 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecuring Educational LLMs: A Generalised Taxonomy of Attacks on LLMs and DREAD Risk Assessment
Aug 12, 2025Due to perceptions of efficiency and significant productivity gains, various organisations, including in education, are adopting Large Language Models (LLMs) into their workflows. Educator-facing, learner-facing, and institution-facing LLMs, collectively, Educational Large Language Models (eLLMs), complement and enhance the effectiveness of teaching, learning, and academic operations. However, their integration into an educational setting raises significant cybersecurity concerns. A comprehensive landscape of contemporary attacks on LLMs and their impact on the educational environment is missing. This study presents a generalised taxonomy of fifty attacks on LLMs, which are categorized as attacks targeting either models or their infrastructure. The severity of these attacks is evaluated in the educational sector using the DREAD risk assessment framework. Our risk assessment indicates that token smuggling, adversarial prompts, direct injection, and multi-step jailbreak are critical attacks on eLLMs. The proposed taxonomy, its application in the educational environment, and our risk assessment will help academic and industrial practitioners to build resilient solutions that protect learners and institutions.
Dynamic hardware system for cascade SVM classification of melanoma
Dec 10, 2021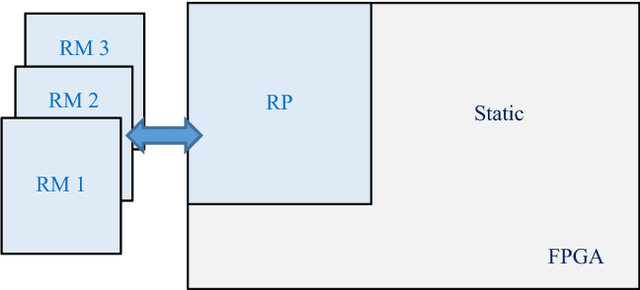


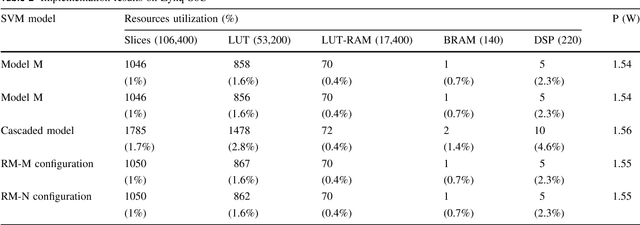
Melanoma is the most dangerous form of skin cancer, which is responsible for the majority of skin cancer-related deaths. Early diagnosis of melanoma can significantly reduce mortality rates and treatment costs. Therefore, skin cancer specialists are using image-based diagnostic tools for detecting melanoma earlier. We aim to develop a handheld device featured with low cost and high performance to enhance early detection of melanoma at the primary healthcare. But, developing this device is very challenging due to the complicated computations required by the embedded diagnosis system. Thus, we aim to exploit the recent hardware technology in reconfigurable computing to achieve a high-performance embedded system at low cost. Support vector machine (SVM) is a common classifier that shows high accuracy for classifying melanoma within the diagnosis system and is considered as the most compute-intensive task in the system. In this paper, we propose a dynamic hardware system for implementing a cascade SVM classifier on FPGA for early melanoma detection. A multi-core architecture is proposed to implement a two-stage cascade classifier using two classifiers with accuracies of 98% and 73%. The hardware implementation results were optimized by using the dynamic partial reconfiguration technology, where very low resource utilization of 1% slices and power consumption of 1.5 W were achieved. Consequently, the implemented dynamic hardware system meets vital embedded system constraints of high performance and low cost, resource utilization, and power consumption, while achieving efficient classification with high accuracy.
* Journal paper, 9 pages, 4 figures, 4 tables
A system on chip for melanoma detection using FPGA-based SVM classifier
Sep 30, 2021
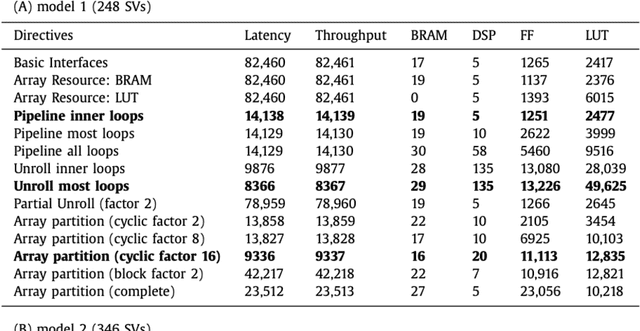
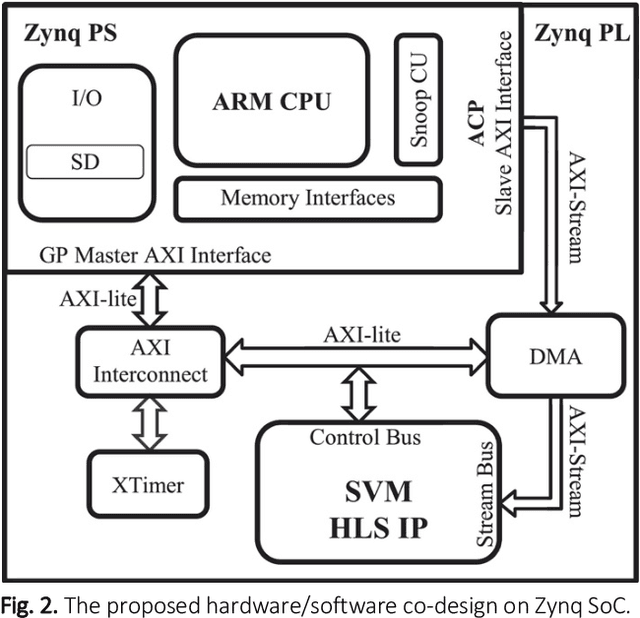

Support Vector Machine (SVM) is a robust machine learning model that shows high accuracy with different classification problems, and is widely used for various embedded applications. However , implementation of embedded SVM classifiers is challenging, due to the inherent complicated computations required. This motivates implementing the SVM on hardware platforms for achieving high performance computing at low cost and power consumption. Melanoma is the most aggressive form of skin cancer that increases the mortality rate. We aim to develop an optimized embedded SVM classifier dedicated for a low-cost handheld device for early detection of melanoma at the primary healthcare. In this paper, we propose a hardware/software co-design for implementing the SVM classifier onto FPGA to realize melanoma detection on a chip. The implemented SVM on a recent hybrid FPGA (Zynq) platform utilizing the modern UltraFast High-Level Synthesis design methodology achieves efficient melanoma classification on chip. The hardware implementation results demonstrate classification accuracy of 97.9%, and a significant hardware acceleration rate of 21 with only 3% resources utilization and 1.69W for power consumption. These results show that the implemented system on chip meets crucial embedded system constraints of high performance and low resources utilization, power consumption, and cost, while achieving efficient classification with high classification accuracy.
* Journal paper, 13 pages, 3 figures, 9 tables
SVM Classifier on Chip for Melanoma Detection
Aug 26, 2021
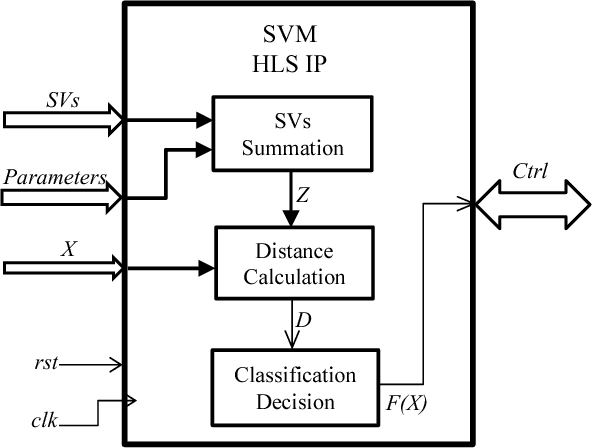
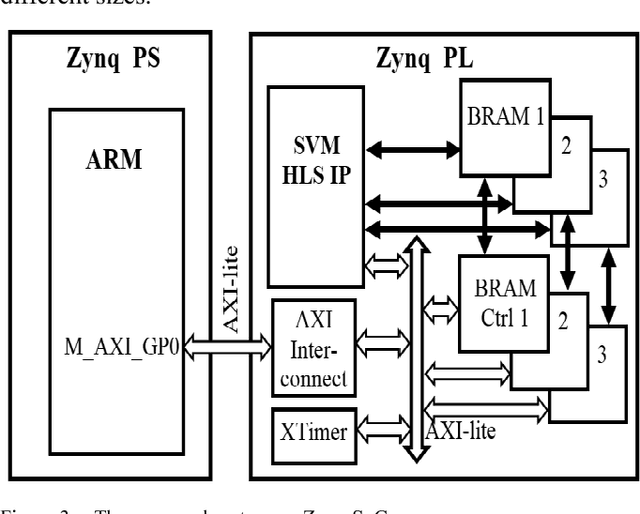
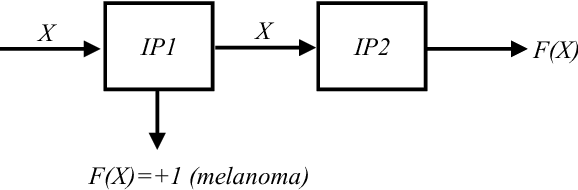
Support Vector Machine (SVM) is a common classifier used for efficient classification with high accuracy. SVM shows high accuracy for classifying melanoma (skin cancer) clinical images within computer-aided diagnosis systems used by skin cancer specialists to detect melanoma early and save lives. We aim to develop a medical low-cost handheld device that runs a real-time embedded SVM- based diagnosis system for use in primary care for early detection of melanoma. In this paper, an optimized SVM classifier is implemented onto a recent FPGA platform using the latest design methodology to be embedded into the proposed device for realizing online efficient melanoma detection on a single system on chip/device. The hardware implementation results demonstrate a high classification accuracy of 97.9% and a significant acceleration factor of 26 from equivalent software implementation on an embedded processor, with 34% of resources utilization and 2 watts for power consumption. Consequently, the implemented system meets crucial embedded systems constraints of high performance and low cost, resources utilization and power consumption, while achieving high classification accuracy.
* Conference paper, 5 pages, 4 figures, 1 tables
Mitigating severe over-parameterization in deep convolutional neural networks through forced feature abstraction and compression with an entropy-based heuristic
Jun 27, 2021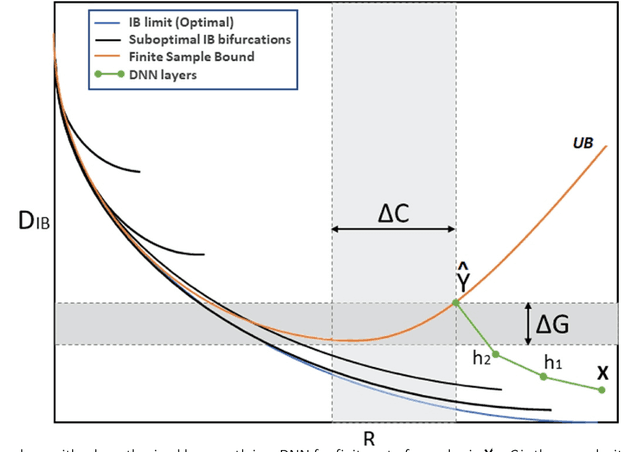
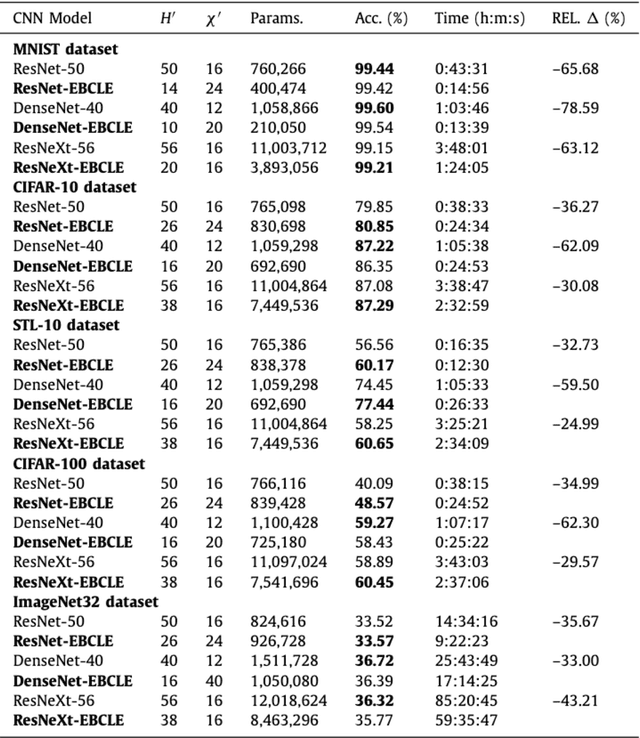
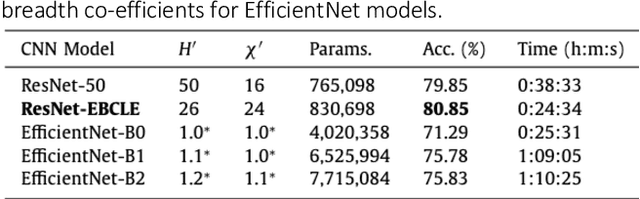

Convolutional Neural Networks (CNNs) such as ResNet-50, DenseNet-40 and ResNeXt-56 are severely over-parameterized, necessitating a consequent increase in the computational resources required for model training which scales exponentially for increments in model depth. In this paper, we propose an Entropy-Based Convolutional Layer Estimation (EBCLE) heuristic which is robust and simple, yet effective in resolving the problem of over-parameterization with regards to network depth of CNN model. The EBCLE heuristic employs a priori knowledge of the entropic data distribution of input datasets to determine an upper bound for convolutional network depth, beyond which identity transformations are prevalent offering insignificant contributions for enhancing model performance. Restricting depth redundancies by forcing feature compression and abstraction restricts over-parameterization while decreasing training time by 24.99% - 78.59% without degradation in model performance. We present empirical evidence to emphasize the relative effectiveness of broader, yet shallower models trained using the EBCLE heuristic, which maintains or outperforms baseline classification accuracies of narrower yet deeper models. The EBCLE heuristic is architecturally agnostic and EBCLE based CNN models restrict depth redundancies resulting in enhanced utilization of the available computational resources. The proposed EBCLE heuristic is a compelling technique for researchers to analytically justify their HyperParameter (HP) choices for CNNs. Empirical validation of the EBCLE heuristic in training CNN models was established on five benchmarking datasets (ImageNet32, CIFAR-10/100, STL-10, MNIST) and four network architectures (DenseNet, ResNet, ResNeXt and EfficientNet B0-B2) with appropriate statistical tests employed to infer any conclusive claims presented in this paper.
* Journal paper, 14 pages, 3 tables, 3 figures
Examining and Mitigating Kernel Saturation in Convolutional Neural Networks using Negative Images
May 10, 2021


Neural saturation in Deep Neural Networks (DNNs) has been studied extensively, but remains relatively unexplored in Convolutional Neural Networks (CNNs). Understanding and alleviating the effects of convolutional kernel saturation is critical for enhancing CNN models classification accuracies. In this paper, we analyze the effect of convolutional kernel saturation in CNNs and propose a simple data augmentation technique to mitigate saturation and increase classification accuracy, by supplementing negative images to the training dataset. We hypothesize that greater semantic feature information can be extracted using negative images since they have the same structural information as standard images but differ in their data representations. Varied data representations decrease the probability of kernel saturation and thus increase the effectiveness of kernel weight updates. The two datasets selected to evaluate our hypothesis were CIFAR- 10 and STL-10 as they have similar image classes but differ in image resolutions thus making for a better understanding of the saturation phenomenon. MNIST dataset was used to highlight the ineffectiveness of the technique for linearly separable data. The ResNet CNN architecture was chosen since the skip connections in the network ensure the most important features contributing the most to classification accuracy are retained. Our results show that CNNs are indeed susceptible to convolutional kernel saturation and that supplementing negative images to the training dataset can offer a statistically significant increase in classification accuracies when compared against models trained on the original datasets. Our results present accuracy increases of 6.98% and 3.16% on the STL-10 and CIFAR-10 datasets respectively.
* Conference paper, 6 pages, 3 figures, 1 table
Examining convolutional feature extraction using Maximum Entropy (ME) and Signal-to-Noise Ratio (SNR) for image classification
May 10, 2021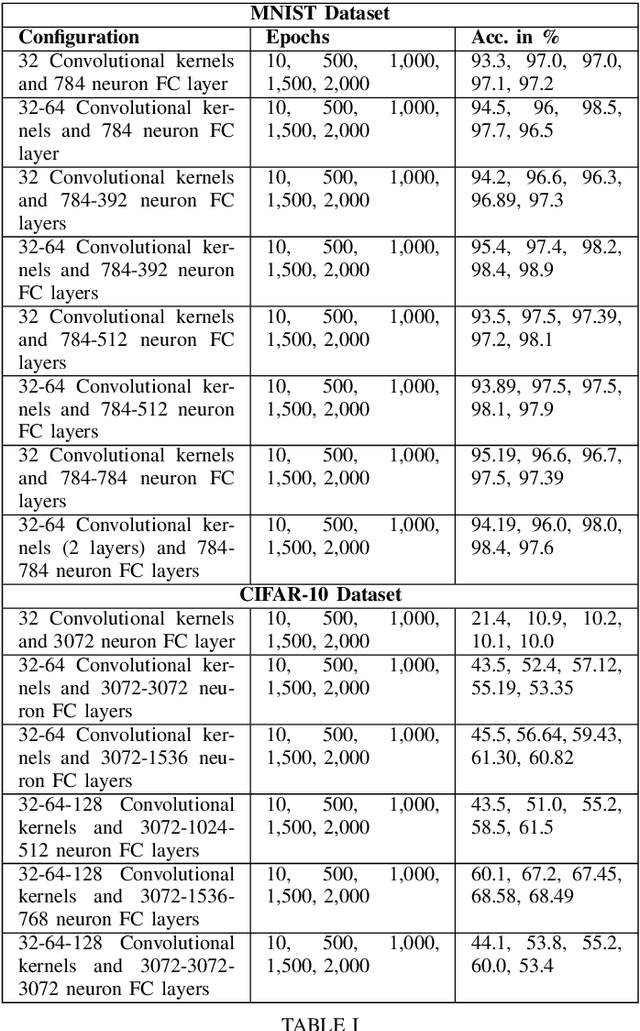
Convolutional Neural Networks (CNNs) specialize in feature extraction rather than function mapping. In doing so they form complex internal hierarchical feature representations, the complexity of which gradually increases with a corresponding increment in neural network depth. In this paper, we examine the feature extraction capabilities of CNNs using Maximum Entropy (ME) and Signal-to-Noise Ratio (SNR) to validate the idea that, CNN models should be tailored for a given task and complexity of the input data. SNR and ME measures are used as they can accurately determine in the input dataset, the relative amount of signal information to the random noise and the maximum amount of information respectively. We use two well known benchmarking datasets, MNIST and CIFAR-10 to examine the information extraction and abstraction capabilities of CNNs. Through our experiments, we examine convolutional feature extraction and abstraction capabilities in CNNs and show that the classification accuracy or performance of CNNs is greatly dependent on the amount, complexity and quality of the signal information present in the input data. Furthermore, we show the effect of information overflow and underflow on CNN classification accuracies. Our hypothesis is that the feature extraction and abstraction capabilities of convolutional layers are limited and therefore, CNN models should be tailored to the input data by using appropriately sized CNNs based on the SNR and ME measures of the input dataset.
* Conference paper, 6 pages, 1 table