 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Dimensional Statistics: Reflections on Progress and Open Problems
May 06, 2026Over the past two decades, the field of high-dimensional statistics has experienced substantial progress, driven largely by technological advances that have dramatically reduced the cost and effort for data collection and storage across a broad range of domains, including biology, medicine, astronomy, and the social and environmental sciences. Modern datasets are increasingly complex, often exhibiting rich dependency, heterogeneity, and other features that challenge traditional statistical methods. In response, high-dimensional statistics has evolved to address more sophisticated estimation and inference problems. This evolution has, in turn, fostered deep connections with and contributions to a wide range of research areas, including optimization, concentration of measure, random matrix theory, information theory, and theoretical computer science. Given the rapid pace of recent developments in high-dimensional statistics, our goal is to synthesize representative advances, highlight common themes and open problems, and point to important works that offer entry points into the field.
On Differentially Private U Statistics
Jul 06, 2024


We consider the problem of privately estimating a parameter $\mathbb{E}[h(X_1,\dots,X_k)]$, where $X_1$, $X_2$, $\dots$, $X_k$ are i.i.d. data from some distribution and $h$ is a permutation-invariant function. Without privacy constraints, standard estimators are U-statistics, which commonly arise in a wide range of problems, including nonparametric signed rank tests, symmetry testing, uniformity testing, and subgraph counts in random networks, and can be shown to be minimum variance unbiased estimators under mild conditions. Despite the recent outpouring of interest in private mean estimation, privatizing U-statistics has received little attention. While existing private mean estimation algorithms can be applied to obtain confidence intervals, we show that they can lead to suboptimal private error, e.g., constant-factor inflation in the leading term, or even $\Theta(1/n)$ rather than $O(1/n^2)$ in degenerate settings. To remedy this, we propose a new thresholding-based approach using \emph{local H\'ajek projections} to reweight different subsets of the data. This leads to nearly optimal private error for non-degenerate U-statistics and a strong indication of near-optimality for degenerate U-statistics.
Differentially Private Synthetic Data with Private Density Estimation
May 06, 2024


The need to analyze sensitive data, such as medical records or financial data, has created a critical research challenge in recent years. In this paper, we adopt the framework of differential privacy, and explore mechanisms for generating an entire dataset which accurately captures characteristics of the original data. We build upon the work of Boedihardjo et al, which laid the foundations for a new optimization-based algorithm for generating private synthetic data. Importantly, we adapt their algorithm by replacing a uniform sampling step with a private distribution estimator; this allows us to obtain better computational guarantees for discrete distributions, and develop a novel algorithm suitable for continuous distributions. We also explore applications of our work to several statistical tasks.
The Sample Complexity of Simple Binary Hypothesis Testing
Mar 25, 2024The sample complexity of simple binary hypothesis testing is the smallest number of i.i.d. samples required to distinguish between two distributions $p$ and $q$ in either: (i) the prior-free setting, with type-I error at most $\alpha$ and type-II error at most $\beta$; or (ii) the Bayesian setting, with Bayes error at most $\delta$ and prior distribution $(\alpha, 1-\alpha)$. This problem has only been studied when $\alpha = \beta$ (prior-free) or $\alpha = 1/2$ (Bayesian), and the sample complexity is known to be characterized by the Hellinger divergence between $p$ and $q$, up to multiplicative constants. In this paper, we derive a formula that characterizes the sample complexity (up to multiplicative constants that are independent of $p$, $q$, and all error parameters) for: (i) all $0 \le \alpha, \beta \le 1/8$ in the prior-free setting; and (ii) all $\delta \le \alpha/4$ in the Bayesian setting. In particular, the formula admits equivalent expressions in terms of certain divergences from the Jensen--Shannon and Hellinger families. The main technical result concerns an $f$-divergence inequality between members of the Jensen--Shannon and Hellinger families, which is proved by a combination of information-theoretic tools and case-by-case analyses. We explore applications of our results to robust and distributed (locally-private and communication-constrained) hypothesis testing.
Robust empirical risk minimization via Newton's method
Jan 30, 2023



We study a variant of Newton's method for empirical risk minimization, where at each iteration of the optimization algorithm, we replace the gradient and Hessian of the objective function by robust estimators taken from existing literature on robust mean estimation for multivariate data. After proving a general theorem about the convergence of successive iterates to a small ball around the population-level minimizer, we study consequences of our theory in generalized linear models, when data are generated from Huber's epsilon-contamination model and/or heavy-tailed distributions. We also propose an algorithm for obtaining robust Newton directions based on the conjugate gradient method, which may be more appropriate for high-dimensional settings, and provide conjectures about the convergence of the resulting algorithm. Compared to the robust gradient descent algorithm proposed by Prasad et al. (2020), our algorithm enjoys the faster rates of convergence for successive iterates often achieved by second-order algorithms for convex problems, i.e., quadratic convergence in a neighborhood of the optimum, with a stepsize that may be chosen adaptively via backtracking linesearch.
Simple Binary Hypothesis Testing under Local Differential Privacy and Communication Constraints
Jan 09, 2023
We study simple binary hypothesis testing under both local differential privacy (LDP) and communication constraints. We qualify our results as either minimax optimal or instance optimal: the former hold for the set of distribution pairs with prescribed Hellinger divergence and total variation distance, whereas the latter hold for specific distribution pairs. For the sample complexity of simple hypothesis testing under pure LDP constraints, we establish instance-optimal bounds for distributions with binary support; minimax-optimal bounds for general distributions; and (approximately) instance-optimal, computationally efficient algorithms for general distributions. When both privacy and communication constraints are present, we develop instance-optimal, computationally efficient algorithms that achieve the minimum possible sample complexity (up to universal constants). Our results on instance-optimal algorithms hinge on identifying the extreme points of the joint range set $\mathcal A$ of two distributions $p$ and $q$, defined as $\mathcal A := \{(\mathbf T p, \mathbf T q) | \mathbf T \in \mathcal C\}$, where $\mathcal C$ is the set of channels characterizing the constraints.
Communication-constrained hypothesis testing: Optimality, robustness, and reverse data processing inequalities
Jun 06, 2022We study hypothesis testing under communication constraints, where each sample is quantized before being revealed to a statistician. Without communication constraints, it is well known that the sample complexity of simple binary hypothesis testing is characterized by the Hellinger distance between the distributions. We show that the sample complexity of simple binary hypothesis testing under communication constraints is at most a logarithmic factor larger than in the unconstrained setting and this bound is tight. We develop a polynomial-time algorithm that achieves the aforementioned sample complexity. Our framework extends to robust hypothesis testing, where the distributions are corrupted in the total variation distance. Our proofs rely on a new reverse data processing inequality and a reverse Markov inequality, which may be of independent interest. For simple $M$-ary hypothesis testing, the sample complexity in the absence of communication constraints has a logarithmic dependence on $M$. We show that communication constraints can cause an exponential blow-up leading to $\Omega(M)$ sample complexity even for adaptive algorithms.
On the identifiability of mixtures of ranking models
Jan 31, 2022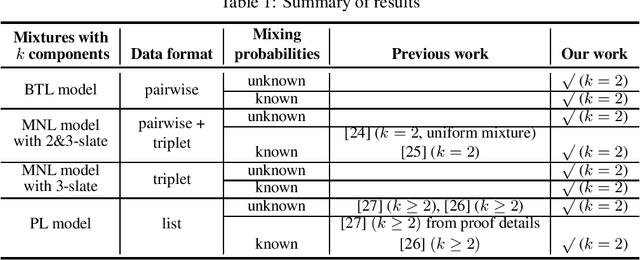
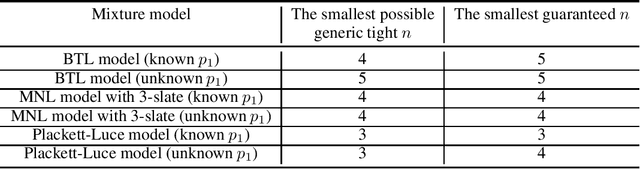
Mixtures of ranking models are standard tools for ranking problems. However, even the fundamental question of parameter identifiability is not fully understood: the identifiability of a mixture model with two Bradley-Terry-Luce (BTL) components has remained open. In this work, we show that popular mixtures of ranking models with two components (Plackett-Luce, multinomial logistic model with slates of size 3, or BTL) are generically identifiable, i.e., the ground-truth parameters can be identified except when they are from a pathological subset of measure zero. We provide a framework for verifying the number of solutions in a general family of polynomial systems using algebraic geometry, and apply it to these mixtures of ranking models. The framework can be applied more broadly to other learning models and may be of independent interest.
Differentially private inference via noisy optimization
Mar 19, 2021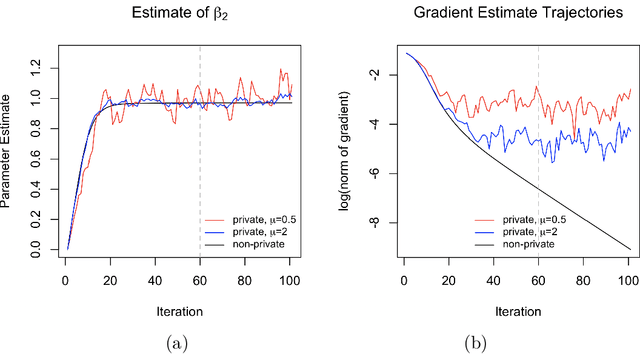
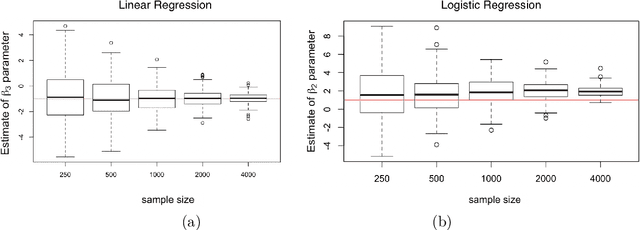
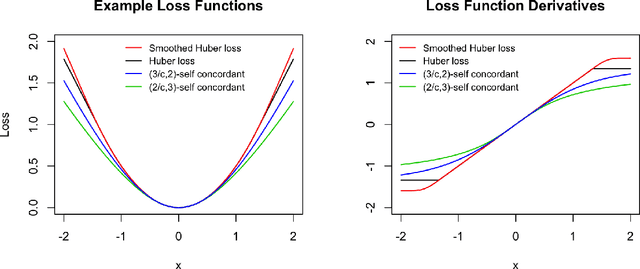
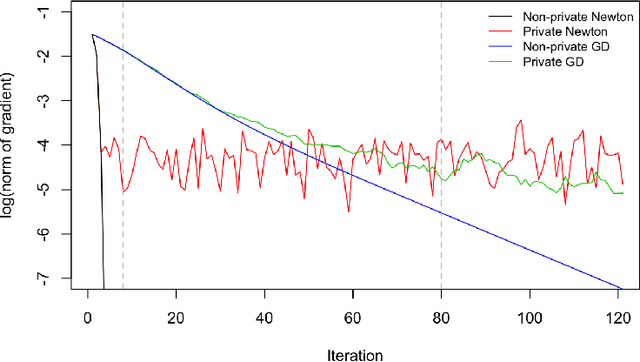
We propose a general optimization-based framework for computing differentially private M-estimators and a new method for constructing differentially private confidence regions. Firstly, we show that robust statistics can be used in conjunction with noisy gradient descent or noisy Newton methods in order to obtain optimal private estimators with global linear or quadratic convergence, respectively. We establish local and global convergence guarantees, under both local strong convexity and self-concordance, showing that our private estimators converge with high probability to a nearly optimal neighborhood of the non-private M-estimators. Secondly, we tackle the problem of parametric inference by constructing differentially private estimators of the asymptotic variance of our private M-estimators. This naturally leads to approximate pivotal statistics for constructing confidence regions and conducting hypothesis testing. We demonstrate the effectiveness of a bias correction that leads to enhanced small-sample empirical performance in simulations. We illustrate the benefits of our methods in several numerical examples.
Robust W-GAN-Based Estimation Under Wasserstein Contamination
Jan 20, 2021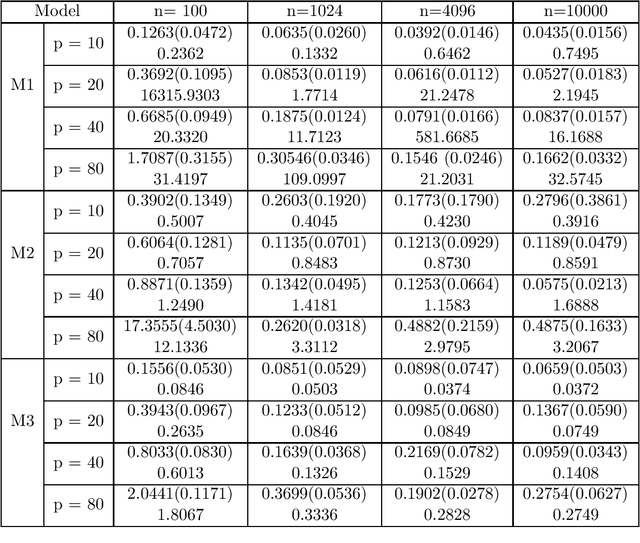
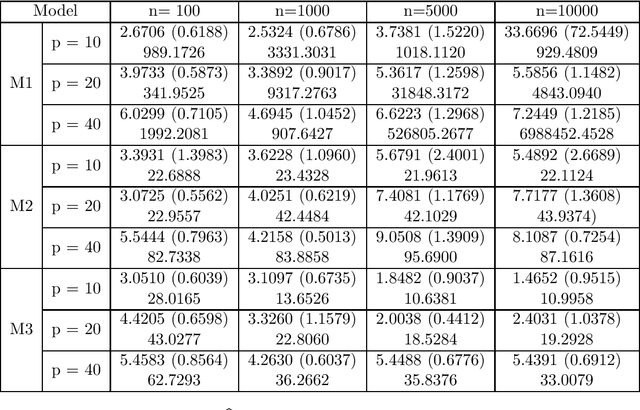
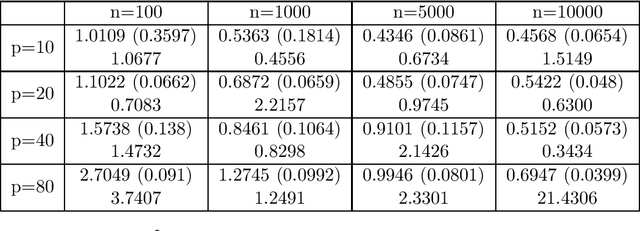
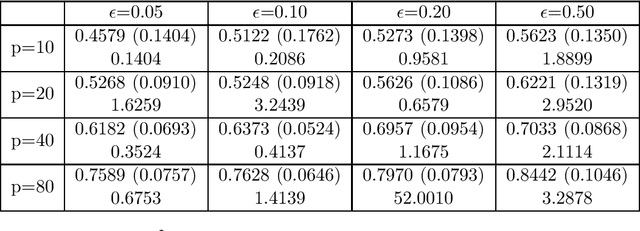
Robust estimation is an important problem in statistics which aims at providing a reasonable estimator when the data-generating distribution lies within an appropriately defined ball around an uncontaminated distribution. Although minimax rates of estimation have been established in recent years, many existing robust estimators with provably optimal convergence rates are also computationally intractable. In this paper, we study several estimation problems under a Wasserstein contamination model and present computationally tractable estimators motivated by generative adversarial networks (GANs). Specifically, we analyze properties of Wasserstein GAN-based estimators for location estimation, covariance matrix estimation, and linear regression and show that our proposed estimators are minimax optimal in many scenarios. Finally, we present numerical results which demonstrate the effectiveness of our estimators.