation algorithm can successfully recover parameters of the stochastic model.
A Hybrid Quantum enabled RBM Advantage: Convolutional Autoencoders For Quantum Image Compression and Generative Learning
Jan 31, 2020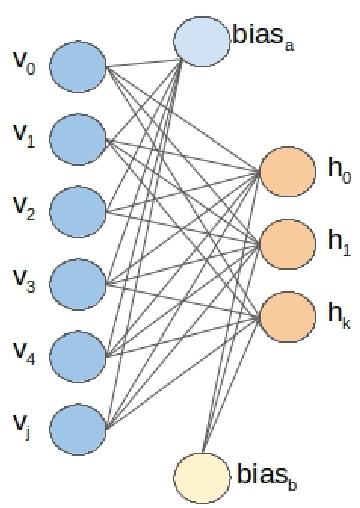

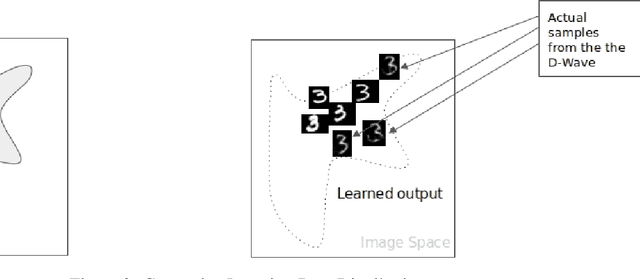

Understanding how the D-Wave quantum computer could be used for machine learning problems is of growing interest. Our work evaluates the feasibility of using the D-Wave as a sampler for machine learning. We describe a hybrid system that combines a classical deep neural network autoencoder with a quantum annealing Restricted Boltzmann Machine (RBM) using the D-Wave. We evaluate our hybrid autoencoder algorithm using two datasets, the MNIST dataset and MNIST Fashion dataset. We evaluate the quality of this method by using a downstream classification method where the training is based on quantum RBM-generated samples. Our method overcomes two key limitations in the current 2000-qubit D-Wave processor, namely the limited number of qubits available to accommodate typical problem sizes for fully connected quantum objective functions and samples that are binary pixel representations. As a consequence of these limitations we are able to show how we achieved nearly a 22-fold compression factor of grayscale 28 x 28 sized images to binary 6 x 6 sized images with a lossy recovery of the original 28 x 28 grayscale images. We further show how generating samples from the D-Wave after training the RBM, resulted in 28 x 28 images that were variations of the original input data distribution, as opposed to recreating the training samples. We formulated an MNIST classification problem using a deep convolutional neural network that used samples from a quantum RBM to train the MNIST classifier and compared the results with an MNIST classifier trained with the original MNIST training data set, as well as an MNIST classifier trained using classical RBM samples. Our hybrid autoencoder approach indicates advantage for RBM results relative to the use of a current RBM classical computer implementation for image-based machine learning and even more promising results for the next generation D-Wave quantum system.