 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Catastrophic Interference in Reinforcement Learning: A Solution Based on Context Division and Knowledge Distillation
Sep 01, 2021
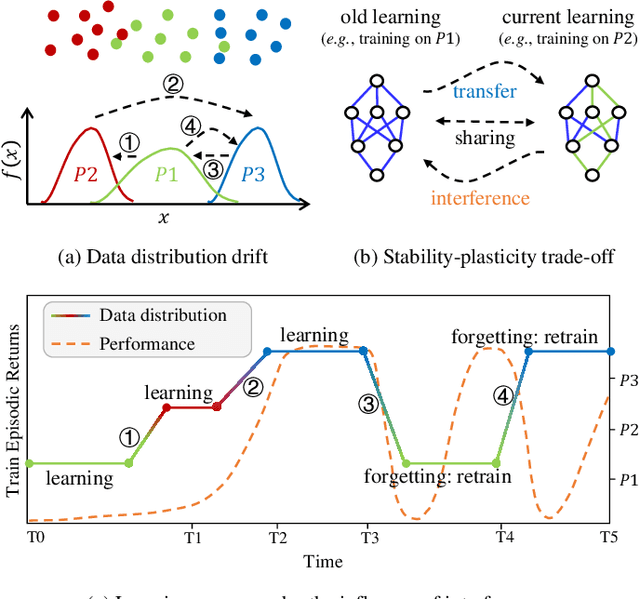
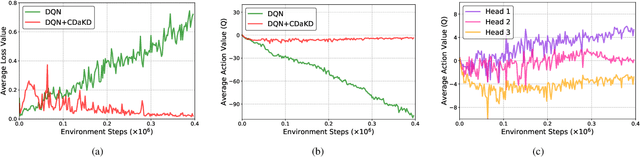
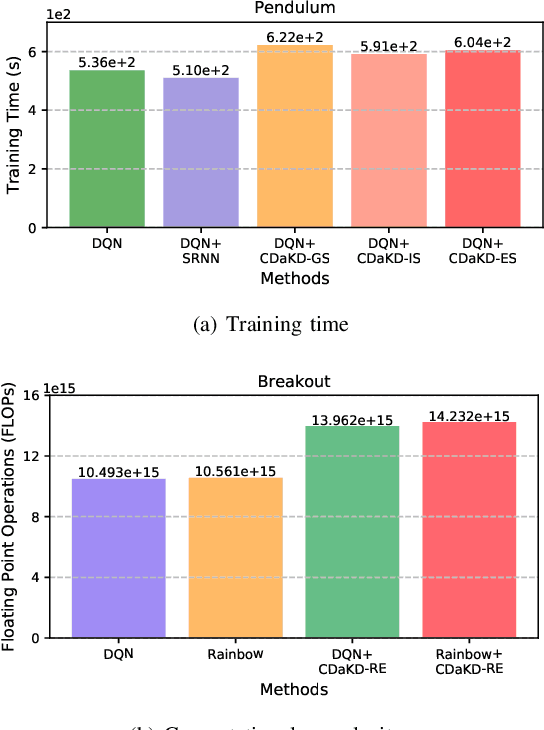
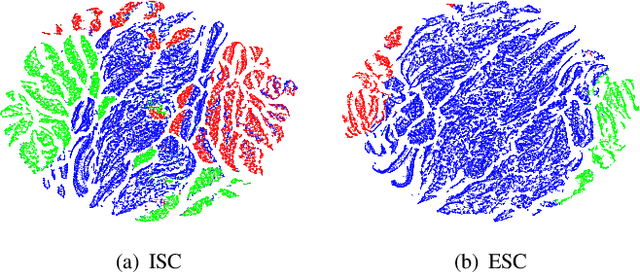
The powerful learning ability of deep neural networks enables reinforcement learning (RL) agents to learn competent control policies directly from high-dimensional and continuous environments. In theory, to achieve stable performance, neural networks assume i.i.d. inputs, which unfortunately does no hold in the general RL paradigm where the training data is temporally correlated and non-stationary. This issue may lead to the phenomenon of "catastrophic interference" and the collapse in performance as later training is likely to overwrite and interfer with previously learned policies. In this paper, we introduce the concept of "context" into single-task RL and develop a novel scheme, termed as Context Division and Knowledge Distillation (CDaKD) driven RL, to divide all states experienced during training into a series of contexts. Its motivation is to mitigate the challenge of aforementioned catastrophic interference in deep RL, thereby improving the stability and plasticity of RL models. At the heart of CDaKD is a value function, parameterized by a neural network feature extractor shared across all contexts, and a set of output heads, each specializing on an individual context. In CDaKD, we exploit online clustering to achieve context division, and interference is further alleviated by a knowledge distillation regularization term on the output layers for learned contexts. In addition, to effectively obtain the context division in high-dimensional state spaces (e.g., image inputs), we perform clustering in the lower-dimensional representation space of a randomly initialized convolutional encoder, which is fixed throughout training. Our results show that, with various replay memory capacities, CDaKD can consistently improve the performance of existing RL algorithms on classic OpenAI Gym tasks and the more complex high-dimensional Atari tasks, incurring only moderate computational overhead.
Geometry-Free View Synthesis: Transformers and no 3D Priors
Apr 15, 2021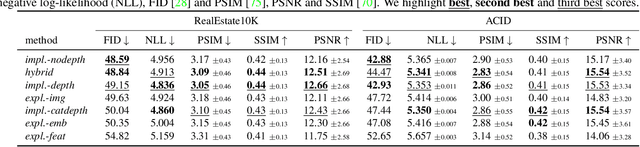
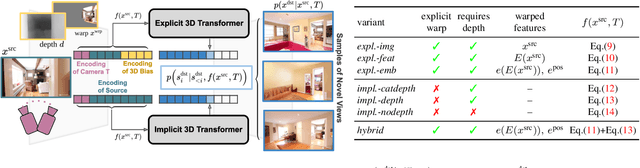
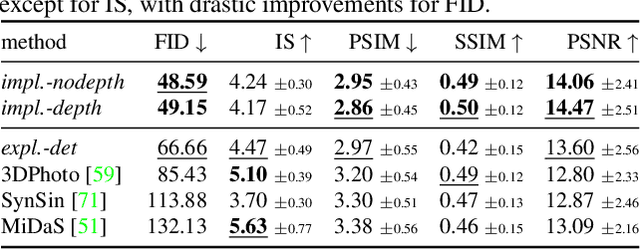

Is a geometric model required to synthesize novel views from a single image? Being bound to local convolutions, CNNs need explicit 3D biases to model geometric transformations. In contrast, we demonstrate that a transformer-based model can synthesize entirely novel views without any hand-engineered 3D biases. This is achieved by (i) a global attention mechanism for implicitly learning long-range 3D correspondences between source and target views, and (ii) a probabilistic formulation necessary to capture the ambiguity inherent in predicting novel views from a single image, thereby overcoming the limitations of previous approaches that are restricted to relatively small viewpoint changes. We evaluate various ways to integrate 3D priors into a transformer architecture. However, our experiments show that no such geometric priors are required and that the transformer is capable of implicitly learning 3D relationships between images. Furthermore, this approach outperforms the state of the art in terms of visual quality while covering the full distribution of possible realizations. Code is available at https://git.io/JOnwn
Joint Dermatological Lesion Classification and Confidence Modeling with Uncertainty Estimation
Jul 19, 2021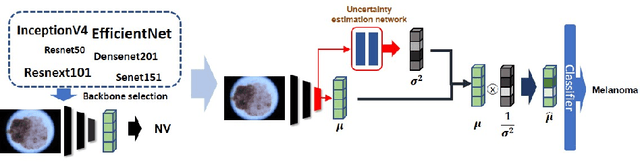
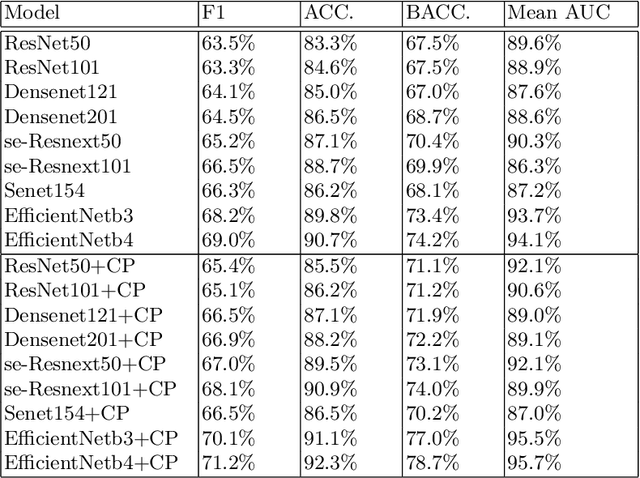

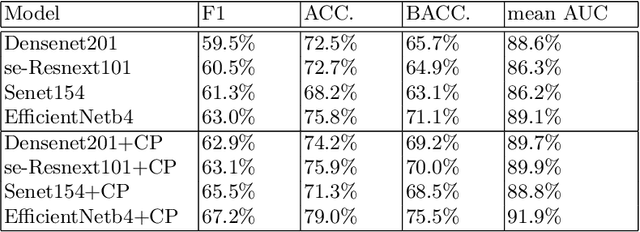
Deep learning has played a major role in the interpretation of dermoscopic images for detecting skin defects and abnormalities. However, current deep learning solutions for dermatological lesion analysis are typically limited in providing probabilistic predictions which highlights the importance of concerning uncertainties. This concept of uncertainty can provide a confidence level for each feature which prevents overconfident predictions with poor generalization on unseen data. In this paper, we propose an overall framework that jointly considers dermatological classification and uncertainty estimation together. The estimated confidence of each feature to avoid uncertain feature and undesirable shift, which are caused by environmental difference of input image, in the latent space is pooled from confidence network. Our qualitative results show that modeling uncertainties not only helps to quantify model confidence for each prediction but also helps classification layers to focus on confident features, therefore, improving the accuracy for dermatological lesion classification. We demonstrate the potential of the proposed approach in two state-of-the-art dermoscopic datasets (ISIC 2018 and ISIC 2019).
MFAGAN: A Compression Framework for Memory-Efficient On-Device Super-Resolution GAN
Jul 27, 2021
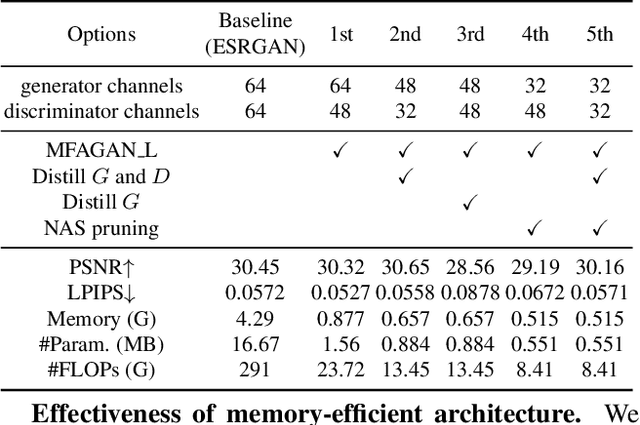
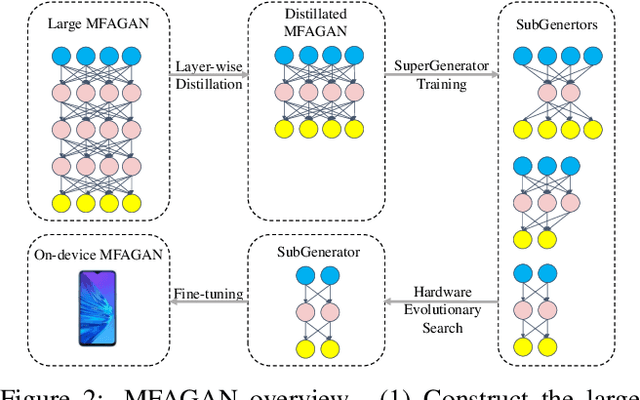

Generative adversarial networks (GANs) have promoted remarkable advances in single-image super-resolution (SR) by recovering photo-realistic images. However, high memory consumption of GAN-based SR (usually generators) causes performance degradation and more energy consumption, hindering the deployment of GAN-based SR into resource-constricted mobile devices. In this paper, we propose a novel compression framework \textbf{M}ulti-scale \textbf{F}eature \textbf{A}ggregation Net based \textbf{GAN} (MFAGAN) for reducing the memory access cost of the generator. First, to overcome the memory explosion of dense connections, we utilize a memory-efficient multi-scale feature aggregation net as the generator. Second, for faster and more stable training, our method introduces the PatchGAN discriminator. Third, to balance the student discriminator and the compressed generator, we distill both the generator and the discriminator. Finally, we perform a hardware-aware neural architecture search (NAS) to find a specialized SubGenerator for the target mobile phone. Benefiting from these improvements, the proposed MFAGAN achieves up to \textbf{8.3}$\times$ memory saving and \textbf{42.9}$\times$ computation reduction, with only minor visual quality degradation, compared with ESRGAN. Empirical studies also show $\sim$\textbf{70} milliseconds latency on Qualcomm Snapdragon 865 chipset.
Zero-Shot Domain Adaptation in CT Segmentation by Filtered Back Projection Augmentation
Aug 03, 2021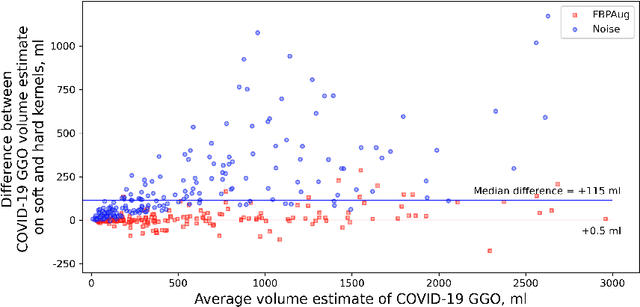


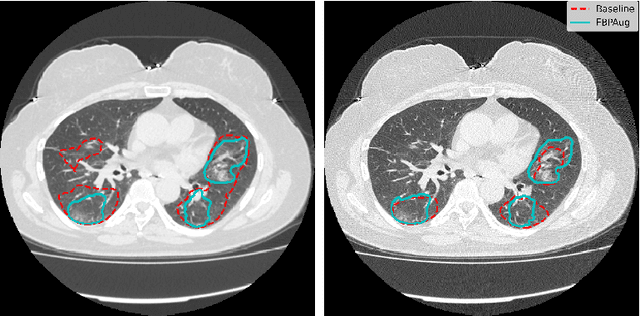
Domain shift is one of the most salient challenges in medical computer vision. Due to immense variability in scanners' parameters and imaging protocols, even images obtained from the same person and the same scanner could differ significantly. We address variability in computed tomography (CT) images caused by different convolution kernels used in the reconstruction process, the critical domain shift factor in CT. The choice of a convolution kernel affects pixels' granularity, image smoothness, and noise level. We analyze a dataset of paired CT images, where smooth and sharp images were reconstructed from the same sinograms with different kernels, thus providing identical anatomy but different style. Though identical predictions are desired, we show that the consistency, measured as the average Dice between predictions on pairs, is just 0.54. We propose Filtered Back-Projection Augmentation (FBPAug), a simple and surprisingly efficient approach to augment CT images in sinogram space emulating reconstruction with different kernels. We apply the proposed method in a zero-shot domain adaptation setup and show that the consistency boosts from 0.54 to 0.92 outperforming other augmentation approaches. Neither specific preparation of source domain data nor target domain data is required, so our publicly released FBPAug can be used as a plug-and-play module for zero-shot domain adaptation in any CT-based task.
Inferring Semantic Layout for Hierarchical Text-to-Image Synthesis
Jul 26, 2018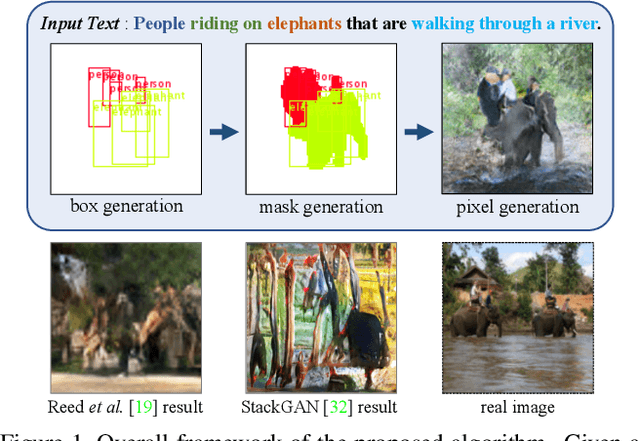
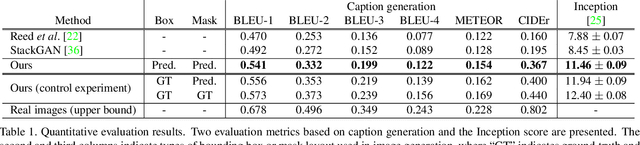
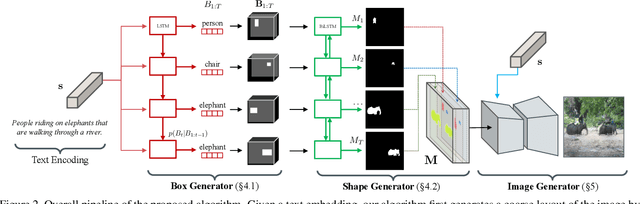
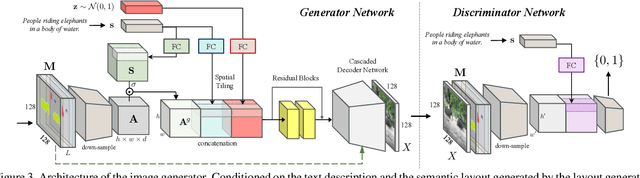
We propose a novel hierarchical approach for text-to-image synthesis by inferring semantic layout. Instead of learning a direct mapping from text to image, our algorithm decomposes the generation process into multiple steps, in which it first constructs a semantic layout from the text by the layout generator and converts the layout to an image by the image generator. The proposed layout generator progressively constructs a semantic layout in a coarse-to-fine manner by generating object bounding boxes and refining each box by estimating object shapes inside the box. The image generator synthesizes an image conditioned on the inferred semantic layout, which provides a useful semantic structure of an image matching with the text description. Our model not only generates semantically more meaningful images, but also allows automatic annotation of generated images and user-controlled generation process by modifying the generated scene layout. We demonstrate the capability of the proposed model on challenging MS-COCO dataset and show that the model can substantially improve the image quality, interpretability of output and semantic alignment to input text over existing approaches.
Closing the Reality Gap with Unsupervised Sim-to-Real Image Translation for Semantic Segmentation in Robot Soccer
Nov 04, 2019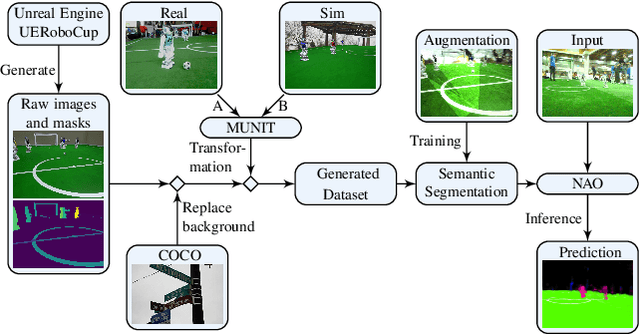

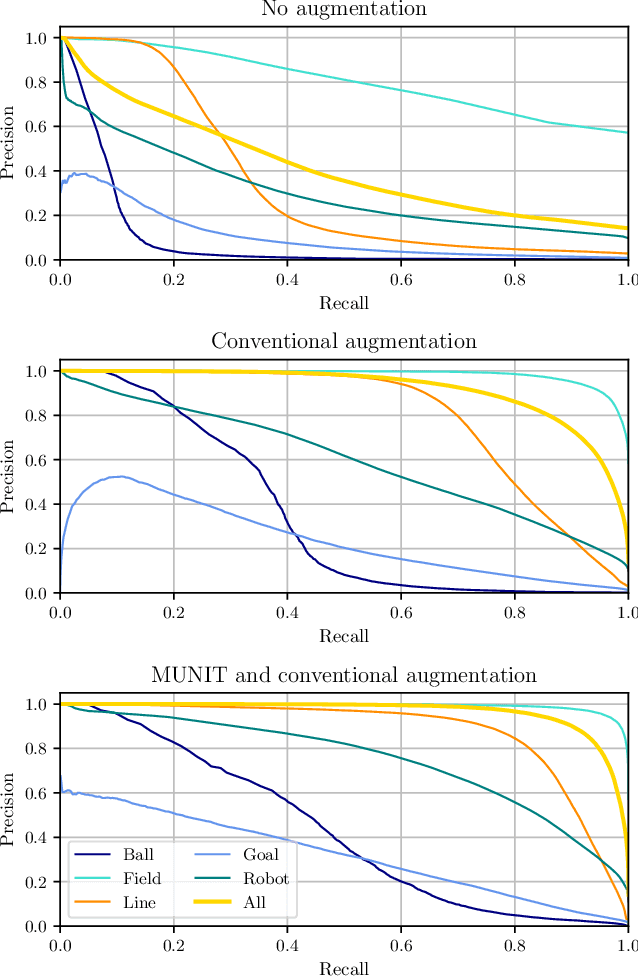

Deep learning approaches have become the standard solution to many problems in computer vision and robotics, but obtaining proper and sufficient training data is often a problem, as human labor is often error prone, time consuming and expensive. Solutions based on simulation have become more popular in recent years, but the gap between simulation and reality is still a major issue. In this paper, we introduce a novel model for augmenting synthetic image data through unsupervised image-to-image translation by applying the style of real world images to simulated images with open source frameworks. This model intends to generate the training data as a separate step and not as part of the training. The generated dataset is combined with conventional augmentation methods and is then applied to a neural network capable of running in real-time on autonomous soccer robots. Our evaluation shows a significant improvement compared to networks trained on simulated images without this kind of augmentation.
Data Augmentation for Object Detection via Differentiable Neural Rendering
Apr 05, 2021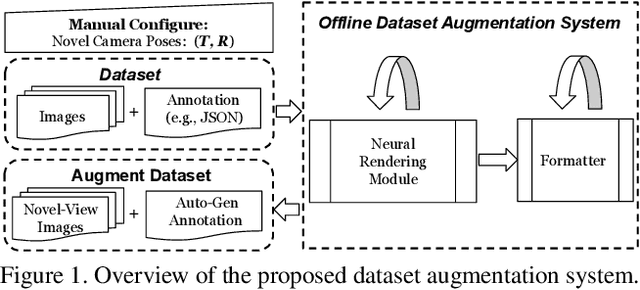
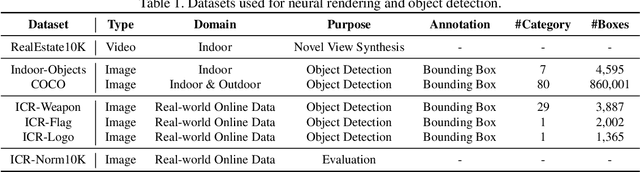
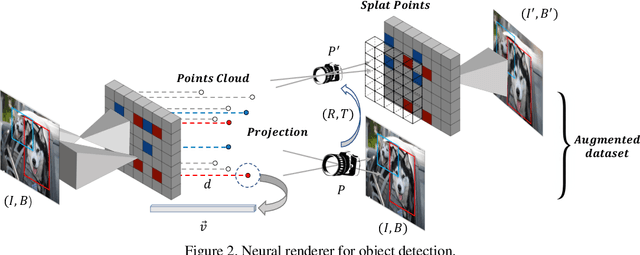
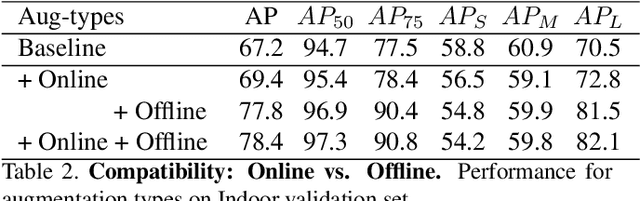
It is challenging to train a robust object detector under the supervised learning setting when the annotated data are scarce. Thus, previous approaches tackling this problem are in two categories: semi-supervised learning models that interpolate labeled data from unlabeled data, and self-supervised learning approaches that exploit signals within unlabeled data via pretext tasks. To seamlessly integrate and enhance existing supervised object detection methods, in this work, we focus on addressing the data scarcity problem from a fundamental viewpoint without changing the supervised learning paradigm. We propose a new offline data augmentation method for object detection, which semantically interpolates the training data with novel views. Specifically, our new system generates controllable views of training images based on differentiable neural rendering, together with corresponding bounding box annotations which involve no human intervention. Firstly, we extract and project pixel-aligned image features into point clouds while estimating depth maps. We then re-project them with a target camera pose and render a novel-view 2d image. Objects in the form of keypoints are marked in point clouds to recover annotations in new views. Our new method is fully compatible with online data augmentation methods, such as affine transform, image mixup, etc. Extensive experiments show that our method, as a cost-free tool to enrich images and labels, can significantly boost the performance of object detection systems with scarce training data. Code is available at \url{https://github.com/Guanghan/DANR}.
Dense Depth Posterior (DDP) from Single Image and Sparse Range
Jan 28, 2019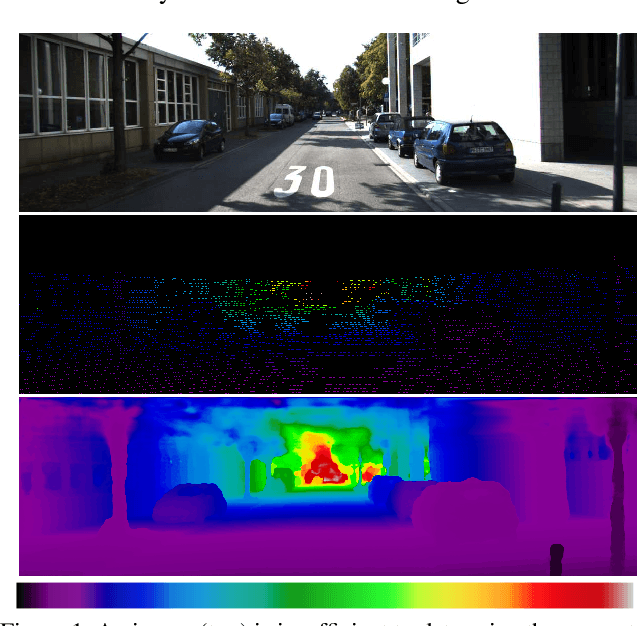
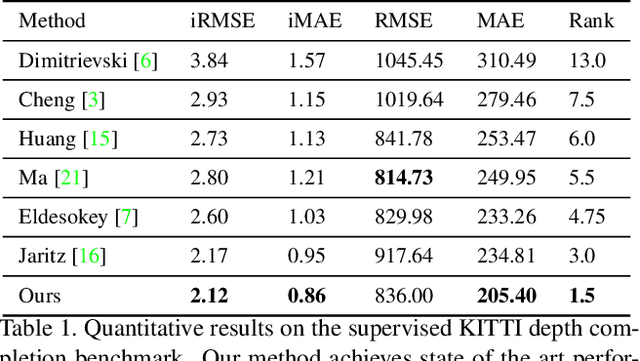
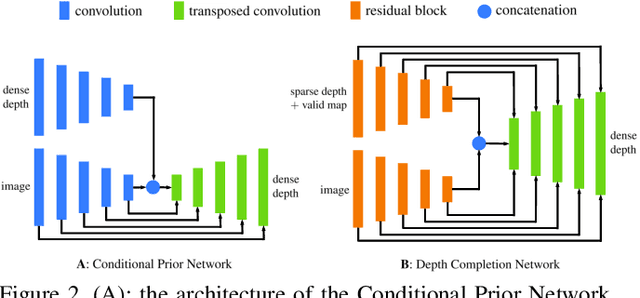
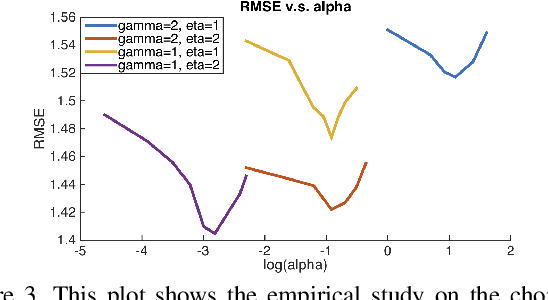
We present a deep learning system to infer the posterior distribution of a dense depth map associated with an image, by exploiting sparse range measurements, for instance from a lidar. While the lidar may provide a depth value for a small percentage of the pixels, we exploit regularities reflected in the training set to complete the map so as to have a probability over depth for each pixel in the image. We exploit a Conditional Prior Network, that allows associating a probability to each depth value given an image, and combine it with a likelihood term that uses the sparse measurements. Optionally we can also exploit the availability of stereo during training, but in any case only require a single image and a sparse point cloud at run-time. We test our approach on both unsupervised and supervised depth completion using the KITTI benchmark, and improve the state-of-the-art in both.
EQFace: A Simple Explicit Quality Network for Face Recognition
May 03, 2021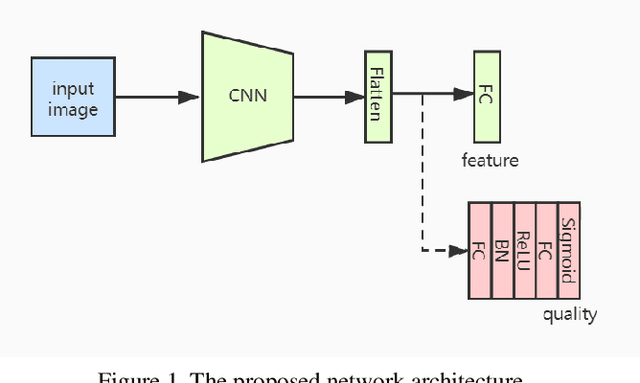
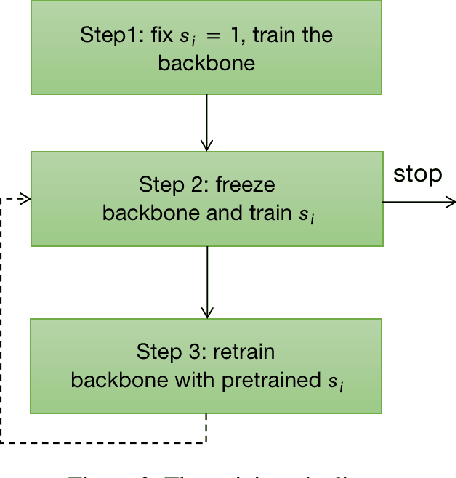
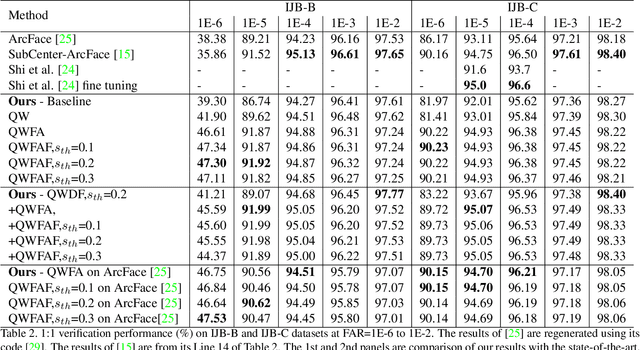
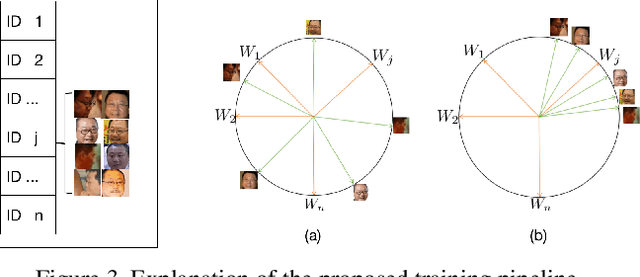
As the deep learning makes big progresses in still-image face recognition, unconstrained video face recognition is still a challenging task due to low quality face images caused by pose, blur, occlusion, illumination etc. In this paper we propose a network for face recognition which gives an explicit and quantitative quality score at the same time when a feature vector is extracted. To our knowledge this is the first network that implements these two functions in one network online. This network is very simple by adding a quality network branch to the baseline network of face recognition. It does not require training datasets with annotated face quality labels. We evaluate this network on both still-image face datasets and video face datasets and achieve the state-of-the-art performance in many cases. This network enables a lot of applications where an explicit face quality scpre is used. We demonstrate three applications of the explicit face quality, one of which is a progressive feature aggregation scheme in online video face recognition. We design an experiment to prove the benefits of using the face quality in this application. Code will be available at \url{https://github.com/deepcam-cn/facequality}.