 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DVMN: Dense Validity Mask Network for Depth Completion
Jul 14, 2021

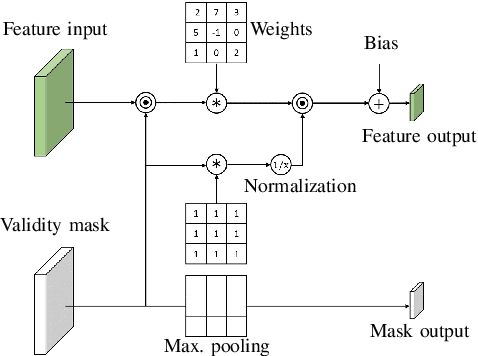
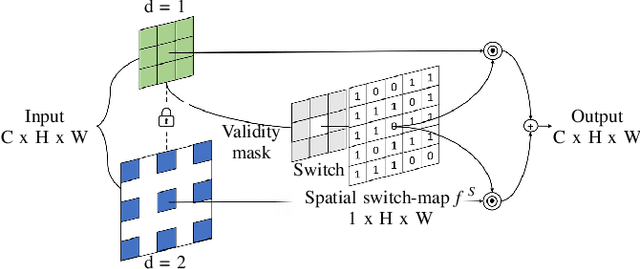
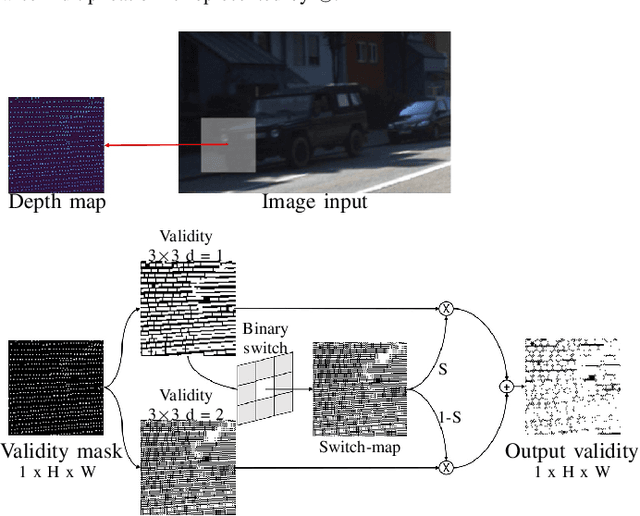
LiDAR depth maps provide environmental guidance in a variety of applications. However, such depth maps are typically sparse and insufficient for complex tasks such as autonomous navigation. State of the art methods use image guided neural networks for dense depth completion. We develop a guided convolutional neural network focusing on gathering dense and valid information from sparse depth maps. To this end, we introduce a novel layer with spatially variant and content-depended dilation to include additional data from sparse input. Furthermore, we propose a sparsity invariant residual bottleneck block. We evaluate our Dense Validity Mask Network (DVMN) on the KITTI depth completion benchmark and achieve state of the art results. At the time of submission, our network is the leading method using sparsity invariant convolution.
Learning Deep Multimodal Feature Representation with Asymmetric Multi-layer Fusion
Aug 11, 2021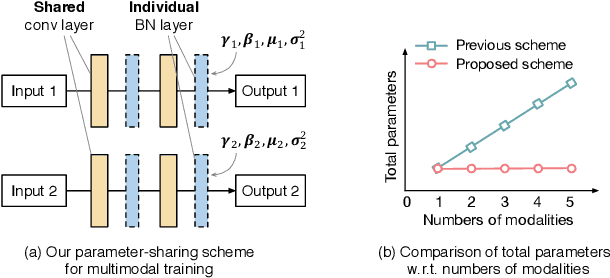
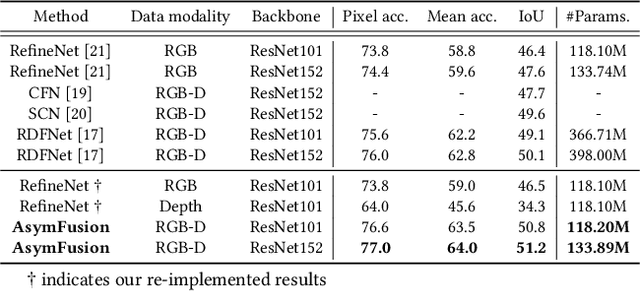
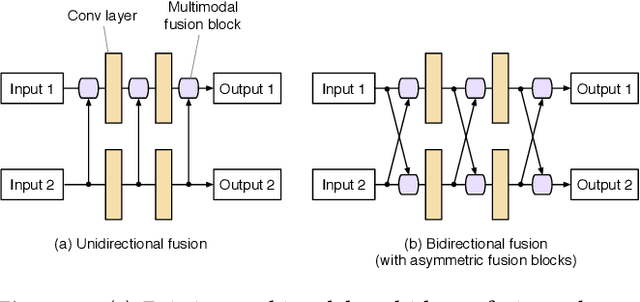
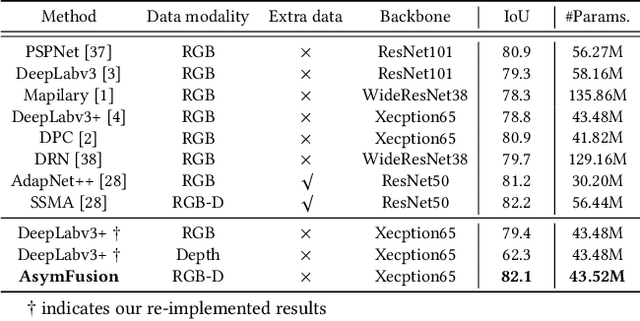
We propose a compact and effective framework to fuse multimodal features at multiple layers in a single network. The framework consists of two innovative fusion schemes. Firstly, unlike existing multimodal methods that necessitate individual encoders for different modalities, we verify that multimodal features can be learnt within a shared single network by merely maintaining modality-specific batch normalization layers in the encoder, which also enables implicit fusion via joint feature representation learning. Secondly, we propose a bidirectional multi-layer fusion scheme, where multimodal features can be exploited progressively. To take advantage of such scheme, we introduce two asymmetric fusion operations including channel shuffle and pixel shift, which learn different fused features with respect to different fusion directions. These two operations are parameter-free and strengthen the multimodal feature interactions across channels as well as enhance the spatial feature discrimination within channels. We conduct extensive experiments on semantic segmentation and image translation tasks, based on three publicly available datasets covering diverse modalities. Results indicate that our proposed framework is general, compact and is superior to state-of-the-art fusion frameworks.
Multi-Task Self-Training for Learning General Representations
Aug 25, 2021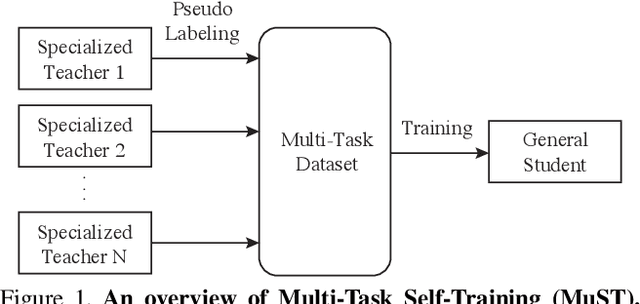
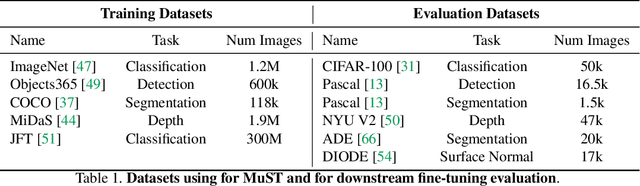

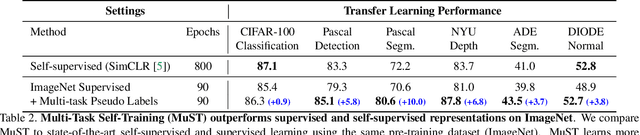
Despite the fast progress in training specialized models for various tasks, learning a single general model that works well for many tasks is still challenging for computer vision. Here we introduce multi-task self-training (MuST), which harnesses the knowledge in independent specialized teacher models (e.g., ImageNet model on classification) to train a single general student model. Our approach has three steps. First, we train specialized teachers independently on labeled datasets. We then use the specialized teachers to label an unlabeled dataset to create a multi-task pseudo labeled dataset. Finally, the dataset, which now contains pseudo labels from teacher models trained on different datasets/tasks, is then used to train a student model with multi-task learning. We evaluate the feature representations of the student model on 6 vision tasks including image recognition (classification, detection, segmentation)and 3D geometry estimation (depth and surface normal estimation). MuST is scalable with unlabeled or partially labeled datasets and outperforms both specialized supervised models and self-supervised models when training on large scale datasets. Lastly, we show MuST can improve upon already strong checkpoints trained with billions of examples. The results suggest self-training is a promising direction to aggregate labeled and unlabeled training data for learning general feature representations.
Black-Box Attacks on Sequential Recommenders via Data-Free Model Extraction
Sep 01, 2021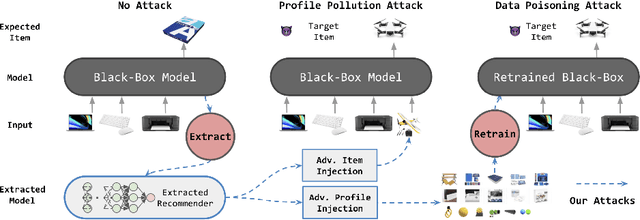

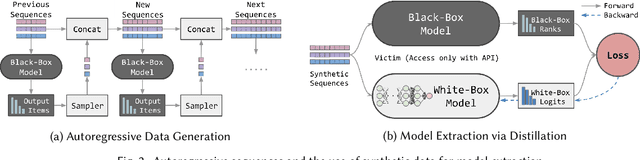
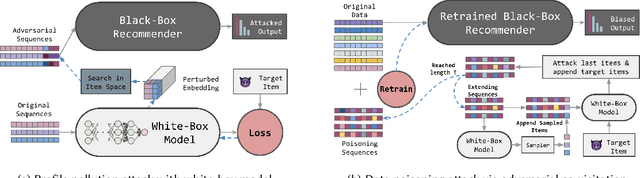
We investigate whether model extraction can be used to "steal" the weights of sequential recommender systems, and the potential threats posed to victims of such attacks. This type of risk has attracted attention in image and text classification, but to our knowledge not in recommender systems. We argue that sequential recommender systems are subject to unique vulnerabilities due to the specific autoregressive regimes used to train them. Unlike many existing recommender attackers, which assume the dataset used to train the victim model is exposed to attackers, we consider a data-free setting, where training data are not accessible. Under this setting, we propose an API-based model extraction method via limited-budget synthetic data generation and knowledge distillation. We investigate state-of-the-art models for sequential recommendation and show their vulnerability under model extraction and downstream attacks. We perform attacks in two stages. (1) Model extraction: given different types of synthetic data and their labels retrieved from a black-box recommender, we extract the black-box model to a white-box model via distillation. (2) Downstream attacks: we attack the black-box model with adversarial samples generated by the white-box recommender. Experiments show the effectiveness of our data-free model extraction and downstream attacks on sequential recommenders in both profile pollution and data poisoning settings.
Network-Agnostic Knowledge Transfer for Medical Image Segmentation
Jan 23, 2021
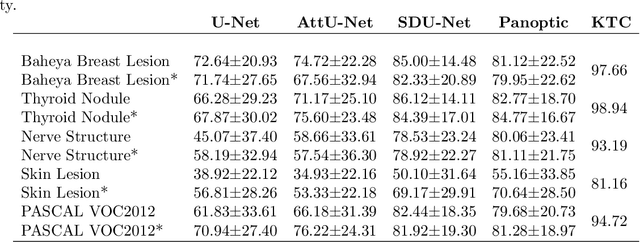
Conventional transfer learning leverages weights of pre-trained networks, but mandates the need for similar neural architectures. Alternatively, knowledge distillation can transfer knowledge between heterogeneous networks but often requires access to the original training data or additional generative networks. Knowledge transfer between networks can be improved by being agnostic to the choice of network architecture and reducing the dependence on original training data. We propose a knowledge transfer approach from a teacher to a student network wherein we train the student on an independent transferal dataset, whose annotations are generated by the teacher. Experiments were conducted on five state-of-the-art networks for semantic segmentation and seven datasets across three imaging modalities. We studied knowledge transfer from a single teacher, combination of knowledge transfer and fine-tuning, and knowledge transfer from multiple teachers. The student model with a single teacher achieved similar performance as the teacher; and the student model with multiple teachers achieved better performance than the teachers. The salient features of our algorithm include: 1)no need for original training data or generative networks, 2) knowledge transfer between different architectures, 3) ease of implementation for downstream tasks by using the downstream task dataset as the transferal dataset, 4) knowledge transfer of an ensemble of models, trained independently, into one student model. Extensive experiments demonstrate that the proposed algorithm is effective for knowledge transfer and easily tunable.
Robustifying deep networks for image segmentation
Aug 01, 2019Purpose: The purpose of this study is to investigate the robustness of a commonly-used convolutional neural network for image segmentation with respect to visually-subtle adversarial perturbations, and suggest new methods to make these networks more robust to such perturbations. Materials and Methods: In this retrospective study, the accuracy of brain tumor segmentation was studied in subjects with low- and high-grade gliomas. A three-dimensional UNet model was implemented to segment four different MR series (T1-weighted, post-contrast T1-weighted, T2- weighted, and T2-weighted FLAIR) into four pixelwise labels (Gd-enhancing tumor, peritumoral edema, necrotic and non-enhancing tumor, and background). We developed attack strategies based on the Fast Gradient Sign Method (FGSM), iterative FGSM (i-FGSM), and targeted iterative FGSM (ti-FGSM) to produce effective attacks. Additionally, we explored the effectiveness of distillation and adversarial training via data augmentation to counteract adversarial attacks. Robustness was measured by comparing the Dice coefficient for each attack method using Wilcoxon signed-rank tests. Results: Attacks based on FGSM, i-FGSM, and ti-FGSM were effective in significantly reducing the quality of image segmentation with reductions in Dice coefficient by up to 65%. For attack defenses, distillation performed significantly better than adversarial training approaches. However, all defense approaches performed worse compared to unperturbed test images. Conclusion: Segmentation networks can be adversely affected by targeted attacks that introduce visually minor (and potentially undetectable) modifications to existing images. With an increasing interest in applying deep learning techniques to medical imaging data, it is important to quantify the ramifications of adversarial inputs (either intentional or unintentional).
An End-to-End Network for Co-Saliency Detection in One Single Image
Oct 25, 2019

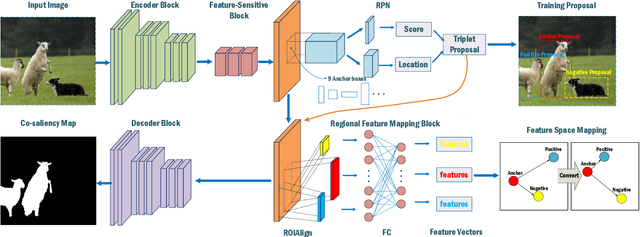
As a common visual problem, co-saliency detection within a single image does not attract enough attention and yet has not been well addressed. Existing methods often follow a bottom-up strategy to infer co-saliency in an image, where salient regions are firstly detected using visual primitives such as color and shape, and then grouped and merged into a co-saliency map. However, co-saliency is intrinsically perceived in a complex manner with bottom-up and top-down strategies combined in human vision. To deal with this problem, a novel end-to-end trainable network is proposed in this paper, which includes a backbone net and two branch nets. The backbone net uses ground-truth masks as top-down guidance for saliency prediction, while the two branch nets construct triplet proposals for feature organization and clustering, which drives the network to be sensitive to co-salient regions in a bottom-up way. To evaluate the proposed method, we construct a new dataset of 2,019 nature images with co-saliency in each image. Experimental results show that the proposed method achieves a state-of-the-art accuracy with a running speed of 28fps.
Micro CT Image-Assisted Cross Modality Super-Resolution of Clinical CT Images Utilizing Synthesized Training Dataset
Oct 20, 2020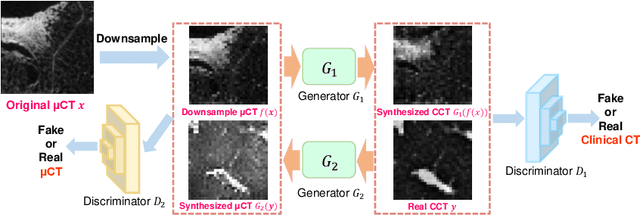
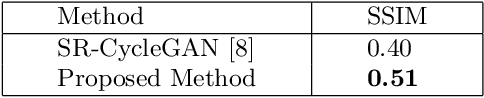
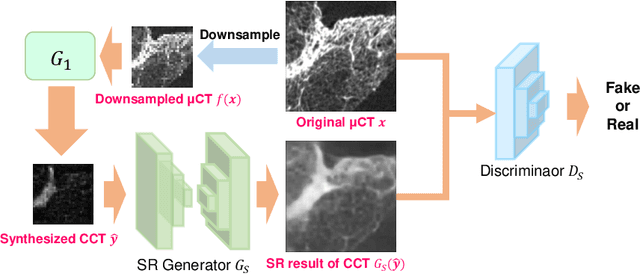

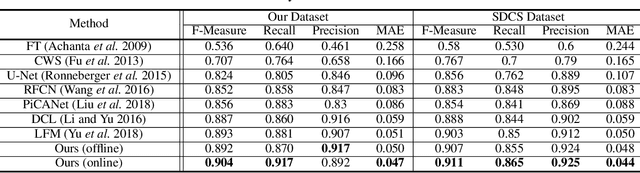
This paper proposes a novel, unsupervised super-resolution (SR) approach for performing the SR of a clinical CT into the resolution level of a micro CT ($\mu$CT). The precise non-invasive diagnosis of lung cancer typically utilizes clinical CT data. Due to the resolution limitations of clinical CT (about $0.5 \times 0.5 \times 0.5$ mm$^3$), it is difficult to obtain enough pathological information such as the invasion area at alveoli level. On the other hand, $\mu$CT scanning allows the acquisition of volumes of lung specimens with much higher resolution ($50 \times 50 \times 50 \mu {\rm m}^3$ or higher). Thus, super-resolution of clinical CT volume may be helpful for diagnosis of lung cancer. Typical SR methods require aligned pairs of low-resolution (LR) and high-resolution (HR) images for training. Unfortunately, obtaining paired clinical CT and $\mu$CT volumes of human lung tissues is infeasible. Unsupervised SR methods are required that do not need paired LR and HR images. In this paper, we create corresponding clinical CT-$\mu$CT pairs by simulating clinical CT images from $\mu$CT images by modified CycleGAN. After this, we use simulated clinical CT-$\mu$CT image pairs to train an SR network based on SRGAN. Finally, we use the trained SR network to perform SR of the clinical CT images. We compare our proposed method with another unsupervised SR method for clinical CT images named SR-CycleGAN. Experimental results demonstrate that the proposed method can successfully perform SR of clinical CT images of lung cancer patients with $\mu$CT level resolution, and quantitatively and qualitatively outperformed conventional method (SR-CycleGAN), improving the SSIM (structure similarity) form 0.40 to 0.51.
Multiview and Multiclass Image Segmentation using Deep Learning in Fetal Echocardiography
Mar 23, 2021Congenital heart disease (CHD) is the most common congenital abnormality associated with birth defects in the United States. Despite training efforts and substantial advancement in ultrasound technology over the past years, CHD remains an abnormality that is frequently missed during prenatal ultrasonography. Therefore, computer-aided detection of CHD can play a critical role in prenatal care by improving screening and diagnosis. Since many CHDs involve structural abnormalities, automatic segmentation of anatomical structures is an important step in the analysis of fetal echocardiograms. While existing methods mainly focus on the four-chamber view with a small number of structures, here we present a more comprehensive deep learning segmentation framework covering 14 anatomical structures in both three-vessel trachea and four-chamber views. Specifically, our framework enhances the V-Net with spatial dropout, group normalization, and deep supervision to train a segmentation model that can be applied on both views regardless of abnormalities. By identifying the pitfall of using the Dice loss when some labels are unavailable in some images, this framework integrates information from multiple views and is robust to missing structures due to anatomical anomalies, achieving an average Dice score of 79%.
Densely connected neural networks for nonlinear regression
Jul 29, 2021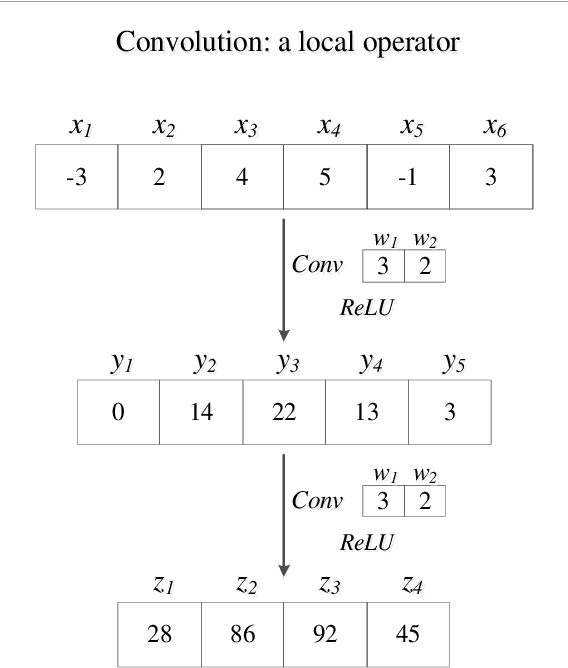
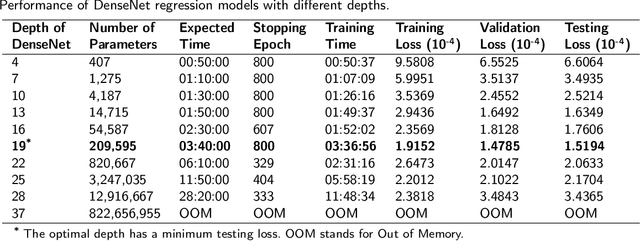
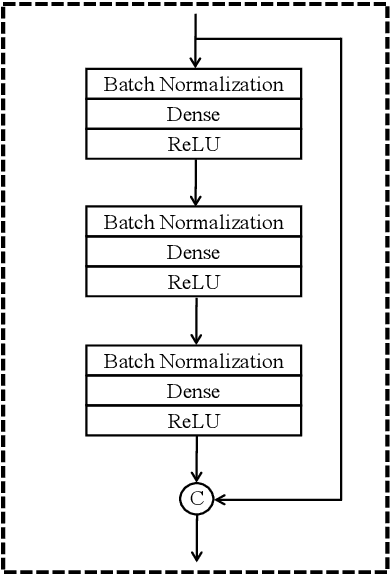
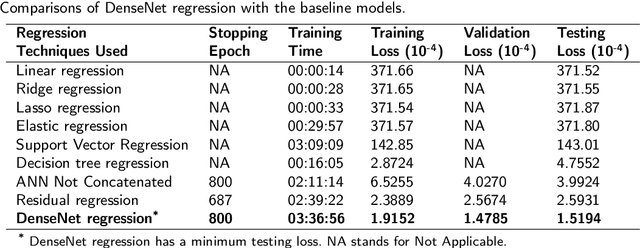
Densely connected convolutional networks (DenseNet) behave well in image processing. However, for regression tasks, convolutional DenseNet may lose essential information from independent input features. To tackle this issue, we propose a novel DenseNet regression model where convolution and pooling layers are replaced by fully connected layers and the original concatenation shortcuts are maintained to reuse the feature. To investigate the effects of depth and input dimension of proposed model, careful validations are performed by extensive numerical simulation. The results give an optimal depth (19) and recommend a limited input dimension (under 200). Furthermore, compared with the baseline models including support vector regression, decision tree regression, and residual regression, our proposed model with the optimal depth performs best. Ultimately, DenseNet regression is applied to predict relative humidity, and the outcome shows a high correlation (0.91) with observations, which indicates that our model could advance environmental data analysis.