 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSA-NET.v2: Real-time vehicle detection from oblique UAV images with use of uncertainty estimation in deep meta-learning
Aug 04, 2022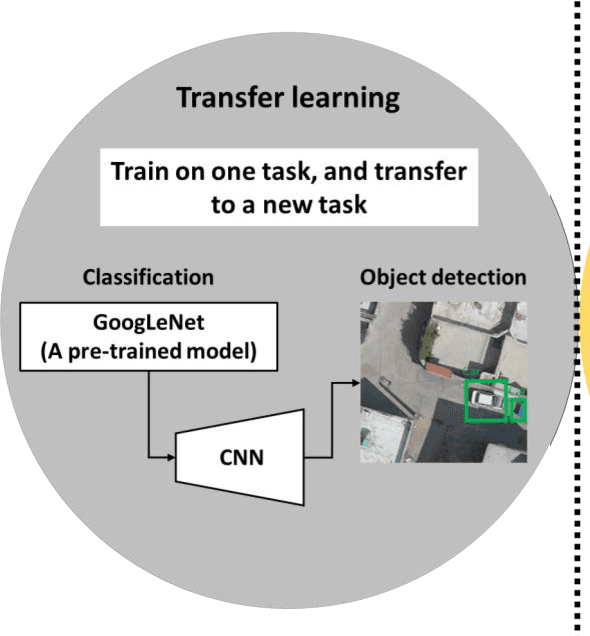
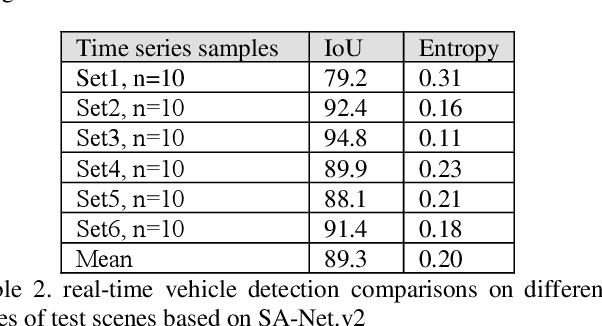

In recent years, unmanned aerial vehicle (UAV) imaging is a suitable solution for real-time monitoring different vehicles on the urban scale. Real-time vehicle detection with the use of uncertainty estimation in deep meta-learning for the portable platforms (e.g., UAV) potentially improves video understanding in real-world applications with a small training dataset, while many vehicle monitoring approaches appear to understand single-time detection with a big training dataset. The purpose of real-time vehicle detection from oblique UAV images is to locate the vehicle on the time series UAV images by using semantic segmentation. Real-time vehicle detection is more difficult due to the variety of depth and scale vehicles in oblique view UAV images. Motivated by these facts, in this manuscript, we consider the problem of real-time vehicle detection for oblique UAV images based on a small training dataset and deep meta-learning. The proposed architecture, called SA-Net.v2, is a developed method based on the SA-CNN for real-time vehicle detection by reformulating the squeeze-and-attention mechanism. The SA-Net.v2 is composed of two components, including the squeeze-and-attention function that extracts the high-level feature based on a small training dataset, and the gated CNN. For the real-time vehicle detection scenario, we test our model on the UAVid dataset. UAVid is a time series oblique UAV images dataset consisting of 30 video sequences. We examine the proposed method's applicability for stand real-time vehicle detection in urban environments using time series UAV images. The experiments show that the SA-Net.v2 achieves promising performance in time series oblique UAV images.
Multi-task learning from fixed-wing UAV images for 2D/3D city modeling
Aug 25, 2021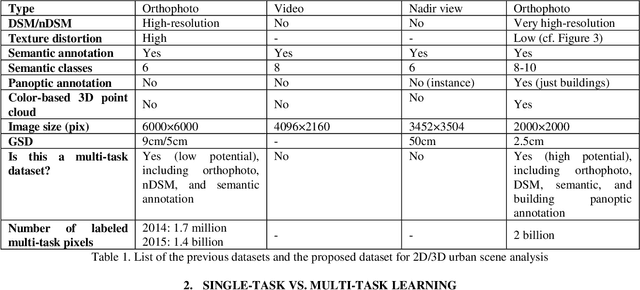
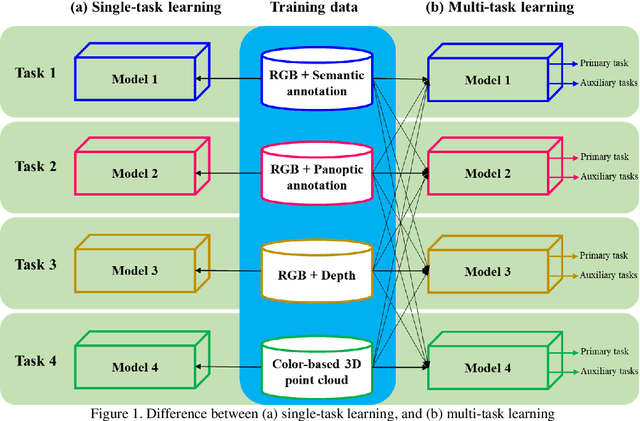

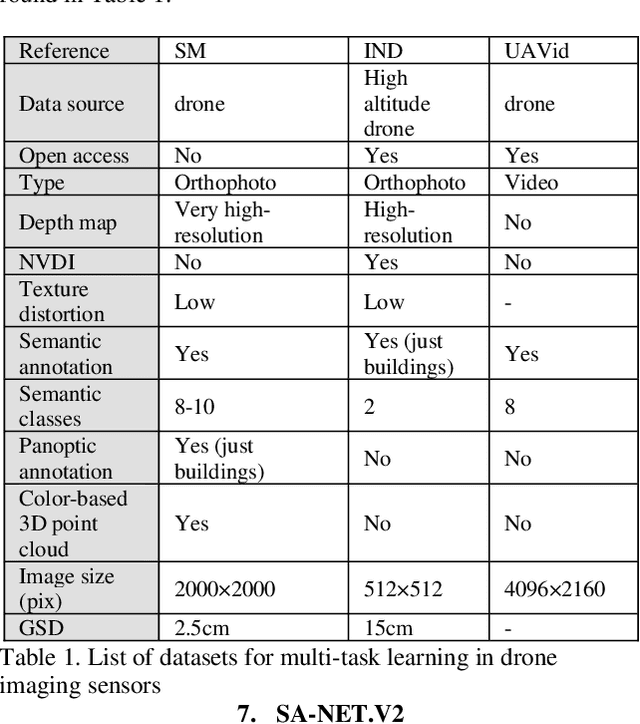
Single-task learning in artificial neural networks will be able to learn the model very well, and the benefits brought by transferring knowledge thus become limited. In this regard, when the number of tasks increases (e.g., semantic segmentation, panoptic segmentation, monocular depth estimation, and 3D point cloud), duplicate information may exist across tasks, and the improvement becomes less significant. Multi-task learning has emerged as a solution to knowledge-transfer issues and is an approach to scene understanding which involves multiple related tasks each with potentially limited training data. Multi-task learning improves generalization by leveraging the domain-specific information contained in the training data of related tasks. In urban management applications such as infrastructure development, traffic monitoring, smart 3D cities, and change detection, automated multi-task data analysis for scene understanding based on the semantic, instance, and panoptic annotation, as well as monocular depth estimation, is required to generate precise urban models. In this study, a common framework for the performance assessment of multi-task learning methods from fixed-wing UAV images for 2D/3D city modeling is presented.
Deep few-shot learning for bi-temporal building change detection
Aug 25, 2021
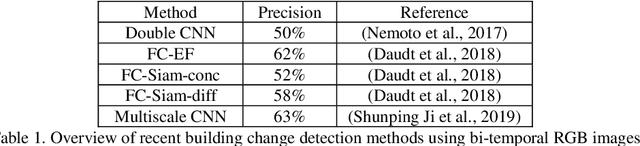
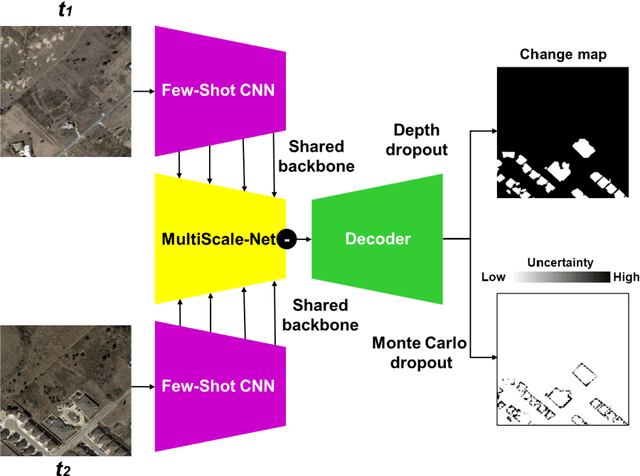
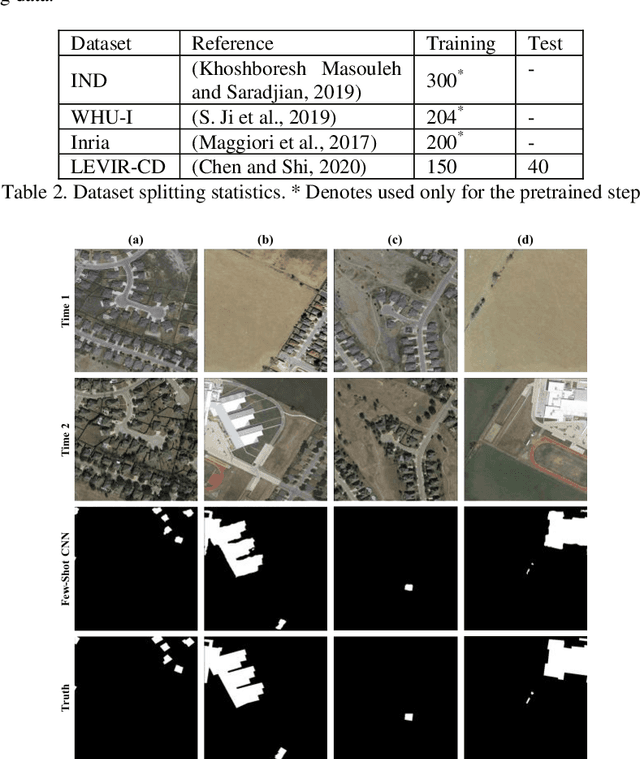
In real-world applications (e.g., change detection), annotating images is very expensive. To build effective deep learning models in these applications, deep few-shot learning methods have been developed and prove to be a robust approach in small training data. The analysis of building change detection from high spatial resolution remote sensing observations is important research in photogrammetry, computer vision, and remote sensing nowadays, which can be widely used in a variety of real-world applications, such as map updating. As manual high resolution image interpretation is expensive and time-consuming, building change detection methods are of high interest. The interest in developing building change detection approaches from optical remote sensing images is rapidly increasing due to larger coverages, and lower costs of optical images. In this study, we focus on building change detection analysis on a small set of building change from different regions that sit in several cities. In this paper, a new deep few-shot learning method is proposed for building change detection using Monte Carlo dropout and remote sensing observations. The setup is based on a small dataset, including bitemporal optical images labeled for building change detection.
* 5 pages, 3 figures
SAMA-VTOL: A new unmanned aircraft system for remotely sensed data collection
Nov 22, 2020In recent years, unmanned aircraft systems (UASs) are frequently used in many different applications of photogrammetry such as building damage monitoring, archaeological mapping and vegetation monitoring. In this paper, a new state-of-the-art vertical take-off and landing fixed-wing UAS is proposed to robust photogrammetry missions, called SAMA-VTOL. In this study, the capability of SAMA-VTOL is investigated for generating orthophoto. The major stages are including designing, building and experimental scenario. First, a brief description of design and build is introduced. Next, an experiment was done to generate accurate orthophoto with minimum ground control points requirements. The processing step, which includes automatic aerial triangulation with camera calibration and model generation. In this regard, the Pix4Dmapper software was used to orientate the images, produce point clouds, creating digital surface model and generating orthophoto mosaic. Experimental results based on the test area covering 26.3 hectares indicate that our SAMA-VTOL performs well in the orthophoto mosaic task.
* 12 pages, 6 figures
Robust building footprint extraction from big multi-sensor data using deep competition network
Nov 16, 2020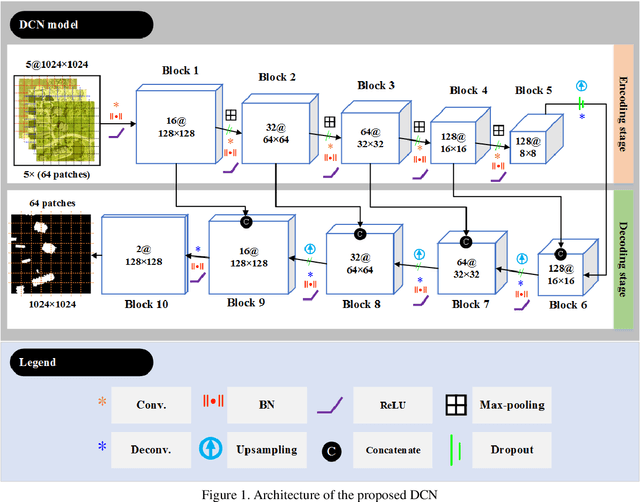
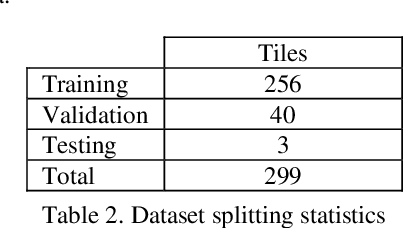
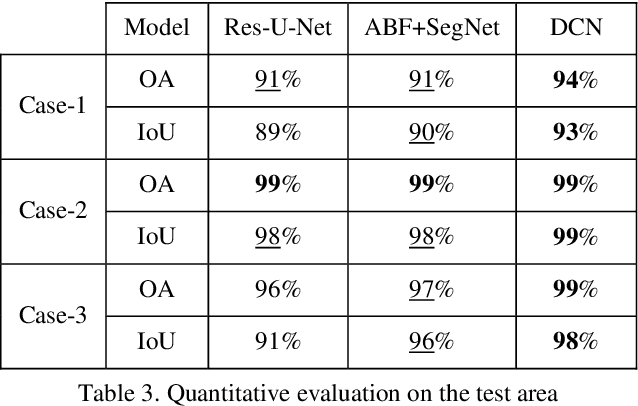
Building footprint extraction (BFE) from multi-sensor data such as optical images and light detection and ranging (LiDAR) point clouds is widely used in various fields of remote sensing applications. However, it is still challenging research topic due to relatively inefficient building extraction techniques from variety of complex scenes in multi-sensor data. In this study, we develop and evaluate a deep competition network (DCN) that fuses very high spatial resolution optical remote sensing images with LiDAR data for robust BFE. DCN is a deep superpixelwise convolutional encoder-decoder architecture using the encoder vector quantization with classified structure. DCN consists of five encoding-decoding blocks with convolutional weights for robust binary representation (superpixel) learning. DCN is trained and tested in a big multi-sensor dataset obtained from the state of Indiana in the United States with multiple building scenes. Comparison results of the accuracy assessment showed that DCN has competitive BFE performance in comparison with other deep semantic binary segmentation architectures. Therefore, we conclude that the proposed model is a suitable solution to the robust BFE from big multi-sensor data.
* 7 pages, 5 figures