 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Semantic-Guided Inpainting Network for Complex Urban Scenes Manipulation
Oct 19, 2020
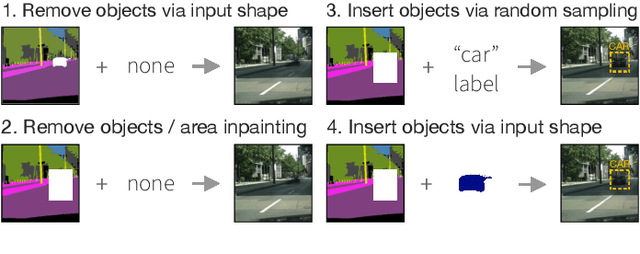



Manipulating images of complex scenes to reconstruct, insert and/or remove specific object instances is a challenging task. Complex scenes contain multiple semantics and objects, which are frequently cluttered or ambiguous, thus hampering the performance of inpainting models. Conventional techniques often rely on structural information such as object contours in multi-stage approaches that generate unreliable results and boundaries. In this work, we propose a novel deep learning model to alter a complex urban scene by removing a user-specified portion of the image and coherently inserting a new object (e.g. car or pedestrian) in that scene. Inspired by recent works on image inpainting, our proposed method leverages the semantic segmentation to model the content and structure of the image, and learn the best shape and location of the object to insert. To generate reliable results, we design a new decoder block that combines the semantic segmentation and generation task to guide better the generation of new objects and scenes, which have to be semantically consistent with the image. Our experiments, conducted on two large-scale datasets of urban scenes (Cityscapes and Indian Driving), show that our proposed approach successfully address the problem of semantically-guided inpainting of complex urban scene.
Spectral Image Visualization Using Generative Adversarial Networks
Feb 07, 2018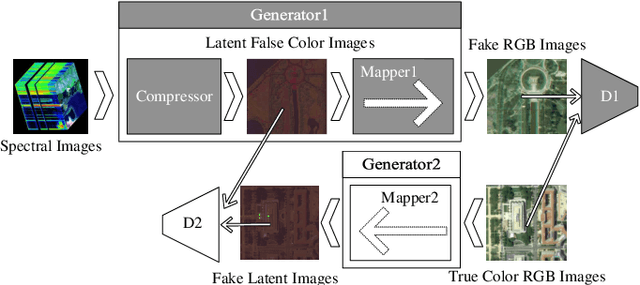

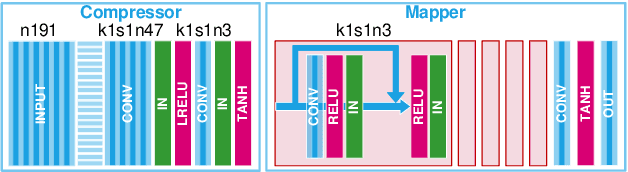

Spectral images captured by satellites and radio-telescopes are analyzed to obtain information about geological compositions distributions, distant asters as well as undersea terrain. Spectral images usually contain tens to hundreds of continuous narrow spectral bands and are widely used in various fields. But the vast majority of those image signals are beyond the visible range, which calls for special visualization technique. The visualizations of spectral images shall convey as much information as possible from the original signal and facilitate image interpretation. However, most of the existing visualizatio methods display spectral images in false colors, which contradict with human's experience and expectation. In this paper, we present a novel visualization generative adversarial network (GAN) to display spectral images in natural colors. To achieve our goal, we propose a loss function which consists of an adversarial loss and a structure loss. The adversarial loss pushes our solution to the natural image distribution using a discriminator network that is trained to differentiate between false-color images and natural-color images. We also use a cycle loss as the structure constraint to guarantee structure consistency. Experimental results show that our method is able to generate structure-preserved and natural-looking visualizations.
Learning with Neural Tangent Kernels in Near Input Sparsity Time
Apr 01, 2021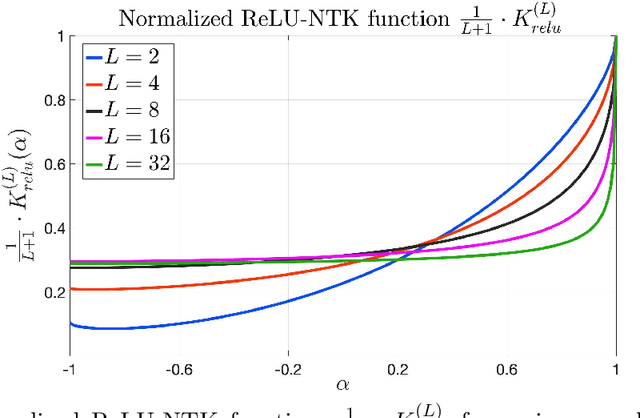
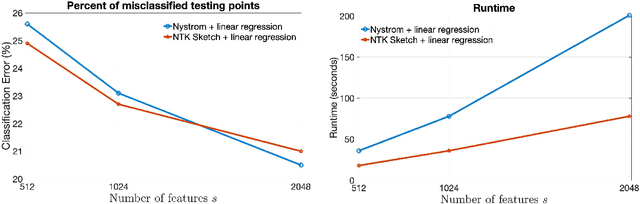
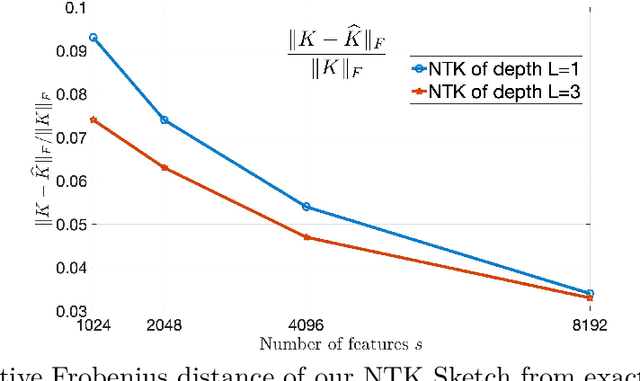
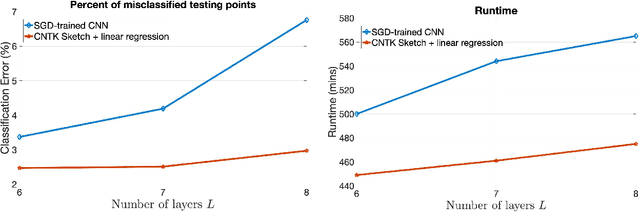
The Neural Tangent Kernel (NTK) characterizes the behavior of infinitely wide neural nets trained under least squares loss by gradient descent (Jacot et al., 2018). However, despite its importance, the super-quadratic runtime of kernel methods limits the use of NTK in large-scale learning tasks. To accelerate kernel machines with NTK, we propose a near input sparsity time algorithm that maps the input data to a randomized low-dimensional feature space so that the inner product of the transformed data approximates their NTK evaluation. Furthermore, we propose a feature map for approximating the convolutional counterpart of the NTK (Arora et al., 2019), which can transform any image using a runtime that is only linear in the number of pixels. We show that in standard large-scale regression and classification tasks a linear regressor trained on our features outperforms trained NNs and Nystrom method with NTK kernels.
Partial Domain Adaptation Using Selective Representation Learning For Class-Weight Computation
Jan 06, 2021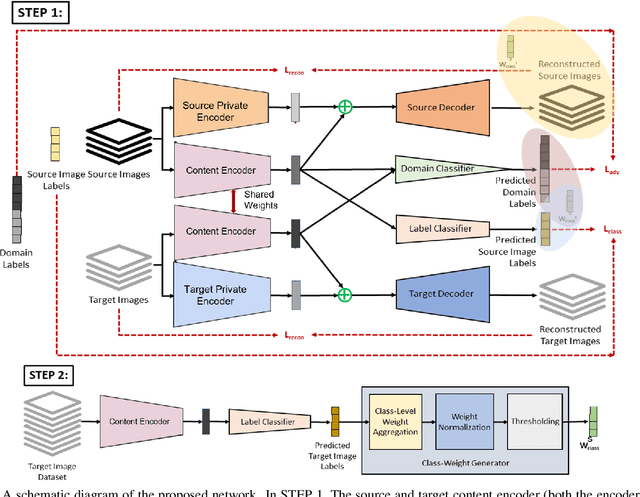
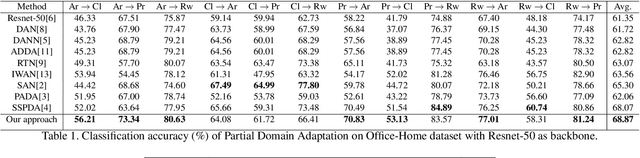
The generalization power of deep-learning models is dependent on rich-labelled data. This supervision using large-scaled annotated information is restrictive in most real-world scenarios where data collection and their annotation involve huge cost. Various domain adaptation techniques exist in literature that bridge this distribution discrepancy. However, a majority of these models require the label sets of both the domains to be identical. To tackle a more practical and challenging scenario, we formulate the problem statement from a partial domain adaptation perspective, where the source label set is a super set of the target label set. Driven by the motivation that image styles are private to each domain, in this work, we develop a method that identifies outlier classes exclusively from image content information and train a label classifier exclusively on class-content from source images. Additionally, elimination of negative transfer of samples from classes private to the source domain is achieved by transforming the soft class-level weights into two clusters, 0 (outlier source classes) and 1 (shared classes) by maximizing the between-cluster variance between them.
Image to Image Translation for Domain Adaptation
Dec 01, 2017

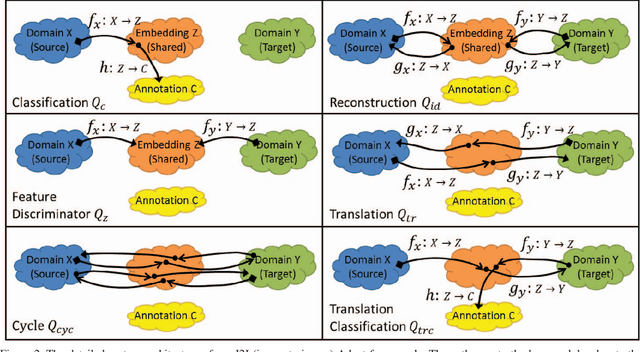
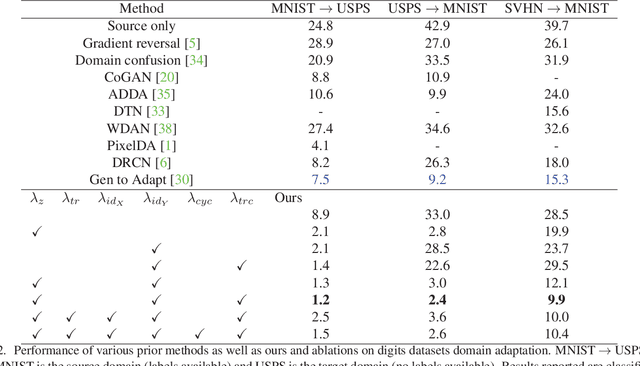
We propose a general framework for unsupervised domain adaptation, which allows deep neural networks trained on a source domain to be tested on a different target domain without requiring any training annotations in the target domain. This is achieved by adding extra networks and losses that help regularize the features extracted by the backbone encoder network. To this end we propose the novel use of the recently proposed unpaired image-toimage translation framework to constrain the features extracted by the encoder network. Specifically, we require that the features extracted are able to reconstruct the images in both domains. In addition we require that the distribution of features extracted from images in the two domains are indistinguishable. Many recent works can be seen as specific cases of our general framework. We apply our method for domain adaptation between MNIST, USPS, and SVHN datasets, and Amazon, Webcam and DSLR Office datasets in classification tasks, and also between GTA5 and Cityscapes datasets for a segmentation task. We demonstrate state of the art performance on each of these datasets.
Translate to Adapt: RGB-D Scene Recognition across Domains
Mar 26, 2021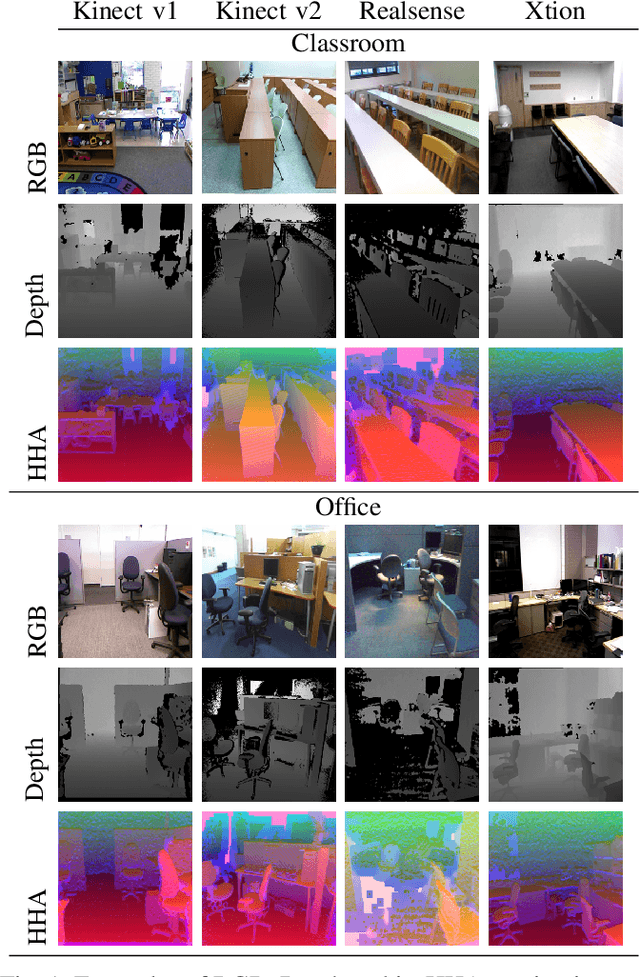
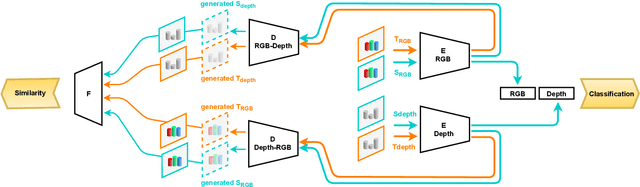
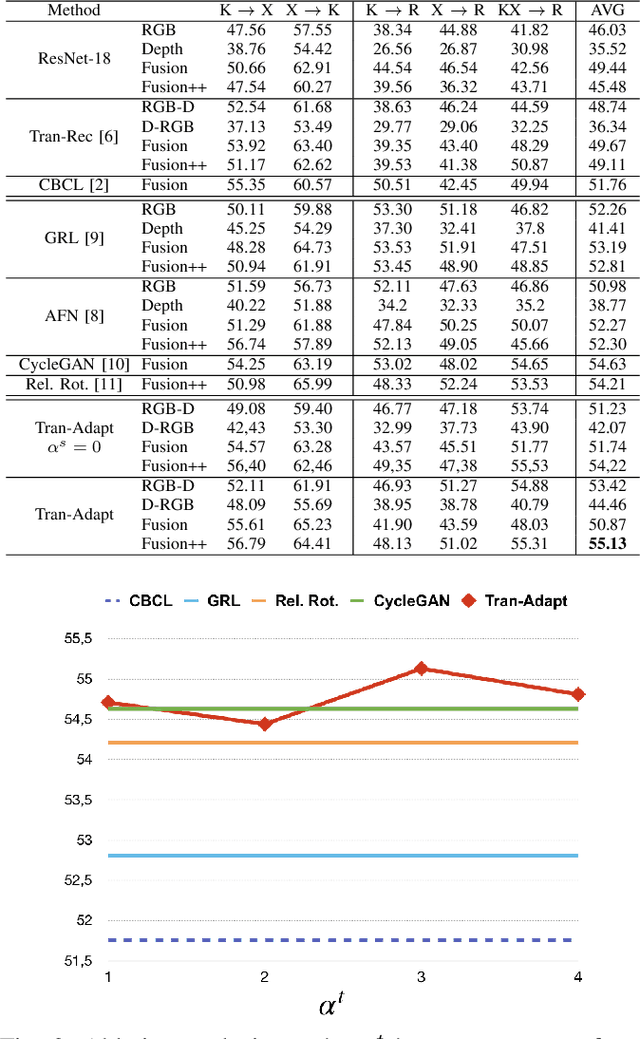

Scene classification is one of the basic problems in computer vision research with extensive applications in robotics. When available, depth images provide helpful geometric cues that complement the RGB texture information and help to identify more discriminative scene image features. Depth sensing technology developed fast in the last years and a great variety of 3D cameras have been introduced, each with different acquisition properties. However, when targeting big data collections, often multi-modal images are gathered disregarding their original nature. In this work we put under the spotlight the existence of a possibly severe domain shift issue within multi-modality scene recognition datasets. We design an experimental testbed to study this problem and present a method based on self-supervised inter-modality translation able to adapt across different camera domains. Our extensive experimental analysis confirms the effectiveness of the proposed approach.
Multi-Disease Detection in Retinal Imaging based on Ensembling Heterogeneous Deep Learning Models
Mar 26, 2021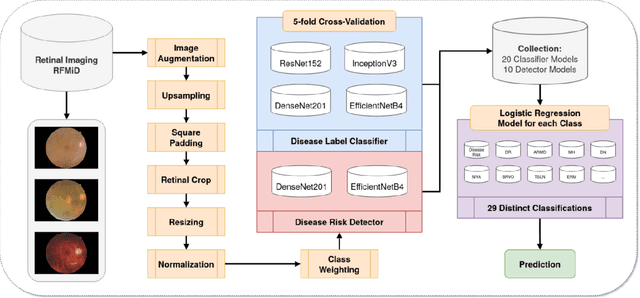
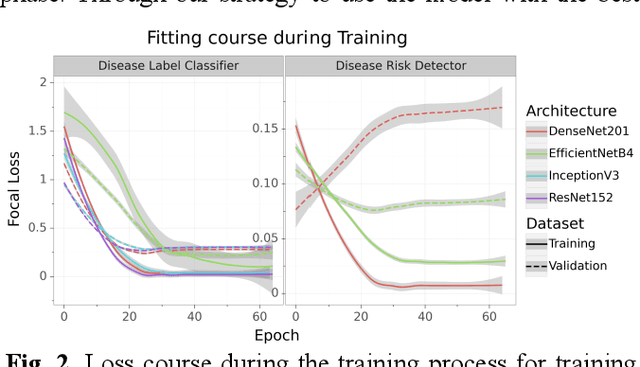
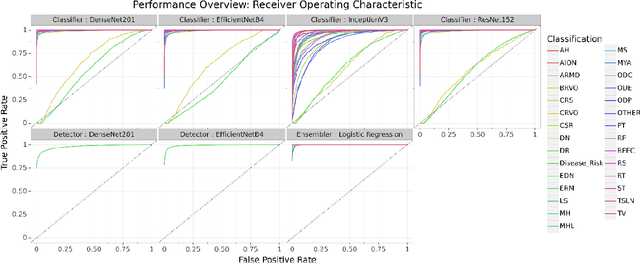
Preventable or undiagnosed visual impairment and blindness affect billion of people worldwide. Automated multi-disease detection models offer great potential to address this problem via clinical decision support in diagnosis. In this work, we proposed an innovative multi-disease detection pipeline for retinal imaging which utilizes ensemble learning to combine the predictive capabilities of several heterogeneous deep convolutional neural network models. Our pipeline includes state-of-the-art strategies like transfer learning, class weighting, real-time image augmentation and Focal loss utilization. Furthermore, we integrated ensemble learning techniques like heterogeneous deep learning models, bagging via 5-fold cross-validation and stacked logistic regression models. Through internal and external evaluation, we were able to validate and demonstrate high accuracy and reliability of our pipeline, as well as the comparability with other state-of-the-art pipelines for retinal disease prediction.
TRk-CNN: Transferable Ranking-CNN for image classification of glaucoma, glaucoma suspect, and normal eyes
May 16, 2019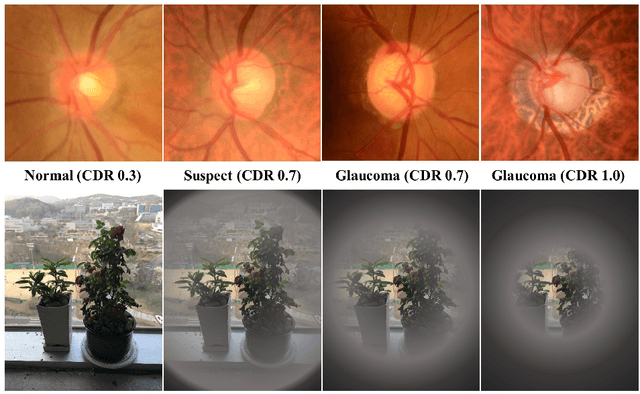
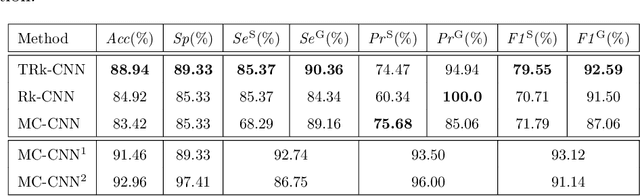
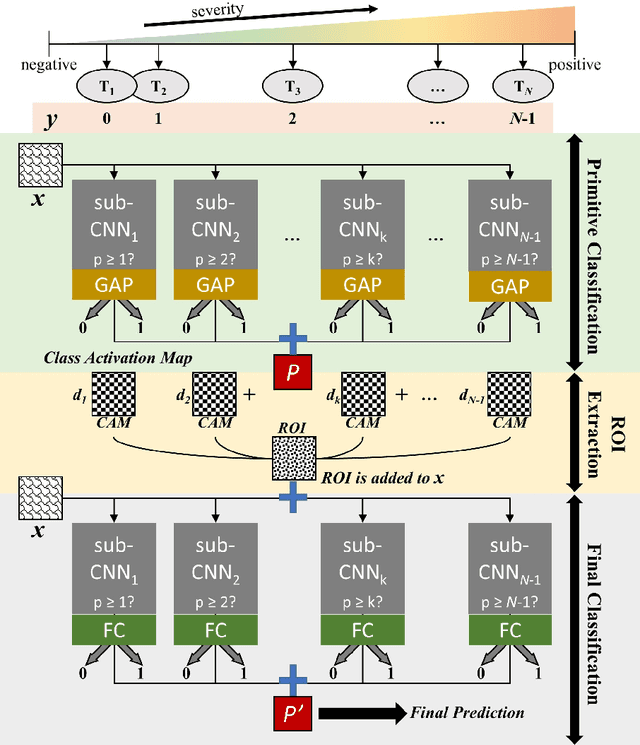
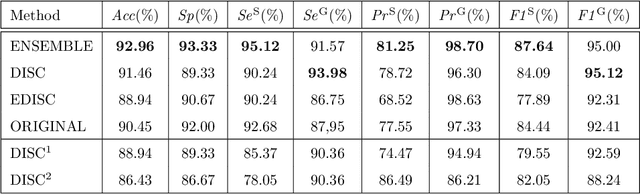
In this paper, we proposed Transferable Ranking Convolutional Neural Network (TRk-CNN) that can be effectively applied when the classes of images to be classified show a high correlation with each other. The multi-class classification method based on the softmax function, which is generally used, is not effective in this case because the inter-class relationship is ignored. Although there is a Ranking-CNN that takes into account the ordinal classes, it cannot reflect the inter-class relationship to the final prediction. TRk-CNN, on the other hand, combines the weights of the primitive classification model to reflect the inter-class information to the final classification phase. We evaluated TRk-CNN in glaucoma image dataset that was labeled into three classes: normal, glaucoma suspect, and glaucoma eyes. Based on the literature we surveyed, this study is the first to classify three status of glaucoma fundus image dataset into three different classes. We compared the evaluation results of TRk-CNN with Ranking-CNN (Rk-CNN) and multi-class CNN (MC-CNN) using the DenseNet as the backbone CNN model. As a result, TRk-CNN achieved an average accuracy of 92.96%, specificity of 93.33%, sensitivity for glaucoma suspect of 95.12% and sensitivity for glaucoma of 93.98%. Based on average accuracy, TRk-CNN is 8.04% and 9.54% higher than Rk-CNN and MC-CNN and surprisingly 26.83% higher for sensitivity for suspicious than multi-class CNN. Our TRk-CNN is expected to be effectively applied to the medical image classification problem where the disease state is continuous and increases in the positive class direction.
Generative Autoregressive Ensembles for Satellite Imagery Manipulation Detection
Oct 08, 2020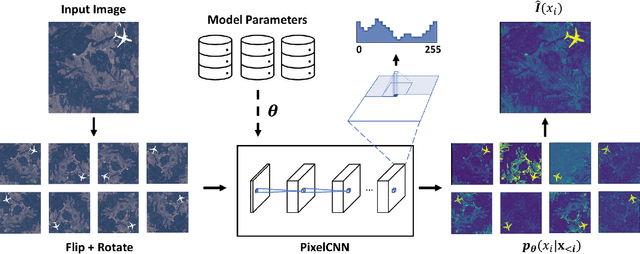

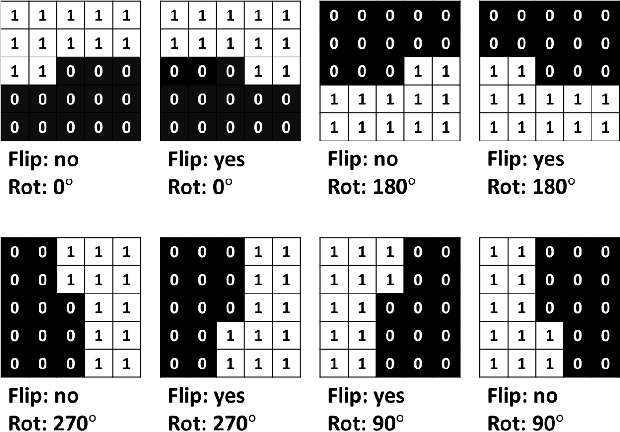
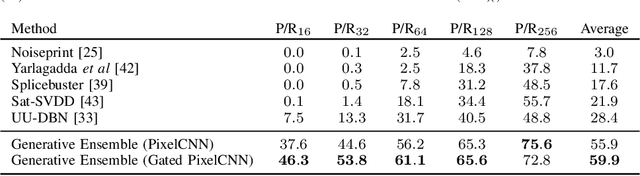
Satellite imagery is becoming increasingly accessible due to the growing number of orbiting commercial satellites. Many applications make use of such images: agricultural management, meteorological prediction, damage assessment from natural disasters, or cartography are some of the examples. Unfortunately, these images can be easily tampered and modified with image manipulation tools damaging downstream applications. Because the nature of the manipulation applied to the image is typically unknown, unsupervised methods that don't require prior knowledge of the tampering techniques used are preferred. In this paper, we use ensembles of generative autoregressive models to model the distribution of the pixels of the image in order to detect potential manipulations. We evaluate the performance of the presented approach obtaining accurate localization results compared to previously presented approaches.
Unsupervised End-to-end Learning for Deformable Medical Image Registration
Jan 20, 2018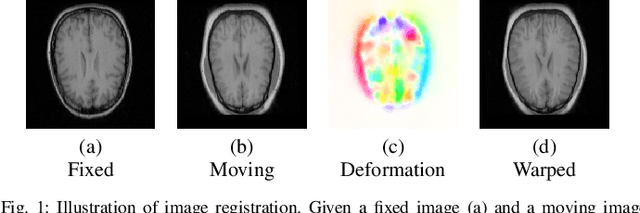
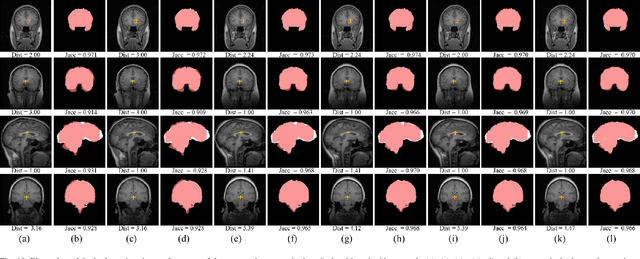
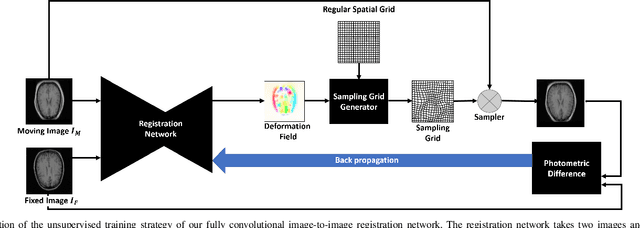
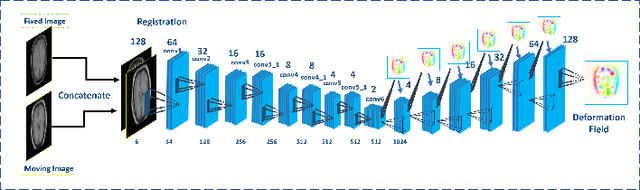
We propose a registration algorithm for 2D CT/MRI medical images with a new unsupervised end-to-end strategy using convolutional neural networks. The contributions of our algorithm are threefold: (1) We transplant traditional image registration algorithms to an end-to-end convolutional neural network framework, while maintaining the unsupervised nature of image registration problems. The image-to-image integrated framework can simultaneously learn both image features and transformation matrix for registration. (2) Training with additional data without any label can further improve the registration performance by approximately 10 %. (3) The registration speed is 100x faster than traditional methods. The proposed network is easy to implement and can be trained efficiently. Experiments demonstrate that our system achieves state-of-the-art results on 2D brain registration and achieves comparable results on 2D liver registration. It can be extended to register other organs beyond liver and brain such as kidney, lung, and heart.