 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Bayesian analysis of the prevalence bias: learning and predicting from imbalanced data
Jul 31, 2021
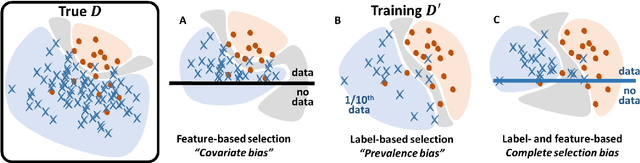
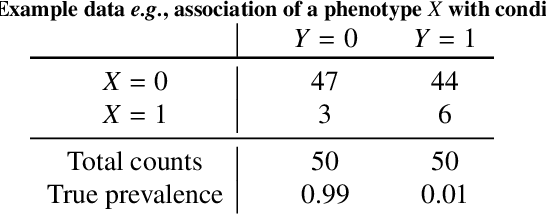

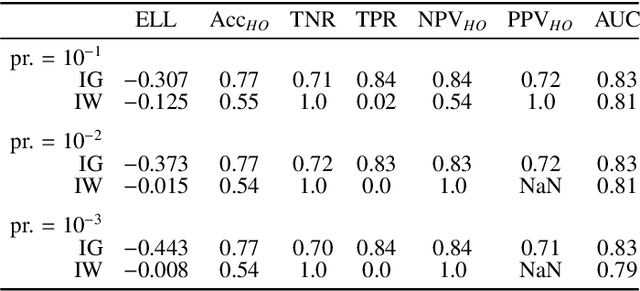
Datasets are rarely a realistic approximation of the target population. Say, prevalence is misrepresented, image quality is above clinical standards, etc. This mismatch is known as sampling bias. Sampling biases are a major hindrance for machine learning models. They cause significant gaps between model performance in the lab and in the real world. Our work is a solution to prevalence bias. Prevalence bias is the discrepancy between the prevalence of a pathology and its sampling rate in the training dataset, introduced upon collecting data or due to the practioner rebalancing the training batches. This paper lays the theoretical and computational framework for training models, and for prediction, in the presence of prevalence bias. Concretely a bias-corrected loss function, as well as bias-corrected predictive rules, are derived under the principles of Bayesian risk minimization. The loss exhibits a direct connection to the information gain. It offers a principled alternative to heuristic training losses and complements test-time procedures based on selecting an operating point from summary curves. It integrates seamlessly in the current paradigm of (deep) learning using stochastic backpropagation and naturally with Bayesian models.
Spatial Attentive Single-Image Deraining with a High Quality Real Rain Dataset
Apr 02, 2019
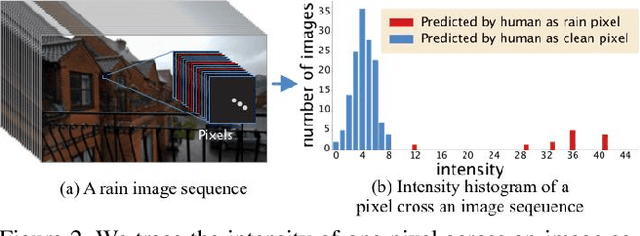

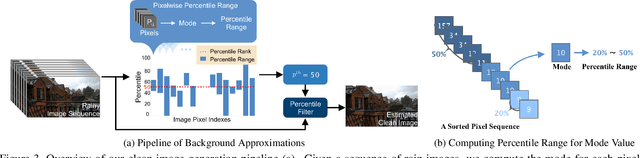
Removing rain streaks from a single image has been drawing considerable attention as rain streaks can severely degrade the image quality and affect the performance of existing outdoor vision tasks. While recent CNN-based derainers have reported promising performances, deraining remains an open problem for two reasons. First, existing synthesized rain datasets have only limited realism, in terms of modeling real rain characteristics such as rain shape, direction and intensity. Second, there are no public benchmarks for quantitative comparisons on real rain images, which makes the current evaluation less objective. The core challenge is that real world rain/clean image pairs cannot be captured at the same time. In this paper, we address the single image rain removal problem in two ways. First, we propose a semi-automatic method that incorporates temporal priors and human supervision to generate a high-quality clean image from each input sequence of real rain images. Using this method, we construct a large-scale dataset of $\sim$$29.5K$ rain/rain-free image pairs that covers a wide range of natural rain scenes. Second, to better cover the stochastic distribution of real rain streaks, we propose a novel SPatial Attentive Network (SPANet) to remove rain streaks in a local-to-global manner. Extensive experiments demonstrate that our network performs favorably against the state-of-the-art deraining methods.
Rethinking Hard-Parameter Sharing in Multi-Task Learning
Jul 23, 2021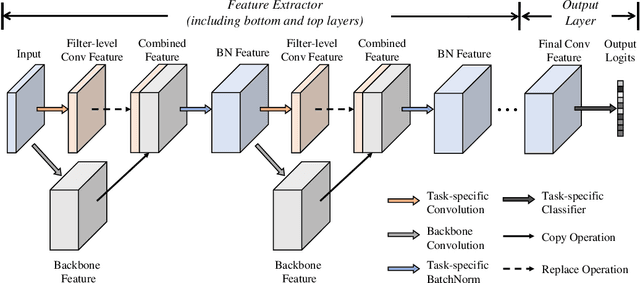
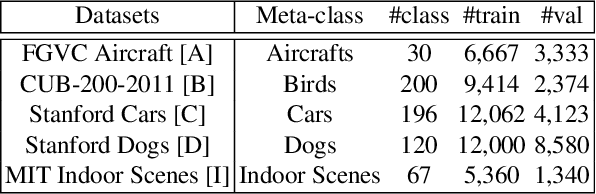
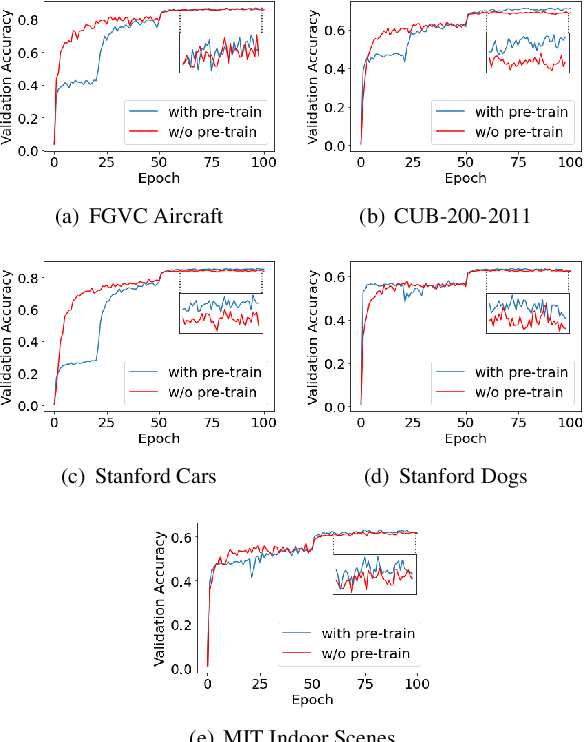
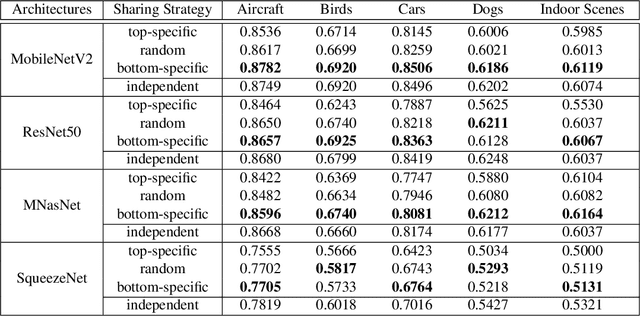
Hard parameter sharing in multi-task learning (MTL) allows tasks to share some of model parameters, reducing storage cost and improving prediction accuracy. The common sharing practice is to share bottom layers of a deep neural network among tasks while using separate top layers for each task. In this work, we revisit this common practice via an empirical study on fine-grained image classification tasks and make two surprising observations. (1) Using separate bottom-layer parameters could achieve significantly better performance than the common practice and this phenomenon holds for different number of tasks jointly trained on different backbone architectures with different quantity of task-specific parameters. (2) A multi-task model with a small proportion of task-specific parameters from bottom layers can achieve competitive performance with independent models trained on each task separately and outperform a state-of-the-art MTL framework. Our observations suggest that people rethink the current sharing paradigm and adopt the new strategy of using separate bottom-layer parameters as a stronger baseline for model design in MTL.
Perceptual Loss for Robust Unsupervised Homography Estimation
Apr 20, 2021
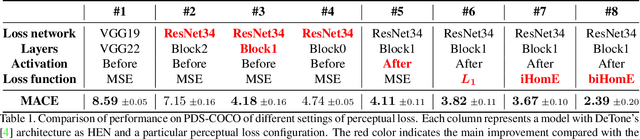
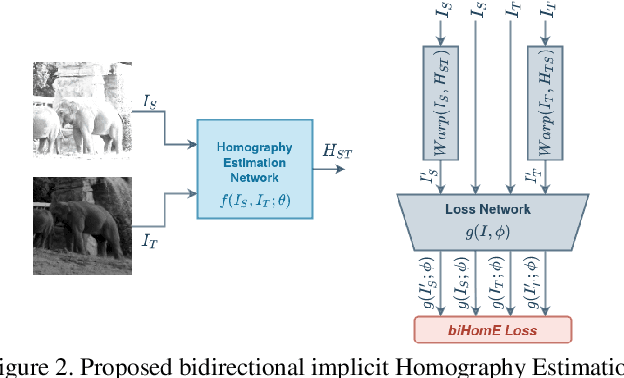
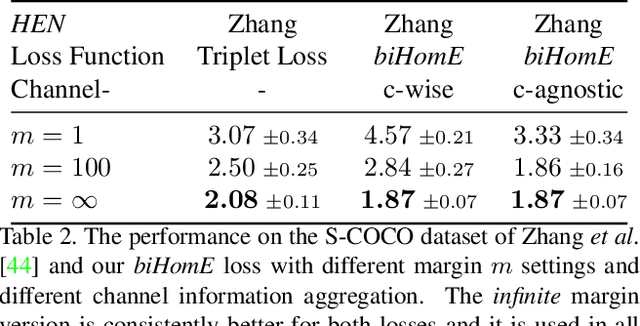
Homography estimation is often an indispensable step in many computer vision tasks. The existing approaches, however, are not robust to illumination and/or larger viewpoint changes. In this paper, we propose bidirectional implicit Homography Estimation (biHomE) loss for unsupervised homography estimation. biHomE minimizes the distance in the feature space between the warped image from the source viewpoint and the corresponding image from the target viewpoint. Since we use a fixed pre-trained feature extractor and the only learnable component of our framework is the homography network, we effectively decouple the homography estimation from representation learning. We use an additional photometric distortion step in the synthetic COCO dataset generation to better represent the illumination variation of the real-world scenarios. We show that biHomE achieves state-of-the-art performance on synthetic COCO dataset, which is also comparable or better compared to supervised approaches. Furthermore, the empirical results demonstrate the robustness of our approach to illumination variation compared to existing methods.
An Autoencoder-based Learned Image Compressor: Description of Challenge Proposal by NCTU
Feb 20, 2019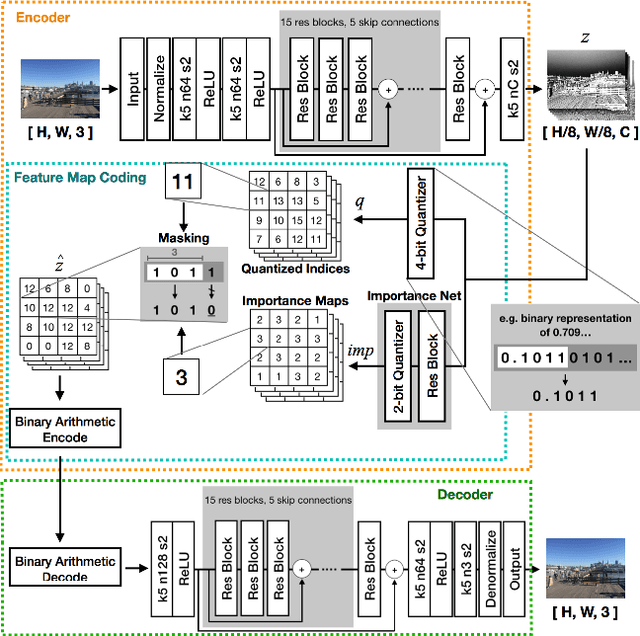
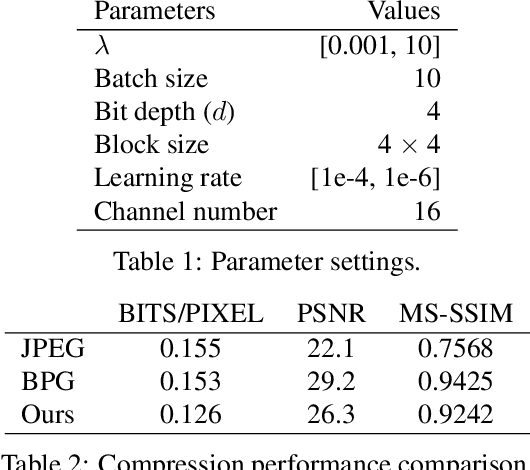

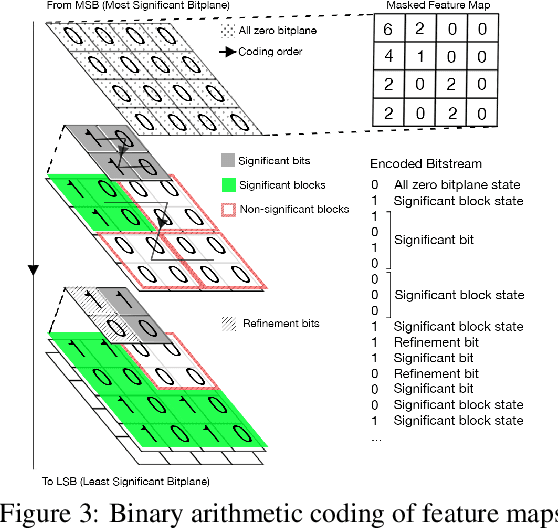
We propose a lossy image compression system using the deep-learning autoencoder structure to participate in the Challenge on Learned Image Compression (CLIC) 2018. Our autoencoder uses the residual blocks with skip connections to reduce the correlation among image pixels and condense the input image into a set of feature maps, a compact representation of the original image. The bit allocation and bitrate control are implemented by using the importance maps and quantizer. The importance maps are generated by a separate neural net in the encoder. The autoencoder and the importance net are trained jointly based on minimizing a weighted sum of mean squared error, MS-SSIM, and a rate estimate. Our aim is to produce reconstructed images with good subjective quality subject to the 0.15 bits-per-pixel constraint.
6D Object Pose Estimation using Keypoints and Part Affinity Fields
Jul 05, 2021



The task of 6D object pose estimation from RGB images is an important requirement for autonomous service robots to be able to interact with the real world. In this work, we present a two-step pipeline for estimating the 6 DoF translation and orientation of known objects. Keypoints and Part Affinity Fields (PAFs) are predicted from the input image adopting the OpenPose CNN architecture from human pose estimation. Object poses are then calculated from 2D-3D correspondences between detected and model keypoints via the PnP-RANSAC algorithm. The proposed approach is evaluated on the YCB-Video dataset and achieves accuracy on par with recent methods from the literature. Using PAFs to assemble detected keypoints into object instances proves advantageous over only using heatmaps. Models trained to predict keypoints of a single object class perform significantly better than models trained for several classes.
* In: Proceedings of 24th RoboCup International Symposium, June 2021, 12 pages, 6 figures
Gated Hierarchical Attention for Image Captioning
Oct 31, 2018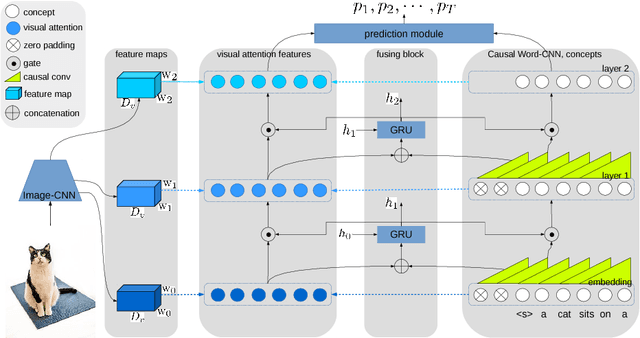
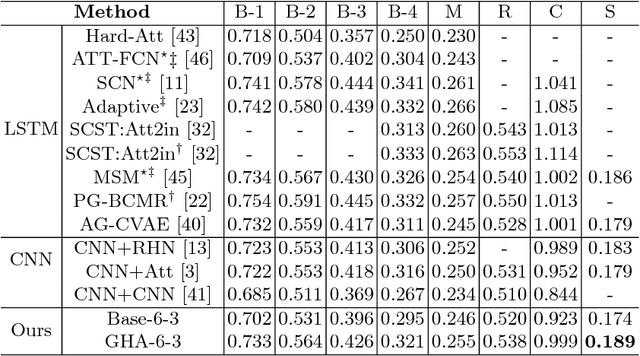
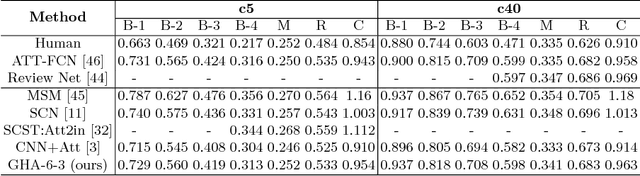

Attention modules connecting encoder and decoders have been widely applied in the field of object recognition, image captioning, visual question answering and neural machine translation, and significantly improves the performance. In this paper, we propose a bottom-up gated hierarchical attention (GHA) mechanism for image captioning. Our proposed model employs a CNN as the decoder which is able to learn different concepts at different layers, and apparently, different concepts correspond to different areas of an image. Therefore, we develop the GHA in which low-level concepts are merged into high-level concepts and simultaneously low-level attended features pass to the top to make predictions. Our GHA significantly improves the performance of the model that only applies one level attention, for example, the CIDEr score increases from 0.923 to 0.999, which is comparable to the state-of-the-art models that employ attributes boosting and reinforcement learning (RL). We also conduct extensive experiments to analyze the CNN decoder and our proposed GHA, and we find that deeper decoders cannot obtain better performance, and when the convolutional decoder becomes deeper the model is likely to collapse during training.
Rethinking Few-Shot Image Classification: a Good Embedding Is All You Need?
Mar 25, 2020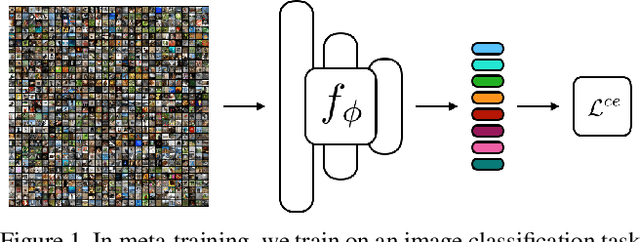
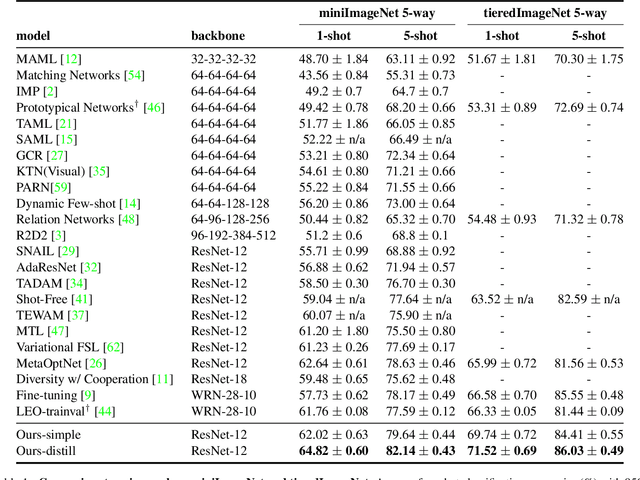
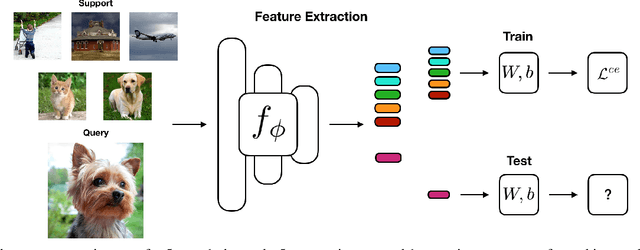
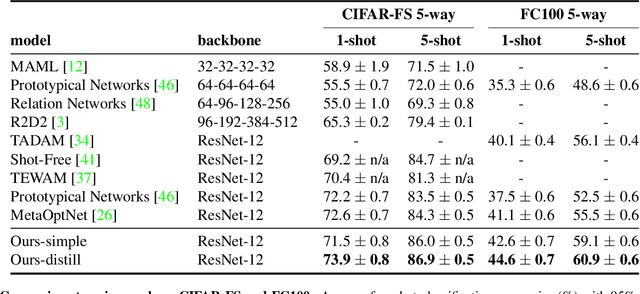
The focus of recent meta-learning research has been on the development of learning algorithms that can quickly adapt to test time tasks with limited data and low computational cost. Few-shot learning is widely used as one of the standard benchmarks in meta-learning. In this work, we show that a simple baseline: learning a supervised or self-supervised representation on the meta-training set, followed by training a linear classifier on top of this representation, outperforms state-of-the-art few-shot learning methods. An additional boost can be achieved through the use of self-distillation. This demonstrates that using a good learned embedding model can be more effective than sophisticated meta-learning algorithms. We believe that our findings motivate a rethinking of few-shot image classification benchmarks and the associated role of meta-learning algorithms. Code is available at: http://github.com/WangYueFt/rfs/.
Adversarial Attack on Deep Product Quantization Network for Image Retrieval
Feb 26, 2020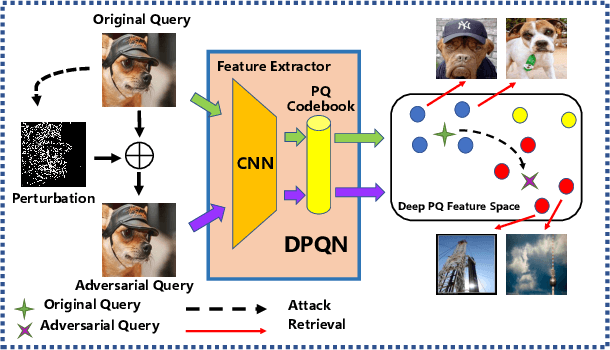
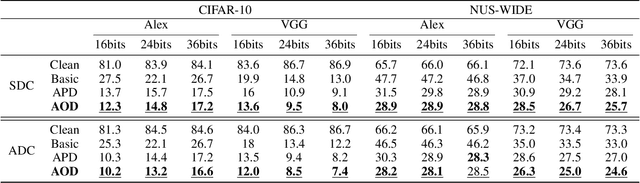
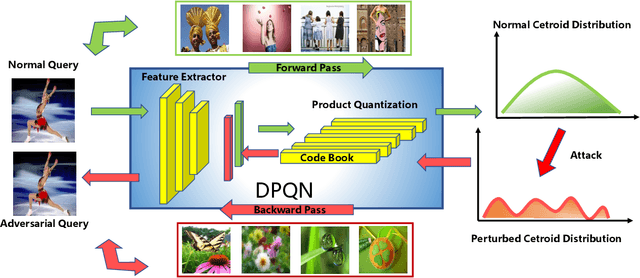
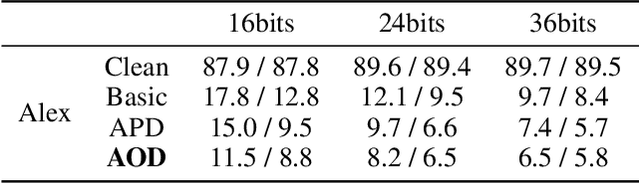
Deep product quantization network (DPQN) has recently received much attention in fast image retrieval tasks due to its efficiency of encoding high-dimensional visual features especially when dealing with large-scale datasets. Recent studies show that deep neural networks (DNNs) are vulnerable to input with small and maliciously designed perturbations (a.k.a., adversarial examples). This phenomenon raises the concern of security issues for DPQN in the testing/deploying stage as well. However, little effort has been devoted to investigating how adversarial examples affect DPQN. To this end, we propose product quantization adversarial generation (PQ-AG), a simple yet effective method to generate adversarial examples for product quantization based retrieval systems. PQ-AG aims to generate imperceptible adversarial perturbations for query images to form adversarial queries, whose nearest neighbors from a targeted product quantizaiton model are not semantically related to those from the original queries. Extensive experiments show that our PQ-AQ successfully creates adversarial examples to mislead targeted product quantization retrieval models. Besides, we found that our PQ-AG significantly degrades retrieval performance in both white-box and black-box settings.
Segmentation-grounded Scene Graph Generation
Apr 29, 2021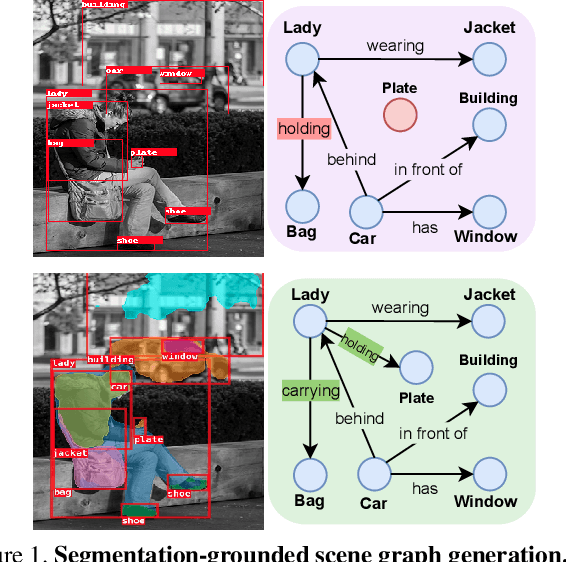
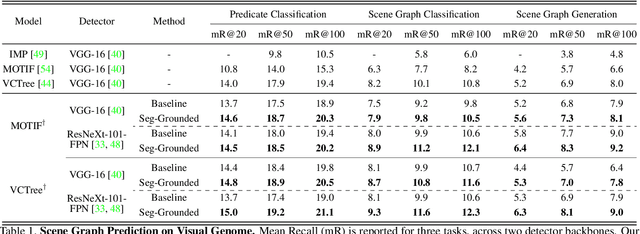
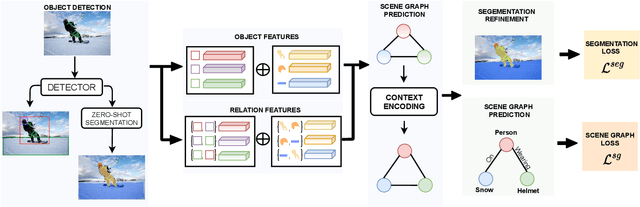
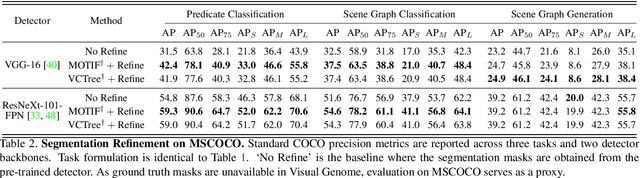
Scene graph generation has emerged as an important problem in computer vision. While scene graphs provide a grounded representation of objects, their locations and relations in an image, they do so only at the granularity of proposal bounding boxes. In this work, we propose the first, to our knowledge, framework for pixel-level segmentation-grounded scene graph generation. Our framework is agnostic to the underlying scene graph generation method and address the lack of segmentation annotations in target scene graph datasets (e.g., Visual Genome) through transfer and multi-task learning from, and with, an auxiliary dataset (e.g., MS COCO). Specifically, each target object being detected is endowed with a segmentation mask, which is expressed as a lingual-similarity weighted linear combination over categories that have annotations present in an auxiliary dataset. These inferred masks, along with a novel Gaussian attention mechanism which grounds the relations at a pixel-level within the image, allow for improved relation prediction. The entire framework is end-to-end trainable and is learned in a multi-task manner with both target and auxiliary datasets.