 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
BERTGEN: Multi-task Generation through BERT
Jun 07, 2021
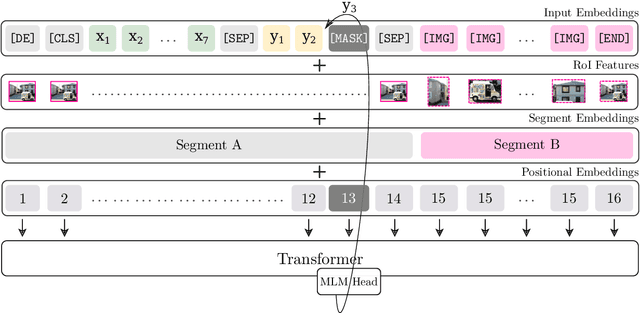
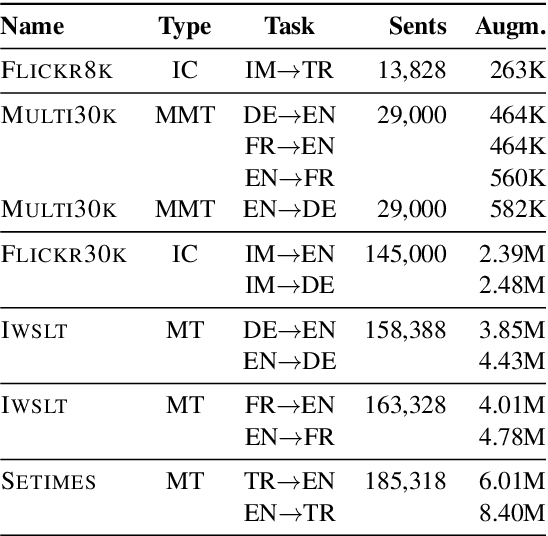
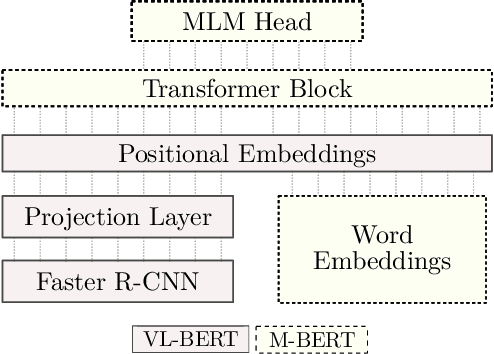
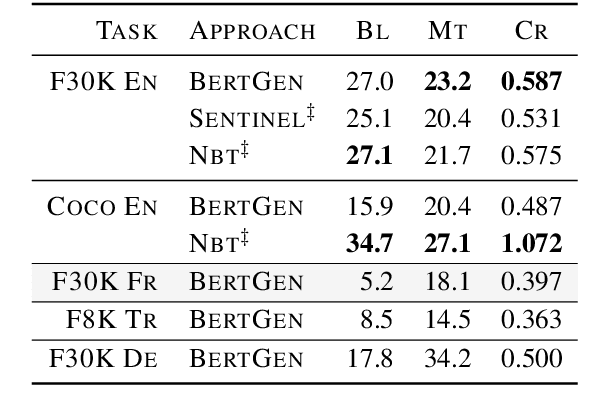
We present BERTGEN, a novel generative, decoder-only model which extends BERT by fusing multimodal and multilingual pretrained models VL-BERT and M-BERT, respectively. BERTGEN is auto-regressively trained for language generation tasks, namely image captioning, machine translation and multimodal machine translation, under a multitask setting. With a comprehensive set of evaluations, we show that BERTGEN outperforms many strong baselines across the tasks explored. We also show BERTGEN's ability for zero-shot language generation, where it exhibits competitive performance to supervised counterparts. Finally, we conduct ablation studies which demonstrate that BERTGEN substantially benefits from multi-tasking and effectively transfers relevant inductive biases from the pre-trained models.
Learning Generic Diffusion Processes for Image Restoration
Jul 17, 2018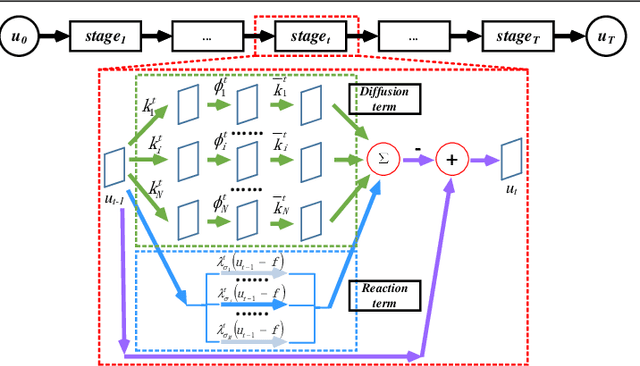
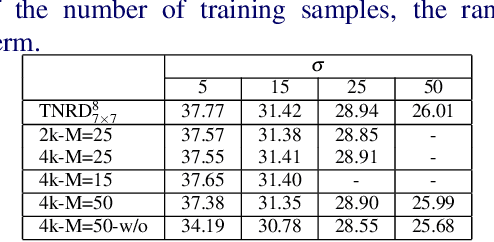
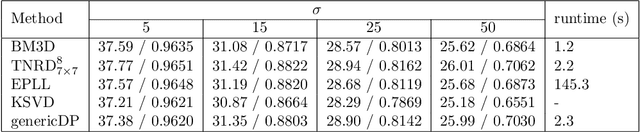

Image restoration problems are typical ill-posed problems where the regularization term plays an important role. The regularization term learned via generative approaches is easy to transfer to various image restoration, but offers inferior restoration quality compared with that learned via discriminative approaches. On the contrary, the regularization term learned via discriminative approaches are usually trained for a specific image restoration problem, and fail in the problem for which it is not trained. To address this issue, we propose a generic diffusion process (genericDP) to handle multiple Gaussian denoising problems based on the Trainable Non-linear Reaction Diffusion (TNRD) models. Instead of one model, which consists of a diffusion and a reaction term, for one Gaussian denoising problem in TNRD, we enforce multiple TNRD models to share one diffusion term. The trained genericDP model can provide both promising denoising performance and high training efficiency compared with the original TNRD models. We also transfer the trained diffusion term to non-blind deconvolution which is unseen in the training phase. Experiment results show that the trained diffusion term for multiple Gaussian denoising can be transferred to image non-blind deconvolution as an image prior and provide competitive performance.
* 12 pages, 3 figures, 3 tables
Removing Pixel Noises and Spatial Artifacts with Generative Diversity Denoising Methods
Apr 03, 2021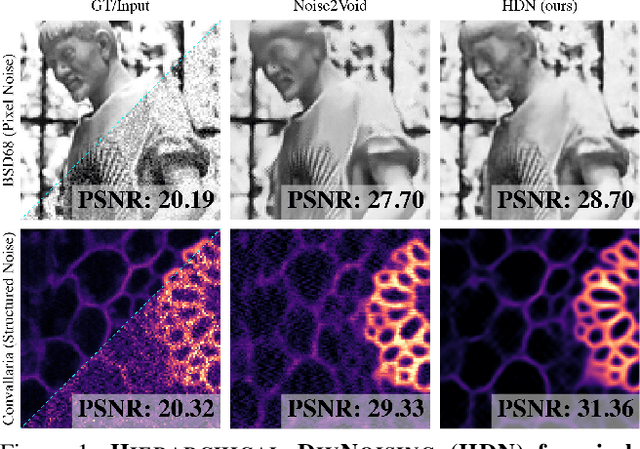
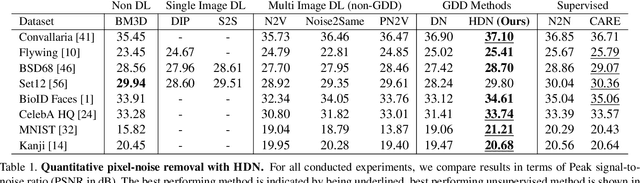
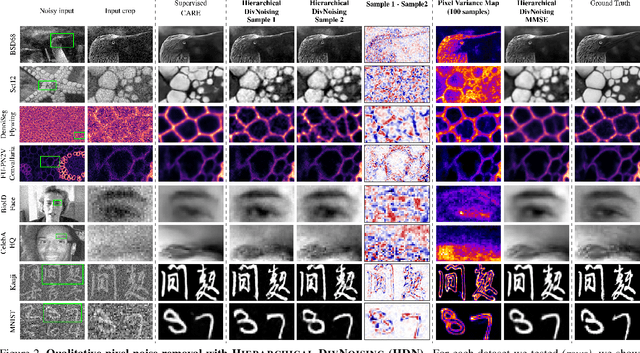

Image denoising and artefact removal are complex inverse problems admitting many potential solutions. Variational Autoencoders (VAEs) can be used to learn a whole distribution of sensible solutions, from which one can sample efficiently. However, such a generative approach to image restoration is only studied in the context of pixel-wise noise removal (e.g. Poisson or Gaussian noise). While important, a plethora of application domains suffer from imaging artefacts (structured noises) that alter groups of pixels in correlated ways. In this work we show, for the first time, that generative diversity denoising (GDD) approaches can learn to remove structured noises without supervision. To this end, we investigate two existing GDD architectures, introduce a new one based on hierarchical VAEs, and compare their performances against a total of seven state-of-the-art baseline methods on five sources of structured noise (including tomography reconstruction artefacts and microscopy artefacts). We find that GDD methods outperform all unsupervised baselines and in many cases not lagging far behind supervised results (in some occasions even superseding them). In addition to structured noise removal, we also show that our new GDD method produces new state-of-the-art (SOTA) results on seven out of eight benchmark datasets for pixel-noise removal. Finally, we offer insights into the daunting question of how GDD methods distinguish structured noise, which we like to see removed, from image signals, which we want to see retained.
Multi-Level Feature Fusion Mechanism for Single Image Super-Resolution
Feb 14, 2020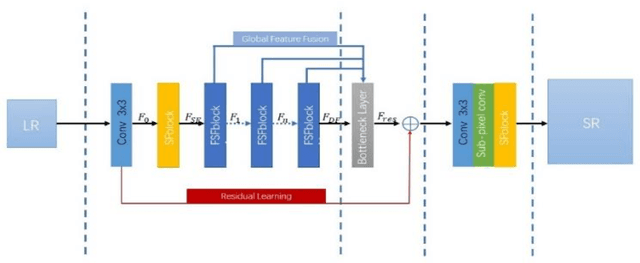
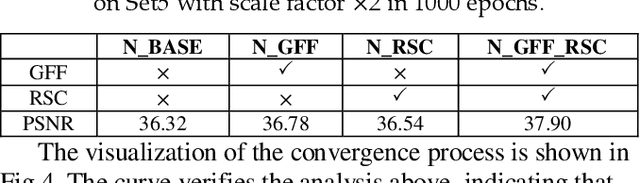

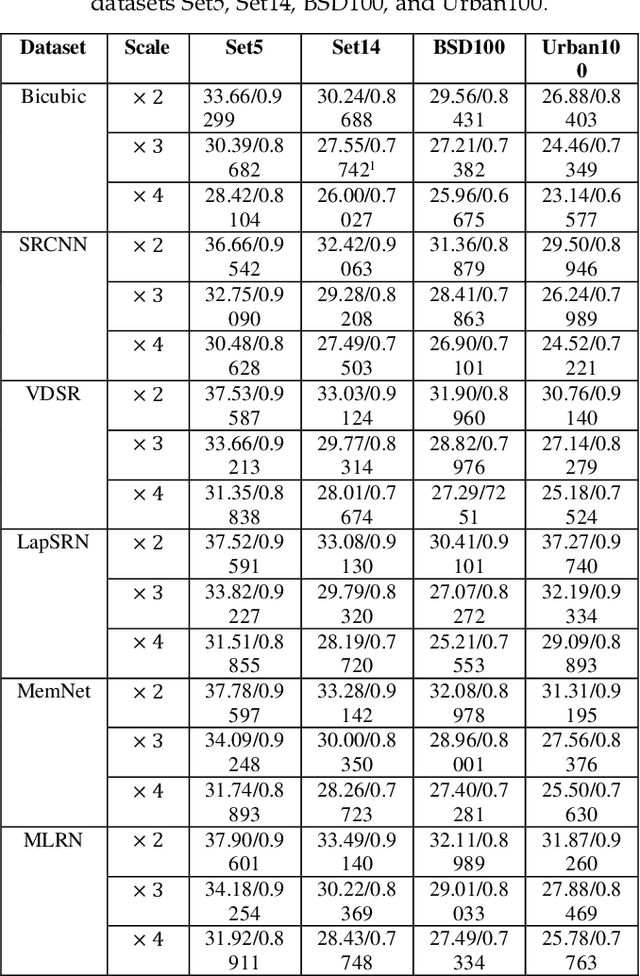
Convolution neural network (CNN) has been widely used in Single Image Super Resolution (SISR) so that SISR has been a great success recently. As the network deepens, the learning ability of network becomes more and more powerful. However, most SISR methods based on CNN do not make full use of hierarchical feature and the learning ability of network. These features cannot be extracted directly by subsequent layers, so the previous layer hierarchical information has little impact on the output and performance of subsequent layers relatively poor. To solve above problem, a novel Multi-Level Feature Fusion network (MLRN) is proposed, which can take full use of global intermediate features. We also introduce Feature Skip Fusion Block (FSFblock) as basic module. Each block can be extracted directly to the raw multiscale feature and fusion multi-level feature, then learn feature spatial correlation. The correlation among the features of the holistic approach leads to a continuous global memory of information mechanism. Extensive experiments on public datasets show that the method proposed by MLRN can be implemented, which is favorable performance for the most advanced methods.
1st Place Solution for YouTubeVOS Challenge 2021:Video Instance Segmentation
Jul 09, 2021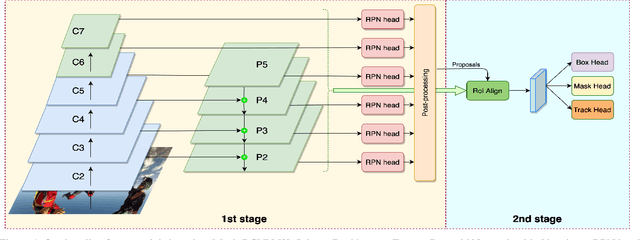

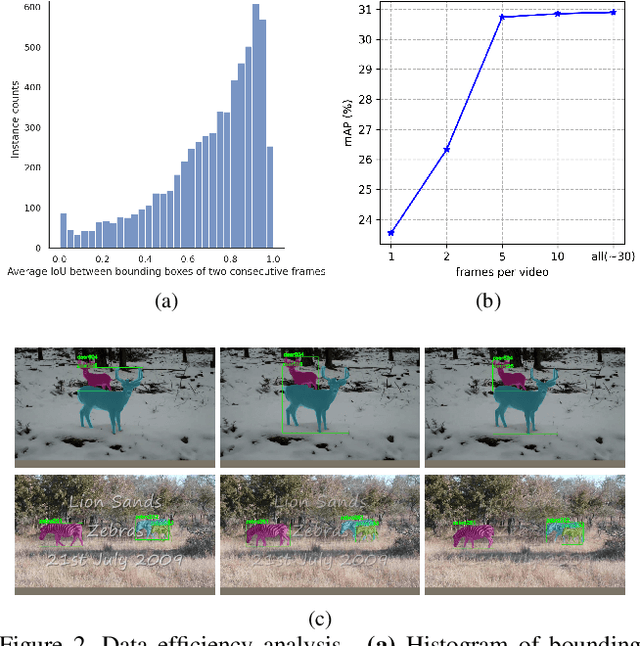
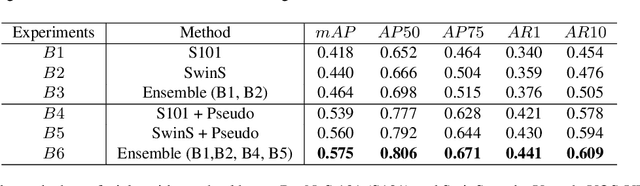
Video Instance Segmentation (VIS) is a multi-task problem performing detection, segmentation, and tracking simultaneously. Extended from image set applications, video data additionally induces the temporal information, which, if handled appropriately, is very useful to identify and predict object motions. In this work, we design a unified model to mutually learn these tasks. Specifically, we propose two modules, named Temporally Correlated Instance Segmentation (TCIS) and Bidirectional Tracking (BiTrack), to take the benefit of the temporal correlation between the object's instance masks across adjacent frames. On the other hand, video data is often redundant due to the frame's overlap. Our analysis shows that this problem is particularly severe for the YoutubeVOS-VIS2021 data. Therefore, we propose a Multi-Source Data (MSD) training mechanism to compensate for the data deficiency. By combining these techniques with a bag of tricks, the network performance is significantly boosted compared to the baseline, and outperforms other methods by a considerable margin on the YoutubeVOS-VIS 2019 and 2021 datasets.
On Fast Sampling of Diffusion Probabilistic Models
May 31, 2021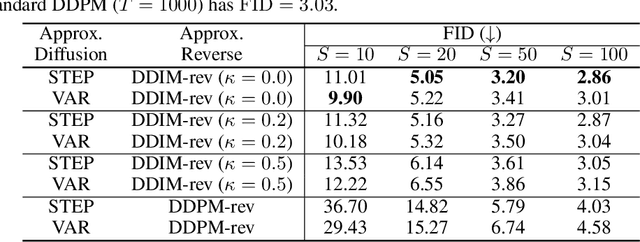

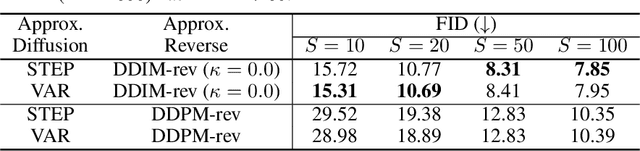

In this work, we propose FastDPM, a unified framework for fast sampling in diffusion probabilistic models. FastDPM generalizes previous methods and gives rise to new algorithms with improved sample quality. We systematically investigate the fast sampling methods under this framework across different domains, on different datasets, and with different amount of conditional information provided for generation. We find the performance of a particular method depends on data domains (e.g., image or audio), the trade-off between sampling speed and sample quality, and the amount of conditional information. We further provide insights and recipes on the choice of methods for practitioners.
Generalisation in Neural Networks Does not Require Feature Overlap
Jul 04, 2021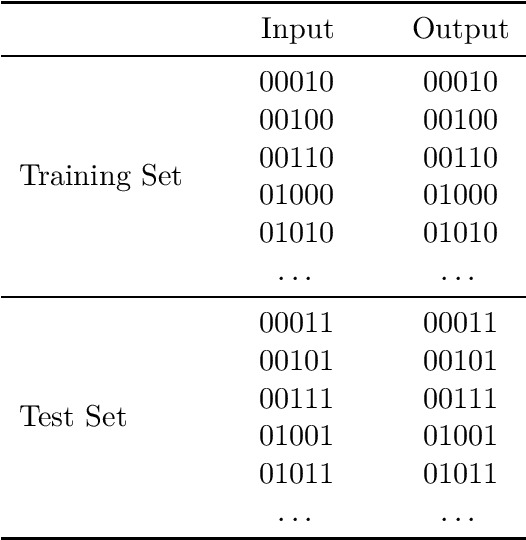
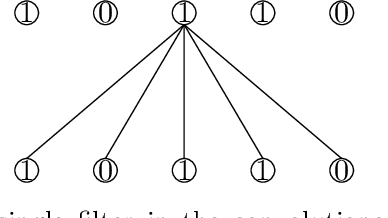

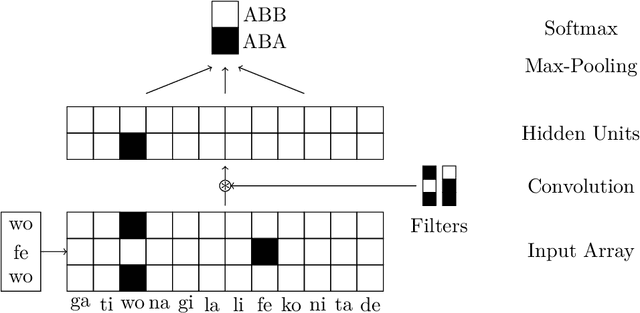
That shared features between train and test data are required for generalisation in artificial neural networks has been a common assumption of both proponents and critics of these models. Here, we show that convolutional architectures avoid this limitation by applying them to two well known challenges, based on learning the identity function and learning rules governing sequences of words. In each case, successful performance on the test set requires generalising to features that were not present in the training data, which is typically not feasible for standard connectionist models. However, our experiments demonstrate that neural networks can succeed on such problems when they incorporate the weight sharing employed by convolutional architectures. In the image processing domain, such architectures are intended to reflect the symmetry under spatial translations of the natural world that such images depict. We discuss the role of symmetry in the two tasks and its connection to generalisation.
AdaAttN: Revisit Attention Mechanism in Arbitrary Neural Style Transfer
Aug 08, 2021
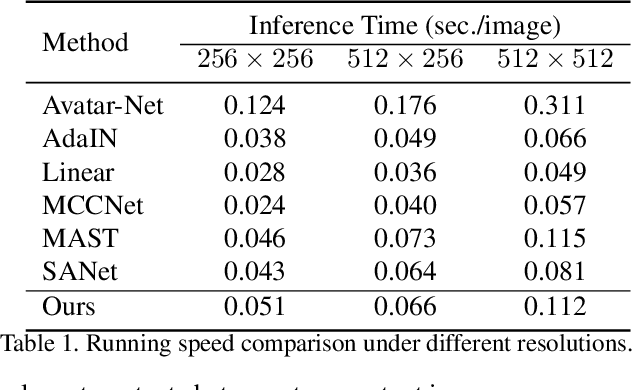
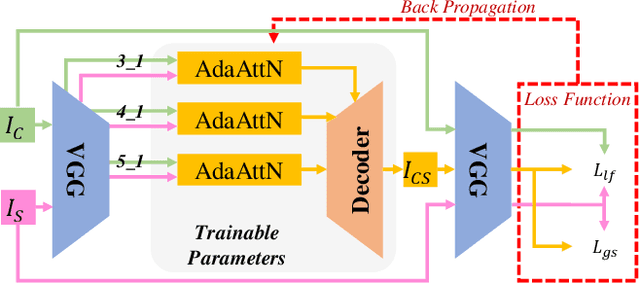

Fast arbitrary neural style transfer has attracted widespread attention from academic, industrial and art communities due to its flexibility in enabling various applications. Existing solutions either attentively fuse deep style feature into deep content feature without considering feature distributions, or adaptively normalize deep content feature according to the style such that their global statistics are matched. Although effective, leaving shallow feature unexplored and without locally considering feature statistics, they are prone to unnatural output with unpleasing local distortions. To alleviate this problem, in this paper, we propose a novel attention and normalization module, named Adaptive Attention Normalization (AdaAttN), to adaptively perform attentive normalization on per-point basis. Specifically, spatial attention score is learnt from both shallow and deep features of content and style images. Then per-point weighted statistics are calculated by regarding a style feature point as a distribution of attention-weighted output of all style feature points. Finally, the content feature is normalized so that they demonstrate the same local feature statistics as the calculated per-point weighted style feature statistics. Besides, a novel local feature loss is derived based on AdaAttN to enhance local visual quality. We also extend AdaAttN to be ready for video style transfer with slight modifications. Experiments demonstrate that our method achieves state-of-the-art arbitrary image/video style transfer. Codes and models are available.
Examining convolutional feature extraction using Maximum Entropy (ME) and Signal-to-Noise Ratio (SNR) for image classification
May 10, 2021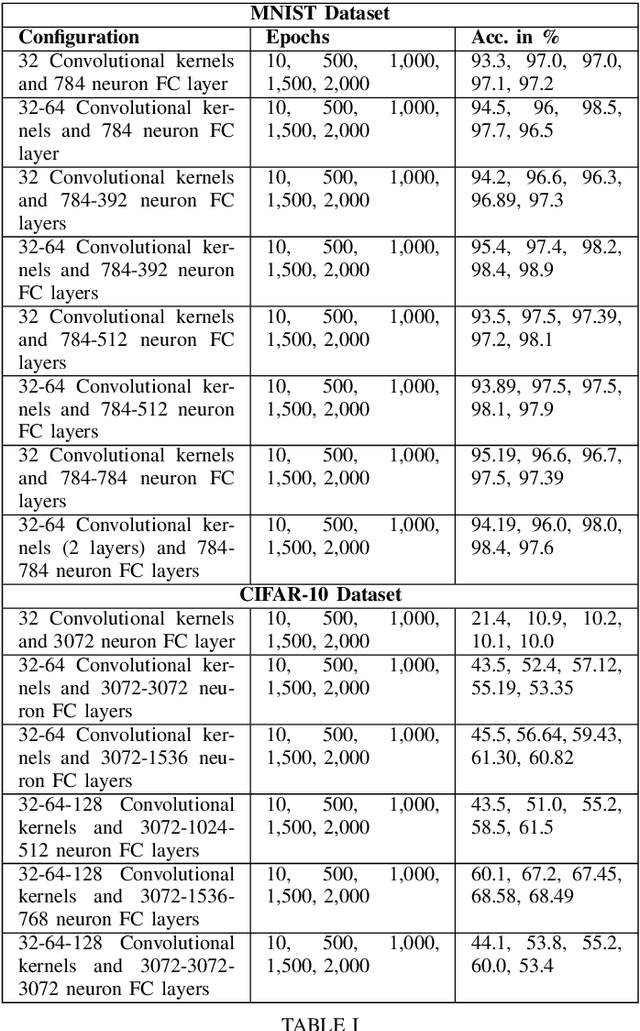
Convolutional Neural Networks (CNNs) specialize in feature extraction rather than function mapping. In doing so they form complex internal hierarchical feature representations, the complexity of which gradually increases with a corresponding increment in neural network depth. In this paper, we examine the feature extraction capabilities of CNNs using Maximum Entropy (ME) and Signal-to-Noise Ratio (SNR) to validate the idea that, CNN models should be tailored for a given task and complexity of the input data. SNR and ME measures are used as they can accurately determine in the input dataset, the relative amount of signal information to the random noise and the maximum amount of information respectively. We use two well known benchmarking datasets, MNIST and CIFAR-10 to examine the information extraction and abstraction capabilities of CNNs. Through our experiments, we examine convolutional feature extraction and abstraction capabilities in CNNs and show that the classification accuracy or performance of CNNs is greatly dependent on the amount, complexity and quality of the signal information present in the input data. Furthermore, we show the effect of information overflow and underflow on CNN classification accuracies. Our hypothesis is that the feature extraction and abstraction capabilities of convolutional layers are limited and therefore, CNN models should be tailored to the input data by using appropriately sized CNNs based on the SNR and ME measures of the input dataset.
* Conference paper, 6 pages, 1 table
Deep Single Image Deraining Via Estimating Transmission and Atmospheric Light in rainy Scenes
Jun 22, 2019
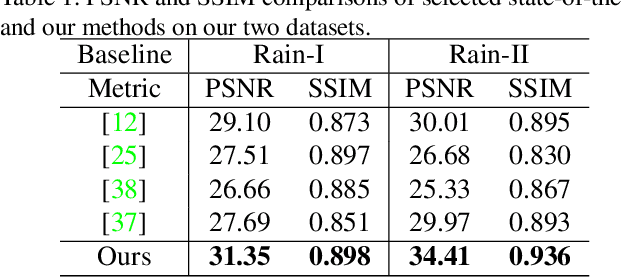
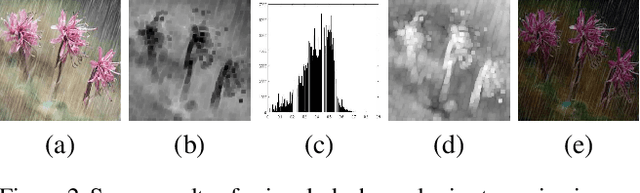
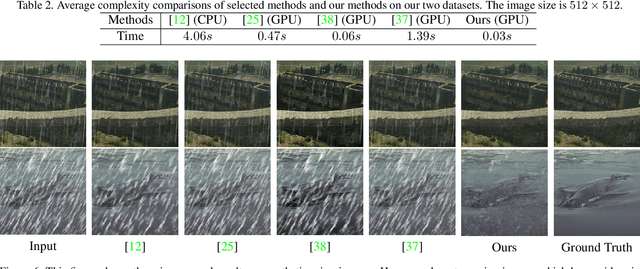
Rain removal in images/videos is still an important task in computer vision field and attracting attentions of more and more people. Traditional methods always utilize some incomplete priors or filters (e.g. guided filter) to remove rain effect. Deep learning gives more probabilities to better solve this task. However, they remove rain either by evaluating background from rainy image directly or learning a rain residual first then subtracting the residual to obtain a clear background. No other models are used in deep learning based de-raining methods to remove rain and obtain other information about rainy scenes. In this paper, we utilize an extensively-used image degradation model which is derived from atmospheric scattering principles to model the formation of rainy images and try to learn the transmission, atmospheric light in rainy scenes and remove rain further. To reach this goal, we propose a robust evaluation method of global atmospheric light in a rainy scene. Instead of using the estimated atmospheric light directly to learn a network to calculate transmission, we utilize it as ground truth and design a simple but novel triangle-shaped network structure to learn atmospheric light for every rainy image, then fine-tune the network to obtain a better estimation of atmospheric light during the training of transmission network. Furthermore, more efficient ShuffleNet Units are utilized in transmission network to learn transmission map and the de-raining image is then obtained by the image degradation model. By subjective and objective comparisons, our method outperforms the selected state-of-the-art works.