 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGated Hierarchical Attention for Image Captioning
Paper and Code
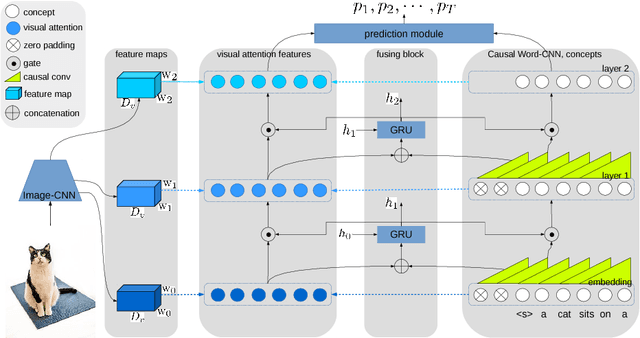
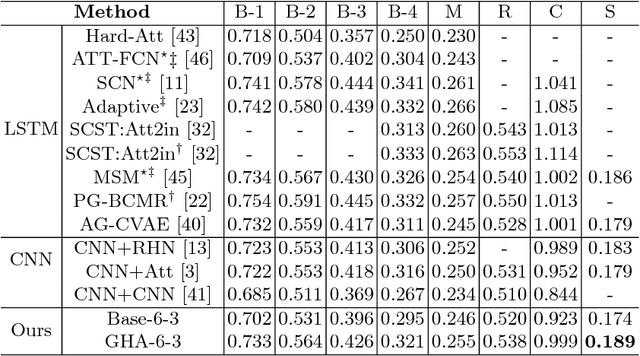
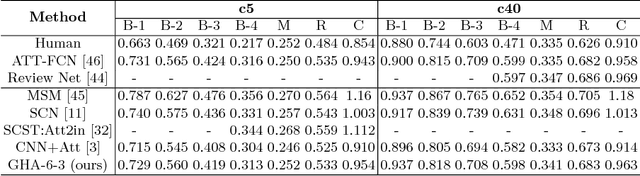

Attention modules connecting encoder and decoders have been widely applied in the field of object recognition, image captioning, visual question answering and neural machine translation, and significantly improves the performance. In this paper, we propose a bottom-up gated hierarchical attention (GHA) mechanism for image captioning. Our proposed model employs a CNN as the decoder which is able to learn different concepts at different layers, and apparently, different concepts correspond to different areas of an image. Therefore, we develop the GHA in which low-level concepts are merged into high-level concepts and simultaneously low-level attended features pass to the top to make predictions. Our GHA significantly improves the performance of the model that only applies one level attention, for example, the CIDEr score increases from 0.923 to 0.999, which is comparable to the state-of-the-art models that employ attributes boosting and reinforcement learning (RL). We also conduct extensive experiments to analyze the CNN decoder and our proposed GHA, and we find that deeper decoders cannot obtain better performance, and when the convolutional decoder becomes deeper the model is likely to collapse during training.