 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Stacked Semantic-Guided Network for Zero-Shot Sketch-Based Image Retrieval
Apr 03, 2019
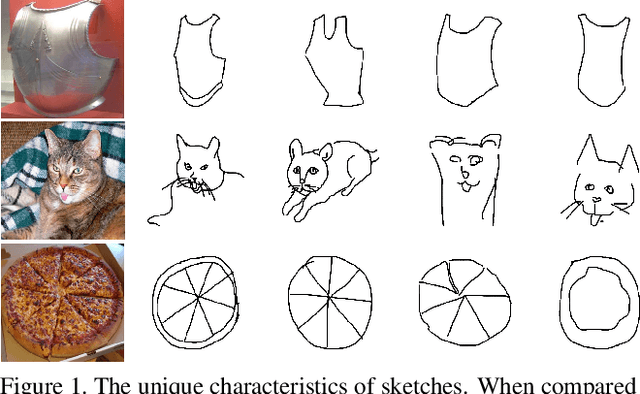
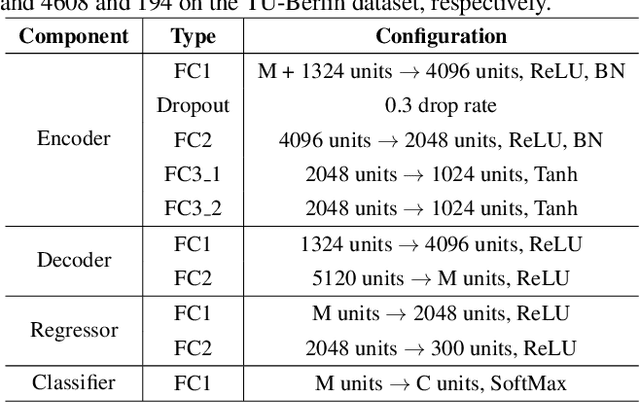
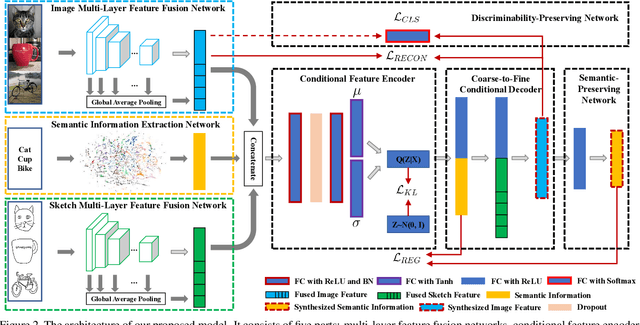
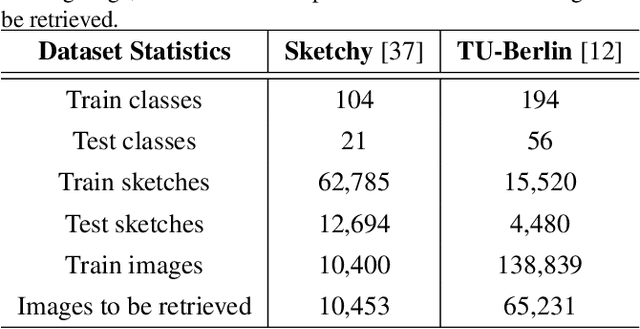
Zero-shot sketch-based image retrieval (ZS-SBIR) is a task of cross-domain image retrieval from a natural image gallery with free-hand sketch under a zero-shot scenario. Previous works mostly focus on a generative approach that takes a highly abstract and sparse sketch as input and then synthesizes the corresponding natural image. However, the intrinsic visual sparsity and large intra-class variance of the sketch make the learning of the conditional decoder more difficult and hence achieve unsatisfactory retrieval performance. In this paper, we propose a novel stacked semantic-guided network to address the unique characteristics of sketches in ZS-SBIR. Specifically, we devise multi-layer feature fusion networks that incorporate different intermediate feature representation information in a deep neural network to alleviate the intrinsic sparsity of sketches. In order to improve visual knowledge transfer from seen to unseen classes, we elaborate a coarse-to-fine conditional decoder that generates coarse-grained category-specific corresponding features first (taking auxiliary semantic information as conditional input) and then generates fine-grained instance-specific corresponding features (taking sketch representation as conditional input). Furthermore, regression loss and classification loss are utilized to preserve the semantic and discriminative information of the synthesized features respectively. Extensive experiments on the large-scale Sketchy dataset and TU-Berlin dataset demonstrate that our proposed approach outperforms state-of-the-art methods by more than 20\% in retrieval performance.
A CNN-RNN Framework for Image Annotation from Visual Cues and Social Network Metadata
Oct 13, 2019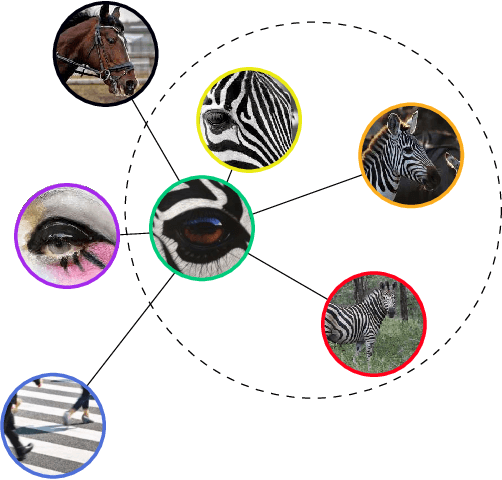
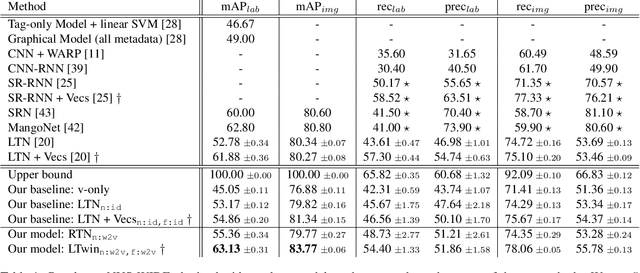
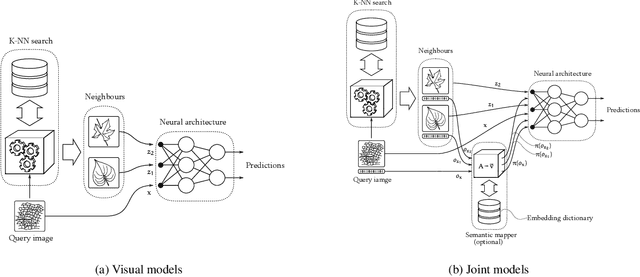
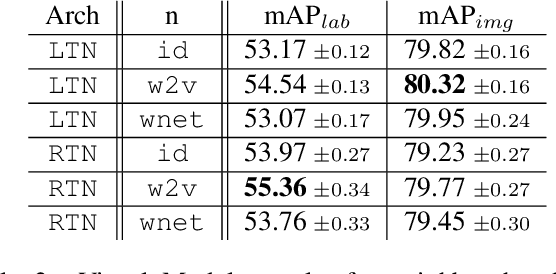
Images represent a commonly used form of visual communication among people. Nevertheless, image classification may be a challenging task when dealing with unclear or non-common images needing more context to be correctly annotated. Metadata accompanying images on social-media represent an ideal source of additional information for retrieving proper neighbourhoods easing image annotation task. To this end, we blend visual features extracted from neighbours and their metadata to jointly leverage context and visual cues. Our models use multiple semantic embeddings to properly map metadata to a meaningful semantic space decoupling the neural model from the low-level representation of metadata and achieve robustness to vocabulary changes between training and testing phases. Convolutional and recurrent neural networks (CNNs-RNNs) are jointly adopted to infer similarity among neighbours and query images. We perform comprehensive experiments on the NUS-WIDE dataset showing that our models outperform state-of-the-art architectures based on images and metadata, and decrease both sensory and semantic gaps to better annotate images.
Poly-NL: Linear Complexity Non-local Layers with Polynomials
Jul 06, 2021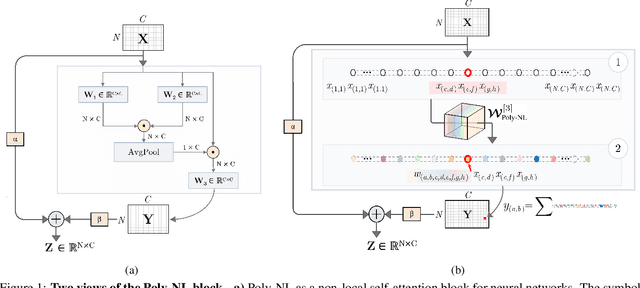
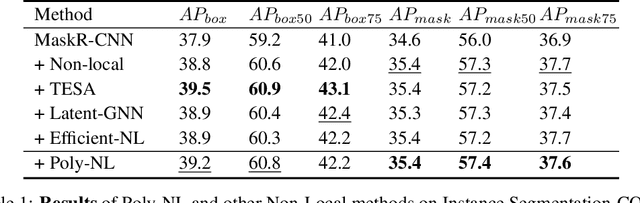
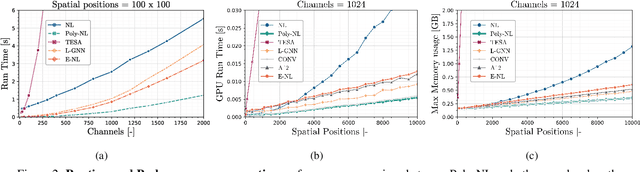
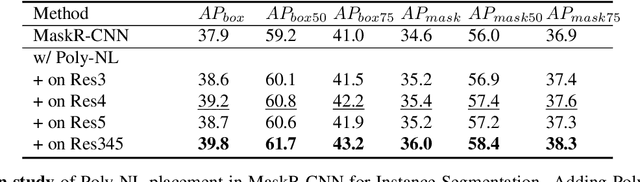
Spatial self-attention layers, in the form of Non-Local blocks, introduce long-range dependencies in Convolutional Neural Networks by computing pairwise similarities among all possible positions. Such pairwise functions underpin the effectiveness of non-local layers, but also determine a complexity that scales quadratically with respect to the input size both in space and time. This is a severely limiting factor that practically hinders the applicability of non-local blocks to even moderately sized inputs. Previous works focused on reducing the complexity by modifying the underlying matrix operations, however in this work we aim to retain full expressiveness of non-local layers while keeping complexity linear. We overcome the efficiency limitation of non-local blocks by framing them as special cases of 3rd order polynomial functions. This fact enables us to formulate novel fast Non-Local blocks, capable of reducing the complexity from quadratic to linear with no loss in performance, by replacing any direct computation of pairwise similarities with element-wise multiplications. The proposed method, which we dub as "Poly-NL", is competitive with state-of-the-art performance across image recognition, instance segmentation, and face detection tasks, while having considerably less computational overhead.
Learned Perceptual Image Enhancement
Dec 07, 2017
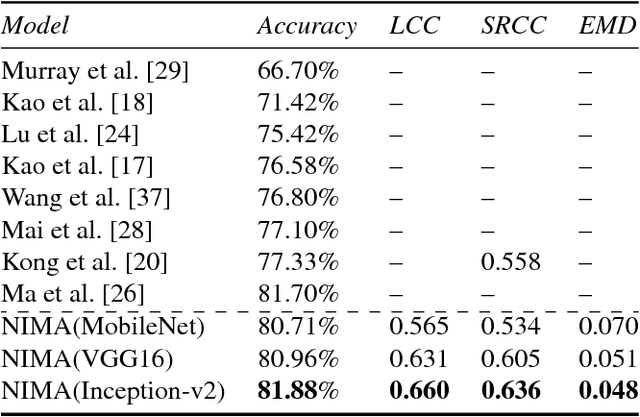
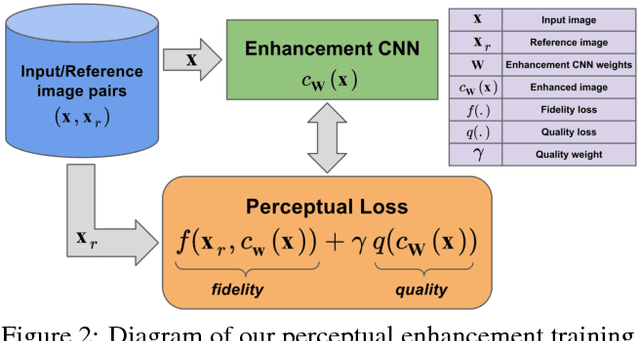
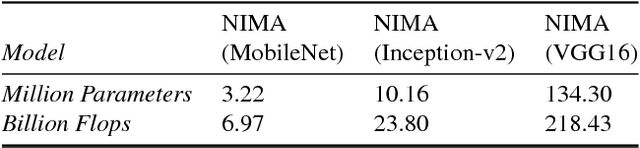
Learning a typical image enhancement pipeline involves minimization of a loss function between enhanced and reference images. While L1 and L2 losses are perhaps the most widely used functions for this purpose, they do not necessarily lead to perceptually compelling results. In this paper, we show that adding a learned no-reference image quality metric to the loss can significantly improve enhancement operators. This metric is implemented using a CNN (convolutional neural network) trained on a large-scale dataset labelled with aesthetic preferences of human raters. This loss allows us to conveniently perform back-propagation in our learning framework to simultaneously optimize for similarity to a given ground truth reference and perceptual quality. This perceptual loss is only used to train parameters of image processing operators, and does not impose any extra complexity at inference time. Our experiments demonstrate that this loss can be effective for tuning a variety of operators such as local tone mapping and dehazing.
Knowing What VQA Does Not: Pointing to Error-Inducing Regions to Improve Explanation Helpfulness
Mar 31, 2021
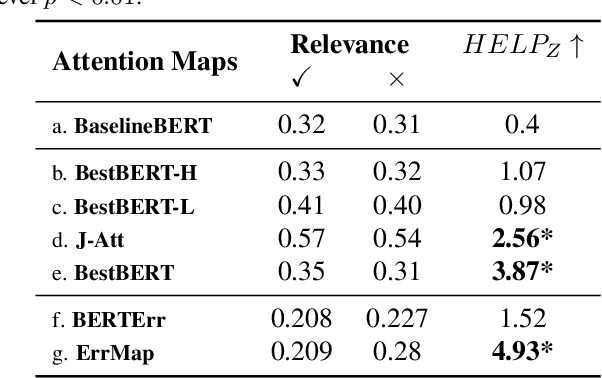

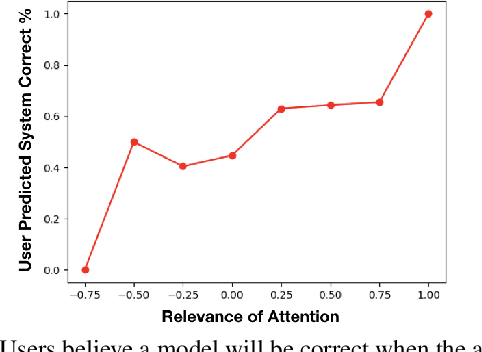
Attention maps, a popular heatmap-based explanation method for Visual Question Answering (VQA), are supposed to help users understand the model by highlighting portions of the image/question used by the model to infer answers. However, we see that users are often misled by current attention map visualizations that point to relevant regions despite the model producing an incorrect answer. Hence, we propose Error Maps that clarify the error by highlighting image regions where the model is prone to err. Error maps can indicate when a correctly attended region may be processed incorrectly leading to an incorrect answer, and hence, improve users' understanding of those cases. To evaluate our new explanations, we further introduce a metric that simulates users' interpretation of explanations to evaluate their potential helpfulness to understand model correctness. We finally conduct user studies to see that our new explanations help users understand model correctness better than baselines by an expected 30% and that our proxy helpfulness metrics correlate strongly ($\rho$>0.97) with how well users can predict model correctness.
A Low-Cost Neural ODE with Depthwise Separable Convolution for Edge Domain Adaptation on FPGAs
Jul 27, 2021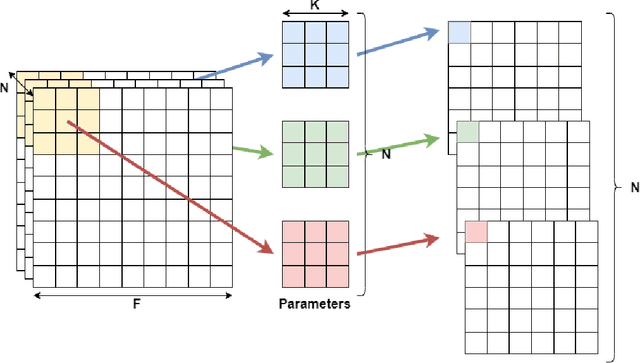

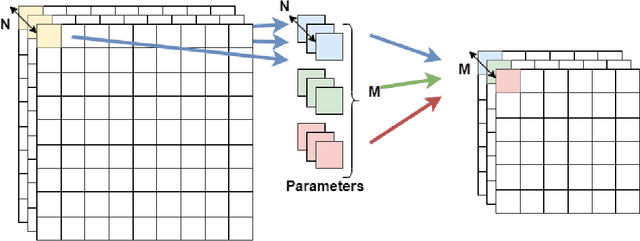
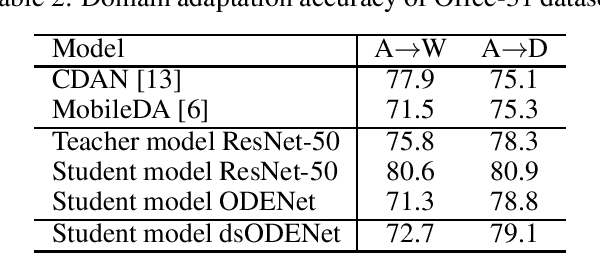
Although high-performance deep neural networks are in high demand in edge environments, computation resources are strictly limited in edge devices, and light-weight neural network techniques, such as Depthwise Separable Convolution (DSC), have been developed. ResNet is one of conventional deep neural network models that stack a lot of layers and parameters for a higher accuracy. To reduce the parameter size of ResNet, by utilizing a similarity to ODE (Ordinary Differential Equation), Neural ODE repeatedly uses most of weight parameters instead of having a lot of different parameters. Thus, Neural ODE becomes significantly small compared to that of ResNet so that it can be implemented in resource-limited edge devices. In this paper, a combination of Neural ODE and DSC, called dsODENet, is designed and implemented for FPGAs (Field-Programmable Gate Arrays). dsODENet is then applied to edge domain adaptation as a practical use case and evaluated with image classification datasets. It is implemented on Xilinx ZCU104 board and evaluated in terms of domain adaptation accuracy, training speed, FPGA resource utilization, and speedup rate compared to a software execution. The results demonstrate that dsODENet is comparable to or slightly better than our baseline Neural ODE implementation in terms of domain adaptation accuracy, while the total parameter size without pre- and post-processing layers is reduced by 54.2% to 79.8%. The FPGA implementation accelerates the prediction tasks by 27.9 times faster than a software implementation.
Image Set Classification for Low Resolution Surveillance
Mar 26, 2018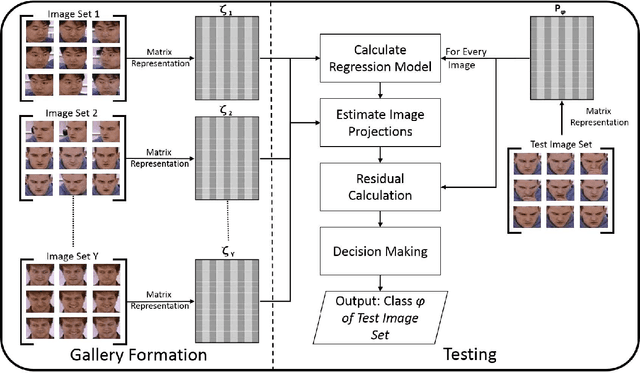
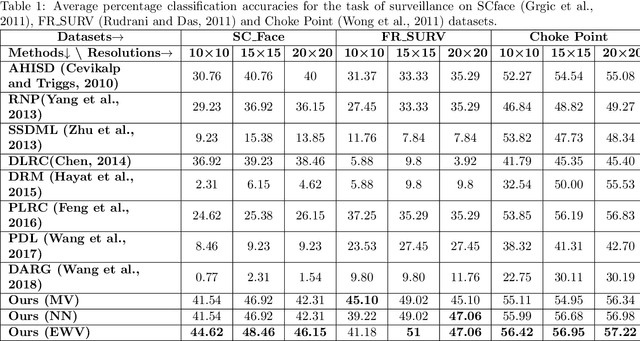
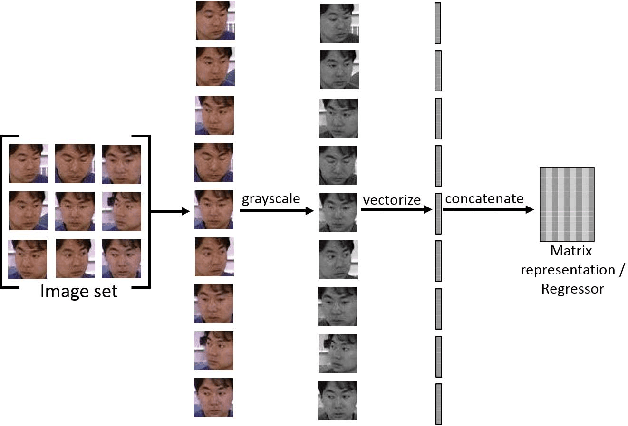
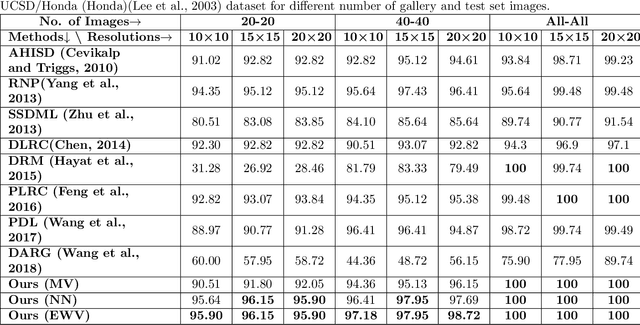
This paper proposes a novel image set classification technique based on the concept of linear regression. Unlike most other approaches, the proposed technique does not involve any training or feature extraction. The gallery image sets are represented as subspaces in a high dimensional space. Class specific gallery subspaces are used to estimate regression models for each image of the test image set. Images of the test set are then projected on the gallery subspaces. Residuals, calculated using the Euclidean distance between the original and the projected test images, are used as the distance metric. Three different strategies are devised to decide on the final class of the test image set. We performed extensive evaluations of the proposed technique under the challenges of low resolution, noise and less gallery data for the tasks of surveillance, video based face recognition and object recognition. Experiments show that the proposed technique achieves a better classification accuracy and a faster execution time under the challenging testing conditions.
Learning Deep Morphological Networks with Neural Architecture Search
Jun 14, 2021

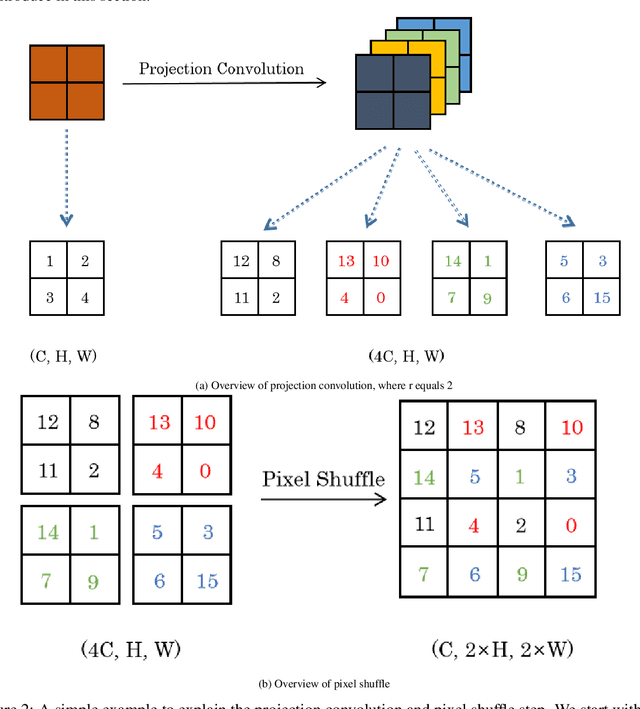

Deep Neural Networks (DNNs) are generated by sequentially performing linear and non-linear processes. Using a combination of linear and non-linear procedures is critical for generating a sufficiently deep feature space. The majority of non-linear operators are derivations of activation functions or pooling functions. Mathematical morphology is a branch of mathematics that provides non-linear operators for a variety of image processing problems. We investigate the utility of integrating these operations in an end-to-end deep learning framework in this paper. DNNs are designed to acquire a realistic representation for a particular job. Morphological operators give topological descriptors that convey salient information about the shapes of objects depicted in images. We propose a method based on meta-learning to incorporate morphological operators into DNNs. The learned architecture demonstrates how our novel morphological operations significantly increase DNN performance on various tasks, including picture classification and edge detection.
Tractable Density Estimation on Learned Manifolds with Conformal Embedding Flows
Jun 09, 2021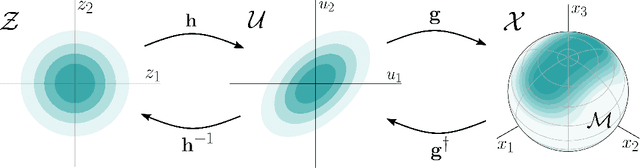


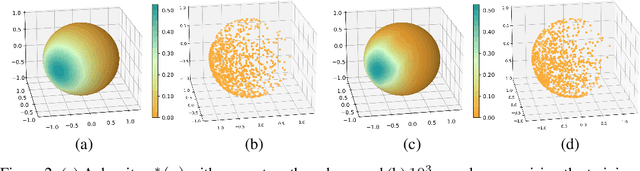
Normalizing flows are generative models that provide tractable density estimation by transforming a simple base distribution into a complex target distribution. However, this technique cannot directly model data supported on an unknown low-dimensional manifold, a common occurrence in real-world domains such as image data. Recent attempts to remedy this limitation have introduced geometric complications that defeat a central benefit of normalizing flows: exact density estimation. We recover this benefit with Conformal Embedding Flows, a framework for designing flows that learn manifolds with tractable densities. We argue that composing a standard flow with a trainable conformal embedding is the most natural way to model manifold-supported data. To this end, we present a series of conformal building blocks and apply them in experiments with real-world and synthetic data to demonstrate that flows can model manifold-supported distributions without sacrificing tractable likelihoods.
Shapes as Product Differentiation: Neural Network Embedding in the Analysis of Markets for Fonts
Jul 06, 2021


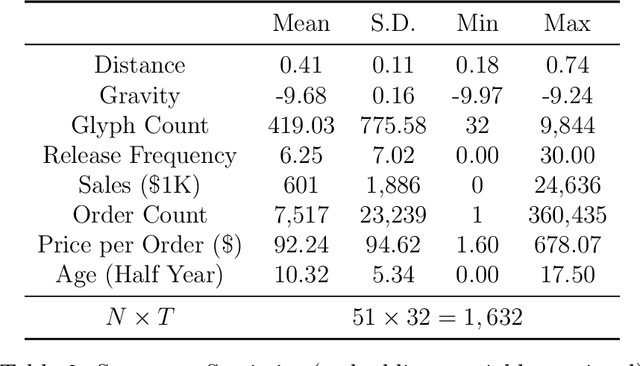
Many differentiated products have key attributes that are unstructured and thus high-dimensional (e.g., design, text). Instead of treating unstructured attributes as unobservables in economic models, quantifying them can be important to answer interesting economic questions. To propose an analytical framework for this type of products, this paper considers one of the simplest design products -- fonts -- and investigates merger and product differentiation using an original dataset from the world's largest online marketplace for fonts. We quantify font shapes by constructing embeddings from a deep convolutional neural network. Each embedding maps a font's shape onto a low-dimensional vector. In the resulting product space, designers are assumed to engage in Hotelling-type spatial competition. From the image embeddings, we construct two alternative measures that capture the degree of design differentiation. We then study the causal effects of a merger on the merging firm's creative decisions using the constructed measures in a synthetic control method. We find that the merger causes the merging firm to increase the visual variety of font design. Notably, such effects are not captured when using traditional measures for product offerings (e.g., specifications and the number of products) constructed from structured data.