 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Thermodynamic Theory of Learning Part II: Critical Period Closure and Continual Learning Failure
Feb 08, 2026Learning performed over finite time is necessarily irreversible. In Part~I of this series, we modeled learning as a transport process in the space of parameter distributions and derived the Epistemic Speed Limit, which lower-bounds entropy production under finite-time learning. In this work (Part~II), we study the consequences of this irreversibility for continual learning from a trajectory-level perspective. We show that finite dissipation constrains not only which solutions are reachable, but which learning paths remain dynamically accessible. Although a continuum of task-equivalent realizations can achieve identical task performance, finite-time learning irreversibly selects among these realizations. This selection occurs through the progressive elimination of degrees of freedom that would otherwise enable structural reconfiguration. We refer to this phenomenon as \emph{critical period closure}: beyond a certain stage of learning, transitions between compatible representations become dynamically inaccessible under any finite dissipation budget. As a result, continual learning failure arises not from the absence of solutions satisfying multiple tasks, but from an irreversible loss of representational freedom induced by prior learning. This reframes catastrophic forgetting as a dynamical constraint imposed by finite-time dissipation, rather than direct task interference.
A Thermodynamic Theory of Learning I: Irreversible Ensemble Transport and Epistemic Costs
Jan 24, 2026Learning systems acquire structured internal representations from data, yet classical information-theoretic results state that deterministic transformations do not increase information. This raises a fundamental question: how can learning produce abstraction and insight without violating information-theoretic limits? We argue that learning is inherently an irreversible process when performed over finite time, and that the realization of epistemic structure necessarily incurs entropy production. To formalize this perspective, we model learning as a transport process in the space of probability distributions over model configurations and introduce an epistemic free-energy framework. Within this framework, we define the free-energy drop as a bookkeeping quantity that records the total reduction of epistemic free energy along a learning trajectory. This reduction decomposes into a reversible component associated with potential improvement and an irreversible component corresponding to entropy production. We then derive the Epistemic Speed Limit (ESL), a finite-time inequality that lower-bounds the minimal entropy production required by any learning process to realize a given distributional transformation. This bound depends only on the Wasserstein distance between initial and final ensemble distributions and is independent of the specific learning algorithm.
PLaMo 2 Technical Report
Sep 05, 2025In this report, we introduce PLaMo 2, a series of Japanese-focused large language models featuring a hybrid Samba-based architecture that transitions to full attention via continual pre-training to support 32K token contexts. Training leverages extensive synthetic corpora to overcome data scarcity, while computational efficiency is achieved through weight reuse and structured pruning. This efficient pruning methodology produces an 8B model that achieves performance comparable to our previous 100B model. Post-training further refines the models using a pipeline of supervised fine-tuning (SFT) and direct preference optimization (DPO), enhanced by synthetic Japanese instruction data and model merging techniques. Optimized for inference using vLLM and quantization with minimal accuracy loss, the PLaMo 2 models achieve state-of-the-art results on Japanese benchmarks, outperforming similarly-sized open models in instruction-following, language fluency, and Japanese-specific knowledge.
When Does Metadata Conditioning (NOT) Work for Language Model Pre-Training? A Study with Context-Free Grammars
Apr 24, 2025



The ability to acquire latent semantics is one of the key properties that determines the performance of language models. One convenient approach to invoke this ability is to prepend metadata (e.g. URLs, domains, and styles) at the beginning of texts in the pre-training data, making it easier for the model to access latent semantics before observing the entire text. Previous studies have reported that this technique actually improves the performance of trained models in downstream tasks; however, this improvement has been observed only in specific downstream tasks, without consistent enhancement in average next-token prediction loss. To understand this phenomenon, we closely investigate how prepending metadata during pre-training affects model performance by examining its behavior using artificial data. Interestingly, we found that this approach produces both positive and negative effects on the downstream tasks. We demonstrate that the effectiveness of the approach depends on whether latent semantics can be inferred from the downstream task's prompt. Specifically, through investigations using data generated by probabilistic context-free grammars, we show that training with metadata helps improve model's performance when the given context is long enough to infer the latent semantics. In contrast, the technique negatively impacts performance when the context lacks the necessary information to make an accurate posterior inference.
PLaMo-100B: A Ground-Up Language Model Designed for Japanese Proficiency
Oct 10, 2024



We introduce PLaMo-100B, a large-scale language model designed for Japanese proficiency. The model was trained from scratch using 2 trillion tokens, with architecture such as QK Normalization and Z-Loss to ensure training stability during the training process. Post-training techniques, including Supervised Fine-Tuning and Direct Preference Optimization, were applied to refine the model's performance. Benchmark evaluations suggest that PLaMo-100B performs well, particularly in Japanese-specific tasks, achieving results that are competitive with frontier models like GPT-4.
Speed-accuracy trade-off for the diffusion models: Wisdom from nonequlibrium thermodynamics and optimal transport
Jul 05, 2024We discuss a connection between a generative model, called the diffusion model, and nonequilibrium thermodynamics for the Fokker-Planck equation, called stochastic thermodynamics. Based on the techniques of stochastic thermodynamics, we derive the speed-accuracy trade-off for the diffusion models, which is a trade-off relationship between the speed and accuracy of data generation in diffusion models. Our result implies that the entropy production rate in the forward process affects the errors in data generation. From a stochastic thermodynamic perspective, our results provide quantitative insight into how best to generate data in diffusion models. The optimal learning protocol is introduced by the conservative force in stochastic thermodynamics and the geodesic of space by the 2-Wasserstein distance in optimal transport theory. We numerically illustrate the validity of the speed-accuracy trade-off for the diffusion models with different noise schedules such as the cosine schedule, the conditional optimal transport, and the optimal transport.
Generative Model for Constructing Reaction Path from Initial to Final States
Jan 19, 2024



Mapping out reaction pathways and their corresponding activation barriers is a significant aspect of molecular simulation. Given their inherent complexity and nonlinearity, even generating a initial guess of these paths remains a challenging problem. Presented in this paper is an innovative approach that utilizes neural networks to generate initial guess for these reaction pathways. The proposed method is initiated by inputting the coordinates of the initial state, followed by progressive alterations to its structure. This iterative process culminates in the generation of the approximate representation of the reaction path and the coordinates of the final state. The application of this method extends to complex reaction pathways illustrated by organic reactions. Training was executed on the Transition1x dataset, an organic reaction pathway dataset. The results revealed generation of reactions that bore substantial similarities with the corresponding test data. The method's flexibility allows for reactions to be generated either to conform to predetermined conditions or in a randomized manner.
Collision-free Path Planning on Arbitrary Optimization Criteria in the Latent Space through cGANs
Feb 26, 2022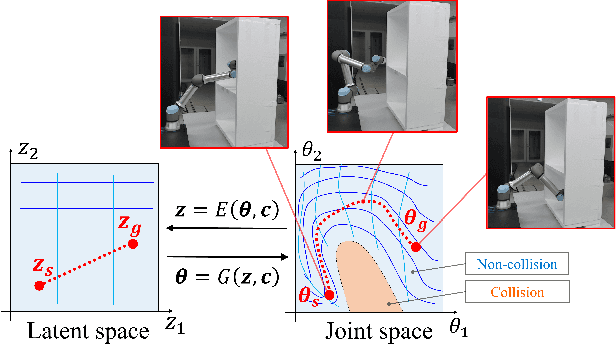
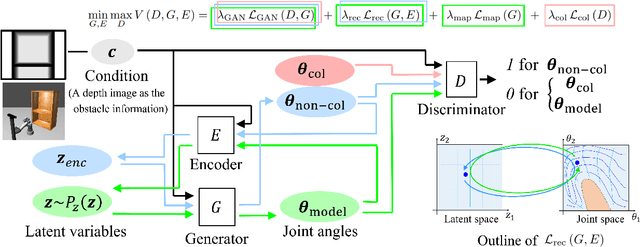
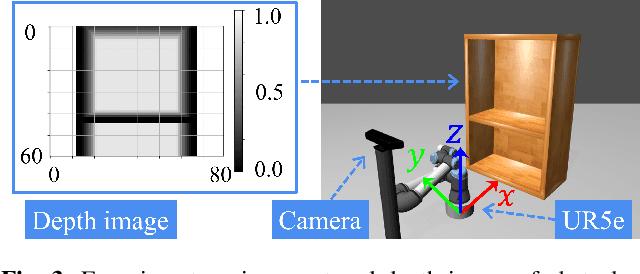

We propose a new method for collision-free path planning by Conditional Generative Adversarial Networks (cGANs) by mapping its latent space to only the collision-free areas of the robot joint space when an obstacle map is given as a condition. When manipulating a robot arm, it is necessary to generate a trajectory that avoids contact with the robot itself or the surrounding environment for safety reasons, and it is convenient to generate multiple arbitrary trajectories appropriate for respective purposes. In the proposed method, various trajectories to avoid obstacles can be generated by connecting the start and goal with arbitrary line segments in this latent space. Our method simply provides this collision-free latent space after which any planner, using any optimization conditions, can be used to generate the most suitable paths on the fly. We successfully verified this method with a simulated and actual UR5e 6-DoF robotic arm. We confirmed that different trajectories can be generated according to different optimization conditions.
Collision-free Path Planning in the Latent Space through cGANs
Feb 15, 2022



We show a new method for collision-free path planning by cGANs by mapping its latent space to only the collision-free areas of the robot joint space. Our method simply provides this collision-free latent space after which any planner, using any optimization conditions, can be used to generate the most suitable paths on the fly. We successfully verified this method with a simulated two-link robot arm.
Neural Multi-scale Image Compression
May 16, 2018



This study presents a new lossy image compression method that utilizes the multi-scale features of natural images. Our model consists of two networks: multi-scale lossy autoencoder and parallel multi-scale lossless coder. The multi-scale lossy autoencoder extracts the multi-scale image features to quantized variables and the parallel multi-scale lossless coder enables rapid and accurate lossless coding of the quantized variables via encoding/decoding the variables in parallel. Our proposed model achieves comparable performance to the state-of-the-art model on Kodak and RAISE-1k dataset images, and it encodes a PNG image of size $768 \times 512$ in 70 ms with a single GPU and a single CPU process and decodes it into a high-fidelity image in approximately 200 ms.