 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Convolutional neural network stacking for medical image segmentation in CT scans
Jul 23, 2019
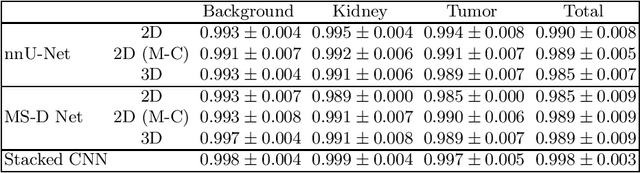
Computed tomography (CT) data poses many challenges to medical image segmentation based on convolutional neural networks(CNNs). The main challenges in handling CT scans with CNN are the scale of data (large range of Hounsfield Units) and the processing of the slices. In this paper, we consider a framework, which addresses these demands regarding the data pre-processing, the data augmentation, and the CNN architecture itself. For this purpose, we present a data preprocessing and an augmentation method tailored to CT data. We evaluate and compare different input dimensionalities and two different CNN architectures. One of the architectures is a modified U-Net and the other a modified Mixed-Scale Dense Network (MS-D Net). Thus, we compare dilated convolutions for parallel multi-scale processing to the U-Net approach with traditional scaling operations based on the different input dimensionalities. Finally, we merge a set of 3D modified MS-D Nets and a set of 2D modified U-Nets as a stacked CNN-model to combine the different strengths of both model.
Robust Rational Polynomial Camera Modelling for SAR and Pushbroom Imaging
Feb 26, 2021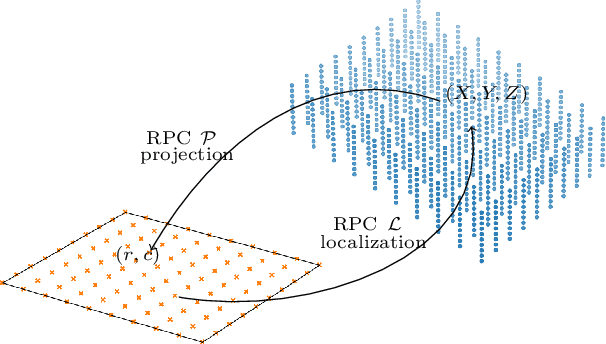
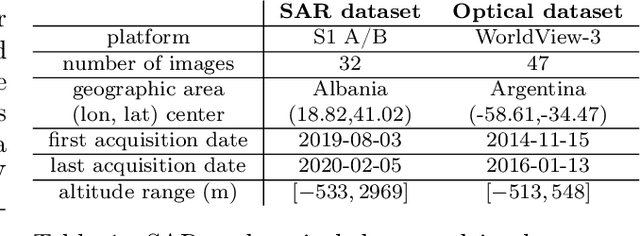
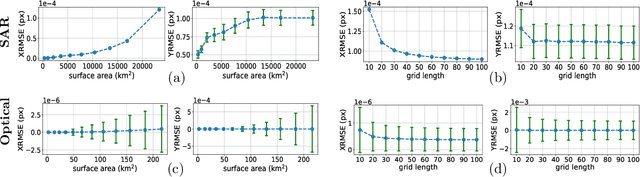
The Rational Polynomial Camera (RPC) model can be used to describe a variety of image acquisition systems in remote sensing, notably optical and Synthetic Aperture Radar (SAR) sensors. RPC functions relate 3D to 2D coordinates and vice versa, regardless of physical sensor specificities, which has made them an essential tool to harness satellite images in a generic way. This article describes a terrain-independent algorithm to accurately derive a RPC model from a set of 3D-2D point correspondences based on a regularized least squares fit. The performance of the method is assessed by varying the point correspondences and the size of the area that they cover. We test the algorithm on SAR and optical data, to derive RPCs from physical sensor models or from other RPC models after composition with corrective functions.
Contrastive Representation Learning for Whole Brain Cytoarchitectonic Mapping in Histological Human Brain Sections
Nov 25, 2020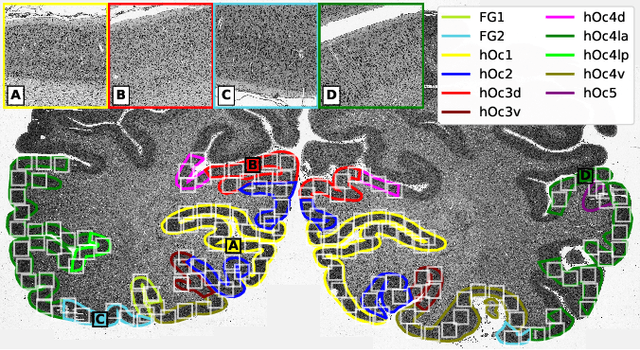
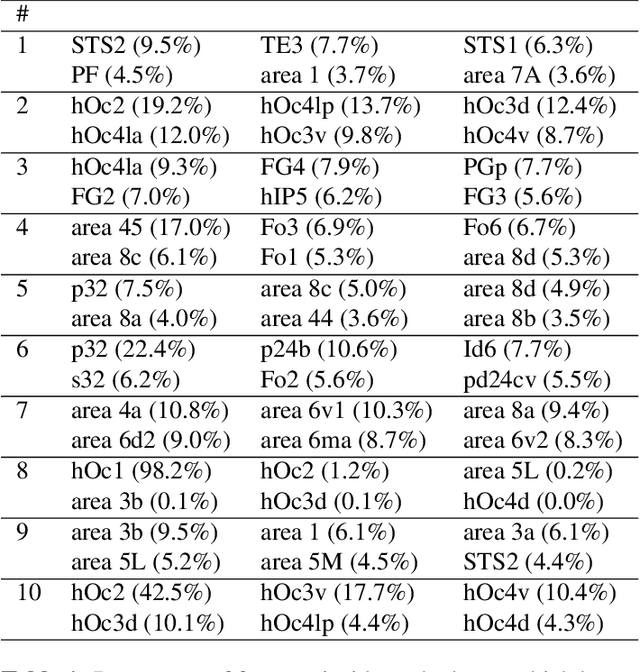
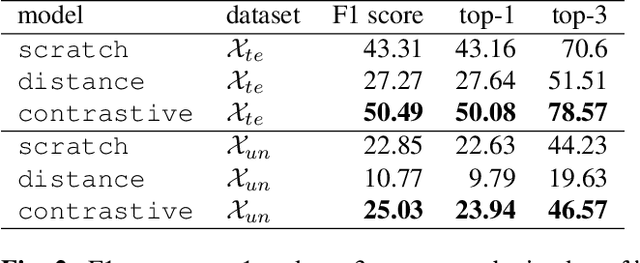
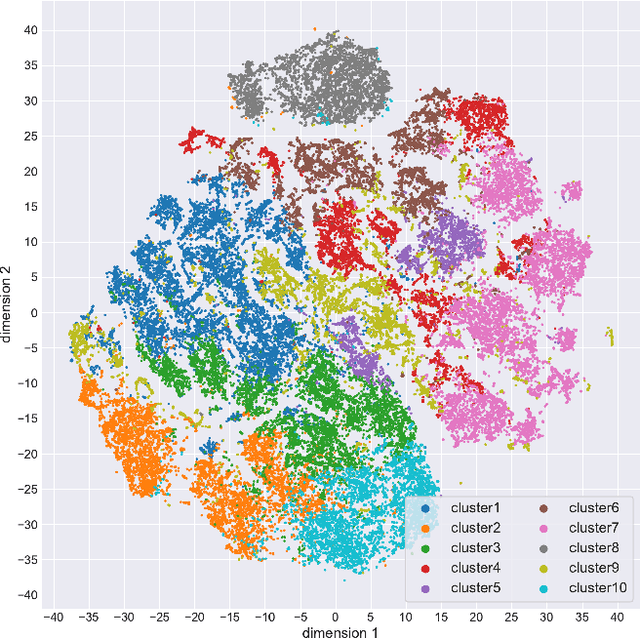
Cytoarchitectonic maps provide microstructural reference parcellations of the brain, describing its organization in terms of the spatial arrangement of neuronal cell bodies as measured from histological tissue sections. Recent work provided the first automatic segmentations of cytoarchitectonic areas in the visual system using Convolutional Neural Networks. We aim to extend this approach to become applicable to a wider range of brain areas, envisioning a solution for mapping the complete human brain. Inspired by recent success in image classification, we propose a contrastive learning objective for encoding microscopic image patches into robust microstructural features, which are efficient for cytoarchitectonic area classification. We show that a model pre-trained using this learning task outperforms a model trained from scratch, as well as a model pre-trained on a recently proposed auxiliary task. We perform cluster analysis in the feature space to show that the learned representations form anatomically meaningful groups.
A Closer Look at Self-training for Zero-Label Semantic Segmentation
Apr 21, 2021
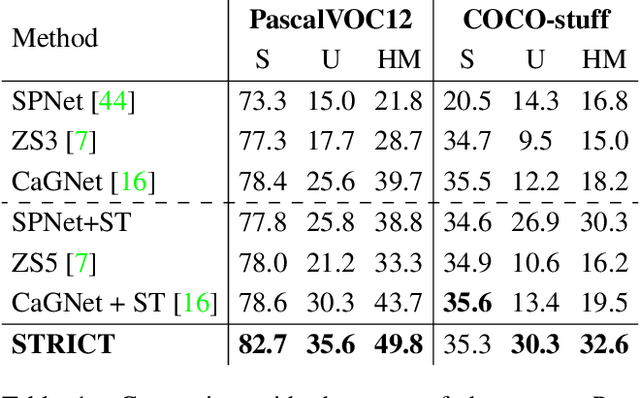
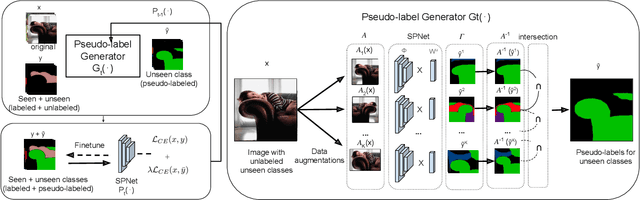
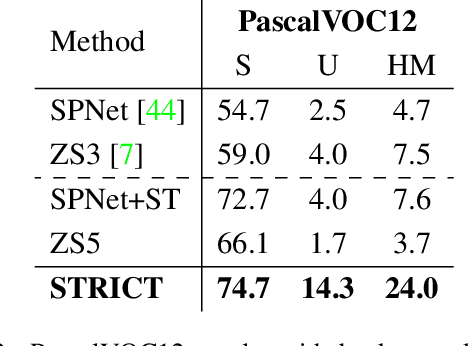
Being able to segment unseen classes not observed during training is an important technical challenge in deep learning, because of its potential to reduce the expensive annotation required for semantic segmentation. Prior zero-label semantic segmentation works approach this task by learning visual-semantic embeddings or generative models. However, they are prone to overfitting on the seen classes because there is no training signal for them. In this paper, we study the challenging generalized zero-label semantic segmentation task where the model has to segment both seen and unseen classes at test time. We assume that pixels of unseen classes could be present in the training images but without being annotated. Our idea is to capture the latent information on unseen classes by supervising the model with self-produced pseudo-labels for unlabeled pixels. We propose a consistency regularizer to filter out noisy pseudo-labels by taking the intersections of the pseudo-labels generated from different augmentations of the same image. Our framework generates pseudo-labels and then retrain the model with human-annotated and pseudo-labelled data. This procedure is repeated for several iterations. As a result, our approach achieves the new state-of-the-art on PascalVOC12 and COCO-stuff datasets in the challenging generalized zero-label semantic segmentation setting, surpassing other existing methods addressing this task with more complex strategies.
Minimal Solutions for Panoramic Stitching Given Gravity Prior
Dec 01, 2020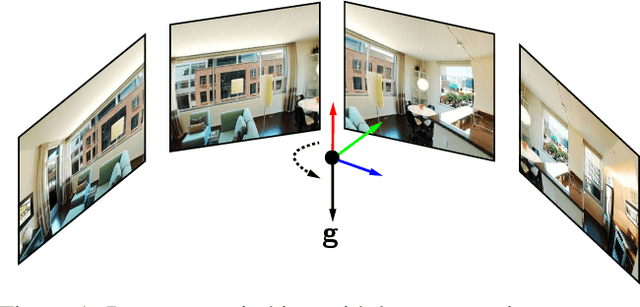
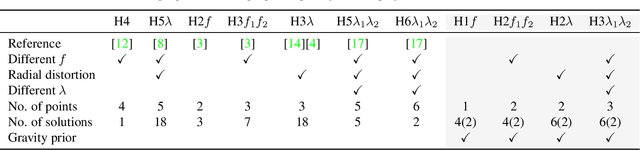

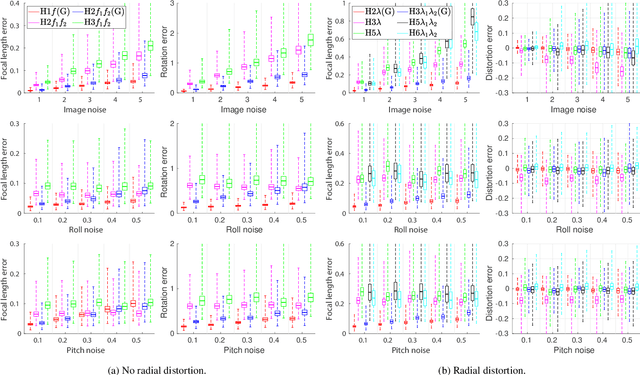
When capturing panoramas, people tend to align their cameras with the vertical axis, i.e., the direction of gravity. Moreover, modern devices, such as smartphones and tablets, are equipped with an IMU (Inertial Measurement Unit) that can measure the gravity vector accurately. Using this prior, the y-axes of the cameras can be aligned or assumed to be already aligned, reducing their relative orientation to 1-DOF (degree of freedom). Exploiting this assumption, we propose new minimal solutions to panoramic image stitching of images taken by cameras with coinciding optical centers, i.e., undergoing pure rotation. We consider four practical camera configurations, assuming unknown fixed or varying focal length with or without radial distortion. The solvers are tested both on synthetic scenes and on more than 500k real image pairs from the Sun360 dataset and from scenes captured by us using two smartphones equipped with IMUs. It is shown, that they outperform the state-of-the-art both in terms of accuracy and processing time.
Globally Optimal Relative Pose Estimation with Gravity Prior
Dec 01, 2020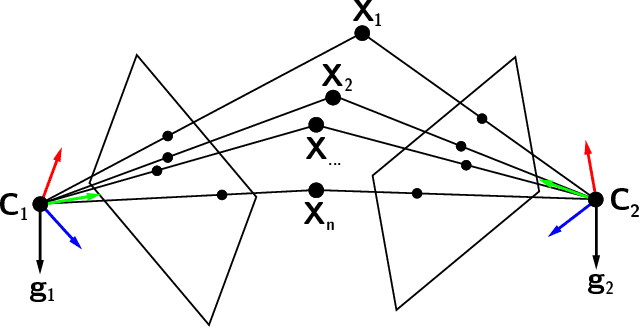
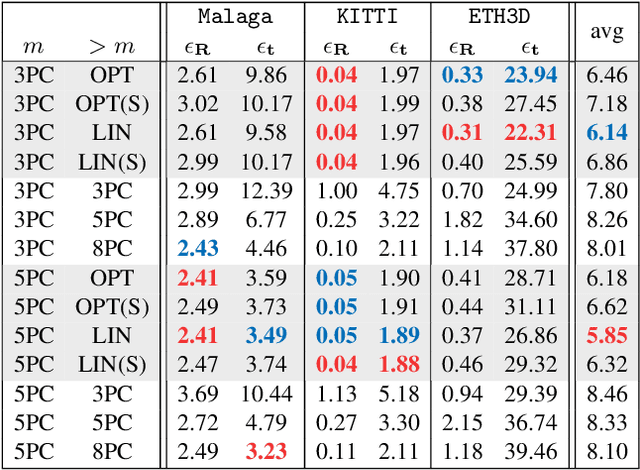
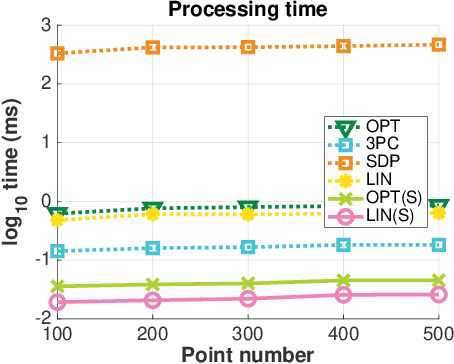
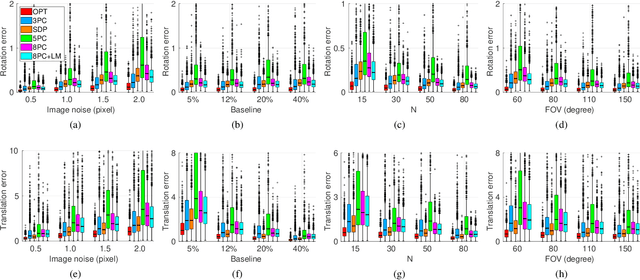
Smartphones, tablets and camera systems used, e.g., in cars and UAVs, are typically equipped with IMUs (inertial measurement units) that can measure the gravity vector accurately. Using this additional information, the $y$-axes of the cameras can be aligned, reducing their relative orientation to a single degree-of-freedom. With this assumption, we propose a novel globally optimal solver, minimizing the algebraic error in the least-squares sense, to estimate the relative pose in the over-determined case. Based on the epipolar constraint, we convert the optimization problem into solving two polynomials with only two unknowns. Also, a fast solver is proposed using the first-order approximation of the rotation. The proposed solvers are compared with the state-of-the-art ones on four real-world datasets with approx. 50000 image pairs in total. Moreover, we collected a dataset, by a smartphone, consisting of 10933 image pairs, gravity directions, and ground truth 3D reconstructions.
Non-Rigid Image Registration Using Self-Supervised Fully Convolutional Networks without Training Data
Jan 11, 2018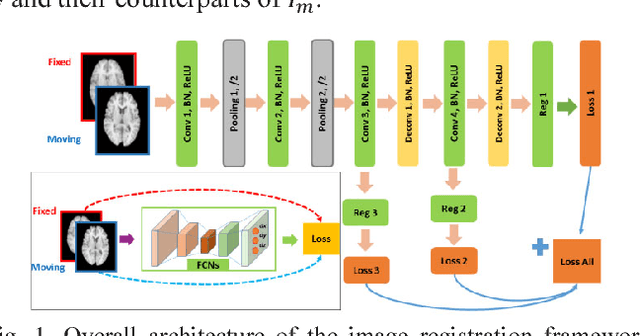
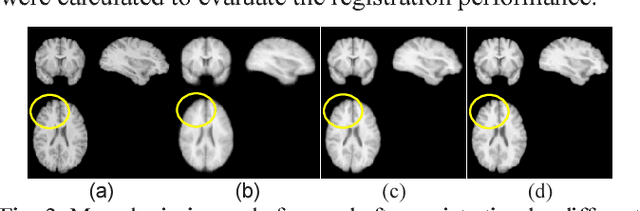
A novel non-rigid image registration algorithm is built upon fully convolutional networks (FCNs) to optimize and learn spatial transformations between pairs of images to be registered in a self-supervised learning framework. Different from most existing deep learning based image registration methods that learn spatial transformations from training data with known corresponding spatial transformations, our method directly estimates spatial transformations between pairs of images by maximizing an image-wise similarity metric between fixed and deformed moving images, similar to conventional image registration algorithms. The image registration is implemented in a multi-resolution image registration framework to jointly optimize and learn spatial transformations and FCNs at different spatial resolutions with deep self-supervision through typical feedforward and backpropagation computation. The proposed method has been evaluated for registering 3D structural brain magnetic resonance (MR) images and obtained better performance than state-of-the-art image registration algorithms.
Weather and Light Level Classification for Autonomous Driving: Dataset, Baseline and Active Learning
Apr 28, 2021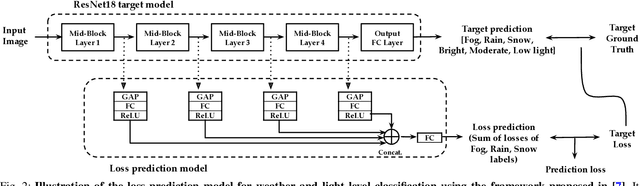
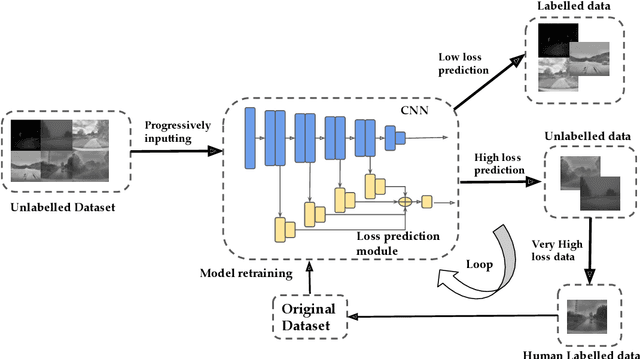
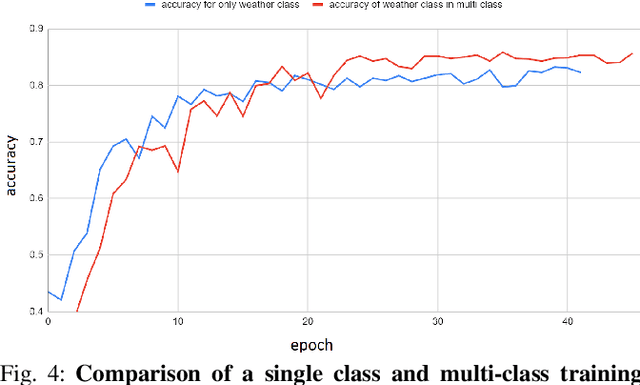
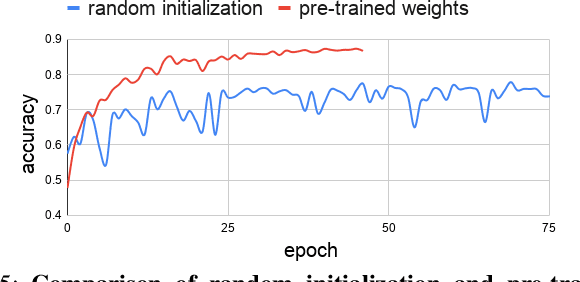
Autonomous driving is rapidly advancing, and Level 2 functions are becoming a standard feature. One of the foremost outstanding hurdles is to obtain robust visual perception in harsh weather and low light conditions where accuracy degradation is severe. It is critical to have a weather classification model to decrease visual perception confidence during these scenarios. Thus, we have built a new dataset for weather (fog, rain, and snow) classification and light level (bright, moderate, and low) classification. Furthermore, we provide street type (asphalt, grass, and cobblestone) classification, leading to 9 labels. Each image has three labels corresponding to weather, light level, and street type. We recorded the data utilizing an industrial front camera of RCCC (red/clear) format with a resolution of $1024\times1084$. We collected 15k video sequences and sampled 60k images. We implement an active learning framework to reduce the dataset's redundancy and find the optimal set of frames for training a model. We distilled the 60k images further to 1.1k images, which will be shared publicly after privacy anonymization. There is no public dataset for weather and light level classification focused on autonomous driving to the best of our knowledge. The baseline ResNet18 network used for weather classification achieves state-of-the-art results in two non-automotive weather classification public datasets but significantly lower accuracy on our proposed dataset, demonstrating it is not saturated and needs further research.
Towards Fast and Accurate Real-World Depth Super-Resolution: Benchmark Dataset and Baseline
Apr 13, 2021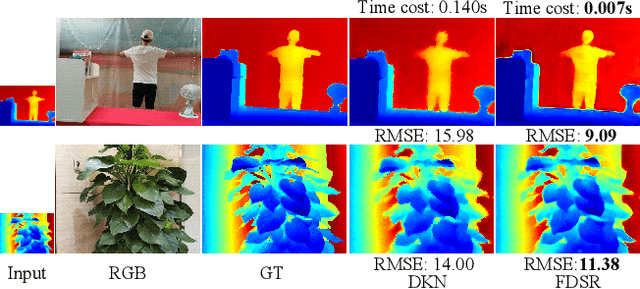


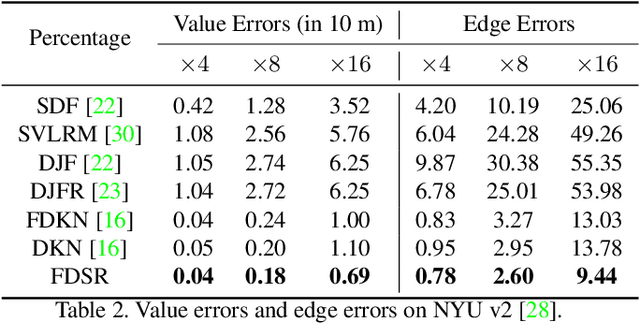
Depth maps obtained by commercial depth sensors are always in low-resolution, making it difficult to be used in various computer vision tasks. Thus, depth map super-resolution (SR) is a practical and valuable task, which upscales the depth map into high-resolution (HR) space. However, limited by the lack of real-world paired low-resolution (LR) and HR depth maps, most existing methods use downsampling to obtain paired training samples. To this end, we first construct a large-scale dataset named "RGB-D-D", which can greatly promote the study of depth map SR and even more depth-related real-world tasks. The "D-D" in our dataset represents the paired LR and HR depth maps captured from mobile phone and Lucid Helios respectively ranging from indoor scenes to challenging outdoor scenes. Besides, we provide a fast depth map super-resolution (FDSR) baseline, in which the high-frequency component adaptively decomposed from RGB image to guide the depth map SR. Extensive experiments on existing public datasets demonstrate the effectiveness and efficiency of our network compared with the state-of-the-art methods. Moreover, for the real-world LR depth maps, our algorithm can produce more accurate HR depth maps with clearer boundaries and to some extent correct the depth value errors.
Unsupervised Classification for Polarimetric SAR Data Using Variational Bayesian Wishart Mixture Model with Inverse Gamma-Gamma Prior
Apr 04, 2021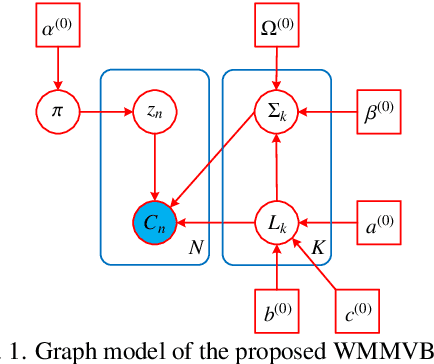
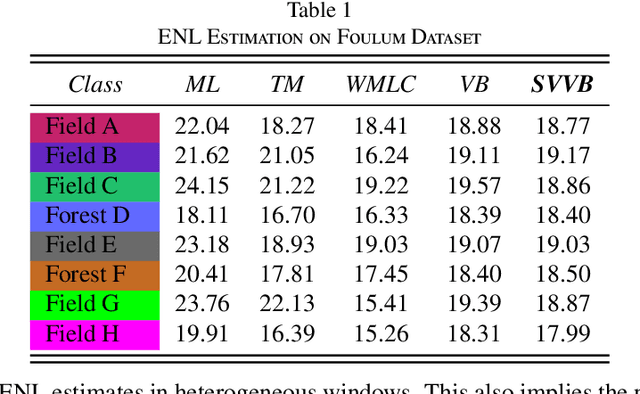
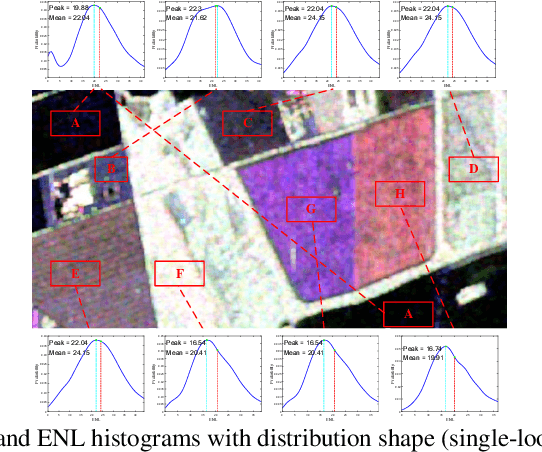
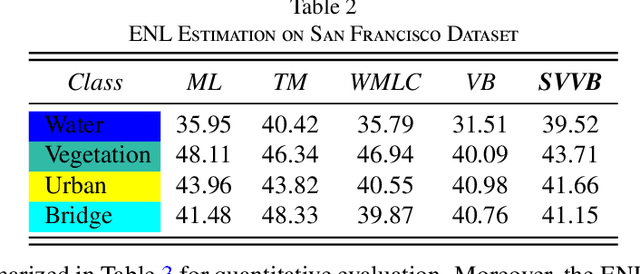
Although various clustering methods have been successfully applied to polarimetric synthetic aperture radar (PolSAR) image clustering tasks, most of the available approaches fail to realize automatic determination of cluster number, nor have they derived an exact distribution for the number of looks. To overcome these limitations and achieve robust unsupervised classification of PolSAR images, this paper proposes the variational Bayesian Wishart mixture model (VBWMM), where variational Bayesian expectation maximization (VBEM) technique is applied to estimate the variational posterior distribution of model parameters iteratively. Besides, covariance matrix similarity and geometric similarity are combined to incorporate spatial information of PolSAR images. Furthermore, we derive a new distribution named inverse gamma-gamma (IGG) prior that originates from the log-likelihood function of proposed model to enable efficient handling of number of looks. As a result, we obtain a closed-form variational lower bound, which can be used to evaluate the convergence of proposed model. We validate the superiority of proposed method in clustering performance on four real-measured datasets and demonstrate significant improvements towards conventional methods. As a by-product, the experiments show that our proposed IGG prior is effective in estimating the number of looks.