 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Medical Datasets Collections for Artificial Intelligence-based Medical Image Analysis
Feb 18, 2021
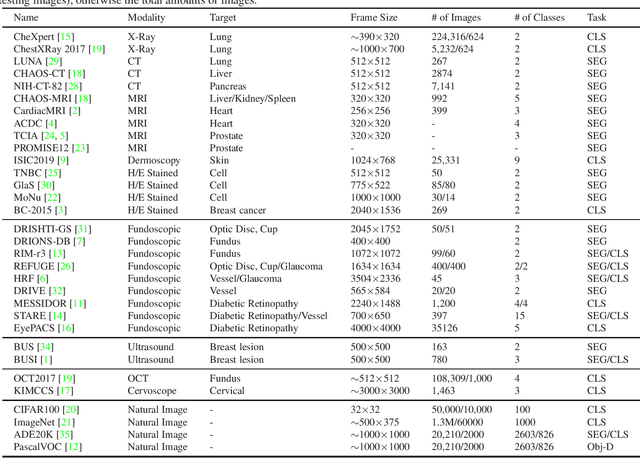
We collected 32 public datasets, of which 28 for medical imaging and 4 for natural images, to conduct study. The images of these datasets are captured by different cameras, thus vary from each other in modality, frame size and capacity. For data accessibility, we also provide the websites of most datasets and hope this will help the readers reach the datasets.
GridDehazeNet: Attention-Based Multi-Scale Network for Image Dehazing
Aug 08, 2019
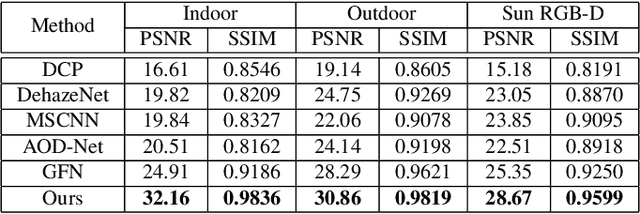
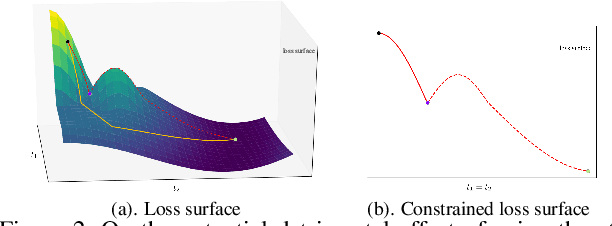
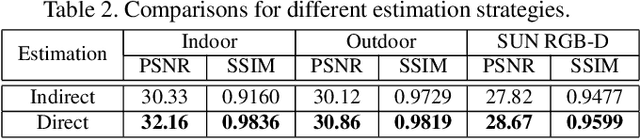
We propose an end-to-end trainable Convolutional Neural Network (CNN), named GridDehazeNet, for single image dehazing. The GridDehazeNet consists of three modules: pre-processing, backbone, and post-processing. The trainable pre-processing module can generate learned inputs with better diversity and more pertinent features as compared to those derived inputs produced by hand-selected pre-processing methods. The backbone module implements a novel attention-based multi-scale estimation on a grid network, which can effectively alleviate the bottleneck issue often encountered in the conventional multi-scale approach. The post-processing module helps to reduce the artifacts in the final output. Experimental results indicate that the GridDehazeNet outperforms the state-of-the-arts on both synthetic and real-world images. The proposed hazing method does not rely on the atmosphere scattering model, and we provide an explanation as to why it is not necessarily beneficial to take advantage of the dimension reduction offered by the atmosphere scattering model for image dehazing, even if only the dehazing results on synthetic images are concerned.
Semantic Hierarchy Preserving Deep Hashing for Large-scale Image Retrieval
Apr 12, 2019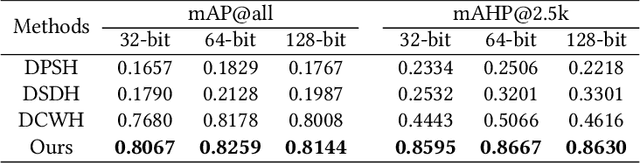

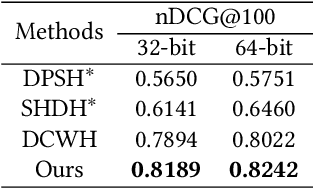
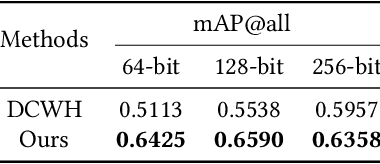
Convolutional neural networks have been widely used in content-based image retrieval. To better deal with large-scale data, the deep hashing model is proposed as an effective method, which maps an image to a binary code that can be used for hashing search. However, most existing deep hashing models only utilize fine-level semantic labels or convert them to similar/dissimilar labels for training. The natural semantic hierarchy structures are ignored in the training stage of the deep hashing model. In this paper, we present an effective algorithm to train a deep hashing model that can preserve a semantic hierarchy structure for large-scale image retrieval. Experiments on two datasets show that our method improves the fine-level retrieval performance. Meanwhile, our model achieves state-of-the-art results in terms of hierarchical retrieval.
Learning Non-local Image Diffusion for Image Denoising
Feb 24, 2017


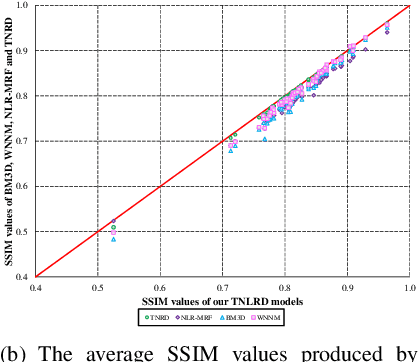
Image diffusion plays a fundamental role for the task of image denoising. Recently proposed trainable nonlinear reaction diffusion (TNRD) model defines a simple but very effective framework for image denoising. However, as the TNRD model is a local model, the diffusion behavior of which is purely controlled by information of local patches, it is prone to create artifacts in the homogenous regions and over-smooth highly textured regions, especially in the case of strong noise levels. Meanwhile, it is widely known that the non-local self-similarity (NSS) prior stands as an effective image prior for image denoising, which has been widely exploited in many non-local methods. In this work, we are highly motivated to embed the NSS prior into the TNRD model to tackle its weaknesses. In order to preserve the expected property that end-to-end training is available, we exploit the NSS prior by a set of non-local filters, and derive our proposed trainable non-local reaction diffusion (TNLRD) model for image denoising. Together with the local filters and influence functions, the non-local filters are learned by employing loss-specific training. The experimental results show that the trained TNLRD model produces visually plausible recovered images with more textures and less artifacts, compared to its local versions. Moreover, the trained TNLRD model can achieve strongly competitive performance to recent state-of-the-art image denoising methods in terms of peak signal-to-noise ratio (PSNR) and structural similarity index (SSIM).
Models Genesis: Generic Autodidactic Models for 3D Medical Image Analysis
Aug 19, 2019
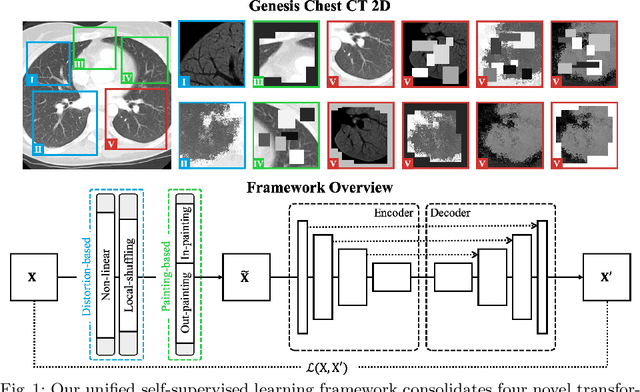
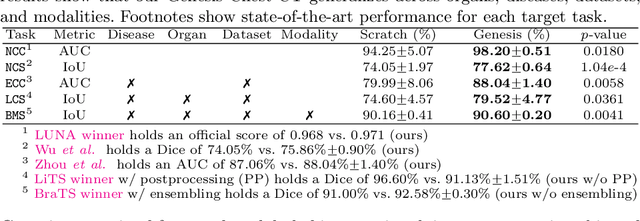
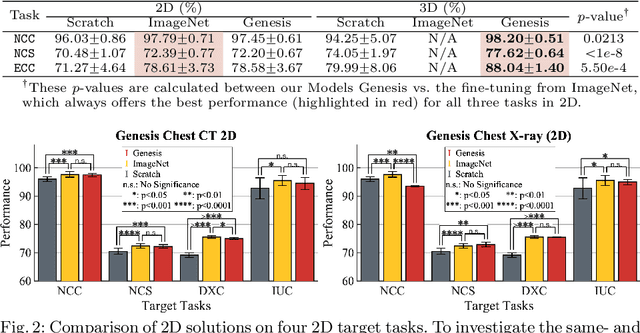
Transfer learning from natural image to medical image has established as one of the most practical paradigms in deep learning for medical image analysis. However, to fit this paradigm, 3D imaging tasks in the most prominent imaging modalities (e.g., CT and MRI) have to be reformulated and solved in 2D, losing rich 3D anatomical information and inevitably compromising the performance. To overcome this limitation, we have built a set of models, called Generic Autodidactic Models, nicknamed Models Genesis, because they are created ex nihilo (with no manual labeling), self-taught (learned by self-supervision), and generic (served as source models for generating application-specific target models). Our extensive experiments demonstrate that our Models Genesis significantly outperform learning from scratch in all five target 3D applications covering both segmentation and classification. More importantly, learning a model from scratch simply in 3D may not necessarily yield performance better than transfer learning from ImageNet in 2D, but our Models Genesis consistently top any 2D approaches including fine-tuning the models pre-trained from ImageNet as well as fine-tuning the 2D versions of our Models Genesis, confirming the importance of 3D anatomical information and significance of our Models Genesis for 3D medical imaging. This performance is attributed to our unified self-supervised learning framework, built on a simple yet powerful observation: the sophisticated yet recurrent anatomy in medical images can serve as strong supervision signals for deep models to learn common anatomical representation automatically via self-supervision. As open science, all pre-trained Models Genesis are available at https://github.com/MrGiovanni/ModelsGenesis.
Unsupervised Person Re-Identification with Multi-Label Learning Guided Self-Paced Clustering
Mar 08, 2021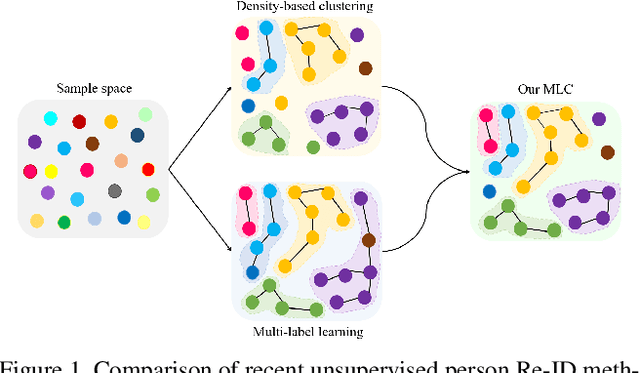

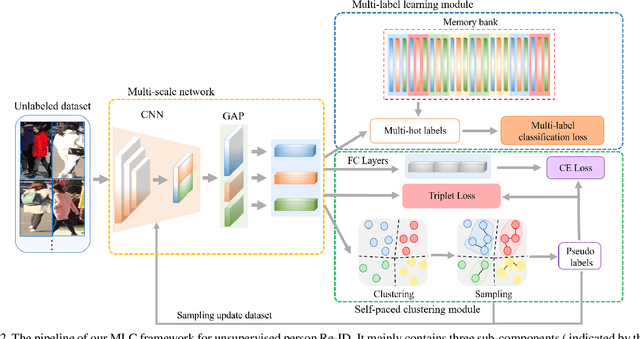
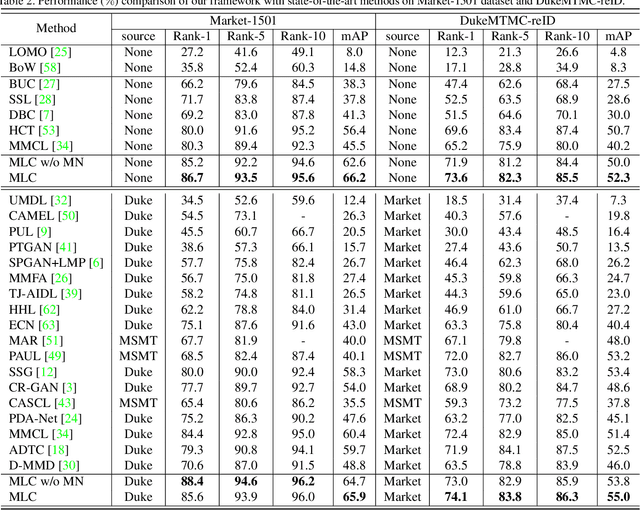
Although unsupervised person re-identification (Re-ID) has drawn increasing research attention recently, it remains challenging to learn discriminative features without annotations across disjoint camera views. In this paper, we address the unsupervised person Re-ID with a conceptually novel yet simple framework, termed as Multi-label Learning guided self-paced Clustering (MLC). MLC mainly learns discriminative features with three crucial modules, namely a multi-scale network, a multi-label learning module, and a self-paced clustering module. Specifically, the multi-scale network generates multi-granularity person features in both global and local views. The multi-label learning module leverages a memory feature bank and assigns each image with a multi-label vector based on the similarities between the image and feature bank. After multi-label training for several epochs, the self-paced clustering joins in training and assigns a pseudo label for each image. The benefits of our MLC come from three aspects: i) the multi-scale person features for better similarity measurement, ii) the multi-label assignment based on the whole dataset ensures that every image can be trained, and iii) the self-paced clustering removes some noisy samples for better feature learning. Extensive experiments on three popular large-scale Re-ID benchmarks demonstrate that our MLC outperforms previous state-of-the-art methods and significantly improves the performance of unsupervised person Re-ID.
IDOL-Net: An Interactive Dual-Domain Parallel Network for CT Metal Artifact Reduction
Apr 03, 2021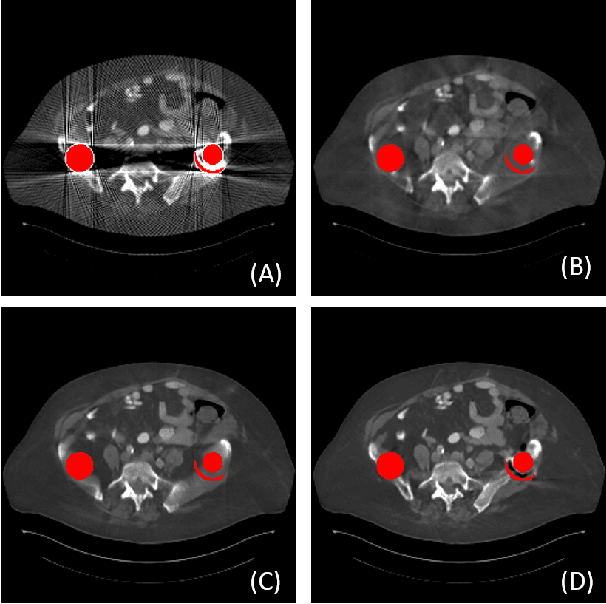
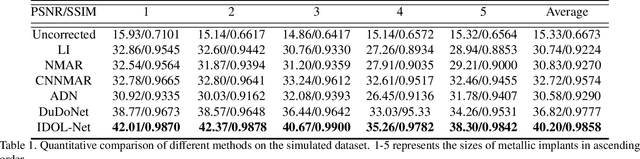
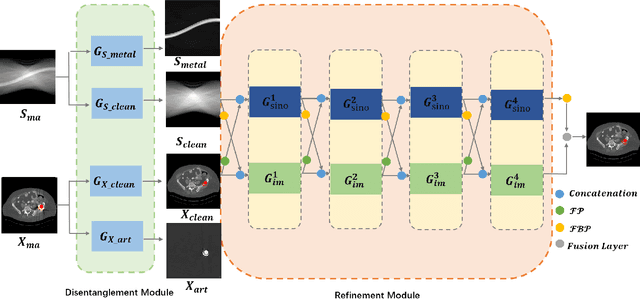

Due to the presence of metallic implants, the imaging quality of computed tomography (CT) would be heavily degraded. With the rapid development of deep learning, several network models have been proposed for metal artifact reduction (MAR). Since the dual-domain MAR methods can leverage the hybrid information from both sinogram and image domains, they have significantly improved the performance compared to single-domain methods. However,current dual-domain methods usually operate on both domains in a specific order, which implicitly imposes a certain priority prior into MAR and may ignore the latent information interaction between both domains. To address this problem, in this paper, we propose a novel interactive dualdomain parallel network for CT MAR, dubbed as IDOLNet. Different from existing dual-domain methods, the proposed IDOL-Net is composed of two modules. The disentanglement module is utilized to generate high-quality prior sinogram and image as the complementary inputs. The follow-up refinement module consists of two parallel and interactive branches that simultaneously operate on image and sinogram domain, fully exploiting the latent information interaction between both domains. The simulated and clinical results demonstrate that the proposed IDOL-Net outperforms several state-of-the-art models in both qualitative and quantitative aspects.
Spatiotemporal Registration for Event-based Visual Odometry
Mar 19, 2021
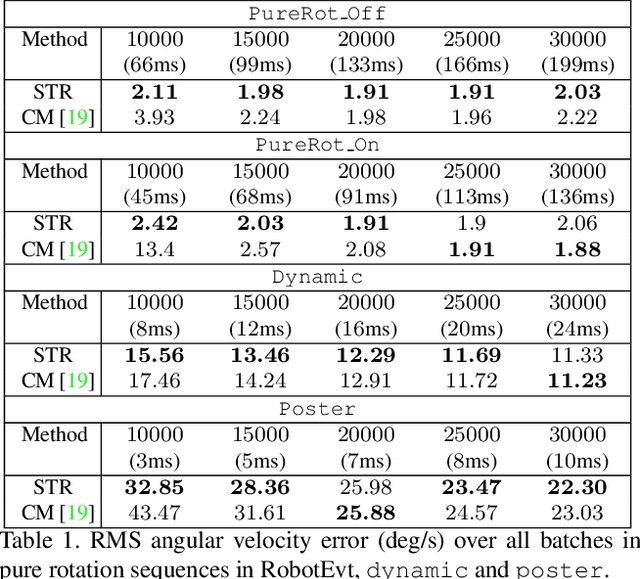
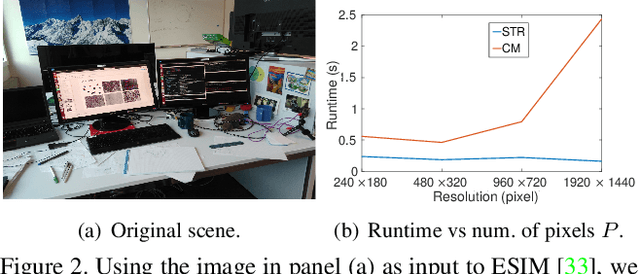
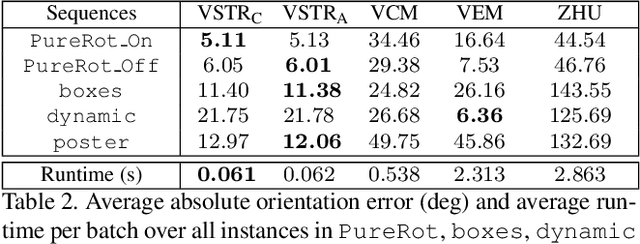
A useful application of event sensing is visual odometry, especially in settings that require high-temporal resolution. The state-of-the-art method of contrast maximisation recovers the motion from a batch of events by maximising the contrast of the image of warped events. However, the cost scales with image resolution and the temporal resolution can be limited by the need for large batch sizes to yield sufficient structure in the contrast image. In this work, we propose spatiotemporal registration as a compelling technique for event-based rotational motion estimation. We theoretcally justify the approach and establish its fundamental and practical advantages over contrast maximisation. In particular, spatiotemporal registration also produces feature tracks as a by-product, which directly supports an efficient visual odometry pipeline with graph-based optimisation for motion averaging. The simplicity of our visual odometry pipeline allows it to process more than 1 M events/second. We also contribute a new event dataset for visual odometry, where motion sequences with large velocity variations were acquired using a high-precision robot arm.
Visual Tree Convolutional Neural Network in Image Classification
Jun 04, 2019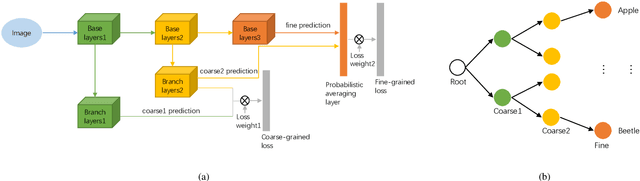
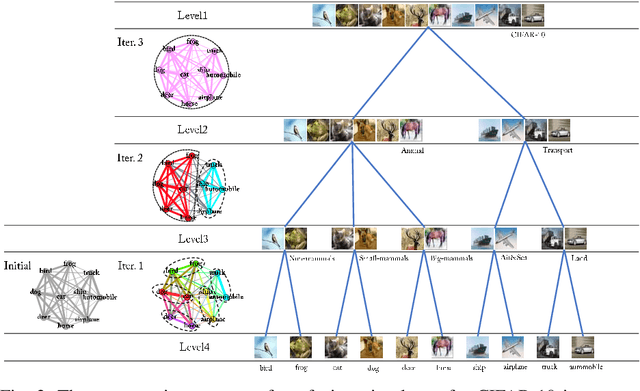
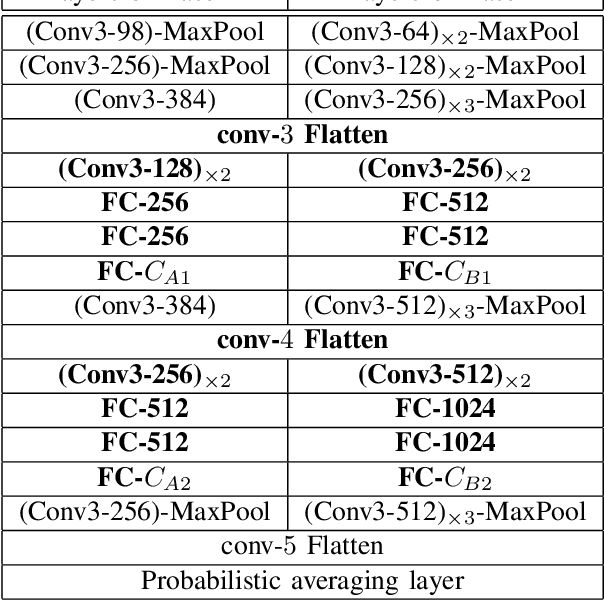
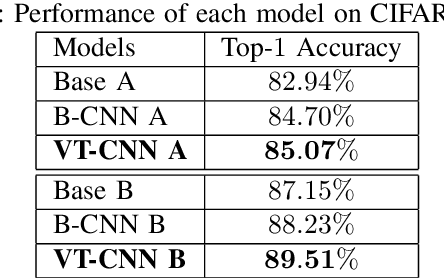
In image classification, Convolutional Neural Network(CNN) models have achieved high performance with the rapid development in deep learning. However, some categories in the image datasets are more difficult to distinguished than others. Improving the classification accuracy on these confused categories is benefit to the overall performance. In this paper, we build a Confusion Visual Tree(CVT) based on the confused semantic level information to identify the confused categories. With the information provided by the CVT, we can lead the CNN training procedure to pay more attention on these confused categories. Therefore, we propose Visual Tree Convolutional Neural Networks(VT-CNN) based on the original deep CNN embedded with our CVT. We evaluate our VT-CNN model on the benchmark datasets CIFAR-10 and CIFAR-100. In our experiments, we build up 3 different VT-CNN models and they obtain improvement over their based CNN models by 1.36%, 0.89% and 0.64%, respectively.
* 7 pages, 2 figures, conference
Universal Image Manipulation Detection using Deep Siamese Convolutional Neural Network
Aug 23, 2018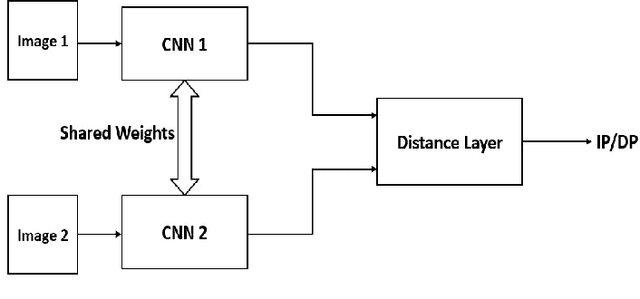
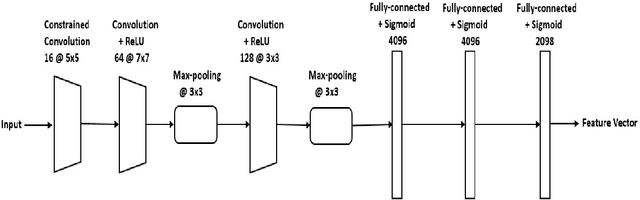
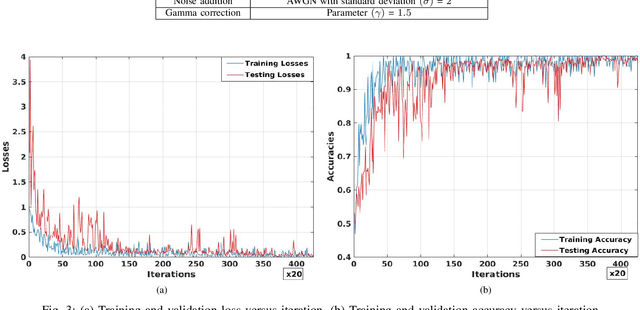

Detection of different types of image editing operations carried out on an image is an important problem in image forensics. It gives the information about the processing history of an image, and also can expose forgeries present in an image. There have been few methods proposed to detect different types of image editing operations in a single framework. However, all the operations have to be known a priori in the training phase. But, in real-forensics scenarios it may not be possible to know about the editing operations carried out on an image. To solve this problem, we propose a novel deep learning-based method which can differentiate between different types of image editing operations. The proposed method classifies image patches in a pair-wise fashion as either similarly or differently processed using a deep siamese neural network. Once the network learns feature that can discriminate between different image editing operations, it can differentiate between different image editing operations not present in the training stage. The experimental results show the efficacy of the proposed method in detecting/discriminating different image editing operations.