 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Neural Multi-scale Image Compression
May 16, 2018




This study presents a new lossy image compression method that utilizes the multi-scale features of natural images. Our model consists of two networks: multi-scale lossy autoencoder and parallel multi-scale lossless coder. The multi-scale lossy autoencoder extracts the multi-scale image features to quantized variables and the parallel multi-scale lossless coder enables rapid and accurate lossless coding of the quantized variables via encoding/decoding the variables in parallel. Our proposed model achieves comparable performance to the state-of-the-art model on Kodak and RAISE-1k dataset images, and it encodes a PNG image of size $768 \times 512$ in 70 ms with a single GPU and a single CPU process and decodes it into a high-fidelity image in approximately 200 ms.
Align2Ground: Weakly Supervised Phrase Grounding Guided by Image-Caption Alignment
Mar 27, 2019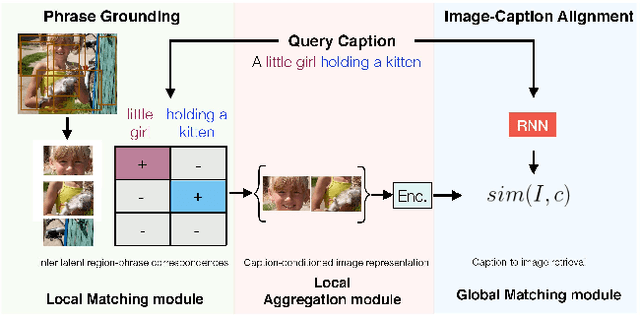
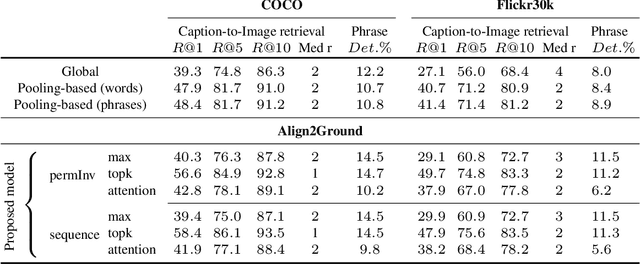

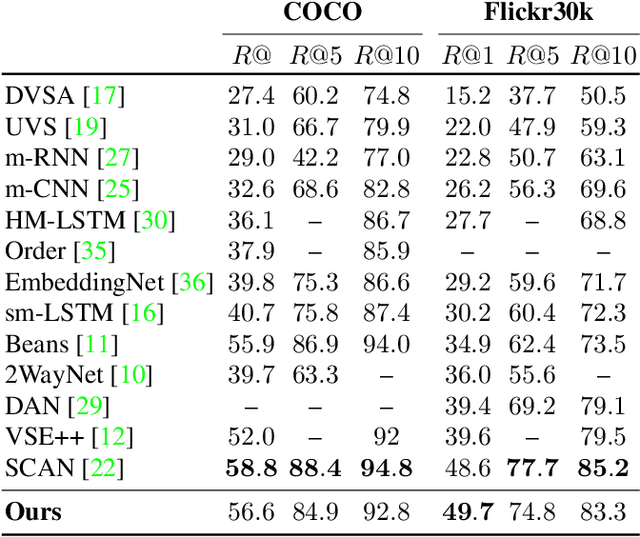
We address the problem of grounding free-form textual phrases by using weak supervision from image-caption pairs. We propose a novel end-to-end model that uses caption-to-image retrieval as a `downstream' task to guide the process of phrase localization. Our method, as a first step, infers the latent correspondences between regions-of-interest (RoIs) and phrases in the caption and creates a discriminative image representation using these matched RoIs. In a subsequent step, this (learned) representation is aligned with the caption. Our key contribution lies in building this `caption-conditioned' image encoding which tightly couples both the tasks and allows the weak supervision to effectively guide visual grounding. We provide an extensive empirical and qualitative analysis to investigate the different components of our proposed model and compare it with competitive baselines. For phrase localization, we report an improvement of 4.9% (absolute) over the prior state-of-the-art on the VisualGenome dataset. We also report results that are at par with the state-of-the-art on the downstream caption-to-image retrieval task on COCO and Flickr30k datasets.
Design of a Graphical User Interface for Few-Shot Machine Learning Classification of Electron Microscopy Data
Jul 21, 2021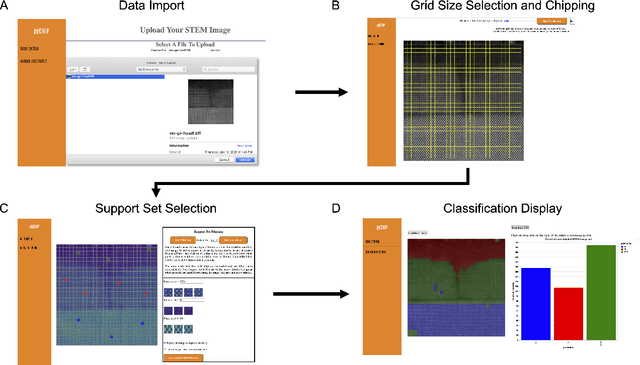
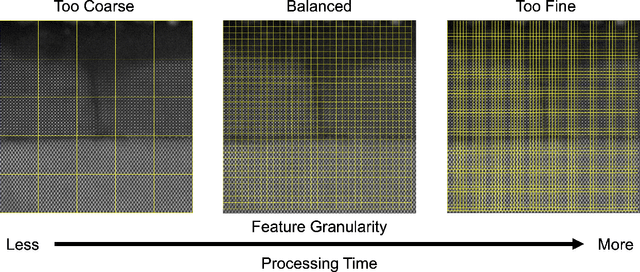

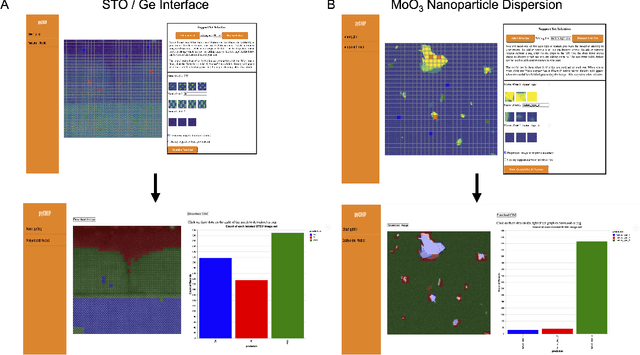
The recent growth in data volumes produced by modern electron microscopes requires rapid, scalable, and flexible approaches to image segmentation and analysis. Few-shot machine learning, which can richly classify images from a handful of user-provided examples, is a promising route to high-throughput analysis. However, current command-line implementations of such approaches can be slow and unintuitive to use, lacking the real-time feedback necessary to perform effective classification. Here we report on the development of a Python-based graphical user interface that enables end users to easily conduct and visualize the output of few-shot learning models. This interface is lightweight and can be hosted locally or on the web, providing the opportunity to reproducibly conduct, share, and crowd-source few-shot analyses.
An Integrated Framework for the Heterogeneous Spatio-Spectral-Temporal Fusion of Remote Sensing Images
Sep 01, 2021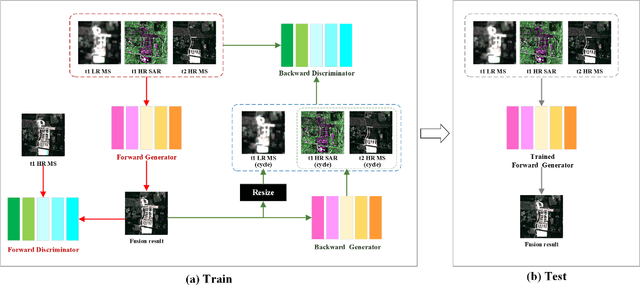
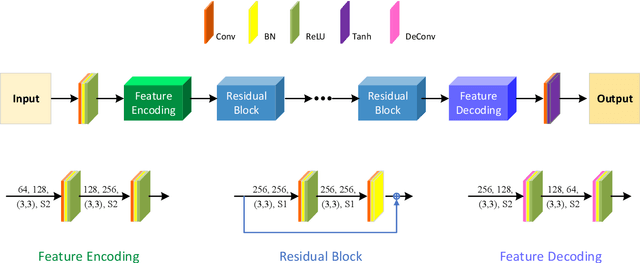
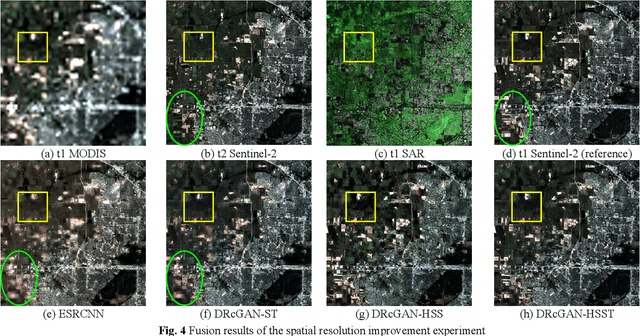
Image fusion technology is widely used to fuse the complementary information between multi-source remote sensing images. Inspired by the frontier of deep learning, this paper first proposes a heterogeneous-integrated framework based on a novel deep residual cycle GAN. The proposed network consists of a forward fusion part and a backward degeneration feedback part. The forward part generates the desired fusion result from the various observations; the backward degeneration feedback part considers the imaging degradation process and regenerates the observations inversely from the fusion result. The proposed network can effectively fuse not only the homogeneous but also the heterogeneous information. In addition, for the first time, a heterogeneous-integrated fusion framework is proposed to simultaneously merge the complementary heterogeneous spatial, spectral and temporal information of multi-source heterogeneous observations. The proposed heterogeneous-integrated framework also provides a uniform mode that can complete various fusion tasks, including heterogeneous spatio-spectral fusion, spatio-temporal fusion, and heterogeneous spatio-spectral-temporal fusion. Experiments are conducted for two challenging scenarios of land cover changes and thick cloud coverage. Images from many remote sensing satellites, including MODIS, Landsat-8, Sentinel-1, and Sentinel-2, are utilized in the experiments. Both qualitative and quantitative evaluations confirm the effectiveness of the proposed method.
Describing like humans: on diversity in image captioning
Apr 01, 2019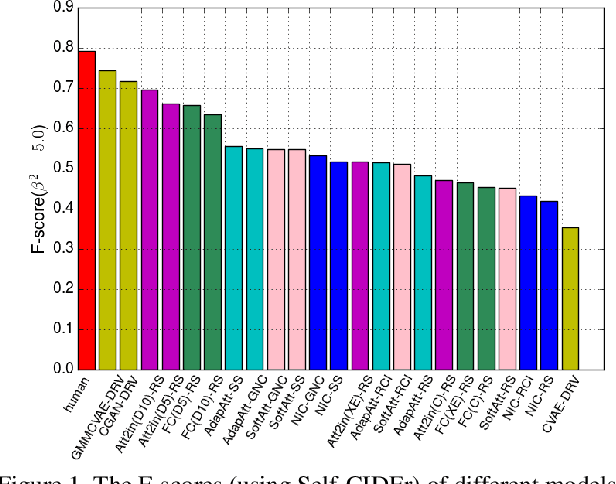
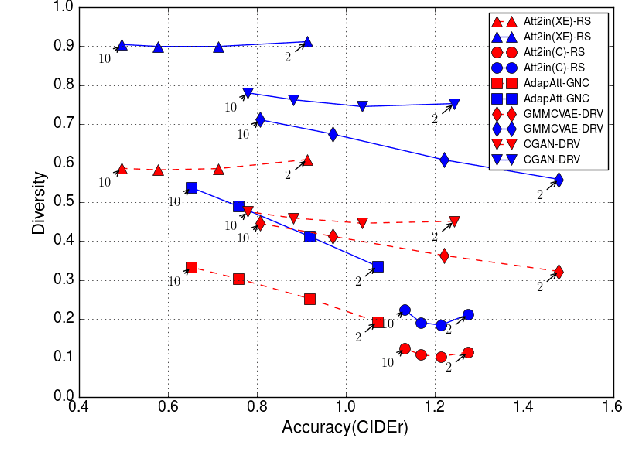
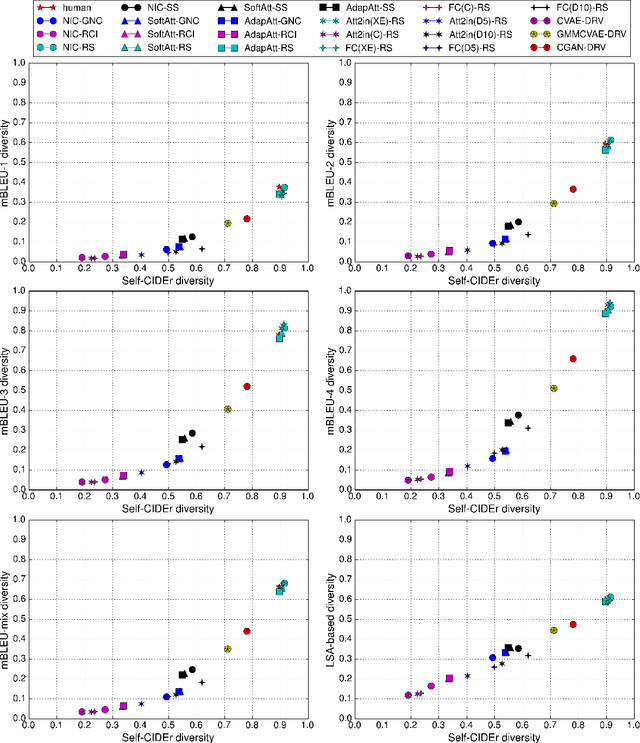
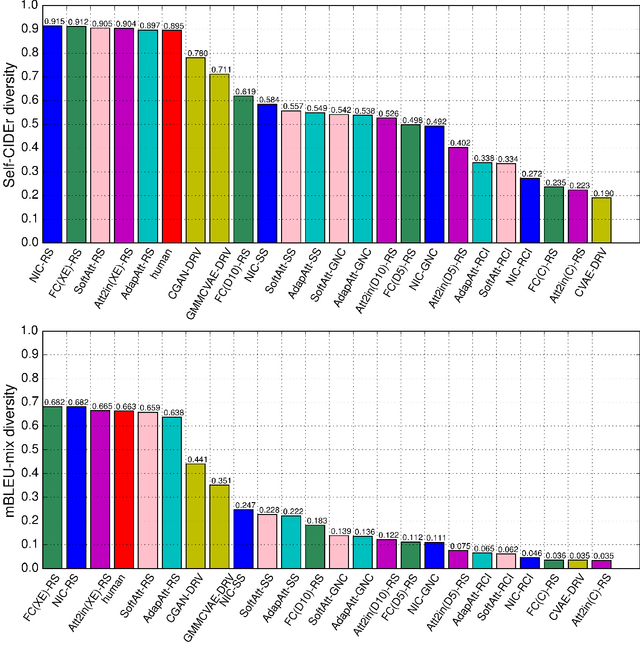
Recently, the state-of-the-art models for image captioning have overtaken human performance based on the most popular metrics, such as BLEU, METEOR, ROUGE, and CIDEr. Does this mean we have solved the task of image captioning? The above metrics only measure the similarity of the generated caption to the human annotations, which reflects its accuracy. However, an image contains many concepts and multiple levels of detail, and thus there is a variety of captions that express different concepts and details that might be interesting for different humans. Therefore only evaluating accuracy is not sufficient for measuring the performance of captioning models --- the diversity of the generated captions should also be considered. In this paper, we proposed a new metric for measuring the diversity of image captions, which is derived from latent semantic analysis and kernelized to use CIDEr similarity. We conduct extensive experiments to re-evaluate recent captioning models in the context of both diversity and accuracy. We find that there is still a large gap between the model and human performance in terms of both accuracy and diversity and the models that have optimized accuracy (CIDEr) have low diversity. We also show that balancing the cross-entropy loss and CIDEr reward in reinforcement learning during training can effectively control the tradeoff between diversity and accuracy of the generated captions.
Deep few-shot learning for bi-temporal building change detection
Aug 25, 2021
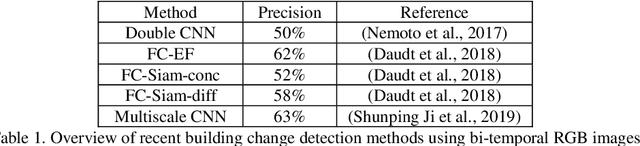
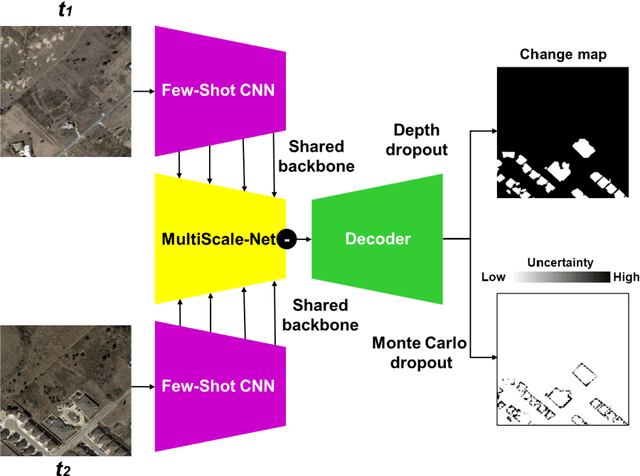
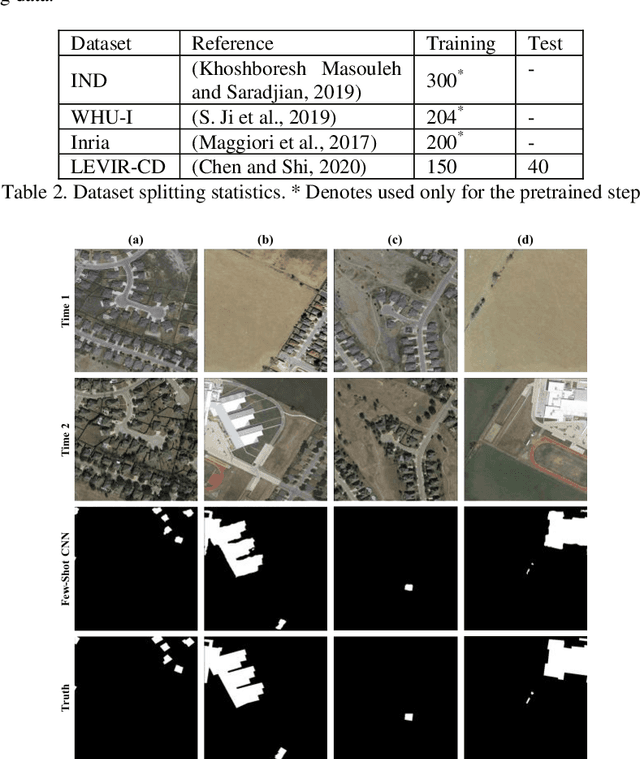
In real-world applications (e.g., change detection), annotating images is very expensive. To build effective deep learning models in these applications, deep few-shot learning methods have been developed and prove to be a robust approach in small training data. The analysis of building change detection from high spatial resolution remote sensing observations is important research in photogrammetry, computer vision, and remote sensing nowadays, which can be widely used in a variety of real-world applications, such as map updating. As manual high resolution image interpretation is expensive and time-consuming, building change detection methods are of high interest. The interest in developing building change detection approaches from optical remote sensing images is rapidly increasing due to larger coverages, and lower costs of optical images. In this study, we focus on building change detection analysis on a small set of building change from different regions that sit in several cities. In this paper, a new deep few-shot learning method is proposed for building change detection using Monte Carlo dropout and remote sensing observations. The setup is based on a small dataset, including bitemporal optical images labeled for building change detection.
* 5 pages, 3 figures
InverseRenderNet: Learning single image inverse rendering
Nov 29, 2018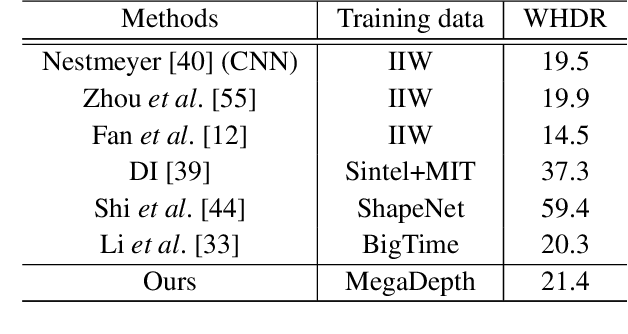
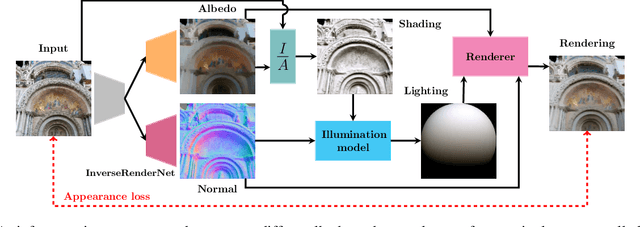
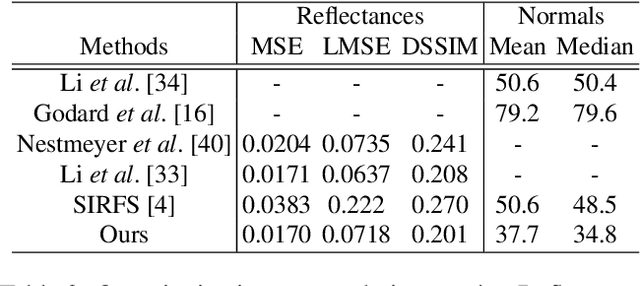
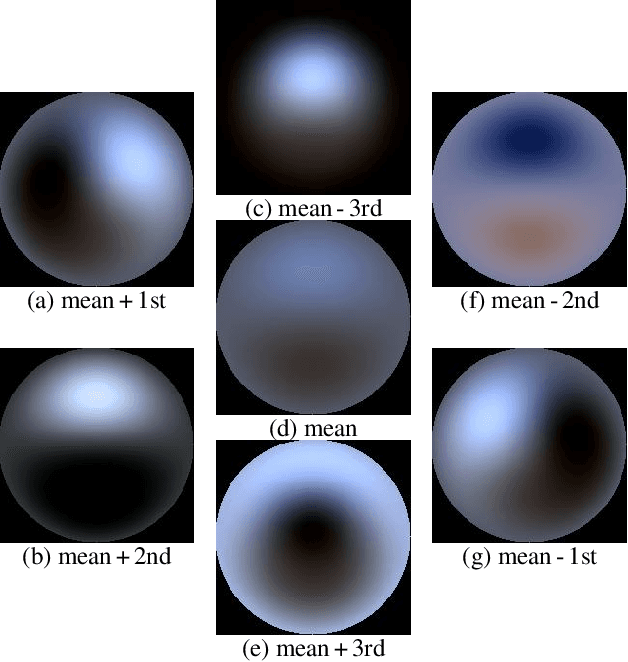
We show how to train a fully convolutional neural network to perform inverse rendering from a single, uncontrolled image. The network takes an RGB image as input, regresses albedo and normal maps from which we compute lighting coefficients. Our network is trained using large uncontrolled image collections without ground truth. By incorporating a differentiable renderer, our network can learn from self-supervision. Since the problem is ill-posed we introduce additional supervision: 1. We learn a statistical natural illumination prior, 2. Our key insight is to perform offline multiview stereo (MVS) on images containing rich illumination variation. From the MVS pose and depth maps, we can cross project between overlapping views such that Siamese training can be used to ensure consistent estimation of photometric invariants. MVS depth also provides direct coarse supervision for normal map estimation. We believe this is the first attempt to use MVS supervision for learning inverse rendering.
Single Image Reflection Removal with Physically-based Rendering
Apr 26, 2019

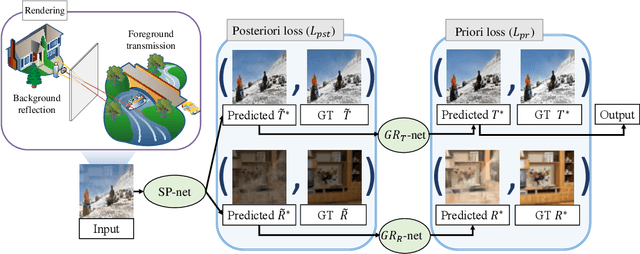
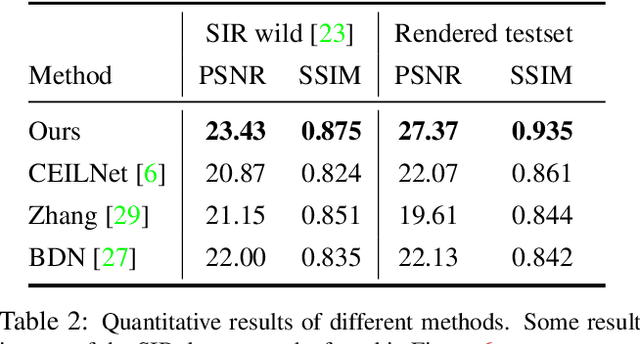
Recently, deep learning based single image reflection separation methods have been exploited widely. To benefit the learning approach, a large number of training image pairs (i.e., with and without reflections) were synthesized in various ways, yet they are away from a physically-based direction. In this paper, physically based rendering is used for faithfully synthesizing the required training images, and corresponding network structure is proposed. We utilize existing image data to estimate mesh, then physically simulate the depth-dependent light transportation between mesh, glass, and lens with path tracing. For guiding the separation better, we additionally consider a module of removing complicated ghosting and blurring glass-effects, which allows obtaining priori information before having the glass distortion. This module is easily accommodated within our approach, since that prior information can be physically generated by our rendering process. The proposed method considering the priori information as well as the existing posterior information is validated with various real reflection images, and is demonstrated to show visually pleasant and numerically better results compared to the state-of-theart techniques.
NLH: A Blind Pixel-level Non-local Method for Real-world Image Denoising
Aug 04, 2019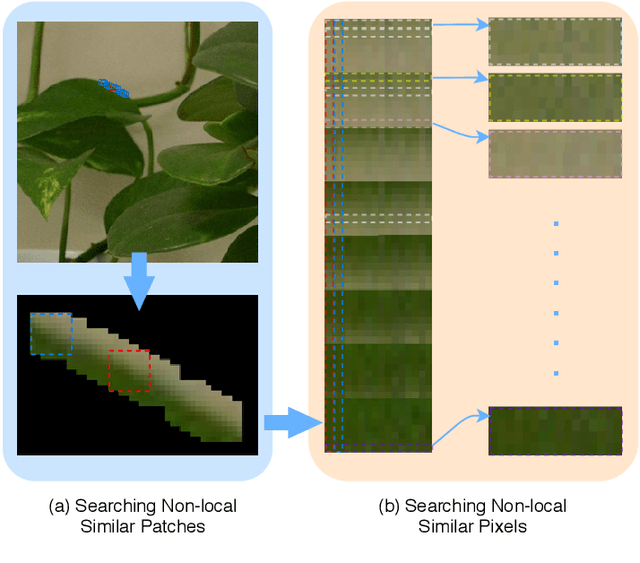
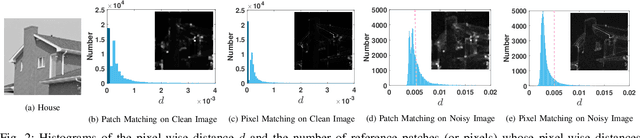
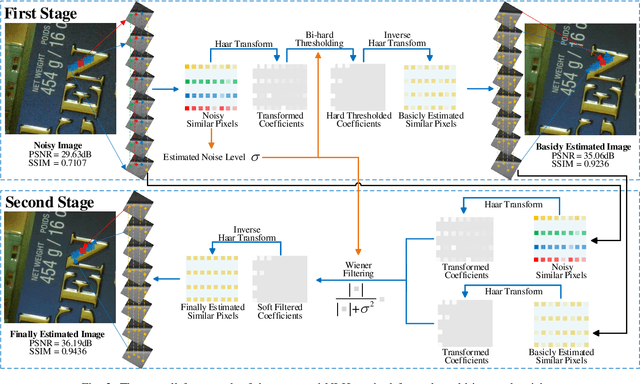

Non-local self similarity (NSS) is a powerful prior of natural images for image denoising. Most of existing denoising methods employ similar patches, which is a patch-level NSS prior. In this paper, we take one step forward by introducing a pixel-level NSS prior, i.e., searching similar pixels across a non-local region. This is motivated by the fact that finding closely similar pixels is more feasible than similar patches in natural images, which can be used to enhance image denoising performance. With the introduced pixel-level NSS prior, we propose an accurate noise level estimation method, and then develop a blind image denoising method based on the lifting Haar transform and Wiener filtering techniques. Experiments on benchmark datasets demonstrate that, the proposed method achieves much better performance than state-of-the-art methods on real-world image denoising. The code will be released.
XGAN: Unsupervised Image-to-Image Translation for Many-to-Many Mappings
Jul 10, 2018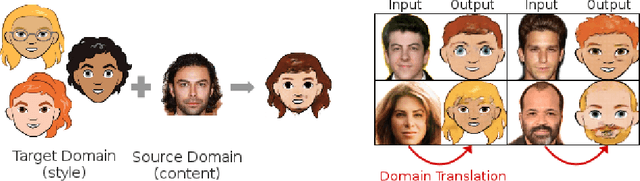

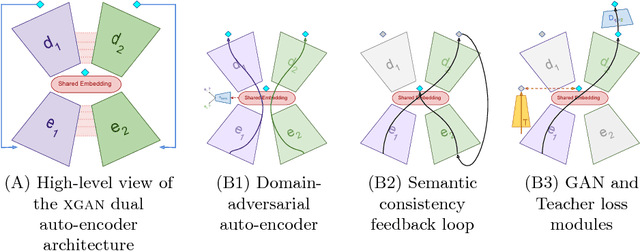

Style transfer usually refers to the task of applying color and texture information from a specific style image to a given content image while preserving the structure of the latter. Here we tackle the more generic problem of semantic style transfer: given two unpaired collections of images, we aim to learn a mapping between the corpus-level style of each collection, while preserving semantic content shared across the two domains. We introduce XGAN ("Cross-GAN"), a dual adversarial autoencoder, which captures a shared representation of the common domain semantic content in an unsupervised way, while jointly learning the domain-to-domain image translations in both directions. We exploit ideas from the domain adaptation literature and define a semantic consistency loss which encourages the model to preserve semantics in the learned embedding space. We report promising qualitative results for the task of face-to-cartoon translation. The cartoon dataset, CartoonSet, we collected for this purpose is publicly available at google.github.io/cartoonset/ as a new benchmark for semantic style transfer.